本記事は日本オラクルが運営する下記Meetupで発表予定の内容になります。発表までに今後、内容は予告なく変更される可能性があることをあらかじめご了承ください。
はじめに

機械学習やAIが業務アプリケーションに組み込まれるようになって久しく、今や多くの企業が当たり前のようにAIを活用する時代になりました。しかしその一方で、より高度で利便性の高いアプリケーションを支えるためには、開発環境の整備だけでなく、それらのアプリケーションが参照する多種多様なデータを一元的かつ網羅的に管理できる基盤が強く求められています。こうしたニーズに応える形で登場したのが Oracle AI Data Platform Service(AIDP) です。このサービスは、「アプリケーションの開発環境」と「データ管理基盤」を統合的に提供し、企業がAIを安全・効率的に活用できるようにする新しいプラットフォームとしてリリースされました。本記事ではリリース間もないこのAIDPのエッセンスをまとめてご紹介します。
Oracle AI Data Platform Service 製品概要
本サービスは、アプリケーション開発、そしてその開発に利用するデータの一元管理に必要な機能を、統合的に提供することを目的としたクラウドサービスです。複数の基盤やツールを個別に用意することなく、アプリケーションの設計・実装からデータ管理、運用までをワンストップで行える点が特徴です。

本サービスが提供する主な機能
本サービスには、アプリケーション開発とデータ管理を支えるための、さまざまな機能が含まれています。
- アプリケーション開発環境
- 分散処理基盤
- メタデータ管理
- ワークフロー
- ユーザー管理・アクセス権管理
- 監査ログ
- 他社ユーザーとのセキュアなデータ共有
- 他サービスとの連携
- 生成AIアプリケーション開発用の Studio(coming soon)
アプリケーションの実行を支える分散処理基盤には Apache Spark を採用しており、Oracle Cloud が提供するその他のサービスと組み合わせることで、構造化データ・非構造化データ・ストリーミングデータを含む、あらゆるデータ処理とデータ管理を統合的に運用することができます。
直感的に操作できるインタフェース
ユーザーは、シンプルかつ直感的にわかりやすいインタフェースを通じて、本サービスの各機能を操作できます。大規模なデータ処理からアプリケーション管理、アクセス権設定まで、複雑な管理作業を負担なく実行できるように設計されています。
幅広いユースケースに対応
本サービスは、以下のような多様なユースケースをサポートします。
- AIアプリケーション
- 機械学習
- データ分析
- ビジネスインテリジェンス
- データウェアハウス
- 業務バッチ処理
- ETL
- ストリーミング処理
アプリケーション開発とデータ管理を統合的に扱えるため、あらゆる開発・分析ワークロードにおいてスムーズな運用を実現できます。
AIDPの構成要素
現在のAIDPの構成要素は下図のようになっており、その一つ一つがAIDPが提供する機能となります。

| 機能 | 説明 |
|---|---|
| Compute | アプリケーションの開発と実行のためのコンピューティングリソース。複数のノードから構成される Apache Spark のクラスタです。 |
| Catalog | AIDP 内、および AIDP と連携するその他のサービスに配置されているデータの統合カタログ。あらゆるデータをカタログ化することで、Spark アプリ開発時にこの統合カタログから簡単にデータを指定できます。 |
| Notebook / Python Script | マネージドで提供される Jupyter ベースのノートブック機能。Notebook や Python Script から Spark アプリを開発し、Compute 上で実行できます。 |
| Workflow | Notebook や Python Script の実行順序を定義し、処理フロー、スケジュール実行、ストリーミング処理などを設定できます。 |
| Data Sharing | Delta Sharing プロトコルにより、AIDP に登録されたカタログデータを社内外のユーザーとセキュアに共有できます。 |
| Audit Log | AIDP 内でのあらゆる処理が自動記録され、監査ログとして運用可能。ログの検索機能も提供します。 |
| Permission Model | AIDP 内のさまざまなオブジェクトに複数のアクセス権が定義されており、それらをユーザーに割り当てることでアクセスを管理します。 |
| Roles | 組織内の任意の役割に応じて複数ユーザーをグルーピングし、効率的に管理できます。 |
| AI Agent Flows | AIエージェントのアプリケーションを開発するためのローコードツールです。 |
以降が上述の機能の概要説明になります。
Compute
AIDP は、さまざまなアプリケーションを開発するための 分散処理基盤として、Apache Spark を用いた実行環境を提供します。複数ノードで構成される Spark クラスタにより並列処理が可能で、スケールした処理性能を発揮します。

クラスタはシンプルなウィザードからプロビジョニングでき、Spark バージョンや Driver/Worker のシェイプ、ノード数の設定も容易です。さらに、オートスケールによるノード数の自動調整や、タイムアウト設定による自動停止にも対応しており、効率的な運用が可能です。
また、Spark 環境変数や init script の設定をサポートしているため柔軟に環境構築ができ、複数アプリケーションからクラスタを共有することもできます。開発者向けには Spark UI も提供されており、ジョブの可視化やデバッグを行える環境が整っています。
Compute:プロビジョニング
AIDPでは非常に簡単にSparkクラスターの構築が可能です。基本的にはプロビジョニングのウィザードでドライバーノードとワーカーノードのシェイプとノード数を指定するだけです。

ドライバーノードはノード数固定(デフォルト一台から変更不可)、ワーカーノードは負荷に応じてノード数を指定することができ、オートスケールにも対応しています。
クラスタは停止・開始の操作が可能なので、利用していないときは、停止しておき課金をセーブすることができます。
Compute:BIツールの利用
Sparkクラスタの代表的な利用方法として、BIツールの配下でDWHとして利用するというパターンがありますが、AIDPでも同様です。

