※本記事はOracleの下記Meetup「Oracle Big Data Jam Session」で実施予定の内容です。
※セミナー実施済の動画に関しては以下をご参照ください。
本記事の対象者
- これから機械学習を利用した開発をしていきたい方
- 機械学習のトレンド技術を知りたい方
- なるべく初歩的な内容から学習したい方
はじめに
Transformerの登場以降、著しい技術革新が続くここ数年、特にOpenAI社のChatGPTのサービス開始以降、おびただしい数の技術ブログや記事がインターネット上に存在する中、本記事に目を留めていただいてありがとうございます。
この勉強会では、専門用語や難解な公式を極力排除し、初学者の方々を対象に、「そもそも自然言語の機械学習ってどういうもの?」、「言語モデルって要するに何?」というところからGPTをざっくり理解することを目的としています。従って本記事に記載のある内容は、わかりやすさを優先して実際の内部処理(特にベクトル演算)をかなり簡略化した説明になっていますことをあらかじめご了承ください。
機械学習
機械学習の重要な登場人物と言えば、大量の学習データと統計関数です。機械学習は、大量の学習データを使って、この統計関数を完成させる処理だと言っていいと思います。
皆様が考える関数とはどのようなものでしょうか?筆者が真っ先に思い浮かぶのは、f(x) = ax + b のようなものです。これは中学生の数学で勉強した一次関数ですよね。機械学習は難解なイメージがありますが、実はこの ax + b のところがもっと複雑になっただけで、上述した基本的な考え方(統計関数を完成させるという点)ではこのシンプルな一次関数を完成させるということと何ら変わりません。そして、通常この x に入力するデータというのは1とか2というような数値を代入して計算しますが、この x に、例えば「日本で一番高い山」というような「文章」をなんとかして入力したい、以降はそんなお話です。
学習データ
そして、次の重要な登場人物(機械学習で一番大事な登場人物と言っていいでしょう。)である「学習データ」に目を向けてみましょう。これまで機械学習ではビジネスの現場で生まれた様々なデータが使われてきました。
下図に代表的なデータ種別を記載してみました。御覧の通り、様々なものがあり、これらのデータを統計関数に入力し最終的な統計関数、つまり「予測モデル」を完成させるというのが機械学習の学習処理ということになります。
この際、上述した通り、統計関数には量的データ、ありていに言うと数値しか入力できません。なので量的データ以外のデータははエンコードと呼ばれる処理を施して、量的データに変換する必要があります。
では、下図にあるようなデータはどのようにしてエンコードするのかを考えていきたいと思います。
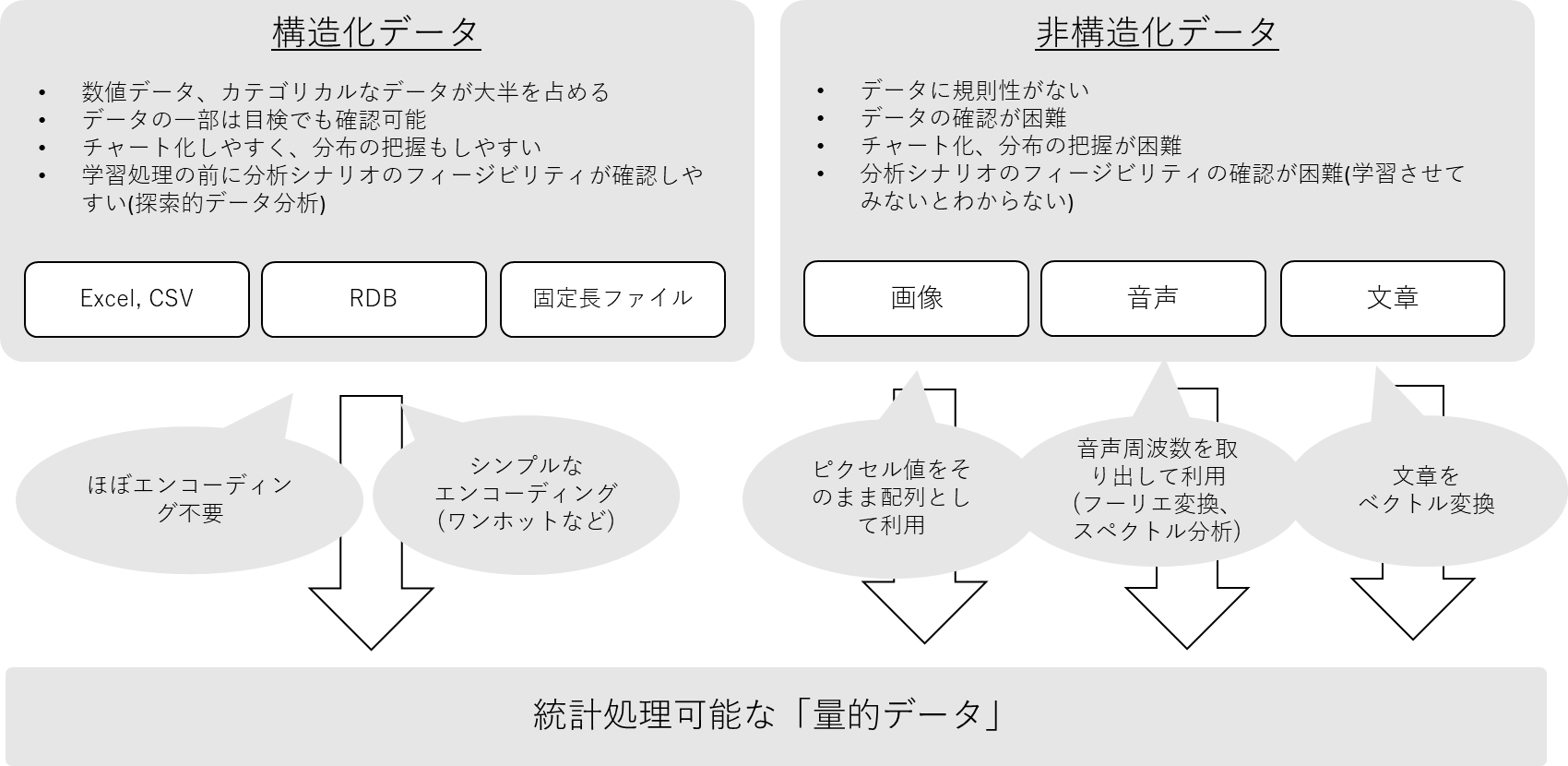
上図左の「構造化データ」から見ると、
ビジネスの現場で、よく使われるExcel、CSV、固定長ファイル、RDBにあるデータがあります。これらは古くはデータマイニングと呼ばれている時代から統計処理によく使われてきました。これらは数値データやカテゴリカルなデータ(例えばジュースのサイズS, M, LなどDWHに入っていそうなデータ)がメインのため簡単に統計関数に入力できます。数値データはエンコーディングは不要ですし、カテゴリカルなデータも簡単に量的データに変換できるので、これらのような構造化データについてはほとんど頭を悩ませる必要はありません。
それと比較して上図右側の「非構造化データ」はどうでしょうか?
