本記事は日本オラクルが運営する下記Meetupで発表予定の内容になります。発表までに今後、内容は予告なく変更される可能性があることをあらかじめご了承ください。
メダリオンアーキテクチャ
メダリオンアーキテクチャとは、2020年前後にDatabricksさん(だったと思う)が提唱したデータ変換処理フローの設計思想です。この周辺技術にあまり親しくないという方のために簡単に説明します。

メダリオンアーキテクチャとは、上図のようにデータを Bronze、Silver、Gold の3つのレイヤに分け、生データから品質を高めながら段階的にデータ変換し、Goldレイヤに近づくにつれて、ビジネスゴールを達成するための分析シナリオに直接利用できるデータへと洗練させていくアーキテクチャです。各レイヤでは主に以下のような処理が行われることになります。
-
Bronzeレイヤ
Bronzeは様々なアプリケーションから出力されるいわばログのようなデータで、言うなればビッグデータとほぼ同義です。データ収集後の後工程で、いざデータ分析処理を実行したときに、「〇〇のデータが足りない、、、」とか「〇〇のデータがあればもっと良い分析結果になったかも、、、」なんてことがよくあります。そうならないように、分析の現場では事前にあらゆるデータを収集しておくという方針がとられがちです。もっとありていに言うと、データ収集の時点ではデータの価値判断は行わずに何でもかんでも収集しておくということです。つまりBronzeレイヤでは何の取捨選択もされていない全部入りの生データを扱うということになります。 -
Silverレイヤ
Bronzeレイヤから一歩進んだSilverレイヤでは、後工程の分析処理を実行しやすくするために、データを整形する処理が中心に行われます。いわゆるデータのクレンジング処理で、正規化、欠損値の補填、データ型を定義したりと、様々な処理が行われます。端的に言うと、「データのかたちを整形し、品質を担保した“統一された構造化データ”にするフェーズ」です。 -
Goldレイヤ
そして、Goldレイヤーで「用途・目的別に意味付けされ、すぐに使える形に加工されたデータ」を作ることになります。わかりやすいところでいうと、DWHやビジネスインテリジェンスでいうところの、日次・月次・年次の集計処理、粒度変更(例:明細 → 店舗別 → 地域別)、ピボット(行→列)などの処理です。
つまり「メダリオンアーキテクチャ」という大層な名前がつけられていますが、本質的には何も新しいことはありません。データウェアハウス、ビジネスインテリジェンス、機械学習などの分析処理を行っているエンジニアであれば特に意識せず昔から当たり前のようにやっている処理ということになります。
Oracle Cloud Infrastructureでの構成例
このアーキテクチャの分析システムをOracle Cloud Infrastructureで構成する一例が下図のようなデザインパターンです。
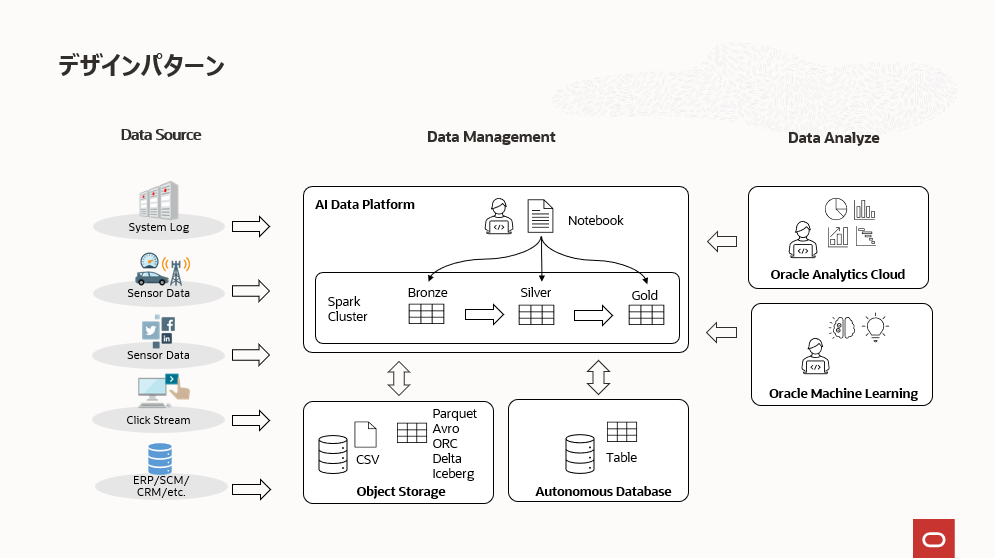
Data Sourceにある既存の業務システムから発生したデータをData Managementにある、AI Data PlatformのSpark Clusterで処理します。上述したメダリオンアーキテクチャに沿って、データをBronze、Silver、Goldに変換する処理です。
これらのデータは必要に応じてオブジェクトストレージやRDB(上図ではAutonomous Database)に永続化します。出来がったデータを分析するData AnalyzeのフェーズではBIツールや機械学習ツールを配置し、そこからGoldデータを分析するという典型的なデータマネージメントのプラットフォームです。
このデザインパターンで利用される各サービスの概要は以下の通り。
- AI Data Platform(AIDP)
Apache Sparkを中心とした分散処理基盤をPaaSとして提供しているサービスです。Sparkだけでなく、ノートブック機能、カタログ機能、ワークフローやジョブ定義機能、ユーザー管理機能、監査ログ機能、AIエージェント開発のローコードツールなど、様々な機能が統合されています。同サービスの詳細は別の記事「Oracle AI Data Platform サービスのエッセンスをクイック・レビュー」をご参照ください。 - Object Storage
このデザインパターンの中ではデータレイクハウスとして非構造化データおよび準構造化データの永続化先データストアとなります。AI Data Platformで処理するデータをオブジェクトストレージから読み込んだり、処理したデータをオブジェクトストレージに永続化する目的で構成します。 - Autonomous AI Database(ADB)
このデザインパターンの中ではデータレイクハウスとして非構造化データの永続化先データストアとなります。オブジェクトストレージ同様に、AI Data Platformで処理するデータをAutonomous AI Databaseから読み込んだり、処理したデータをAutonomous AI Databaseに永続化する目的で構成します。 - Oracle Analytics Cloud(OAC)
BIツールとして利用します。Oracle Analytics CloudからAIDPに接続することで、AIDP上のカタログが利用できるため、AIDPで管理している全てのデータにアクセス・分析できます。 - Oracle Machine Learning(OML)
機械学習ツールとして利用します。上図では独立したサービスのように見えますが、実際にはOracle Machine LearningはAutonomous AI Databaseの一機能になります。従って、GoldデータをADBに永続化した場合、機械学習もデータベースの中でそのまま実行することができるようになります。また、ADBにはAutoML UIと呼んでいるローコードの機械学習ツールや、ノートブック環境もありますので基本的な機械学習処理はADB一つで全てこなせます。ADBのAutoML UIの詳細については別記事「Autonomous Database かんたん機械学習」をご参照ください。
プロビジョニング
まず最初にこのデザインパターンにある、サービスのインスタンスを作成し、メダリオンアーキテクチャの各処理を実行できる状態にします。
大まかな手順としては下記3ステップです。
- Autonomous AI Database インスタンスを作成し、DBユーザーを作成する
- AI Data Platform インスタンスを作成する
- AI Data Platform インスタンスにAutonomous AI Databaseのカタログを作成する
- AI Data Platform インスタンスにCompute(Spark Cluster)を構成する
Autonomous AI Database インスタンスを作成する
最終的なGoldデータを保持するデータベースとしてまずはAutonomous AI Database インスタンスの作成します
下記の順にメニューを辿ります。
OCIの左上メニューバー → Oracle AI Database → Autonomous AI Database

