※ 2021/01/15 NVIDIA ドライバと NVIDIA Docker のインストール方法を更新しました。
※ 2019/11/21 AWS の NVIDIA Volta Deep Learning AMI の名称変更などに対応しました。
※ 2019/04/25 Google Cloud と Oracle Cloud でも試してみたので追記しました。
※ 2019/04/10 Alibaba Cloud の東京リージョンで NGC VM Image が利用可能になったので追記しました。
※ 2019/04/04 Alibaba Cloud でも試してみたのでちょっと追記しました。
※ 2019/03/03 NGC の対応環境や、NVIDIA ドライバ等のインストール方法の部分を中心に、古くなっていた部分をあちこち更新しました。
※ 2018/7/2 コンテナー イメージを指して「コンテナ」と書いていた部分を「コンテナー イメージ」あるいは単に「イメージ」と修正しました。
※ 2018/6/10 Tesla V100 のメモリ 32GB 化、Azure の NCv3 インスタンスの GA などを反映してちょこちょこ更新しました。
こんにちは。エヌビディアの佐々木です。
NGC というサービスをご存知でしょうか。端的に書けば 「NVIDIA が公開している Docker レジストリおよび学習済みモデルなどを提供するサービス」 です。Caffe、Chainer、TensorFlow 等の各種ディープラーニング フレームワークや、GAMESS、Gromacs、LAMMPS といった HPC アプリケーションのコンテナー イメージが揃っており、もちろん GPU 実行に最適化されています。このイメージを使えば、計算環境構築の手間をかなり削減することができます。