そのため様々なBIツールからAIDPのSparkクラスタに簡単に接続できるよう、専用の画面からその接続情報を取得することができるようになっています。
Tableau、Power BI、DBeaverなど商用からオープンソースのBIツールまで著名なものはウィザードから簡単に接続できるようになっていますし、基本的には、JDBCまたはODBC経由で接続できるBIツールであれば大抵のものは動作します。
Notebook
AIDP では、Spark アプリケーションの開発に利用するノートブック環境が提供されており、AIDP 上でのデータ処理はすべて Notebook または Python スクリプトから実行します。

ノートブックは作成済みの Spark クラスタにアタッチするだけで処理を実行でき、利用できる言語としては PySpark と SparkSQL がサポートされています。また、ノートブックはスケジュール実行にも対応しており、定期的なバッチ処理にも活用できます。
さらに、一つの Compute を複数のユーザーや複数のノートブックで共有することも可能です。もちろん、Spark アプリケーションから他のさまざまなサービスへアクセスできるため、データ連携や拡張的な処理も柔軟に実現できます。

上図のように、メニューからNotebookを選択するだけで簡単にノートブックが作成できアプリケーションの開発ができます。
Work Flow
AIDP には、シンプルな UI でジョブを定義できる ワークフローエンジンが用意されています。
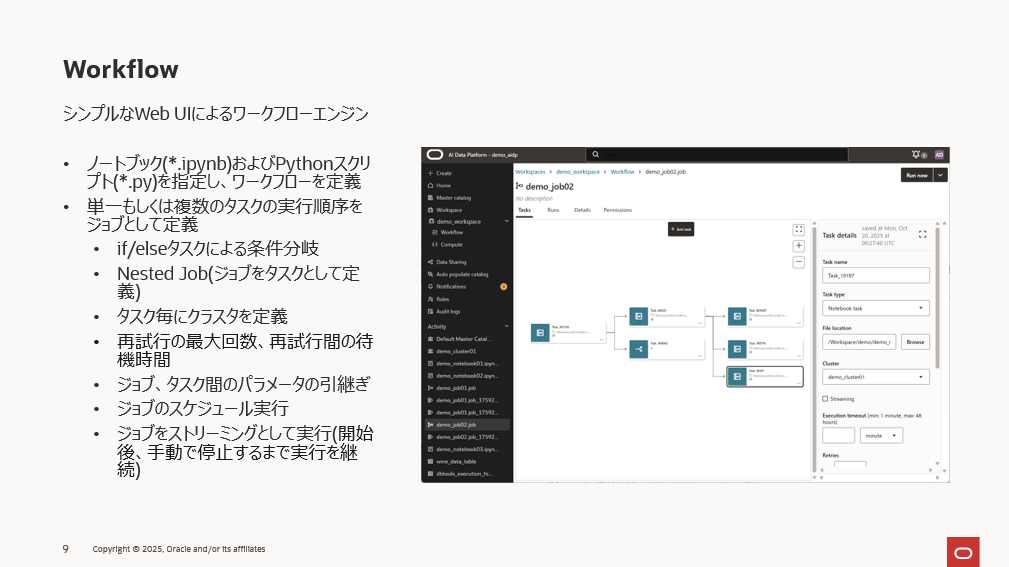
任意のデータ処理を「タスク」として定義し、そのタスクの実行順序をまとめたものを「ジョブ」と呼びます。図中の四角がタスク、複数タスクが連なる全体がジョブというイメージです。
タスクの定義では、Notebook(.ipynb)または Python スクリプト(.py)を指定し、それらの実行順序を組み合わせてワークフローを構築します。たとえば、データ前処理用のノートブック(data_prep.ipynb)の後に、機械学習処理を行うノートブック(ml.ipynb)を実行するといった流れを簡単に作成できます。
さらに、実行時の条件分岐を可能にする if/else タスクも提供されており、「タスクA の結果が true ならタスクB、false ならタスクC」というような分岐処理をワークフローに組み込むことができます。
また、ジョブ内の各タスクごとに実行するクラスタを選択できるため、タスクごとに負荷や運用要件に応じてクラスタを使い分けることも可能です。その他にも、再試行回数や待機時間、ジョブ・タスク間のパラメータ引き継ぎ、スケジュール実行、ストリーミング実行など、Spark の詳細設定を UI 上から柔軟に行えるようになっています。

ワークフローを定義する際はまずタスクを作ります。タスクを作成すると上図のようなタスクを表すアイコンが表示され、このタスクにどのような処理を割り当てるのかを右ペインから設定します。
まずはタスクのタイプの選択です。基本的にはワークフローの中で任意の単位での処理をノートブックで予め開発しておき、そのノートブックをタスクに指定します。ノートブックだけでなく、Pythonスクリプトでも指定することができます。前者の場合は「Notebook task」を、後者の場合は「Python task」を選択します。
このようにしてタスクを数珠繋ぎにしてワークフローを定義してゆきます。その際、タスクの結果によって、次に実行するタスクを変更したい場合は、「if/else condition」のタスクを追加します。また、既に保存済みのワークフローをタスクとして定義することもできます。
上述のような作業を繰り返し、下図のように目的の処理フローを定義してゆきます。

条件分岐によるタスクの制御以外に、複数のタスクをシーケンシャルに実行したり、並列に実行したりとより複雑な定義が可能です。
Catalog
AIDP では、さまざまなデータをカタログに登録し、プラットフォーム内でメタデータのライフサイクルを統合的に管理できます。データストアの登録やメタデータ収集はウィザード形式で簡単に実行でき、利用者は手間なくカタログを構築できます。

登録されたカタログ情報(スキーマやファイル配置場所など)を元に、Notebook や Python スクリプトからデータ処理を行えるため、コード内でのデータ指定が大幅に簡素化されます。また、既存のデータはカタログからすぐに確認できるため、データ探索や開発効率の向上にもつながります。
カタログタイプは大きく 2 種類あり、データを Object Storage 上に配置する「標準カタログ」と、ADW、ATP、Oracle Database、Kafka(coming soon)などの外部データ基盤に配置されたデータを扱う「外部カタログ」があります。さらに、Generative AI Service が提供する LLM もすでにカタログ化されており、シンプルなコードで利用できるようになっています。必要に応じて、カタログの自動収集を設定することも可能です。
Catalog - 標準カタログと外部カタログ
下図は標準カタログと外部カタログを模式図にしたものです。これらのカタログは スキーマ・表・ボリューム の3つで構成されます。