Autonomous AI Databaseの詳細画面に移動しますので、そこで下図のボタンをクリックします。
インスタンス作成に必要な下記情報を入力してゆきます。
ワークロード・タイプはレイクハウスもしくはトランザクション処理のどちらかを選択します。

データベースのバージョンは19cを選択します。(2025年11月現在 26ai はAIDPでは未サポートとなっており近日中に対応予定です。)
ストレージ容量は任意のサイズで大丈夫です。

下記についてはデフォルトを選択します。

ネットワークについては「全ての場所からセキュア・アクセス」を選択します。

連絡先としてメールアドレスを入力し、作成ボタンをクリックします。

数分後に下記のように Autonomous AI Databaseインスタンスが作成され使用可能な状態になります。

AI Data Platformインスタンスを作成する
次にAIDPインスタンスを作成します。
下記の順にメニューを辿ります。OCIの左上メニューバー → アナリティクスとAI → AIデータ・プラットフォーム
ADIPの画面に移動しますので、下図のボタンをクリックします。

AIDPインすんタスの作成に必要な情報を入力します。
AI Data Platform nameおよびworkspace nameに任意の名前を入力し、Createボタンをクリックします。

約十数分後に下図のようにAIDPインスタンスの作成が完了し、リストされます。作成したインスタンスをクリックします。
下図のように作成したAIDPインスタンスの詳細画面が表示されます。

上図左が操作メニューになります。
以前の記事「Oracle AI Data Platform サービスのエッセンスをクイック・レビュー」で一通りご紹介したAIDPの様々な機能をここから設定します。
上図中央のRecentがAIDP上で最近設定したオブジェクトへのリンクです。インスタンス作成後、初めてログインした際にはまだ何も操作していないのでこの部分は表示されません。
上図右にはマニュアルへのリンク、サンプルコードのダウンロードリンクや、典型的な処理設定へのリンクなどです。特に初めて使う場合はサンプルコードは必読となります。
作成したADBをAIDPにカタログ化する
AIDPのインスタンスが作成できたので、ADBをAIDPのカタログに登録します。
下記の順にメニューを辿ります。
Create → Catalog

下図のようにカタログを作成するためのウィザードが表示されますので必要な情報を入力します。以下重要な部分を説明します。

まず、今回はADBをカタログ化しますので、CatalogタイプはExternal Catalogを選択します。そして、Source typeでOracle Autonomous Data Warehouseを選択します。
そして、External Source methodはChoose ADW instanceの方を選択するとわかりやすいと思います。
Tenant OCIDを入力すると、以降の項目はADWインスタンスの選択まで、選択可能な項目が全てプルダウンメニューに表示されますので目的のものを選択するだけです。このあたり、非常に使い勝手がいいと感じます。
更に、下図のように、DBユーザー名とパスワードを入力し、Test connectionボタンをクリックします。

AIDPインスタンスと指定したADBインスタンスの接続に問題がなければ下図のように Connection Status Successfulと出力されます。ここでCreateボタンをクリックします。

下図の赤枠のようにADWインスタンスや、DBユーザーがExternalカタログとして、AIDPにカタログ化されたことがわかります。
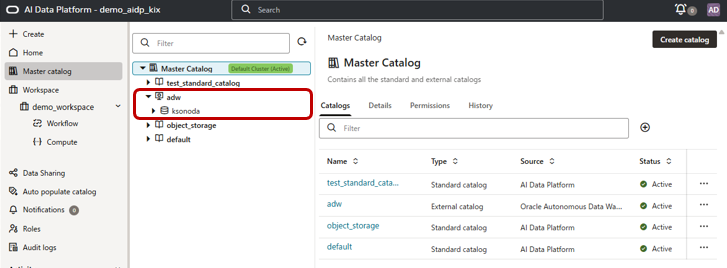
ここまででADWのカタログ化が完了しました。このADWのカタログ情報は後ほどGoldデータをロードする際に利用します。
Compute(Spark Cluster)を構成する
次に、AIDPでSparkアプリケーションを実行するためのSpark Clusterを作ります。
下記の順にメニューを辿ります。
Create → Compute

下図のように、Spark Cluster作成のウィザードが表示されますので必要な情報を入力します。

現在、Runtime versionはSpark 3.5.0のみが選択可能です。そして、SparkのDriverノードとWorkerノードのリソースを設定します。CPUタイプ、コア数、メモリサイズをしています。
(Quickstartは初めからリソースサイズが決まっているので、それが要件に合わない場合は、Customを選びます。)
下図のように、AIDPではDriverノードは1ノード固定です。Workerのみ、ノード数が指定できます。(ノード数は固定か、オートスケールのどちらかを選択可能です。)

RundurationでFoever(常時起動)か、idle timeout(指定の分数で自動停止)のどちらかを選択できます。
これらを設定してCreateボタンをクリックすると、下図のように15分ほどでCompute(Spark Cluster)のマネージドインスタンスが起動し、Activeとなります。
Spark Clusterが利用できるようになりましたのでノートブックを作成し、コードの実行準備を行います。
ノートブックを作成し、Compute(Spark Cluster)にアタッチする
次に、Sparkアプリを開発するためにノートブックを作成します。
下記の順にメニューを辿ります。
Create → Notebook

下図のようにノートブックに任意の名前を付け、説明(オプション)を記載し、Createボタンをクリックします。

すると下図のようにノートブックが作成されますので、ここにコードを書いて実行してゆきます。

ですが、コードを書く前に、このノートブックをSpark Clusterにアタッチしないとコードが実行できませんのでその設定を行います。
Cluster → Attach existing cluster → <作成済のクラスタを選択>