一見複雑そうに感じる画像データは実は一番単純です。画像データはもともとピクセル値の配列で体系だって作られているデータですから、大した前処理もせずにそのまま関数に入力できます。
そして音声ファイルも量的データへの変換方法はだいたい決まっています。「フーリエ変換」し、音声周波数を取り出して、「スペクトル分析」をすると数値化が可能です。「フーリエ変換」や「スペクトル分析」など小難しい名前がでてきますが、昨今は便利がAPIが沢山あり、数行のコードで簡単に処理できますので心配無用です。
そして非構造化データの最後、本記事の主役である、文章データはどうでしょうか?文章データも当然数値化は可能です。一般に想像する1とか2という数値ではなく「ベクトル」(もしくは「埋め込み表現」と言ったりします。)という数値表現です。
この記事はGPTに関連する記事ですが、GPT、ひいては自然言語処理のお話を突き詰めると、結局は「文章というデータをどのように良質なベクトルに変換するか」というのが本質なように思います。
統計関数
そして、自然言語のような非構造化データを扱うアルゴリズムとしてはやはりニューラルネットワークということになります。いわゆる深層学習で使われるアルゴリズムです。

ニューラルネットワークは人間の脳内で起こっている生体現象を数理モデルに落とし込んだアルゴリズムとして有名ですが、目的に応じた様々なタイプのネットワークが開発されています。
-
CNN(Convolution Neural Network)
画像分類や物体検出などのタスクはCNN(Convolution Neural Network)を使うことで精度が確保できることが多く、現在はこの一択という感じです。 -
GAN(Generative Adversarial Network)
また、画像生成はGAN(Generative Adversarial Network)が元祖ということで、こちらも技術革新著しい生成AIの分野でよく使われるアルゴリズムになります。 -
RNN
そして、主に、自然言語をデータとして扱うアルゴリズムとしてRNNがあります。今となってはGPTの前世代の技術となりますが、この時代の技術を概要だけでも知っておくことはGPTの理解に大きく役立ちます。新しい技術とは過去の技術の課題を改善しながら発展してゆくケースが多く、自然言語処理の世界もまた然りです。
自然言語処理はその他の分野と比べて非常に難解な機構が多いため、RNNからの技術変遷をベースにGPTを理解することが最も腹落ち感が高いのではないかと感じます。
RNN(Recurrent Neural Network)
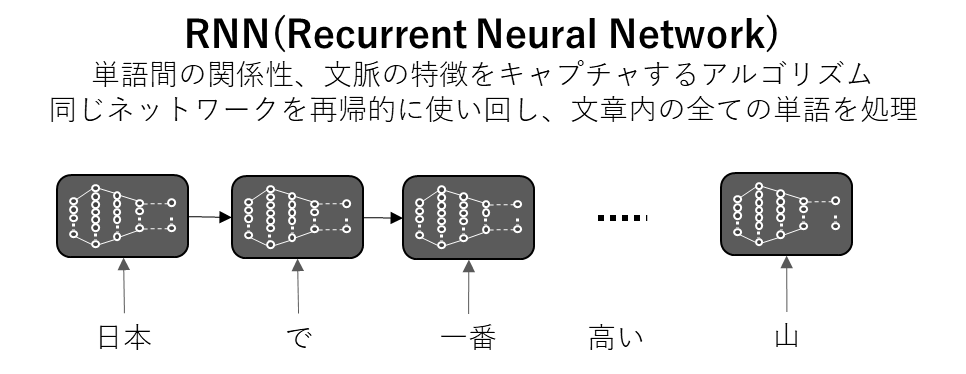
RNNは主に、自然言語の深層学習に効果を発揮するアルゴリズムです。入力された文章を単語に区切り、その単語をニューラルネットワークで計算し、その計算結果を次の単語の計算に利用するという処理を、文章の全ての単語に再帰的(Recurrent)に繰り返すニューラルネットワーク、ということでRNN(Recurrent Neural Network)と呼ばれています。
RNNの課題
このような処理により、単語間の関係性や文脈の特徴を表現できるアルゴリズムとして長きに渡ってこの分野をけん引してきましが、RNNには下記のように二つの大きな課題がありました。
-
長期記憶の仕組みがない
これが意味するところは、RNNには長文を学習させることに限界があるということです。人間も言語を学習する際、長文を扱うことは重要ですよね。例えば英語学習を例にあげると。「私は学校に行きました。」「私は病院に行きました。」という単純な英文をたくさん学習したところで、長文を理解すること、話せるようになることは難しいと感覚的にわかります。ところが、この状態から関係代名詞という文法を学習したとします。それにより、「私は東京駅の近くにある大きな病院に行きました。」という少し長い文章を理解することができます。コンピュータの言語認識もこれに非常に似ており、長文データの学習が非常に有効だということは、過去の研究で証明されています。 -