表はデータベースのテーブルのような構造化データを扱い、ボリュームは CSV や Parquet などのファイル形式で、非構造化・準構造化データを扱います。これらがアプリケーションの処理対象となるデータです。
さらに、表とボリュームには Managed と External の2種類があります。Managed はメタデータとデータ本体をどちらも AIDP 内で管理し、データのライフサイクルも AIDP が担います。
一方 External はメタデータのみを AIDP が保持し、データ本体はオブジェクトストレージに置かれ、そのライフサイクルもそちらで管理されます。
この仕組みは Spark における Managed / External の考え方と同様です。
例えば、下記はAutonomous Databaseを外部カタログとしてAIDPに登録した場合の画面です。

左ペインで、登録されたDBのAdminスキーマやその中の表(図ではboston_house_prisesとdbtools_execution_history)がメタデータとして取り込まれている様子がわかります。また、左側のペインで選択された表の表定義が右ペインに表示されていることがわかります。
Autonomous Databaseは外部カタログとしてのみ登録可能ですから、データ自体はAIDPには取り込まれません。あくまでメタデータのみがAIDPに取り込まれ、データ自体はAutonomous Databaseに配置されています。従って、Sparkからのデータ操作もAutonomous Databaseに接続して、Autonomous Databaseに対して行います。その際、ノートブックからは下記のように簡単にAutonomous Databaseのデータにアクセスできます。
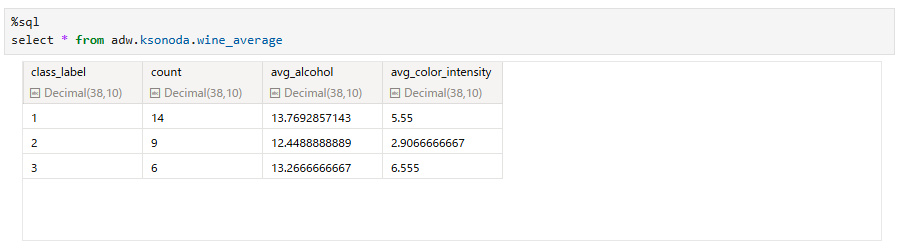
上図のように、fromの後の表名としてこの表のカタログを指定するだけでAutonomous Databaseに接続し対象の表にアクセスできるようになります。これはAutonomous Databaseが既に外部カタログとしてAIDPに登録されているからです。
Sparkから変更されたAutonomous Databaseのデータは再度、AIDPに同期することで、最新のカタログが保持されます。

上図左ペインからわかるように、AIDPではOCIのLLMのPaaSであるGenerative AI ServiceのLLMがデフォルトでカタログ化されています。ですので、これらのLLMを使った処理も下記のように簡単なコードで実行できます。

上記はSparkSQLのコードですが、当然PySparkでも処理できます。
Workspace
AIDPにはコマンドコンソールファイルシステムといった構造がありません。
従って、ディレクトリのファイル操作をシェルコマンドで実行するという運用ではなく、Workspaceの機能を使います。
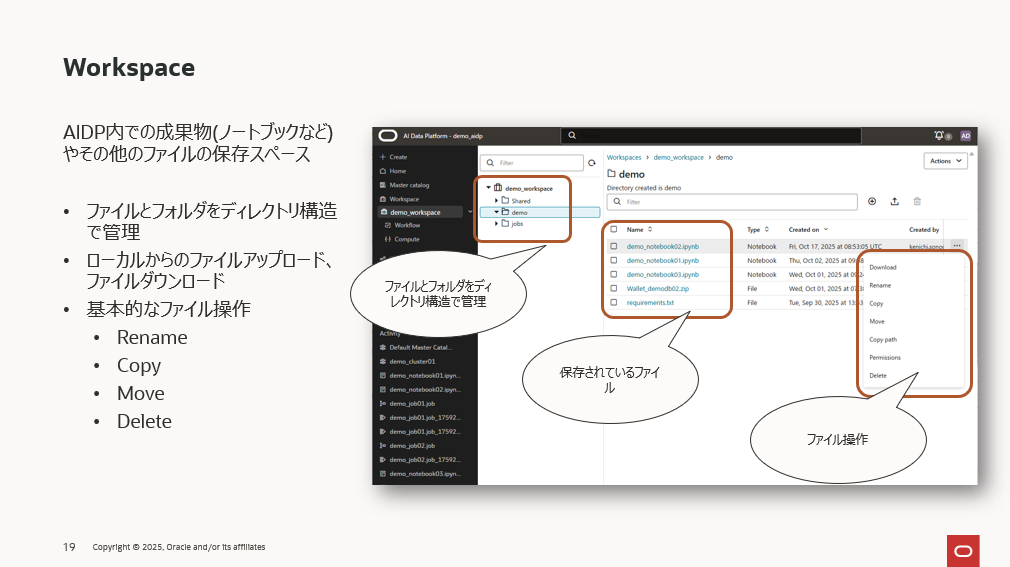
作成したノートブックをこのworkspaceに保存したり、開発に必要なファイルなどをこのworkspaceにアップロードしたりして管理します。ファイルに対する必要な操作もメニューから選択して実行することになります。
Data Sharing
AIDP内で管理しているデータを社内外のユーザーと共有する機能です。共有プロトコルはDatabricksさんのdelta shaingとなり、使い方もほぼ同じです。