「Cloud」とあるので、クラウドで GPU を使うためのサービスと思われることがあるのですが、NGC は「コンテナー イメージを提供するクラウドサービス」であって、そのイメージはクラウドに限らず、オンプレミスのコンピューターでも利用できます。
今のところ、コンテナーの利用環境としてエヌビディアが正式にサポートするのは下記のとおりです。
(この文書を初めに書いた時よりだいぶ増えたので更新しました)
- Alibaba Cloud
- Amazon EC2
- Google Cloud
- Microsoft Azure
- Oracle Cloud
- NVIDIA DGX Systems 製品群
- サーバーベンダー各社の NGC Ready System
- Pascal / Volta / Turing 世代の TITAN / Quadro GPU 搭載 PC
- NVIDIA Quadro 仮想データ センター ワークステーション (Quadro vDWS) ソフトウェアが動作する Linux VM
というわけで、次のような環境で試してみました。
- AWS の P3 インスタンス (Tesla V100 搭載)
- Microsoft Azure の ND インスタンス (Tesla P40 搭載)
- Alibaba Cloud の gn5 インスタンス (Tesla P100 搭載)
- Google Cloud の Tesla T4 搭載インスタンス
- Oracle Cloud の BM.GPU2.2 インスタンス (Tesla P100 搭載)
- 私の自宅 PC (GeForce GTX 1050 Ti 搭載)