並列処理ができない
RNNの絵を見ていただくとわかりますが、RNNでは、一つ一つの単語の計算は逐次処理となります。「日本」という単語を処理した後、その処理結果を使って、次の単語「で」の処理を行うということを繰り返します。つまり前の単語の計算が終わらないと、次の単語の計算が始められないのです。したがって、文章内の全ての単語を同時に計算するということができません。この制約により、RNNで大規模なデータを学習させるためには膨大な時間を要することとなり、事実上、合理的な時間で精度の高い推論モデルを作ることが不可能でした。
ただ、このようなデメリットがありながらも、RNNは単語間の関係性や、文脈の特徴をとらえることができるという大きなメリットをもったアルゴリズムなので、そうそう他のものに置き換えることができないという実情がありました。そこで、RNNを使いながら、これらの課題をなんとか解決できないかという方向性で、出てきた技術の主だったものがLSTMとAttentionというものです。
LSTM(Long Short Term Memory)
RNNに長期記憶の仕組みがないのであれば、RNNのネットワークを改造して、長期記憶の仕組みを組み込んでしまおう、というのがLSTMです。(つまりLSTMもニューラルネットワークの一種です。)
LSTMでは下図のように、もともとのRNNのネットワークを拡張して、長期記憶が可能なネットワークに作り変えています。
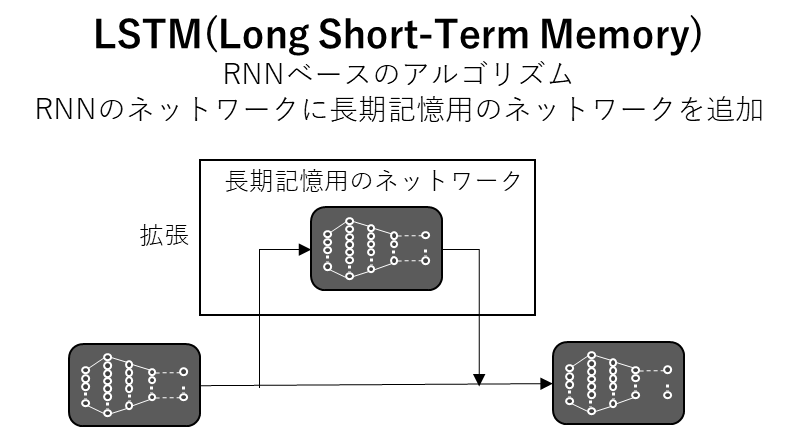
このようにネットワークを改造して、もともとのアルゴリズムの構造に機能を追加できる点はニューラルネットワークの非常に便利な点ですね。
Attention
そして、Attention機構は「文章内のどの単語に注意を払うべきか」という点に着目し、各単語に重み付をするような処理を行い、各単語間の関係性や文脈の特徴を表す機構です。各単語間の関係性や文脈の特徴を表す機構という観点ではRNNもそうですよね?と思われますよね。そうです同じなので、AttentionはRNNの補助的な役割として、RNNと併用する形で実装されていました。

ただ、LSTM、Attentionともに、RNNがベースになっています。RNNを使っている限り、並列処理ができない⇒なので大規模データの学習ができない⇒なのでモデルの精度は結局あまり改善されなかった、というのが歴史的な経緯です。
そこで、思い切ってRNNはあきらめ、もともと補助的に組み込まれていたAttentionを、文脈把握と単語間の関係性把握のためのメインの機構としてフル活用することにより、RNNの大きな課題であった並列処理と長期記憶の問題を解決したTransformerが開発されました。
Transformerの登場
GPTの話がいつ出てくるの?と思われるかもしれませんが、実はこのTransformerこそがGPTです。GPTの「T」はTransformerの頭文字である「T」です。GPTはGenerative Pretrained Transformerの略となり、Transformerの前についているGenerativeとPretrainedは、端的にこの大規模言語モデルの特長を捉えた名前になっています。
- Generative ⇒ 生成的という意味を持ち、文章生成能力が高いということを指しています。
- Pretrained ⇒ 事前学習済み、つまり、Open AI社によって、膨大な学習データで既に学習済のモデルだということを指しています。
- Transformer ⇒ その学習がTransformerで行われたということで