はじめにシェアと呼んでいるオブジェクトを定義します。そこに共有したいデータ(カタログから選択)と共有相手(Recipients)を登録します。「共有相手」と言っても新たにユーザーをAIDPに登録するなどの設定はありません。「共有相手(Recipients)」とは共有先へ渡すアクティベーションリンクを管理するための名前付けに近い概念です。
このアクティベーションリンクにはデータのURL(つまり場所)と認証情報が含まれており、共有されたユーザーはこれらを使ってデータにアクセスします。単純にローカルにダウンロードしたり、アプリケーションからデータを読み込んだりという感じです。ちょうど、OCI Object StorageのPAR(Pre-Authentication Request)のような機能に相当します。
Data Sharingの設定自体はいたって簡単です。
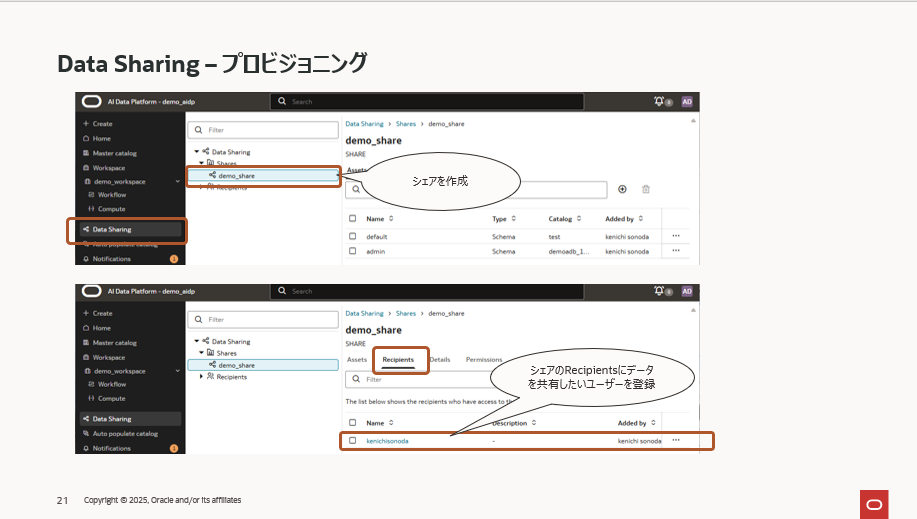
まず、共有するための情報を纏めて管理するために「シェア」を作成し、このシェアに共有相手の情報を「Recipients」として登録します。繰り返しになりますが、この「Recipients」はユーザーの認証情報のようなものではなく単にアクティベーションリンクに紐づいた名前です。
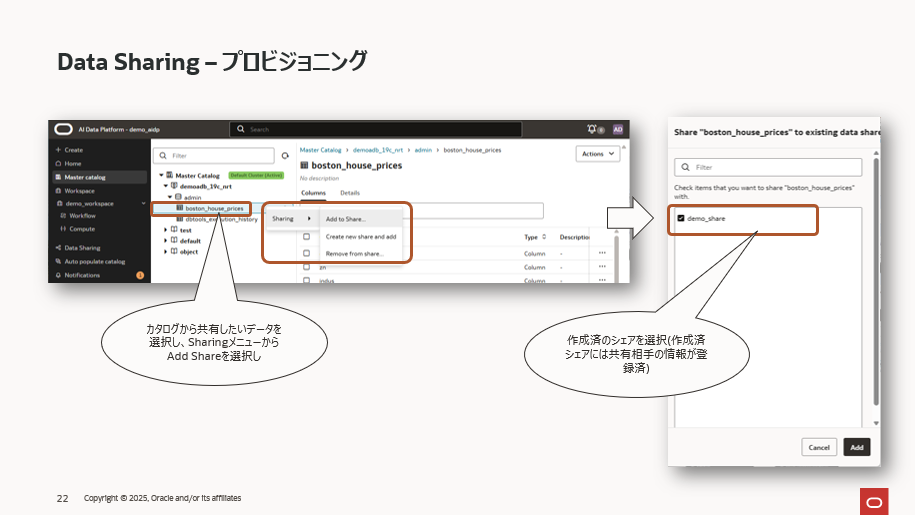
次にカタログから共有したデータを選択し、メニューから「Sharing」、「Add to Share」と選択し、事前に作成した「シェア」を選択します。これにより、共有したいデータとアクティベーションリンクが紐づくことになります。
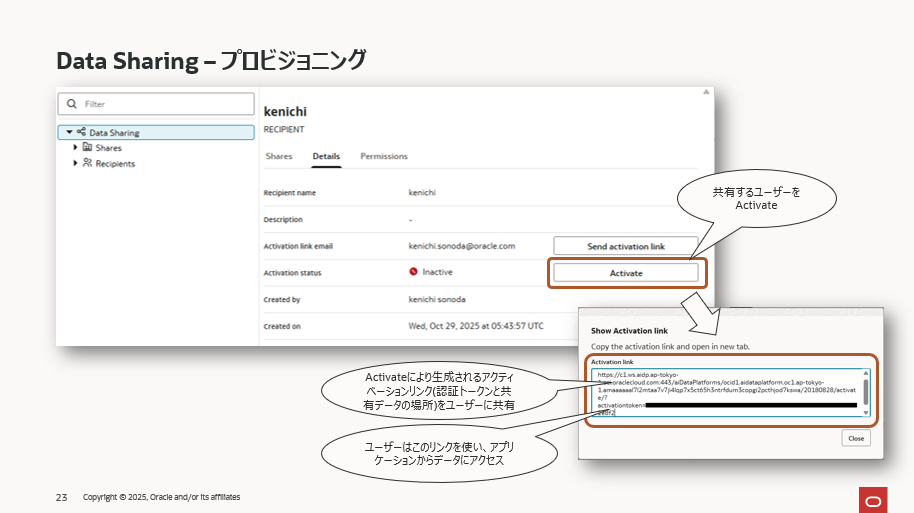
最後に「Recipients」からアクティベーションリンクを生成し、このリンクを共有相手に渡せば、共有相手はOCIやAIDPにアカウントがなくても、このデータを利用することができるようになります。
使い方としては、このリンクをSparkアプリに埋め込んで、アプリケーションから直接データを操作したり、データをダウンロードしてローカルで利用したりと様々です。
Audit Logs
AIDP上での詳細なユーザーアクティビティを自動記録する機能です。デフォルトで有効になっており、無効にすることもできます。