これでノートブックのコードを実行できるようになりました。
ここまでくるとあとはもうほとんどApache Sparkの世界です。
シンプルなメダリオンアーキテクチャを実行してみる
基本的なプロビジョニングが完了したので、実際にメダリオンアーキテクチャの簡単なデータ処理を実行してみます。下図の①、②、③の処理になります。

処理概要としては下記4ステップになります。
- Bronzeデータの作成:オブジェクトストレージ上のCSVファイルをAIDPのCompute(Spark Cluster)に読み込み、Bronzeデータを作成します
- Silver、Goldデータの作成:Bronzeデータにデータ変換処理を行いSilverデータを作成し、更にSilverデータにデータ変換処理を行い、Goldデータを作成します
- GoldデータをADBやオブジェクトストレージに永続化します
- BIツールや機械学習ツールからAIDPのSpark Clusterに接続し、Goldデータを分析します
Bronze データの作成
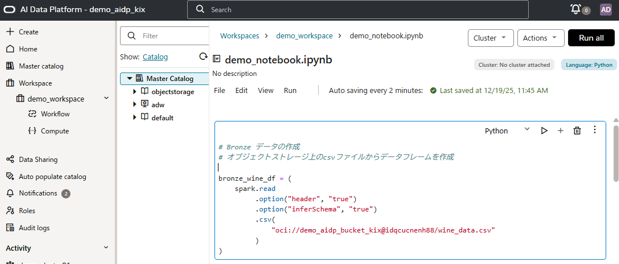
ここでのBronzeデーは、オブジェクトストレージに配置したcsvファイルをSparkに読み込んだデータフレームというシンプルなものです。PySparkの下記コードでcsvファイルを読み込みます。
# オブジェクトストレージ上のcsvファイルからデータフレームを作成
bronze_wine_df = (
spark.read
.option("header", "true")
.option("inferSchema", "true")
.csv("oci://demo_aidp_bucket_kix@idqcucnenh88/wine_data.csv")
)
AIDPで作成したCompute(Spark Cluster)にはOCI HDFS Connectorと呼んでいるモジュールが既に組み込まれており、これにより、SparkからOCI Object Storage上のネームスペースを直接指定・認識させることができます。上記コードの"oci://demo_aidp_bucket_kix@idqcucnenh88/wine_data.csv"の部分です。下記のような文法でオブジェクトストレージ上のファイルへのパスを指定しSparkからアクセスすることができます。
oci:/<バケット名>@<テナント名>/<ディレクトリ名>/<ファイル名>
下図のように上記コードをAIDPのノートブックで実行します。
このデータフレームの中身を確認します。
# データフレームの最初の5行を表示
bronze_wine_df.show(5, False)
+-----------+-------+----------+----+-----------------+---------+-------------+----------+--------------------+---------------+---------------+----+----------------------------+-------+
|class_label|alcohol|malic_acid|ash |alcalinity_of_ash|magnesium|total_phenols|flavanoids|nonflavanoid_phenols|proanthocyanins|color_intensity|hue |OD280_OD315_of_diluted_wines|proline|
+-----------+-------+----------+----+-----------------+---------+-------------+----------+--------------------+---------------+---------------+----+----------------------------+-------+
|1 |14.23 |1.71 |2.43|15.6 |127 |2.8 |3.06 |0.28 |2.29 |5.64 |1.04|3.92 |1065 |
|1 |13.2 |1.78 |2.14|11.2 |100 |2.65 |2.76 |0.26 |1.28 |4.38 |1.05|3.4 |1050 |
|1 |13.16 |2.36 |2.67|18.6 |101 |2.8 |3.24 |0.3 |2.81 |5.68 |1.03|3.17 |1185 |
|1 |14.37 |1.95 |2.5 |16.8 |113 |3.85 |3.49 |0.24 |2.18 |7.8 |0.86|3.45 |1480 |
|1 |13.24 |2.59 |2.87|21.0 |118 |2.8 |2.69 |0.39 |1.82 |4.32 |1.04|2.93 |735 |
+-----------+-------+----------+----+-----------------+---------+-------------+----------+--------------------+---------------+---------------+----+----------------------------+-------+
only showing top 5 rows
CSVファイルのデータがデータフレームとしてロードされていることが確認できました。
AIDPのノートブックで実行した画面は下図のようになります。