Generative Pretrained Transformerという名前になっています。
ちなみに、Google社のBERTもTransformerで学習したモデルです。BERTはBidirectional Encoder Representations from Transformersの略となり、こちらも、Bidirectional Encoder Representations(双方向のエンコード表現)がBERTの技術的特徴(文章を文頭と文末から双方向に学習するような仕組み)を表したものだということになります。
つまり、TransformerとGPT、BERTさらに、両社の関連サービスの関係は以下のようになると思います。

つまりOpen AI社とGoogle社は一部の技術エリアで完全なライバル企業同士ということになります。そして、興味深い点は、両社が利用しているTransformerはGoogle社が開発し、2017年にオープンソースとしてリリースしたものなのです。
オープンソース戦略は今やIT企業にとってマーケットでの企業優位性確保しつつマネタイズモデルを確立するお決まりの戦略となってますが、それと同時に諸刃の剣であることは自明です。IT業界においてかつてこれほどの規模の諸刃の剣になった技術はなかったのではないでしょうか。
Transformerの仕組み
Transformerの論文を見ると、まず目を引くのが下図。この図を読み解くことは、Transformerを理解するうえで避けて通れません。
非常に難解な図ですが、ここでは、ざっくりと理解することを目的に、まずは全体を俯瞰した図に置き換えつつ、内部の処理について「要はなにをしているのか?」、「何のためにその処理をしているのか?」という観点で説明します。
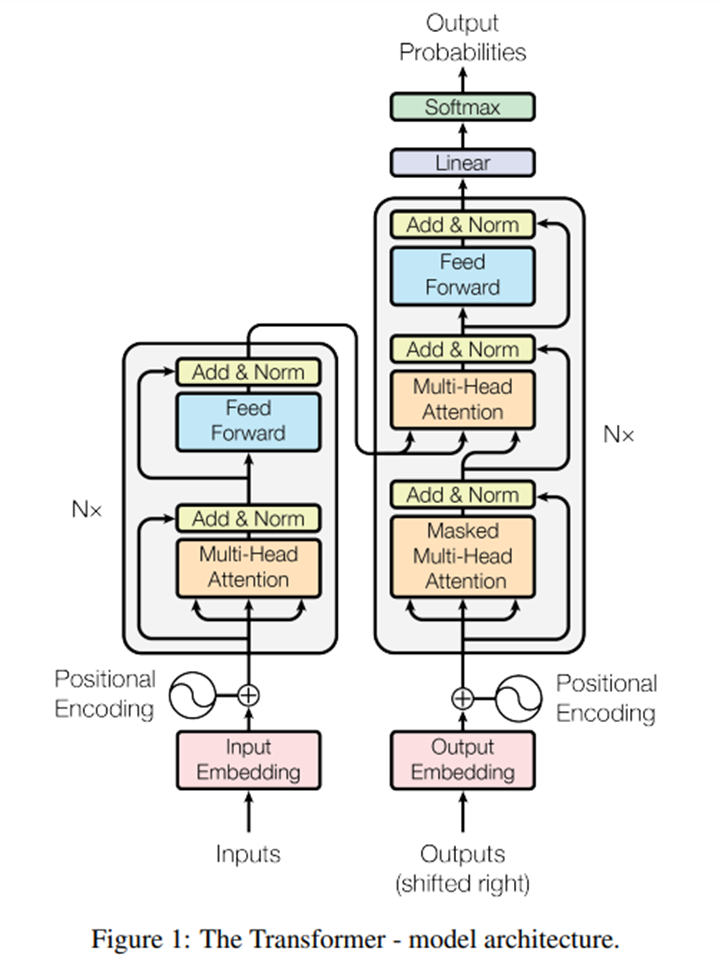
まず、この図を最も抽象化した図に置き換えると以下のようなイメージです。そして、今回はあえてこの絵をGPTとして説明したいと思います。

例えば、「日本で一番高い山」という文章をGPTに入力したとします。すると、GPTはその文章に関連する可能性の高い単語を推論します。この場合、「富士山」という単語が出力されることが期待されます。
つまり、GPTとは、「入力された文章の次に配置される可能性が最も高い単語を推論する計算機(ニューラルネットワーク)」ということになります。
エンコーダーとデコーダー
更に、図を左側(Encoder側)と右側(Decoder側)に分けて理解を深めます。
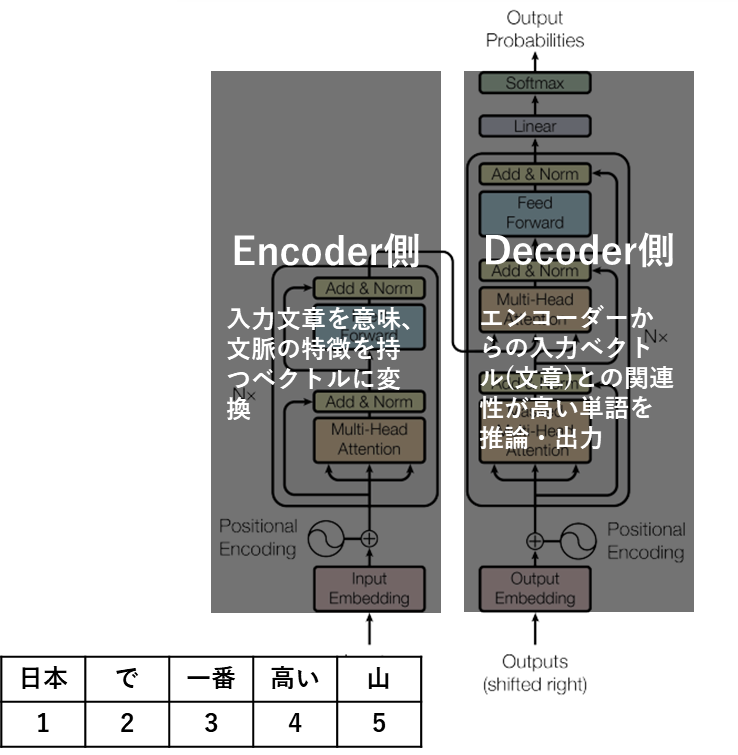
Encoderは冒頭で説明した「エンコーディング」を行うパートです。文章をそのまま推論の統計関数に入力することはできないので量的データであるベクトルに変換するという処理を受け持つパートです。
そして、Encoderで作られたベクトルはDecoderに入力されます。Decoderはこの入力文章のベクトルを受けて、その文章の後に続く単語(関連性の高い単語)を推論する計算を行い、最終的に最も可能性の高い単語を出力します。
従って、「エンコーダー側で、入力文章をベクトルに変換し、そのベクトルをデコーダーが受け取って、推論計算を行ってを単語を生成する」とざっくり考えればよいのですが、この中で行われる、自然言語のベクトル化は、画像データや音声データのようなシンプルな手法では実現できません。
なぜなら、画像データや音声データはもともと、体系だった数値の集合体からなるデータなのでベクトル化には複雑な機構が不要なのですが、自然言語の単語には意味があり、さらに文脈があるからです。
それゆえに、これらの文章とベクトルの変換処理の過程で、文脈や単語間の関係性をベクトルに反映するための様々な処理があります。以降はそれらの中の代表的な機構のお話になります。
エンコーダー側の処理