使用状況の監視から、コンプライアンスの確保、不正アクセスや構成変更などの確認を行えます。
ログの対象は、
- 標準カタログ
- 外部カタログ
- Roles
- Compute
- ワークスペースのファイル
- フォルダ
- 自動入力抽出ツール
などです。
これらの対象に対して、下記属性に関する情報を記録します。
- オブジェクト名
- オブジェクトタイプ
- リクエストの詳細
- 日付、時刻、タイムゾーン
- オブジェクトを開始したユーザーの詳細(開始者)
- オブジェクトが開始された場所の詳細 (UI、Terraform、SDK、API、ノートブックなど)
- オブジェクトのステータス(成功、失敗)
当然、収集した監査ログの検索もできるようになっています。
RolesとPermission Model
AIDPでは、AIDP内のオブジェクトに対してロールベースのアクセス制御 (RBAC) を使用してユーザーとアクセス権を一元管理します。

まず、アクセスを管理するうえでのユーザーは、IAMアカウントということになります。単一のIAMアカウントにアクセス権を割り当てることもできますし、複数のIAMアカウントをグルーピングしてそこにアクセス権を割り当てることも可能です。
後者の場合、複数のIAMアカウントをMemberとして纏めて定義しこのMemberを任意の役割に基づいたRolesに関連づけることでグループとして扱うことができます。例えば、部署Aの全員や、開発者全員といった具合でそのRoleに基づいてグルーピングすることができるようになっています。
AIDP内の下記オブジェクトに対して、IAMアカウントやRolesからアクセスできるように設定します。
- ワークスペース
- ワークスペースのフォルダおよびファイル
- コンピューティングクラスター
- ジョブ
- ノートブック
- マスターカタログ、標準カタログ、外部カタログ、スキーマ、テーブル、ボリューム
どのようなアクセス権の種類があるかはオブジェクト毎に異なり、例えば、ワークスペースであれば下記のようにアクセス権のレベルが分かれています。
| 権限レベル | 内容 |
|---|---|
| Read | ユーザーはファイルとフォルダーを読み取り/一覧表示できます。 |
| Use | ユーザーはフォルダーとその中のファイルを読み取り/書き込みでき、許可されたジョブタイプ(.ipynb、.py、.sql、.scala など)を実行できます。 |
| Manage | ユーザーは読み取り・使用の権限に加え、ファイル/フォルダー名の変更やファイルの修正が可能です。 |
| Admin | すべての権限を持ち、他ユーザーの権限を作成・変更・削除できます。 |
また、IAMアカウントだけでなく、Active DirectoryグループをIAMグループにマッピングすることも可能です。
データ連携