- 職場の PC (GeForce RTX 2080 Ti 搭載)
※ 私の PC だけちょっと弱めですが、ロープロファイルのカードしか付かないんです…
NGC のアカウントを作る
※ 現在、多くの NGC コンテナーイメージがログイン不要で利用可能になっています。ログイン不要なイメージの利用については、下記のアカウント作成及び API Key の取得は不要です。
アカウントを作成するには、NGC のサインアップページへアクセスします。サインアップは無料です。
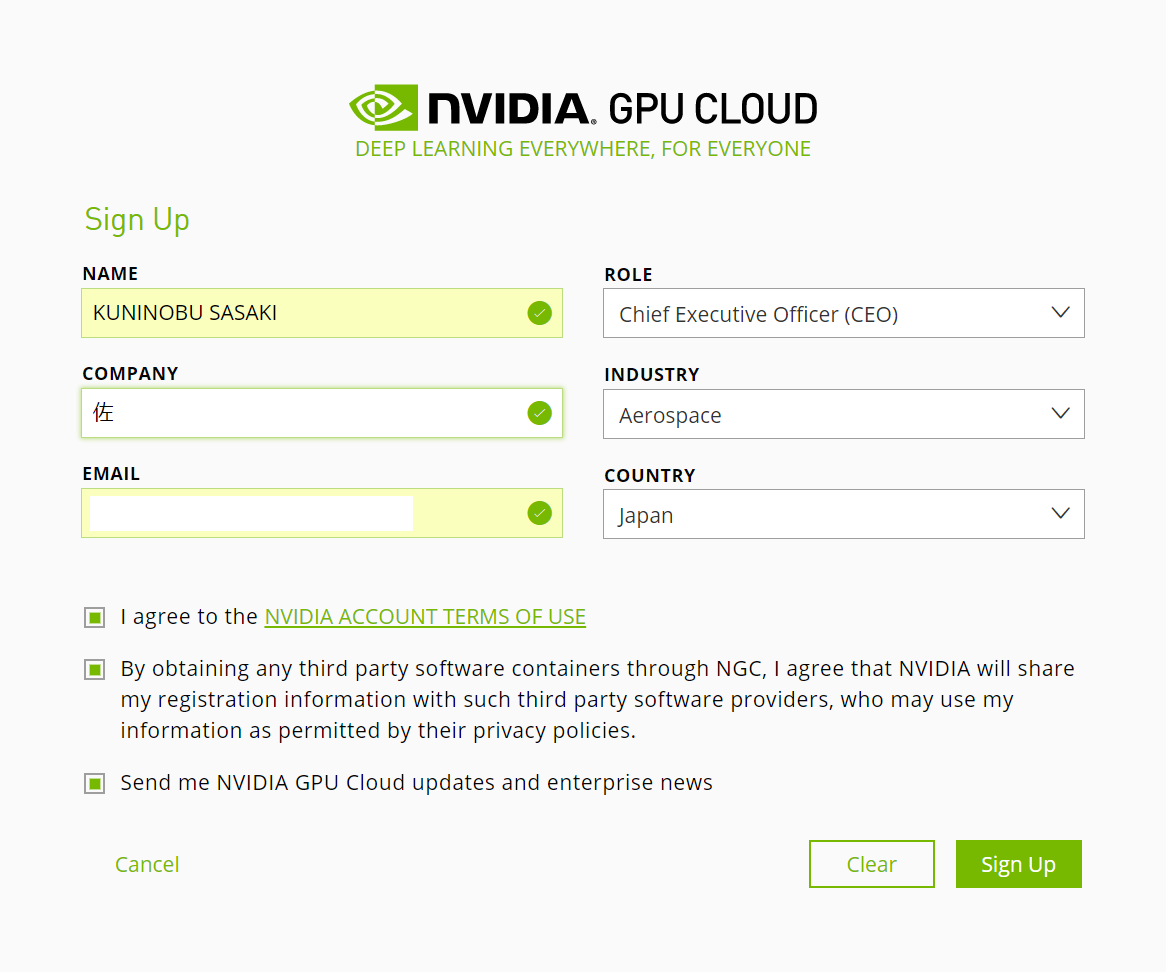
NGC の API キーを生成する
アカウントができたらログインして、画面右上の "Get API Key" をクリックしてください。
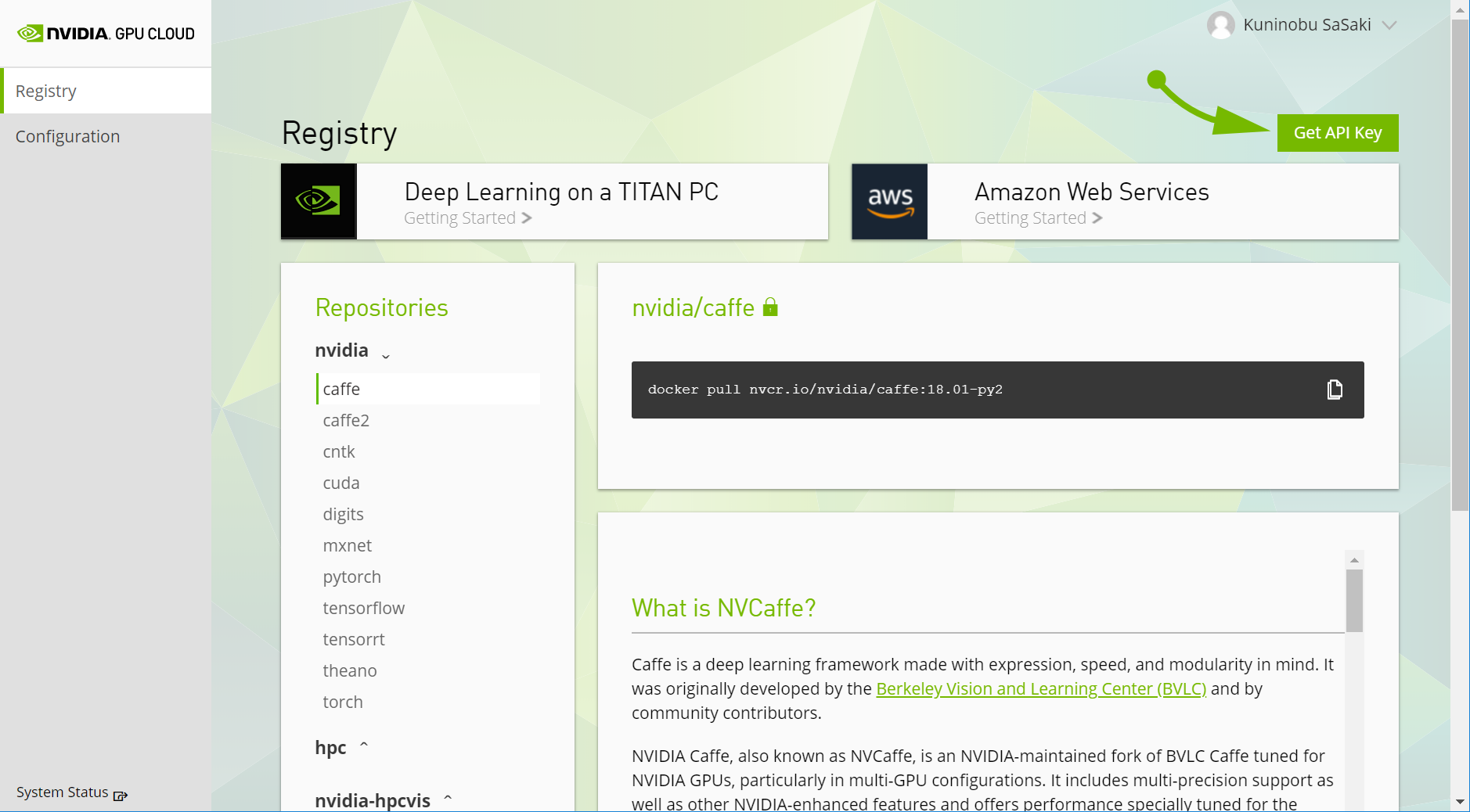
次に、"Generate API Key" をクリックして API キーを生成します。これは後ほど NGC からイメージを pull する際に使用します。
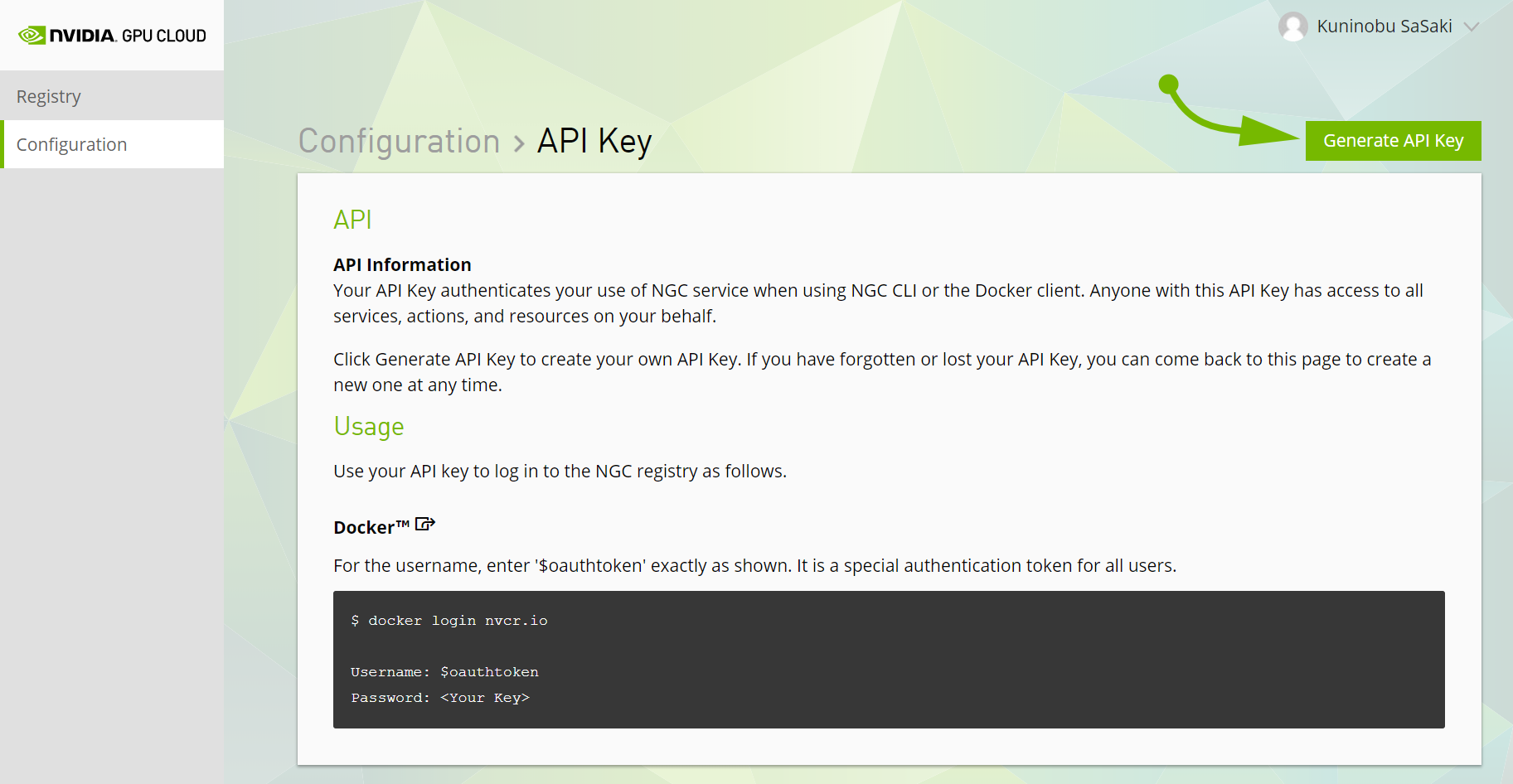
生成されたキーは必ずどこかに控えておいてください。"This is the only time your API Key will be displayed." とあるとおり、二度と表示されません。

さて、アカウントと API Key ができたら、あとは実行環境の準備です。要件は次の通り。
- Pascal 世代以降の GPU (と、そのドライバ)
- NVIDIA Docker
では、各種クラウドと自宅 PC のそれぞれで試していきます。
実行環境を作る (AWS で)
AWS は NGC の正式サポート環境なので、準備も簡単です。NVIDIA Deep Learning AMI という AMI をエヌビディアが提供していますので、これを使って P3 や G4 インスタンスを作れば OK です。ドライバも NVIDIA Docker もインストール済み。別途セットアップする必要はありません。(なお、G2, G3, P2 は、GPU が Kepler や Maxwell 世代なので NGC 非対応)

早速作ってみます。東京は高いのでオレゴンで、インスタンスタイプは p3.2xlarge (Tesla V100 を1基搭載)を選びました。
インスタンスが起動したらログインしてみます。
Welcome to the NVIDIA GPU Cloud image. This image provides an optimized
environment for running the deep learning and HPC containers from the
NVIDIA GPU Cloud Container Registry. Many NGC containers are freely
available. However, some NGC containers require that you log in with
a valid NGC API key in order to access them. This is indicated by a
"pull access denied for xyz ..." or "Get xyz: unauthorized: ..." error
message from the daemon.