まずは図の左側エンコーダー側からみてゆきましょう。
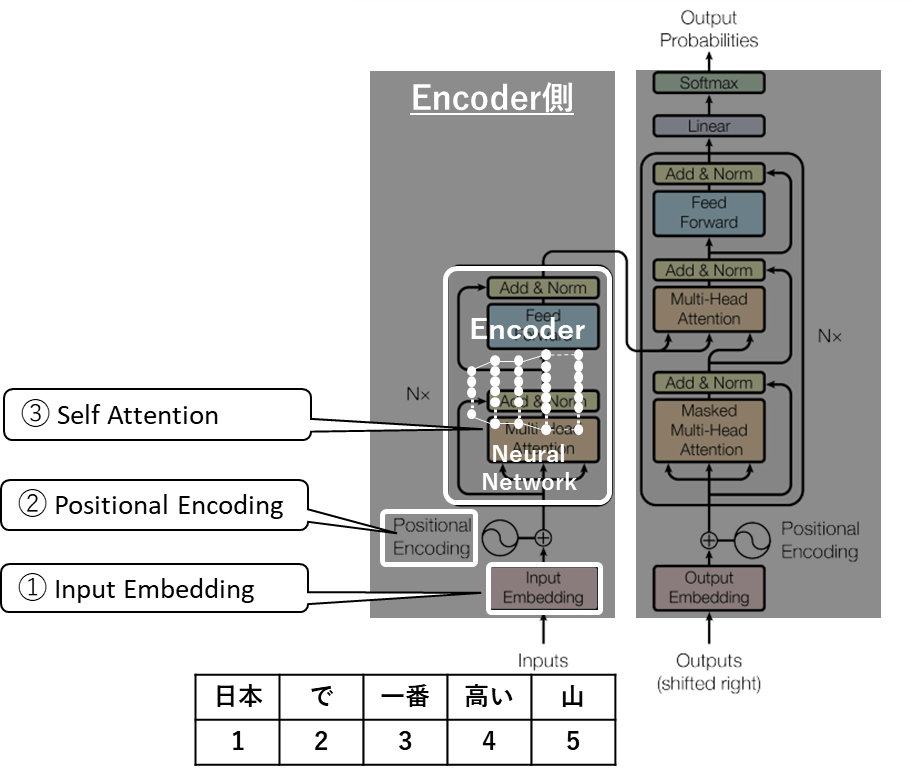
- メインの処理として「エンコーダー」があり、これはニューラルネットワークのアルゴリズム、つまり統計関数そのものです。ここでは様々な処理を行いますが、Transformerを理解するうえで欠かせないAttention機構があります。
- この統計関数(ニューラルネットワーク)には文章や単語をそのまま入力することはできないため、量的データに変換する処理が必要になり、Input EmbeddingとPositional Encodingと呼んでいる処理です。
①Input Embedding
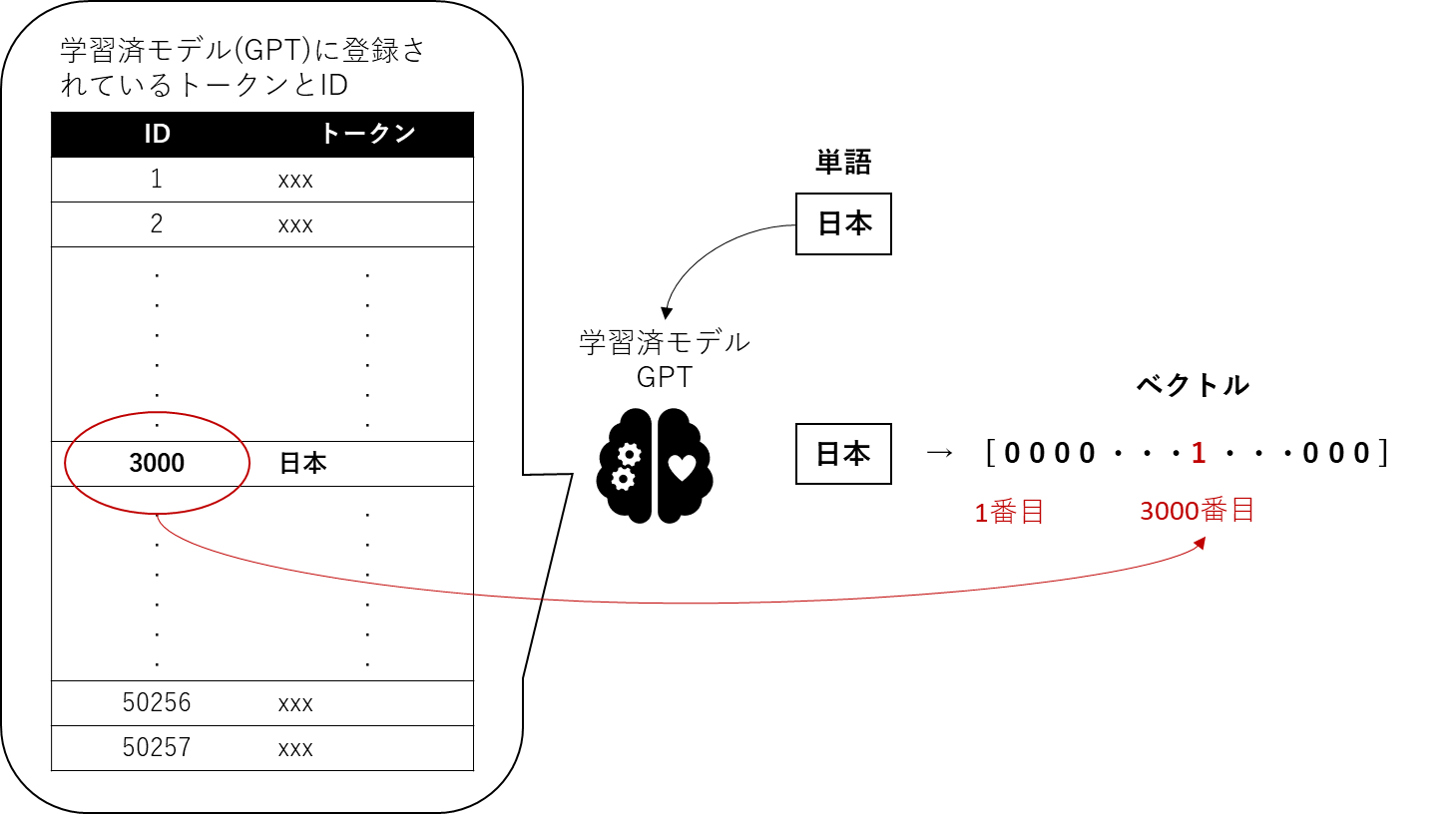
例えば、「日本で一番高い山」という文章が入力されたとします。まずはこの文章を単語の単位(≒トークン)に分割しベクトル化します。GPTなどはインターネット上の文章データをクローリングして集めた大規模なコーパス(学習データ)を既に学習済のモデルなので、この学習済モデルには多数の単語の(≒トークン)とそれに対応するIDが既に登録されています。このIDを使って、入力された単語をベクトル化します。仮に「日本」という単語のIDが3000番だったとした場合、下図のように、3000番目に1が入り、その他は全て0で埋められた一行のベクトルが生成されます。
この処理を入力文章内の単語全てに行うと下図のようなベクトルが出来上がることがわかります。

実際はGPTに登録されているトークンは完全な単語ではなく、テキスト中に頻繁に現れる文字のグループになっているそうです。
しかし、変換されたベクトルのほとんどの成分は0で構成された非効率で巨大なベクトルです。なので、これを線形射影し、より小さな次元空間に線形射影した時の長さを成分とするベクトルに変換します。
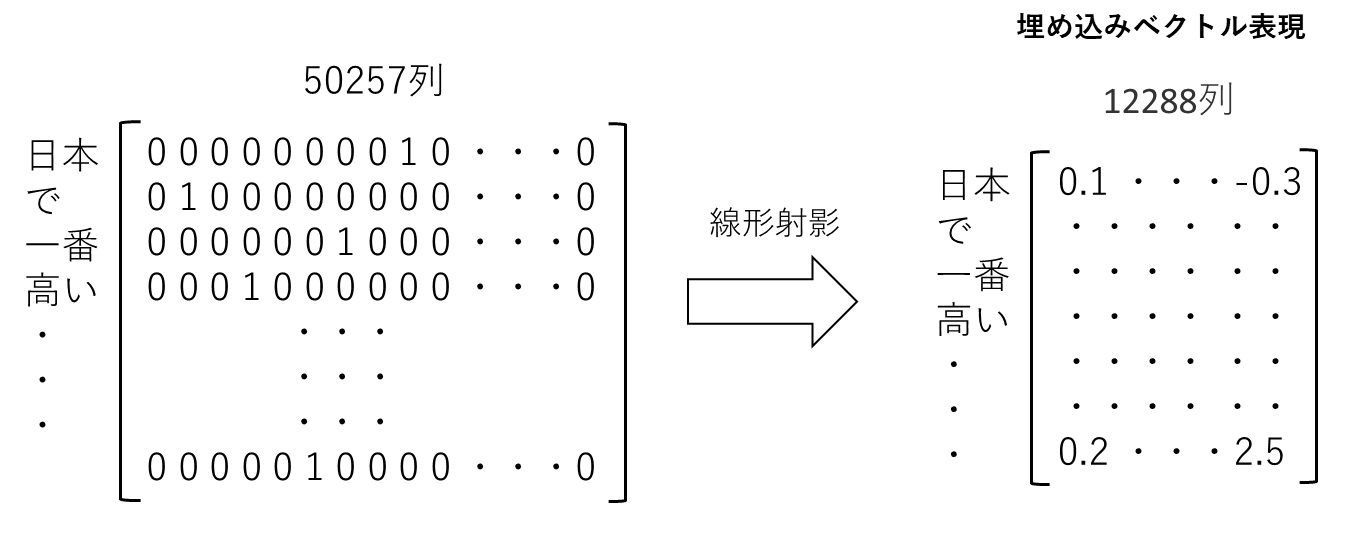
これらのベクトルは、GPTの学習済モデルの中で、事前学習された巨大な意味空間にマッピングされ、単語の意味を持ったベクトル表現になっています。このベクトル化をすることで単語同士の意味の近さを計算したり、単語の意味自体を計算することができるようになります。
仮に、この意味空間が二次元だとした場合、下図のようなイメージです。意味の近い単語は近いベクトルを持ちます。下図は二次元の例ですが、GPTでは大量の単語が登録された1万2288次元のとてつもなく大きな意味空間に、入力された単語がマッピングされます。

②Positional Encoding
各単語がベクトル化されたので、もうエンコーダー(ニューラルネットワーク)に入力できる状態です。しかし、このまま入力してしまっては、文章としての「語順」の特徴が完全に抜けてしまっています。この「語順」は文章の文脈把握のためには非常に重要な特徴というのは感覚的に理解できますよね。人間が言葉を話すときに、語順がめちゃくちゃだと意味が理解できない、もしくは間違った意味になってしまうのと同じです。
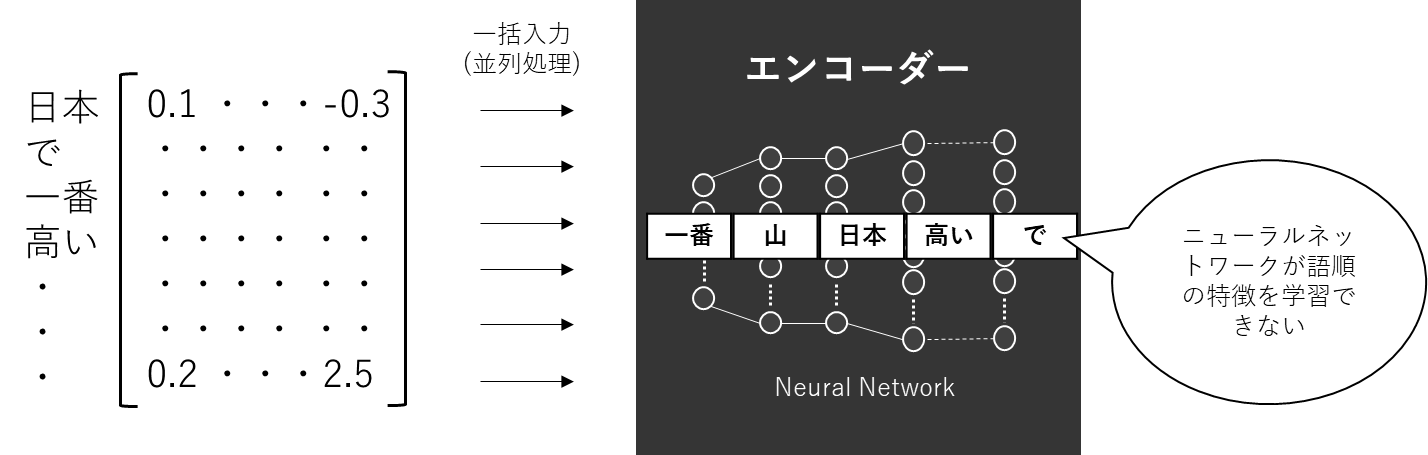
ですので、ニューラルネットワークにデータを入力する前にこの語順の情報をベクトルとして付加する必要があり、その処理をPositional Encodingと呼んでいます。
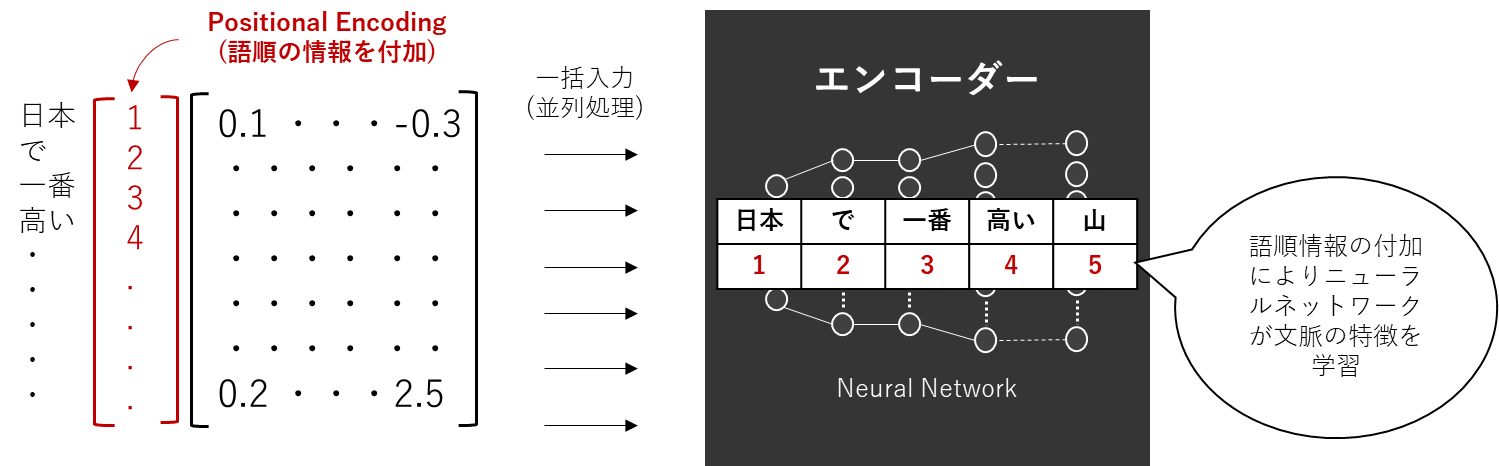
また、RNNでは、文章を単語(≒トークン)に区切って文頭から一単語づつベクトル化して、ニューラルネットワークに順番に入力していました。これは一つ目の単語を計算し、その結果を二つ目の計算の入力に使うからです。