ちなみに、コード実行後、下図の赤枠のViewをクリックするとこの処理過程をSparkUIで確認することができます。
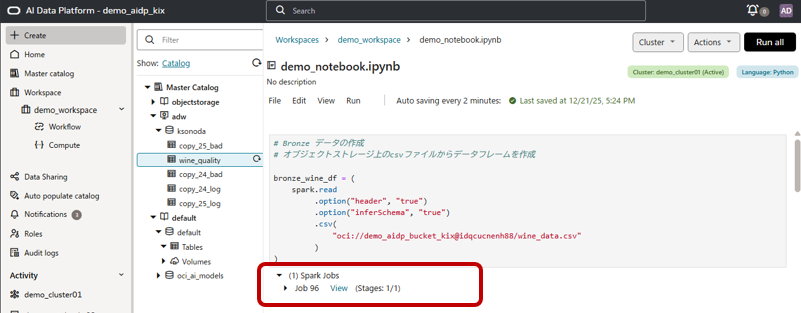
下図のような感じです。

このような調子でどんどんコードを実行してゆきます。
以降はAIDPの画面は最小限にしてPySparkのコードを中心に説明します。
上記で作成したデータフレームがいわゆるBronzeデータです。このシナリオでは、いろんなワインのあらゆる成分データがただ単純に集められており、分析のための前処理が全くされていない、生データということになります。
Silver データの作成
次に、上述のBronzeデータをSilverデータに変換してゆきます。
冒頭で説明したとおり、Silverレイヤではデータを整形するためのデータ操作の処理が中心になります。イメージしやすいように処理例を挙げるとすると
- データクレンジング:NULLや空文字の補正・除外、異常値の除去、重複レコードの排除など
- 型変換・正規化:文字列 "2025-01-01" → DATE 型、数値が文字列で入っている列を数値型に変換、単位の統一(円 / ドル、秒 / ミリ秒)など
- 構造の整理:JSON / ネスト構造を列に展開、配列データを行に展開、不要なカラムの削除、複数データの結合など
などです。上述した例はごく一部でその他様々な処理があります。もともとのbronzeの生データが不揃いで全く整形されていない場合、このレイヤで様々な処理を行う必要があり往々にして大仕事になります。
本記事では上述の様々な処理を理解することが目的ではないので、簡単な処理例のコードで Silverデータを作るシナリオとします。
例えばカラム名の正規化をする場合は下記のようなコードを実行します
(※ このケースでは ほぼ既に正規化済みなので、結果としては大文字→小文字変換のみ。)
# カラム名の正規化
from pyspark.sql.functions import col
silver_wine_df = (
bronze_wine_df
.withColumnRenamed("class_label", "class_label")
.withColumnRenamed("alcohol", "alcohol")
.withColumnRenamed("malic_acid", "malic_acid")
.withColumnRenamed("ash", "ash")
.withColumnRenamed("alcalinity_of_ash", "alcalinity_of_ash")
.withColumnRenamed("magnesium", "magnesium")
.withColumnRenamed("total_phenols", "total_phenols")
.withColumnRenamed("flavanoids", "flavanoids")
.withColumnRenamed("nonflavanoid_phenols", "nonflavanoid_phenols")
.withColumnRenamed("proanthocyanins", "proanthocyanins")
.withColumnRenamed("color_intensity", "color_intensity")
.withColumnRenamed("hue", "hue")
.withColumnRenamed(
"OD280_OD315_of_diluted_wines",
"od280_od315_of_diluted_wines"
)
.withColumnRenamed("proline", "proline")
)
次に、型安全のために、型の正規化をしてみます。
# 型の正規化
from pyspark.sql.types import IntegerType, DoubleType
silver_wine_df = (
silver_wine_df
.withColumn("class_label", col("class_label").cast(IntegerType()))
.withColumn("alcohol", col("alcohol").cast(DoubleType()))
.withColumn("malic_acid", col("malic_acid").cast(DoubleType()))
.withColumn("ash", col("ash").cast(DoubleType()))
.withColumn("alcalinity_of_ash", col("alcalinity_of_ash").cast(DoubleType()))
.withColumn("magnesium", col("magnesium").cast(DoubleType()))
.withColumn("total_phenols", col("total_phenols").cast(DoubleType()))
.withColumn("flavanoids", col("flavanoids").cast(DoubleType()))
.withColumn("nonflavanoid_phenols", col("nonflavanoid_phenols").cast(DoubleType()))