AIDPはその他の様々なサービスと簡単に連携を設定できるようにするためのインタフェースを持っています。現状、現状はFusionのデータソースとのデータ連携が可能で、今後 GoldenGateやその他のサービスも対象になってきます。
Fusionとのデータ連携では、Business Intelligence Cloud Connector(BICC)を使用し、AIDPのComputeからFusionのデータソースに直接アクセスし、ノートブックでデータ分析が可能です。
また、Fusionのデータソースからオブジェクトストレージへデータを取り込み、同じくノートブックからそのデータの分析を実行することも可能です。
GoldenGateとのデータ連携では、ソースシステムからトランザクションの変更を AI Data Platform ターゲットテーブルに継続的にストリーミングしてマージする機能が追加されますので、リアルタイムのデータ分析やデータ変換などが簡単に行えるようになります。
AI Agent Flows(comming soon)
AIDPには今後、AIエージェントを開発するためのローコードツールの機能が追加されます。下記のビデオにその操作が一通り説明されていますが、ここではその操作の中でトピックとなる部分を簡単に解説します。
ローコードツールなのでAIエージェントを開発するために必要なコンポーネントは事前に用意されています。それらをWebUIの画面で組み合わせていくだけでAIエージェントの処理フローを定義できるように作られています。
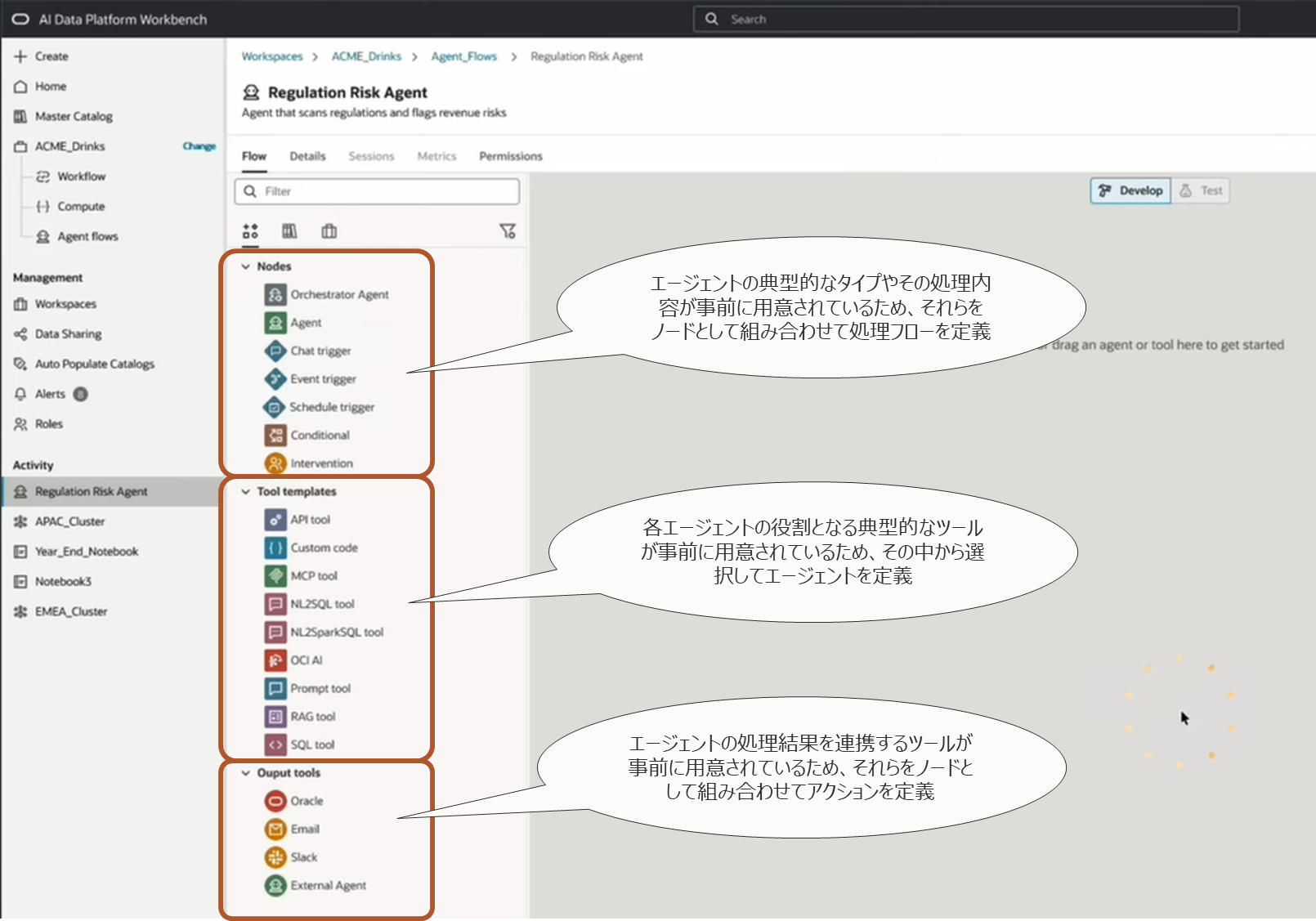
事前に用意されているものとしては上図の3つのカテゴリになります。
-
Nodes
AIエージェントではエージェントをグラフデータモデルのノードに見立てて処理フローを定義します。このノードとしては以下のようなタイプが事前に定義され、それらを組み合わせるだけでAIエージェントシステムが開発できるようになっています。 -
Tool templetes
AIエージェントシステムでは各エージェントに個別の役割が割り当てられ、複数のエージェントが連携することで最終的な目的となる処理を実行します。AIDPでは各エージェントがその役割に応じて必要とする典型的な処理(例えば、自然言語をSQLに変換する処理)を事前にツールとして提供していますので、それをエージェントに割り当てるだけでツールを持ったエージェントが簡単に定義できるようになっています。 -
Output tools
AIエージェントの実行結果を渡すインタフェース(例えばSlackの指定のチャネルに出力したり、Emailで送信したり)も典型的なものが用意されています。
Nodes
下記4タイプのノードが用意されており目的に応じてこのノードを定義してゆきます。
-
オーケストレーター・エージェント
複数のエージェントが協力してタスクをこなすとき、全体の流れを指示してまとめる司令塔の役割 を持つエージェントです。例えば、「次はこのエージェントを動かして」、「結果が揃ったからまとめて最終回答を作る」といったワークフロー全体を管理します。 -
エージェント(通常のエージェント)
特定の役割に特化してタスクを実行する作業担当者です。例えば、情報を検索するエージェント、計算するエージェント、テキストを翻訳するエージェントなどです。オーケストレータータイプ(Supervisedタイプ)のマルチエージェントでは上述したオーケストレーター・エージェントからの指示を受けて処理を行います。 -
チャット / イベント / スケジュール トリガー
ワークフローを “いつ” 動かすかを決める起動スイッチのようなものです。チャットトリガーは「ユーザーのメッセージを受けてスタート」、イベントトリガーは「APIの呼び出しや外部システムの通知でスタート」、スケジュールトリガーは毎日 9:00など指定した時間に自動実行」という感じです。これらのトリガーでエージェントのフローが動き出します。 -
条件分岐
エージェントの実行結果に応じて、次にどのエージェントを動かすかを自動判断する分岐ポイントです。
例えば、「分析結果が成功 → 次の集計エージェントを実行」、「データが欠損 → 補完エージェントに分岐」、「エラーが発生 → リトライ処理へ」のような、プログラミングの “if/else” に相当するノードです。 -
Human in the loop(人間の介入ポイント)
ワークフローの中で、最終判断を人が行うためのステップです。AIでは判断が難しい場面で、人が自然言語で指示を返すことで次の処理が決まります。例えば、「AIが提案した3つのプランの中から人が選択」、「曖昧なリクエストの意図を人が補足」、「倫理的・ビジネス判断が必要な局面で人が承認」などがその典型例です。完全自動ではなく、必要なところだけ人が介入できる仕組みです。
Tools
上述した様々なタイプのノード(エージェント)に対して、事前定義済の様々なツールが提供されています。非常に沢山ありますのでその中でもいくつかピックアップしてご紹介します。
-
RAG
LLMを使うアプリではお馴染みになったRAGツールです。ベクトルデータベースにドキュメントを保存し、ベクトル検索により、入力プロンプトに関連するテキストデータを検索し、LLMに連携するツールです。ドキュメントに関するFAQのシステムでよく利用される処理です。 -
NL2SQL/NL2SparkSQL
ユーザーが入力した自然言語をSQLに変換するツールです。これにより、SQLではなく自然言語でデータベースへの問い合わせや分析、データベースの操作が可能になります。 -
MCP
LLMが外部のサービスやデータ源と安全・統一的にやり取りするための標準的な仕組みです。エージェントは必要な情報だけを外部から取得でき、動作範囲を明確に管理できます。また、市場にはMCP形式で提供される外部連携モジュールが増えており、開発者はそれらを簡単に組み込んで機能を拡張できます。
Output Tools
AIエージェントの実行結果を出力する連携ツールとして、「Email」、「Slack」、「External Agent(AIDP以外で開発されたエージェント)」などが事前に用意されており、ユーザーはそれをフローに組み込むだけです。
AIエージェントの処理フローの定義
この動画では以下のような手順でAIエージェントを定義しています。
まず、AIエージェントを実行するトリガーとして下記のようにShedule Triggerのノードが選択されています。