Documentation on using this image and accessing the NVIDIA GPU Cloud
Container Registry can be found at
http://docs.nvidia.com/ngc/index.html
ubuntu@ip-192-168-100-1:~$
この時点で NGC の利用準備がすべて整っています。以前は、プロンプトが出る前に NGC の API KEY の入力を求められましたが、今は多くのコンテナーイメージが NGC へのログインなしで利用可能になったため、 API KEY の入力は必須ではなくなりました。
コンテナーを動かす前に、 GPU を確認してみます。
$ nvidia-smi
Sun Mar 3 00:32:17 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 410.104 Driver Version: 410.104 CUDA Version: 10.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... On | 00000000:00:1E.0 Off | 0 |
| N/A 37C P0 26W / 300W | 0MiB / 16130MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
本当に Tesla V100 SXM2 だ!テンション上がりますねー。
では、動作確認をしてみましょう。
手順はこちらにまとめました → コンテナーの動作確認
実行環境を作る (Azure で)
※ この文書を最初に書いたときは「サポートされていないクラウドでも動く」例として Azure を試したのですが、現在は Microsoft Azure 上での NGC 利用が正式にサポートされているのは前述のとおりです。
Microsoft Azure の仮想マシンで、Pascal 以降の GPU を搭載しているのは次の通りです。
- NCv2 (Tesla P100)
- ND (Tesla P40)
- NCv3 (Tesla V100 PCIe)
- NDv2 (Tesla V100 SXM2)
NGC が Azure を正式にサポートしたので、AWS の NVIDIA Volta Deep Learning AMI と同様の NVIDIA GPU Cloud Image をエヌビディアが提供しています。これを使って ND6s サイズのインスタンスを作ってみます。なお、イメージの ID は nvidia:ngc_azure_17_11:nvidia_gpu_cloud_2019_01_0:19.01.0 です。

ログインしたら GPU を確認。確かに、Tesla P40 が搭載されていますね。こいつの GPU メモリサイズは 24GB と、P100 (16GB) や 初期の V100 (初期型: 16GB, 現行型: 32GB) よりも大きいのです。
nvidia@nvf2ced237:~$ nvidia-smi
Sun Mar 3 01:50:35 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 410.79 Driver Version: 410.79 CUDA Version: 10.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P40 On | 000039A8:00:00.0 Off | 0 |
| N/A 25C P8 11W / 250W | 0MiB / 22919MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
では、動作確認をしてみましょう。
手順はこちら → コンテナーの動作確認
実行環境を作る (Alibaba Cloud で)
最近存在感をメキメキと増している (個人の感想です) Alibaba Cloud も NGC のサポート対象クラウドサービスです。そのほかの対応クラウドと同様に、エヌビディアが NGC 対応の VM イメージを提供しています。私は今まで Alibaba Cloud を使ったことがなく、今回初めてサインアップしたのですが、Web の管理コンソールは使いやすく、特に迷うところはありませんでした。
Elastic Compute Service (ECS) のインスタンス作成画面で以下のように選ぶだけです。
- リージョン: US West 1 (Silicon Valley) ←
- インスタンスタイプ: gn5-c4g1.xlarge (Tesla P100 搭載)
- イメージ: Marketplace Image の NVIDIA GPU Cloud Virtual Machine Image 19.03.0
詳しくはこちらをご覧ください → Deploy an NGC on gn5 instances