.withColumn("proanthocyanins", col("proanthocyanins").cast(DoubleType()))
.withColumn("color_intensity", col("color_intensity").cast(DoubleType()))
.withColumn("hue", col("hue").cast(DoubleType()))
.withColumn(
"od280_od315_of_diluted_wines",
col("od280_od315_of_diluted_wines").cast(DoubleType())
)
.withColumn("proline", col("proline").cast(DoubleType()))
)
次に異常値の削除(NULL値の削除)をしてみます。
# 異常値の削除(NULL値の削除)
silver_wine_df = (
silver_wine_df
.dropna()
.filter(col("alcohol") > 0)
.filter(col("proline") > 0)
)
このように、Silverレイヤはデータの中身にはあまりフォーカスせずに、データの形を整えてゆくような処理イメージです。
出来上がったSilverデータの中身を見てみましょう。(と言っても、この例ではbronzeデータからの変更は殆どありません。)
silver_wine_df.show(5)
+-----------+-------+----------+----+-----------------+---------+-------------+----------+--------------------+---------------+---------------+----+----------------------------+-------+
|class_label|alcohol|malic_acid| ash|alcalinity_of_ash|magnesium|total_phenols|flavanoids|nonflavanoid_phenols|proanthocyanins|color_intensity| hue|od280_od315_of_diluted_wines|proline|
+-----------+-------+----------+----+-----------------+---------+-------------+----------+--------------------+---------------+---------------+----+----------------------------+-------+
| 1| 14.23| 1.71|2.43| 15.6| 127.0| 2.8| 3.06| 0.28| 2.29| 5.64|1.04| 3.92| 1065.0|
| 1| 13.2| 1.78|2.14| 11.2| 100.0| 2.65| 2.76| 0.26| 1.28| 4.38|1.05| 3.4| 1050.0|
| 1| 13.16| 2.36|2.67| 18.6| 101.0| 2.8| 3.24| 0.3| 2.81| 5.68|1.03| 3.17| 1185.0|
| 1| 14.37| 1.95| 2.5| 16.8| 113.0| 3.85| 3.49| 0.24| 2.18| 7.8|0.86| 3.45| 1480.0|
| 1| 13.24| 2.59|2.87| 21.0| 118.0| 2.8| 2.69| 0.39| 1.82| 4.32|1.04| 2.93| 735.0|
+-----------+-------+----------+----+-----------------+---------+-------------+----------+--------------------+---------------+---------------+----+----------------------------+-------+
only showing top 5 rows
以上でSilverデータが作成できました。
Goldデータの作成
整形されたSilverデータから、最終的な分析用途のデータであるGoldデータを作成します。
例えば、以降の処理ではワインの品質を分析するための簡単なデータの前処理を実行しています。
# Goldデータの作成
# 事前にseabornとmatplotlibをSpark Clusterにインストール
# 特徴量の総関係数の確認ー>機械学習用の特徴量テーブルの作成(ML向け)
import seaborn as sns
import matplotlib.pyplot as plt
# Spark DataFrame を Pandas に変換
pdf = silver_wine_df.toPandas()
# 数値列の相関行列を計算
corr = pdf.corr(numeric_only=True)
# ヒートマップを描画
plt.figure(figsize=(12, 10))
sns.heatmap(corr, annot=True, fmt=".2f", cmap="coolwarm")
plt.title("Correlation Heatmap of silver_wine_df", fontsize=16)
plt.show()