Shedule Triggeは指定した日時に処理実行するノードなので、その情報を下記のように定義しています。

次に、トリガーされた後に実行するエージェントのノードを定義しています。

同じく定義したエージェントノードの設定(LLMとしてはMiniLMを使うなど)をしています。

次に、このエージェントに持たせるツールの定義です。この例では「RAG Tool」を選択しています。

同じくRAG Toolの設定を行います。ここではRAG Toolの処理対象となるナレッジベース(ドキュメントを保存したベクトルデータベース)としてAutonomous DatabaseがAIDPのカタログに登録されている前提で、それを選択しています。
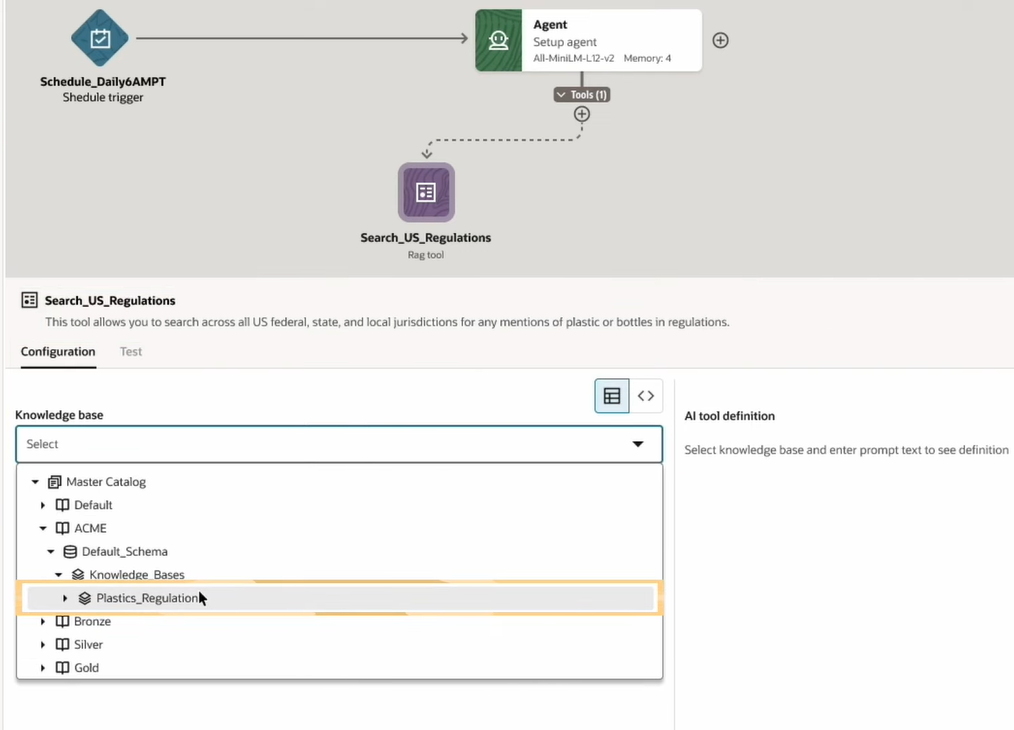
同じ操作で、今度はNL2SQL Toolを追加しています。このツールにより、自然言語でDBへの問い合わせができるようになります。
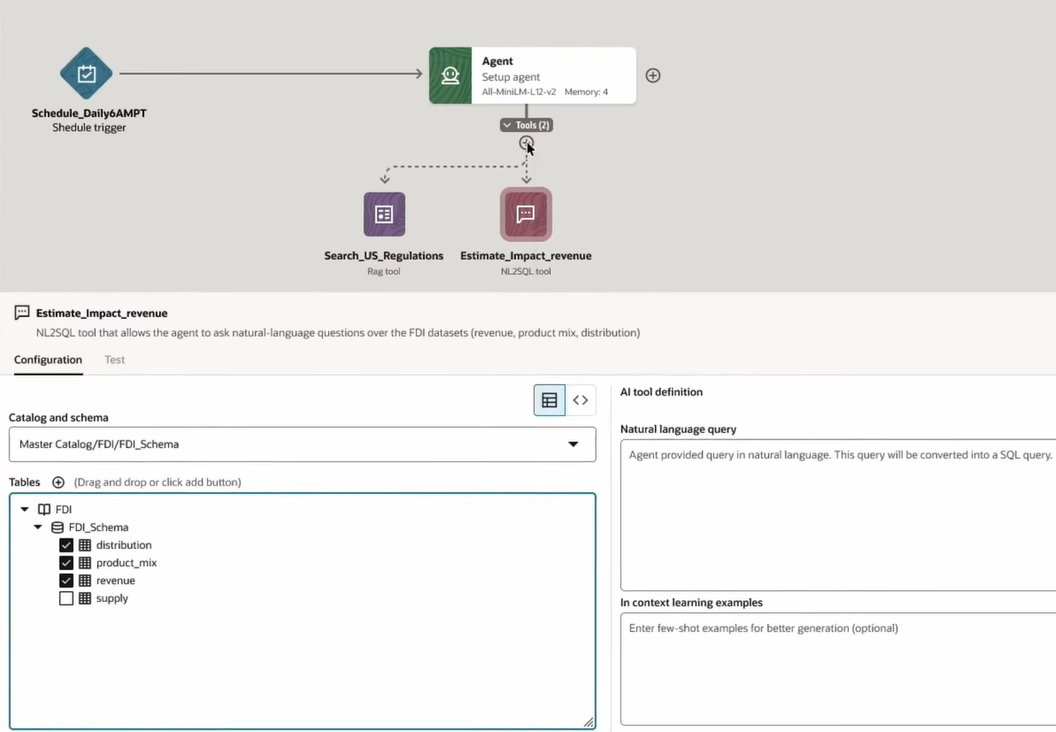
更に、SQL Toolを追加しています。このツールにより、問い合わせだけでなく、データベースにデータをinsertすることができるようになります。