ログインして GPU を確認。Tesla P100 の PCIe 版が搭載されていますね。Azure の NCv2 と同じ、Pascal 世代の GPU です。
# nvidia-smi
Thu Apr 4 21:25:01 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.40.04 Driver Version: 418.40.04 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P100-PCIE... On | 00000000:00:08.0 Off | 0 |
| N/A 26C P0 25W / 250W | 0MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
では、動作確認をしてみましょう。
手順はこちら → コンテナーの動作確認
[補足] サインアップ時の注意事項
Alibaba Cloud は、サインアップ (アカウント作成) をどのサイトから行うかによって提供されるプロダクトに違いがあり、例えば同じリージョン (今回はシリコンバレー) でも、日本サイトから作ったアカウントでは、 NGC VM イメージの最新バージョンが使用できないといったことがあるようです。私は今回、国際サイトからサインアップしました。
- 中国サイト https://www.aliyun.com/
- 国際サイト https://www.alibabacloud.com/
- 日本サイト https://jp.alibabacloud.com/
実行環境を作る (Google Cloud で)
Google Cloud Platform は、最新の Turing 世代 GPU である Tesla T4 を提供する現時点 (2019年4月) で唯一のクラウドです。P100 や V100 もありますが、せっかくなので T4 搭載インスタンスを作ってみました。
仮想マシンイメージとしては、他の NGC 対応クラウドと同様に、NVIDIA GPU Cloud Image for Deep Learning, Data Science, and HPC という NGC 用の VM イメージをエヌビディアが提供していますので、これを使います。。と言いたいところなのですが、どうもこの VM イメージだと Tesla P100 と V100 しか選択できないようなので、 Google 謹製の Deep Learning VM というイメージを試してみます。これも GPU ドライバから NVIDIA Docker まで一式入っている便利なイメージです。

「COMPUTE ENGINE 上で起動」をクリックして、

Tesla T4 を 2 つ付けちゃいます。いろんなインスタンスタイプに GPU をポン付けできるのが GCP のすごいところですよね。一体どういう仕掛けなのか… あと、「INSTALL NVIDIA GPU driver automatically on first startup?」にチェックを入れるの忘れずに。
そして、あっという間にできあがった VM にログインして確認してみると、
$ nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 410.72 Driver Version: 410.72 CUDA Version: 10.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 47C P0 27W / 70W | 0MiB / 15079MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla T4 Off | 00000000:00:05.0 Off | 0 |
| N/A 66C P0 31W / 70W | 0MiB / 15079MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Tesla T4 が 2 基、確かにありますね!
では、動作確認をしてみましょう。
手順はこちら → コンテナーの動作確認
実行環境を作る (Oracle Cloud で)
まもなく日本リージョンができるらしい Oracle Cloud Infrastructure (OCI) も複数の GPU インスタンスをラインアップしています。Pascal 世代以降の GPU を備えるのは次の通り。
- BM.GPU2.2 (Tesla P100 x 2)
- VM.GPU2.1 (Tesla P100 x 1)
- VM.GPU3.1 (Tesla V100 x 1)
「BM」で始まるやつは仮想マシンではなくベアメタル!です。今回はこれを試してみました。
インスタンス作成時に、「Oracle Images」のタブから NVIDIA GPU Cloud Machine Image を選びます。これ重要。