これによって、語順の特徴を確保し文脈把握に役立てていました。しかしこの計算順序では複数の単語のベクトル化を同時に計算することができません。前の単語の計算が終わらないと次の単語の計算が始められない、つまり並列化できないというのは一目瞭然です。RNNは文脈把握ができるというメリットがありつつ、並列化できないというデメリットを同時に持ち合わせるアルゴリズムでした。
これに対して、TransformerではPositional Encodingにより、ベクトル化した単語を纏めてエンコーダー(ニューラルネットワーク)に入力することができるようになっています。(Positional Encodingにより、生成されたベクトルに語順の特徴量が含まれているからです。)そうすることで並列処理にも寄与しています。
実際には、このような単純なベクトルではなく、正弦関数を通して、元の埋め込みベクトルに加算されるような処理が行われています。
③エンコーダーでのAttention(Self Attention)
Attentionとは日本語でいうと「注意を向ける」という文脈でよく使われますよね。これは自然言語だけでなく、画像処理やその他、いたるところで使われている機構です。例えば画像分類や物体検出にニューラルネットワークを使う例を考えてみましょう。下記のような画像に何が映っているかを検出する場合、人間であれば、瞬時に車だということが認識できます。その認識は、この画像を無意識に、「物体」と「背景」に分け、「物体」に「注意を向ける」ことから始まっています。

これは、「物体に注意を向ける」ことにより、「背景の情報を処理しなくてよい」ので瞬時に認識できると言い換えることができます。この人間の脳内で行われているAttention(つまり注意を向けていないところは処理しなくていい)と呼ばれる処理を採用したことがTransformerの最大の成功理由であると同時に、ここ数年の自然言語処理の著しい精度向上の最大の要因だと言われています。
因みに、このAttention機構は、研究者の思いつきではなく、認知科学の分野では「ウィケンズの情報処理モデル」として確立している有名な機構だそうです。
実際にAttention機構を備えた画像分類のコードは、下記の図のように、「背景と物体の分離を行い、注意を向ける領域を推論するネットワーク」を構成し、その計算結果をメインのネットワークに戻すようなネットワークを構成します。このような処理を画像のピクセル値に基づくベクトル演算により行います。
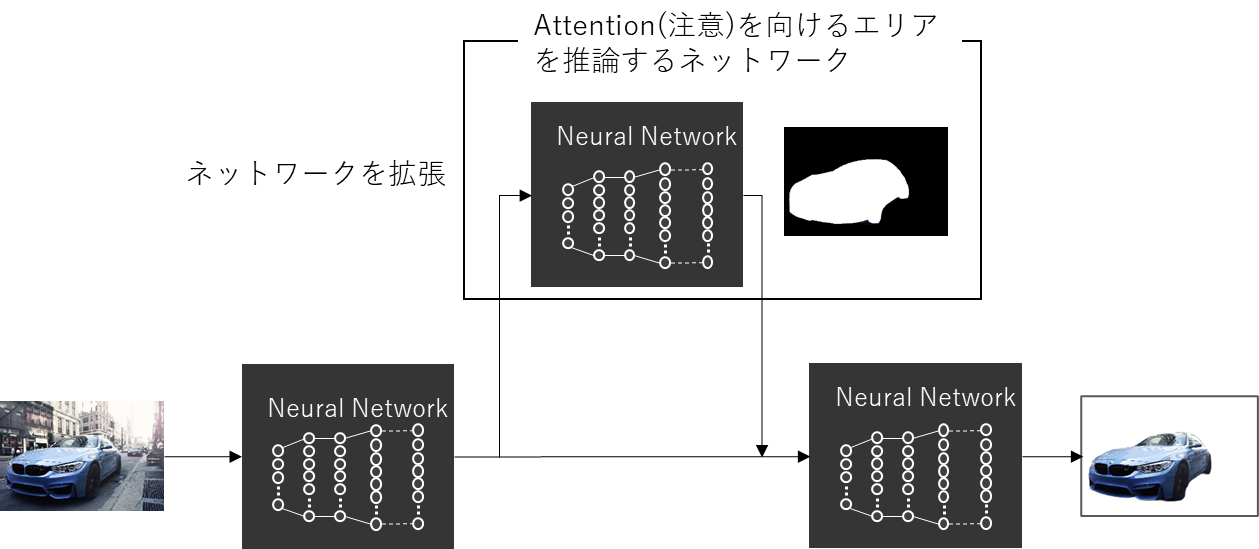
このAttentionは自然言語では入力された文章内の各単語間の関連性を把握するために使われています。単語間の関連性情報は文脈把握に非常に重要な特徴となり、このAttentionのおかげで、Transformerは精度の高い認識能力を発揮します。
下図のように、「日本で一番高い山」という文章が入力された場合にAttention機構がどのような処理を行っているのかを見ていきましょう。
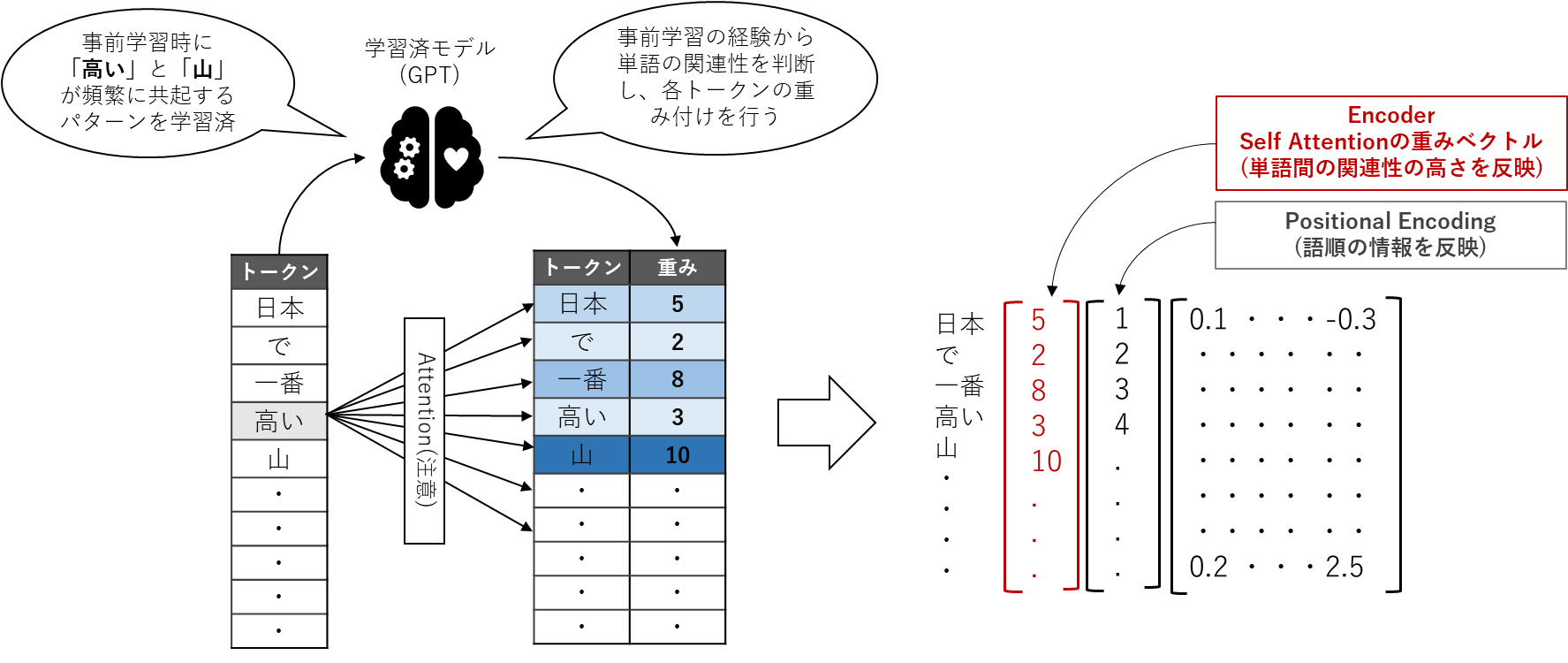
GPTは学習済モデルですから、大規模データで事前学習した際に、「高い」という単語と「山」という単語が非常に関連の高い単語同士であるということを既に理解しています。したがって、この二つの単語の重み付けを優先し「10」という大きな値を割り当てるイメージです。同じように入力された文章内の全ての単語に対して重み付けを行います。
そして、Attentionの前段階で得られたベクトルにAttentionで計算した重みベクトルを反映します。これにより、文脈把握のための重要な情報である単語間の関連性の特徴を数値データとして含め、更に言語認識が高くなるベクトルが作れたということになります。
その他、文法構造や、例えば「それ」が何を指すかなどの代名詞の関係もこのAttetion機構で把握しているそうです。