各列同士の相関係数が確認できたので、ワインの品質情報であるclass_label との相関関係が 0.7 以上の列だけをフィルタリングし作ったデータをGoldデータとしてみます。
from pyspark.sql.types import NumericType
# 相関を見る対象列(数値列のみ、class_label自身は除外)
numeric_cols = [
f.name for f in silver_wine_df.schema.fields
if isinstance(f.dataType, NumericType) and f.name != "class_label"
]
# class_label との相関係数を計算
corr_dict = {
col: silver_wine_df.stat.corr("class_label", col)
for col in numeric_cols
}
# 相関係数の絶対値が 0.7 以上の列を抽出
selected_cols = [
col for col, corr in corr_dict.items()
if corr is not None and abs(corr) >= 0.7
]
# class_label を含めて DataFrame を作成
gold_wine_df = silver_wine_df.select(["class_label"] + selected_cols)
# 確認
gold_wine_df.show(5)
+-----------+-------------+----------+----------------------------+
|class_label|total_phenols|flavanoids|od280_od315_of_diluted_wines|
+-----------+-------------+----------+----------------------------+
| 1| 2.8| 3.06| 3.92|
| 1| 2.65| 2.76| 3.4|
| 1| 2.8| 3.24| 3.17|
| 1| 3.85| 3.49| 3.45|
| 1| 2.8| 2.69| 2.93|
+-----------+-------------+----------+----------------------------+
only showing top 5 rows
GoldデータをオブジェクトストレージやADBに永続化する
下記コードで、作成したGoldデータをオブジェクトストレージに永続化します。
gold_wine_df.write \
.mode("overwrite") \
.format("delta") \
.save("oci://<バケット名>@<テナンシー名>/wine_clean")
上記の例ではwine_cleanという名前でdeltaフォーマットでファイルを保存しています。ファイルフォーマットは必要に応じて、parquet/avro/orc/csv/icebergなどが選択可能です。
対象のバケットを確認すると下記の通りdeltaフォーマットでGoldデータが永続化されていることが確認できます。