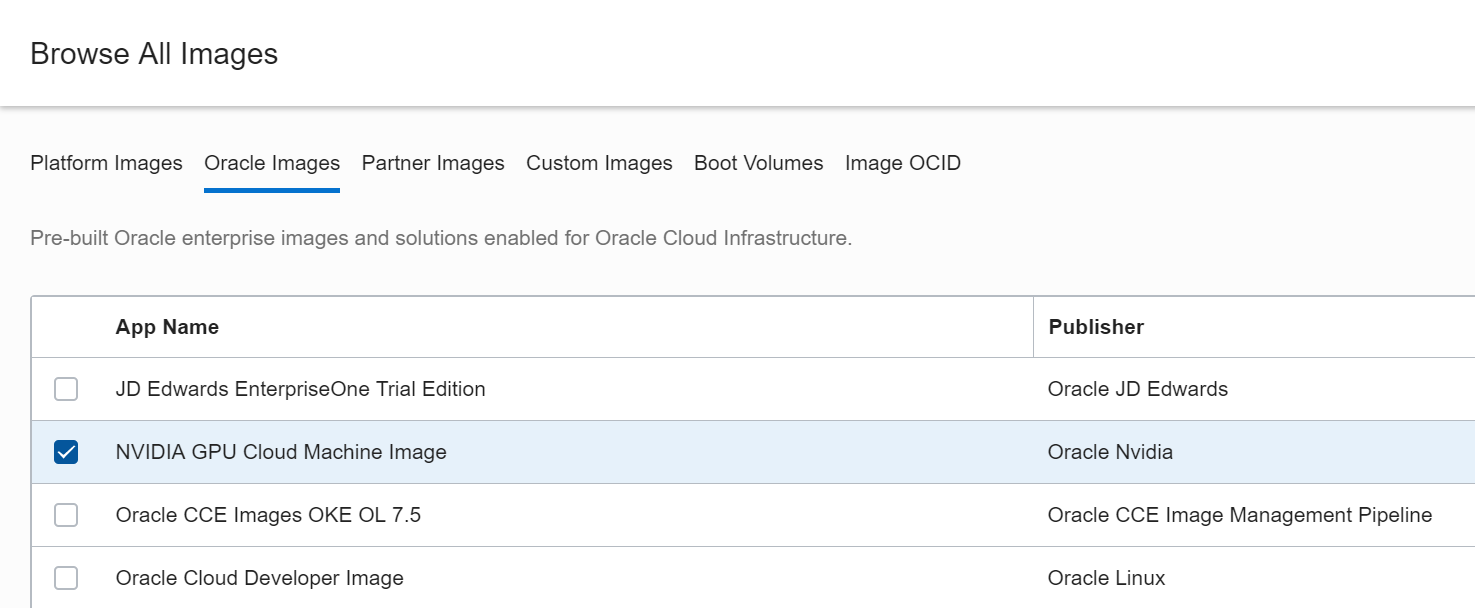
Oracle Cloud ではインスタンスタイプのことを "Shape" と呼ぶようです。BM.GPU2.2 を選択しました。
3分ほどで起動しました。早いね!
ログインして確認してみると、Tesla P100 SXM2 が 2 基確認できました。
$ nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.40.04 Driver Version: 418.40.04 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P100-SXM2... Off | 00000000:5E:00.0 Off | 0 |
| N/A 41C P0 41W / 300W | 0MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla P100-SXM2... Off | 00000000:86:00.0 Off | 0 |
| N/A 37C P0 34W / 300W | 0MiB / 16280MiB | 3% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
では、動作確認をしてみましょう。
手順はこちら → コンテナーの動作確認
実行環境を作る (自宅の PC 等で)
ここまで雲の上 (クラウド) で環境を作ってきましたが、NGC はもちろん地上 (オンプレミス) でも使えます。そこで、自宅の PC でも試してみました。環境は次の通りです。
- OS: Ubuntu 18.04.2 LTS
- GPU: GeForce GTX 1050 Ti (Pascal 世代)
Deep Learning AMI のような便利なものはないので、GPU のドライバと NVIDIA Docker は自分でインストールする必要があります。
※ 2021/1/15 更新: 以前、ここに書いた手順は少し古くなりましたので、下記をご覧ください。
NVIDIA Docker って今どうなってるの? (20.09 版)
コンテナーの動作確認
各種のクラウドとオンプレミスの PC で環境を構築しました。一度環境ができてしまえば、あとはどの環境でも全く同じ手順でコンテナーの動作確認ができます。2 種類ほど試してみました。
PyTorch で MNIST
PyTorch のイメージに含まれる MNIST 手書き文字認識サンプルがシンプルな動作確認には最適です。
--runtime=nvidia オプションを指定して、PyTorch イメージを実行します。
$ docker run --runtime=nvidia -ti nvcr.io/nvidia/pytorch:19.02-py3
Unable to find image 'nvcr.io/nvidia/pytorch:19.02-py3' locally
19.02-py3: Pulling from nvidia/pytorch
7b722c1070cd: Pulling fs layer 5e902e450acf: Pulling fs layer <略>
初回なのでいろいろとダウンロードする必要があり、少し時間がかかりますが、うまくコンテナーが動き出しました。
=============
== PyTorch ==
=============
NVIDIA Release 19.02 (build 5571962)
PyTorch Version 1.1.0a0+9a7bcac
Container image Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
Copyright (c) 2016- Facebook, Inc (Adam Paszke)
Copyright (c) 2014- Facebook, Inc (Soumith Chintala)
Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)
Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)
Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)
Copyright (c) 2011-2013 NYU (Clement Farabet)
Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)
Copyright (c) 2006 Idiap Research Institute (Samy Bengio)
Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)
All rights reserved.