実際には、入力トークンのベクトルから、Key、Value、Queryと呼ばれる三つのベクトルを生成し、これらのベクトルを使って単語間の関連性の高さを計算する構造となっています。
Attention機構の非常に重要な構造なのですが、本記事の技術粒度に合わないので割愛させてください。インターネットを検索すると、専門家の方々が書かれている大変優良な記事が大量にありますのでそちらをご参照いただくといいと思います。
このようにして、入力された文章はEmbeddingで初期のベクトルに変換され後続の処理により、文章を認識するための様々な情報が付け加えられ、表情豊かなベクトルとなって出力され、これらのベクトルはデコーダー側へ入力されます。
デコーダー側の処理
ここからはデコーダー側の処理をみてゆきます。下図のようにデコーダー側にはメインの機構としてデコーダーがあります。エンコーダーから出力されたベクトルはデコーダー側に入力されます。エンコーダーから伸びた矢印がデコーダーの真ん中あたりに伸びている部分です。
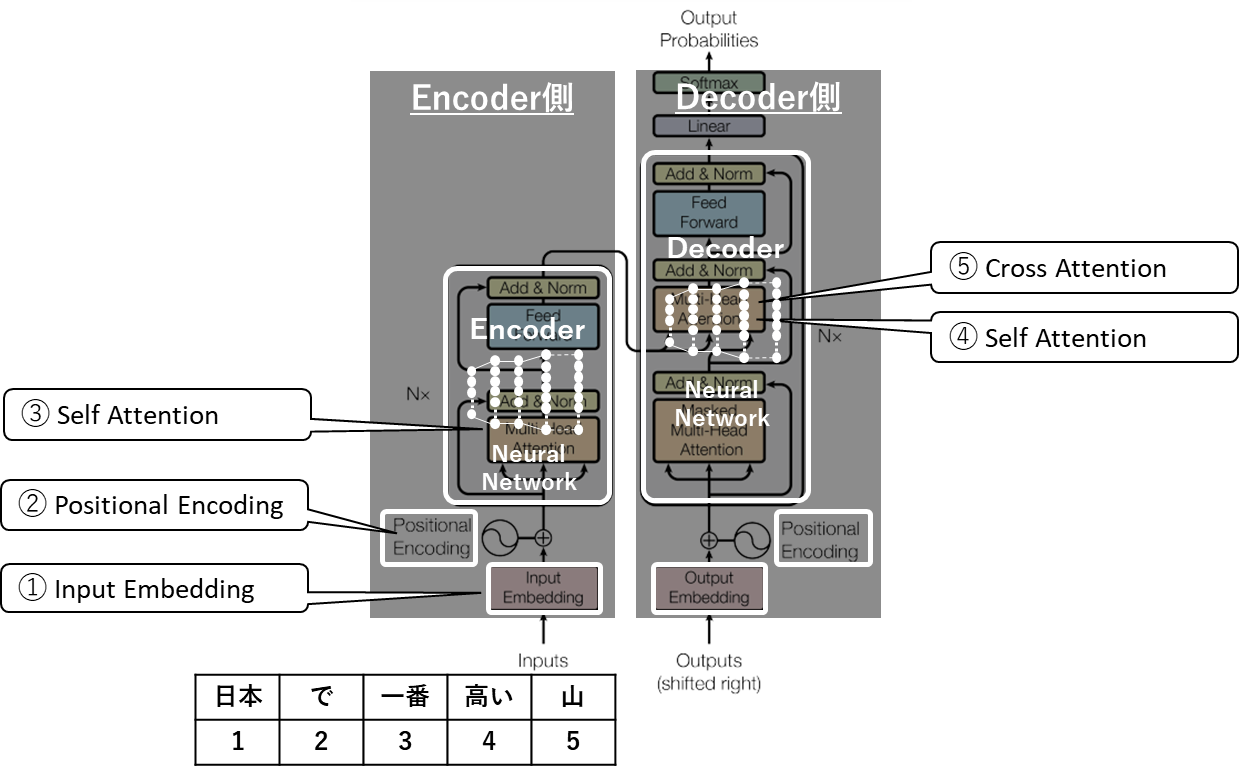
④デコーダーでのSelf Attention
エンコーダーからベクトルを受け取ったデコーダーは、エンコーダーと同じようにSelf Attentionの処理を行います。注意したいのは、エンコーダーとデコーダでSelf Attentionを行う目的が違うということです。
エンコーダーとデコーダーはそれぞれ課せられているタスクが異なります。エンコーダーは入力文全体の情報を把握できるようにエンコードするのに対して、デコーダーは文脈や依存関係を考慮して次の単語を生成する必要があります。
したがって、それぞれのタスクの目的に応じてSelf Attentionを行いますので、結果として、計算された重みのベクトルの値はエンコーダーとデコーダーで異なる可能性があります。

⑤デコーダーでのCross Attention
このように、デコーダーはエンコーダーとは別で独自にSelf Attentionを行います。ですが、やはり、エンコーダーが行ったSelf Attentionの結果も考慮したいため、Cross Attentionと呼ばれる別のタイプのAttentionの計算を行います。
下図のように、デコーダーとエンコーダーの両方のAttentionの結果を反映するような処理をし、このベクトルから最終的に出力候補となる単語とその確率分布を推論します。

実際には、確率分布は後続の処理(Softmax関数)で計算して出力しますが、cross attention処理の時点で出力候補のトークンは確定しています。
Attentionにはその他、Multi Head Self-Attention(Self Attentionの並列化処理)、Masked Self-Attention(一部のトークンをマスクするAttention)など、目的の処理に応じて元のAttentionに追加の工夫が入ったタイプがあり、TransformerではこれらのAttentionがふんだんに使われています。
長文を出力できる仕組み
ChatGPTを使うと、単語ではなくて、長文を出力してくれますが、これは上述した処理を下図のように繰り返すことにより、逐次生成された単語が最終的には長文となっているということになります。
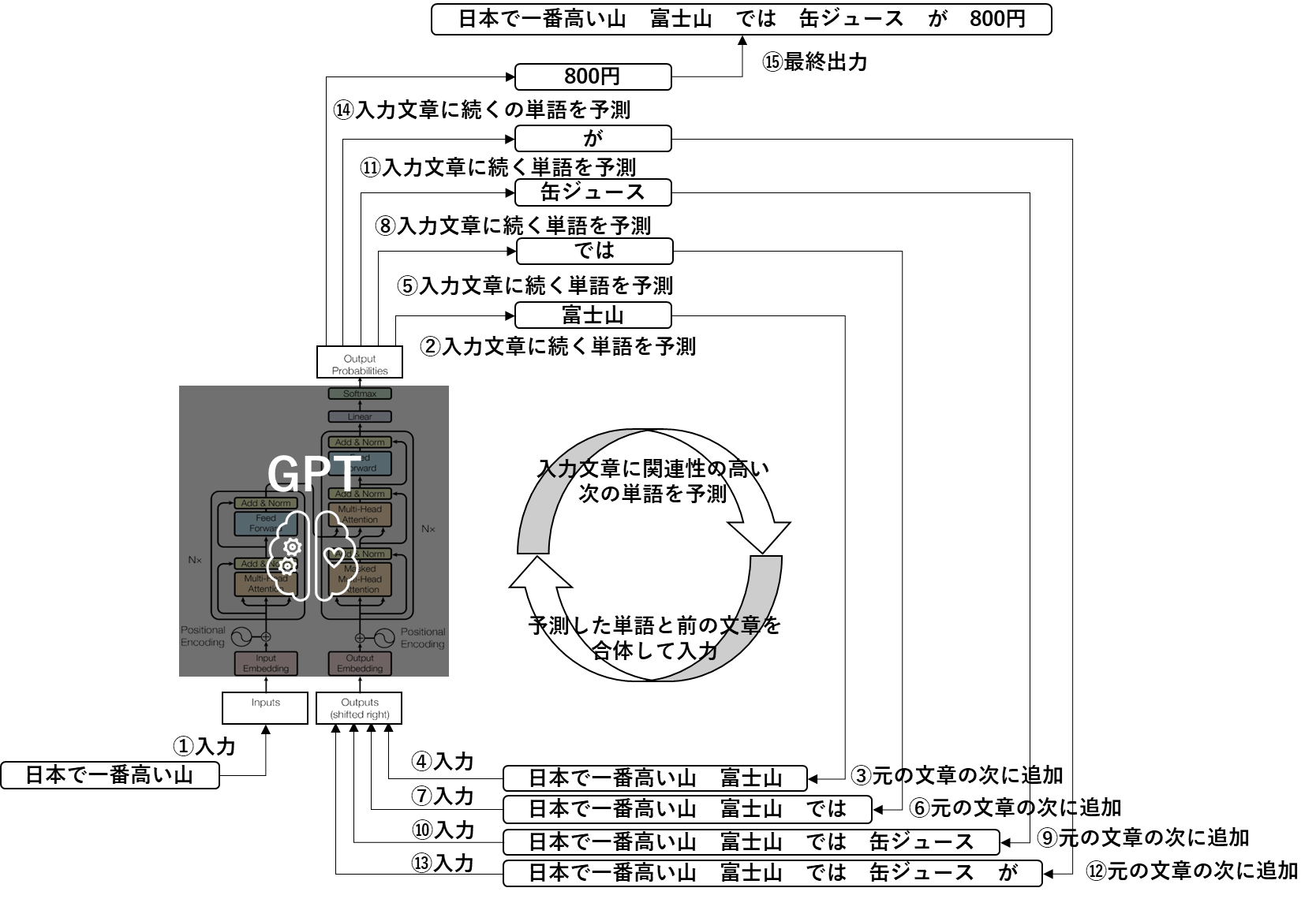
この図では、
①で最初に、「日本で一番高い山」と入力されています。
②そうするとGPTは学習済のモデルですから、この文章と関連性の高い単語は「富士山」だと推論して出力します。
③GPTは入力された文章の次に続く単語を予測するというモデルですよね。したがって、入力された文章である「日本で一番高い山」の続きに、予測した「富士山」という単語を追加して、「日本で一番高い山 富士山」という文章を作ります。