ADBに永続化する場合は下記のコードになります。(表名はwine_quality)
# goldデータをADWにロード(表明はgold_wine)
gold_wine_df.write.mode("overwrite").saveAsTable("adw.ksonoda.wine_quality")
すると下図のようにADBのSQLツールからwine_qualityという名前の表が作成されていることが確認できます。
下図左ペインにwine_qualityの表と列名が表示されており、右上ペインで、その表に対してselect文を実行し、右下ペインにそのクエリ結果が表示されていることが確認できます。

このADBは、AIDPではExternal Catalogとして登録されました。External Catalogの場合、データのライフサイクルは、AIDPではなくデータソース側(ADB側)で行われます。上述のコードでAIDPからデータをADWに書き込みましたが、書き込む処理はADB側で行われていますので、このメタデータは自動的にはAIDPに同期されません。
そこで、下図のようにAIDP側からメタデータをADBに収集(同期)する処理が必要になります。具体的にはカタログ内のスキーマの右にある丸い矢印をクリックすることで同期処理が実行されます。

同期が完了すると、先ほど作成したwine_quality表が下図のようにカタログに表示されます。

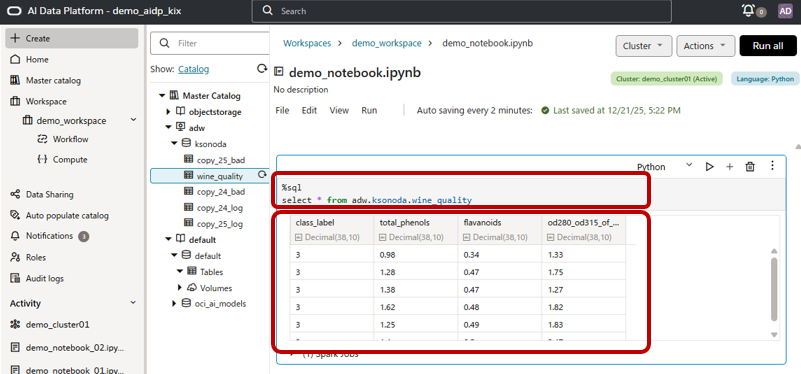
このカタログ情報を使うことで、AIDPからADWに下記のようなシンプルなコードでクエリを実行することができます。
%sql
select * from adw.ksonoda.wine_quality
AIDPのコンソールで確認すると下記のようにADWへのクエリ結果が表示されていることがわかります。
このカタログ情報がないと、同じ結果を得るために、connectionオブジェクトを作成して、DBに接続して、カーソルをとって、クエリを投げて、カーソルの出力をフェッチして、、、というような煩雑コードを書くことになります。
BIツール(Oracle Analytics Cloud)からGoldデータを使ってみる
Goldデータが出来上がったので、BIツールからこのデータにアクセスしてみたいと思います。様々なBIツールからAIDPのCompute(Spark Cluster)に接続できますが、今回はOracle Analytics Cloudを使ってみたいと思います。
下図の④の処理になります。
まずは、BIツールからAIDPに接続するための接続情報を取得する必要があり、そのページに移動します。
下図のように、AIDPの画面から Compute → <対象のクラスタ> をクリック。

クラスターの詳細画面でConnection detailsを選択。

BIツールの選択画面からOracle Analytics Cloudをクリック。

すると、AIDPへの接続情報が入ったconfig.jsonファイルがローカルにダウンロードされます。
このファイルの中身は下記のようなもので、ユーザー、テナンシー、リージョン、APIキーのフィンガープリントに加えて、AIDPインスタンスのocidと、その中のクラスタへの接続情報が記載されています。