Various files include modifications (c) NVIDIA CORPORATION. All rights reserved.
NVIDIA modifications are covered by the license terms that apply to the underlying project or file.
#
コンテナーの中で、サンプルスクリプトを動かしてみます。
# cd /opt/pytorch/examples/upstream/mnist && python main.py
※ 従来のバージョンとは、 main.py のパスが変わっています。
Train Epoch: 10 [58880/60000 (98%)] Loss: 0.426179
Train Epoch: 10 [59520/60000 (99%)] Loss: 0.152902
Test set: Average loss: 0.0564, Accuracy: 9830/10000 (98%)
#
1分半ほどで10エポック完了しました。クラウドでもオンプレでも、同じように動きますので是非お試しを。
[補足] Turing 世代 GPU での実行
職場の GeForce RTX 2080 Ti で、ちょっと古い PyTorch イメージ (18.01) の MNIST サンプルを実行したところ、下記のエラーで失敗してしまいました。これは Turing 世代の GPU で発生するようです。最新の 19.02 版イメージでは問題ありませんので、Turing では新しめのイメージを試してみてください。
Traceback (most recent call last):
File "main.py", line 112, in <module>
train(epoch)
File "main.py", line 83, in train
output = model(data)
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/nn/modules/module.py", line 325, in __call__
result = self.forward(*input, **kwargs)
File "main.py", line 62, in forward
x = F.relu(F.max_pool2d(self.conv1(x), 2))
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/nn/modules/module.py", line 325, in __call__
result = self.forward(*input, **kwargs)
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/nn/modules/conv.py", line 277, in forward
self.padding, self.dilation, self.groups)
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/nn/functional.py", line 90, in conv2d
return f(input, weight, bias)
RuntimeError: CUDNN_STATUS_EXECUTION_FAILED
Horovod + TensorFlow で ResNet-50 をトレーニング
MNIST だけではあまりにも簡単なので、マルチ GPU の環境ではちょっと違うサンプルを試してみましょう。NGC の TensorFlow イメージには /opt/tensorflow/nvidia-examples 配下にいろいろなサンプルが入っています。この中の、ResNet-50 の学習スクリプトなんか良いんじゃないでしょうか。Horovod を使ったノード内並列のサンプルです。と言ってもこれも MNIST 同様に簡単なのですが。
下記のコマンドは、 Oracle Cloud の BM.GPU2.2 (Tesla P100 x 2) で実行したものです。GPU が 2 基なので、 mpiexec には -np 2 を指定しています。
docker run --runtime=nvidia --rm -it nvcr.io/nvidia/tensorflow:19.03-py3 \
mpiexec --allow-run-as-root --bind-to socket -np 2 python /opt/tensorflow/nvidia-examples/cnn/resnet.py \
--layers=50 \
--precision=fp16 \
--batch_size=128
結果を抜粋するとこんな感じ。毎秒570イメージ弱、といったところでしょうか。
Step Epoch Img/sec Loss LR
1 1.0 38.2 7.777 8.748 2.00000
10 10.0 297.2 4.032 5.005 1.62000
20 20.0 558.9 0.047 1.025 1.24469
30 30.0 571.4 0.063 1.043 0.91877
40 40.0 566.7 0.269 1.251 0.64222
50 50.0 571.9 0.055 1.039 0.41506
60 60.0 569.4 0.089 1.075 0.23728
70 70.0 568.4 0.048 1.035 0.10889
80 80.0 568.6 0.002 0.989 0.02988
90 90.0 469.7 0.001 0.988 0.00025
コマンド一つで (これはノード内ですが) Horovod を使った MPI ジョブが実行できちゃうなんてやはりコンテナは便利ですね!
まとめ
NVIDIA GPU Cloud のコンテナーを、数種類のクラウドと自宅の PC で動かしてみました。
NGC 対応クラウドでは GPU ドライバと NVIDIA Docker インストール済みの仮想マシン イメージが使えるのでとても簡単。それ以外の環境でも、NVIDIA Docker の環境さえ作ってしまえば、あとは毎月更新される最新のコンテナーを活用することで、環境構築とメンテナンスをかなり効率化できます。是非お試しを!