④そして、この追加された文章をまたGPTに入力します。
(文章をベクトル化するためEmbeddingと、語順エンコーディングのためののPositional Encodingもこの図のデコーダー側にはしっかりと入っています。。)
⑤GPTは新たに入力された文章「日本で一番高い山 富士山」の次に続く単語を予測します。
⑥、、、、ということを繰り返しているということになります。
(たしかにChatGPTの出力は全ての長文が一度に出力されるということはなく、文字や単語レベルで徐々に出力されます。人間が文字をタイプしているように見せているのだと思っていました。。。)
ChatGPT、Bardなど完成されたサービスを利用すると、言葉(単語、文法、表現)や様々な分野の知識を体得した、人間の頭脳のようなプログラムが、入力された質問を理解して、それに対して回答しているような印象を覚えますが、その要素技術のメインは、「入力された文章と関連性が最も高い単語の推論を、繰り返し行う」という処理を機械的に実行しているというものとなり、サービスを利用している人間が感じ、想像するものと比較して、実際には驚くほどシンプルな入出力の構造をしているということがわかります。
少しややこしいのですが、実はデコーダーでのSelf Attentionは二つのケースに分けて考える必要があります。初回文章が入力された後の、初回のデコーダーでのSelf Attentionは「文の始まり」を示す特殊なベクトルを出力します。この特殊なベクトルと、エンコーダーでのSelf Attentionの結果を参照し、cross attentionの処理から出力候補の単語ベクトルが生成されます。(つまり、上述の②の処理で「富士山」という単語はエンコーダーのSelf Attention計算結果とデコーダのSelf Attentionが出力する「文の始まり」を示す特殊なベクトルからCross Attentionで算出された結果)ですので、デコーダーでのSelf Attentionの章で説明した内容は実は二回目以降のイメージを図にしたものです。
さいごに
この記事を読まれている方が、自然言語のベクトル化の処理の雰囲気がどのようなものかを感じ取られていることを願います。非構造化データの中でも、画像データや音声データと比較してかなり複雑なベクトル化の手順を踏んでいることがお判りになるかと思います。自然言語の処理はこのように、私達初学者には一見不可解ともとれる処理が多数登場します。これをどう腹落ちさせるかは、その方々のバックグランドやナレッジに大きく依存しますが、一歩ひいて全体を俯瞰して見ると、見えてくるものがあると思います。
少し乱暴な解釈をすると、自然言語処理では上述して説明したように、文章認識に有効そうだと思われる特徴をとにかくニューラルネットワークに放り込みさえすれば、何かでてくるだろうという考えのもとに研究されているように思います。
そして、でてきたものをスコアリングして「総じてスコアが高ければその機構は有効だった」的な発想です。そこに必ずしも「なぜスコアがよくなったか」という理論は不要というのが、魔法の計算機であるニューラルネットワークなのだと思います。逆に言うと、ニューラルネットワークが優れているのは、特徴量があれば、その分布など確認しなくても、片っ端から、ネットワークに突っ込んでみて試してみるというアプローチがとれるという点で、特に非構造化データの機械学習ではこのメリットをフル活用しているんだなと感じました。
恐らく、深層学習の研究の過程では、あらゆる機構が試され、そのほとんどは効果がなく、生き残った機構だけがライブラリとして登場しているのでしょうから、初学者の方々はAttentionなどという機構が唐突に表れ、それが不可解なものと感じるのかもしれません。しかし、その裏で、膨大な研究を行っているであろう、ライブラリの開発者や研究者の方々には本当に尊敬の念を抱きます。