次に、Output ToolとしてSlackを追加しています。これにより、このエージェントの実行結果をSlackの指定のチャネルに出力することができるようになります。
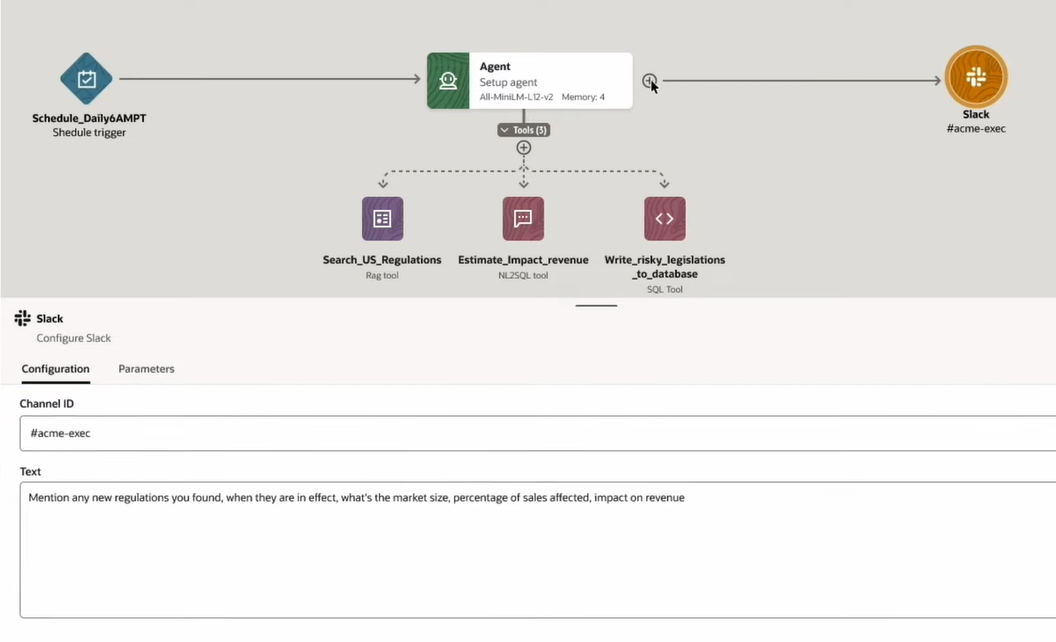
出力先として、更にEmailを追加しています。

最後に、このAIエージェントを動作させ、定義した各処理にどの程度の時間がかかっているかなど、詳細な情報を得ることができます。
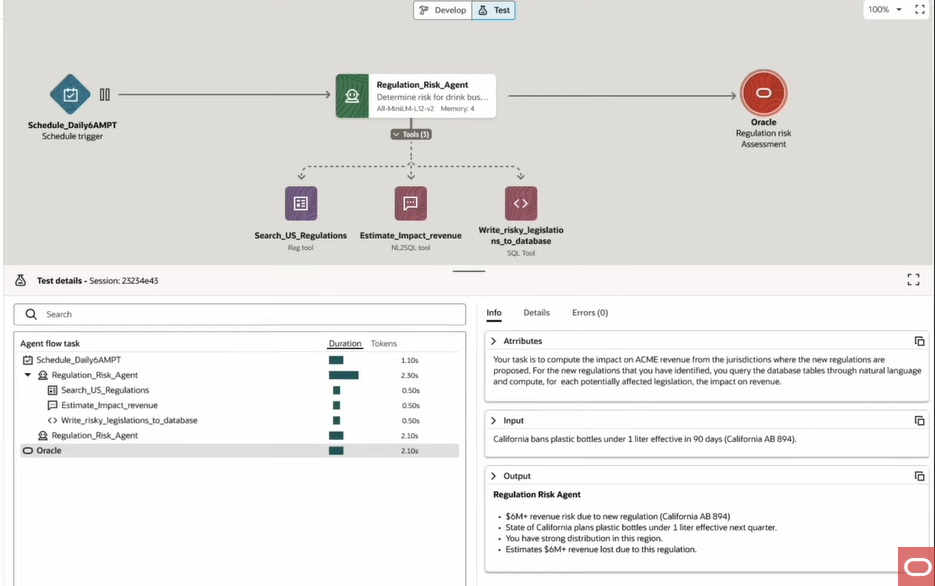
上記は単体エージェントの非常にシンプルな処理ですが、複数のエージェントで様々な処理を実行するフローを定義することでよりユーザーの業務要件に沿った、よりリアルなAIエージェントの処理フローがこのような簡単な画面で実装できます。
さいごに
構造化データ、非構造化データを統合管理しつつ、それらを活用するSparkアプリケーションの開発、そのアプリケーションの中でも、AIエージェントを実に簡単に構築できる統合プラットフォームとなるサービスであることが本記事を通しておわかりいただけたのではないでしょうか。
AIDPでは、今後更に沢山の機能がリリースされる予定ですのでご興味がある方は是非トライアルでご利用いただければと思います。