{
"username":"ocid1.user.oc1..xxxxxxxxxxxxxxxxxxxxx",
"tenancy": "ocid1.tenancy.oc1..xxxxxxxxxxxxxxxxxxxxx",
"region": "ap-osaka-1",
"fingerprint": "23:c9:e1:20:bc:70:7b:52:d4:xxxxxxxxxxxxxxxxxxxxx",
"dsn": "jdbc:spark://gateway.aidp.ap-osaka-1.oci.oraclecloud.com/default;SparkServerType=IDL;httpPath=cliservice/xxxxxxxxxxxxxxxxxxxxx",
"idl-ocid": "ocid1.aidataplatform.oc1.ap-osaka-1.xxxxxxxxxxxxxxxxxxxxx"
}
上記 config.jsonファイルとAPIキーをOracle Analytics Cloudに設定すれば、AIDPに接続できるようになります。手順としては、下図のようにアナリティクスクラウドのページに移動します。

アナリティクスクラウドでインスタンスの作成ボタンをクリックし、インスタンスの作成を行うウィザードにはいります。

任意の名前と説明、コンパートメント、容量タイプを選択します。

その他の項目も選択しますが、基本はデフォルトで大丈夫です。作成ボタンをクリック。

およそ10分ほどでインスタンス作成が完了し、下図のようにリストされます。このインスタンスをクリックし詳細画面に移動します。

インスタンスの詳細画面から、分析ホームページのボタンをクリックすると、このインスタンスのツールの画面に移動できます。

下図が、分析画面になります。ここからAIDPへの接続を設定します。まず右上の create メニューから connectionをクリックします。

リストの中からOracle AI Data Platformをクリックします。

接続情報を入力する画面が表示されます。下図赤枠の connection detailsにダウンロードした config.jsonファイルを指定すると、その内容が画面に反映されます。private api keyの項目にAPIキーの秘密鍵のファイルを指定し、その他の必須項目を埋めれば設定完了です。saveボタンをクリックすることでAIDPへの接続設定が出来上がります。

ここからAIDPで定義したGoldデータをアナリティクスクラウドのデータセットとして登録する設定です。CreateメニューからDatasetをクリックします。

前段階で作成した接続設定(下図ではdemo_aidp_kix)をクリックします。

下図のような画面に遷移し、アナリティクスクラウドからAIDPに接続した状態になっています。左ペインのスキーマを展開すると、defaultスキーマの中に、AIDPの外部表として定義した wine_quality が表示されていることがわかります。

このwine_qualityをダブルクリックすると右ペインにデータの状態がビジュアライズされ、ここでデータの編集ができます。今回はアナリティクスクラウドの操作はせずに、これをそのままデータセットとして保存してみます。右上赤枠ンのフロッピーディスクのマークをクリック。

任意の名前を付けてデータセットとして保存します。

保存ができると左上のNew Datasetが指定したデータセット名に変わります。このデータセットをワークブックで編集したい場合は右上のCreate Workbookボタンをクリックします。

New Workbookの画面に遷移しますので、ここで先ほど作成したデータセット wine_quality を選択します。

下図のようにワークブックが実行できるようになり、左ペインに選択したデータセットが表示されていることがわかります。

ここから、データセットの必要な列をダブルクリックし、下図のように様々なBIの分析ができるようになります。

必要な分析が完了すれば、右上のフロッピーディスクのマークからこのワークブックに名前を付けて保存することができます。
ADBでGoldデータを使い、機械学習を実行してみる
ADBにロードされたGoldデータを使った機械学習を実行する場合、ADBのAutoML UIがお勧めです。AutoML UIはADBの表に対してWebUIから機械学習を実行するローコードツールです。ノートブックも使えますのでコーディングベースの機械学習も可能です。
下記の記事ではADBの表に対して、AutoML UIやノートブックで機械学習を実行する動画を掲載していますのでご興味のある方はご参照ください。
さいごに
今回はSparkでよく実行する典型的なデータ処理を記事にしてみました。もちろん様々な機能を持ったAIDPのごく一例になります。皆様が普段運用されている業務システムの処理とは比較にならないほどシンプルな処理例ですが、その処理内容ではなくどちらかというとAIDPの操作感と、各サービスとの連携方法がご参考になると幸いです。
特に、このようなビッグデータ系の処理を扱う場合、様々なサービスを連携させる必要がでてきますが、それらは意外と複雑だったり、各サービス特有の仕様のラーニングコストが高い場合が多いです。
AIDPではそのようなことがないように、主要な機能をなるべくこのサービス一つに統合し、かつ非常にわかりやすいインタフェースで構築できる点が最大の魅力となります。
また、現在はAIDPのBETA機能ですが、AIエージェントのローコード開発ツール(AI Agent Flows)も間もなくリリースされますので、同サービスの今後に是非ご期待ください。