サンプル的にブロック崩しの設定厳しめゲームを作った。機械学習の勉強も兼ねて強化学習を学んでみようと、このゲームをML-Agentsを使って学習させてみようと試みた記事。。。
始まりはこの本。
https://www.borndigital.co.jp/book/6702.html
しかし・・・ml-Agents色々変わってるし。。結局GitHubのドキュメントみながら一つ一つやっていくことになる。。
(強化学習の概要を、マップ探索で説明してあって個人的にはわかりやすかった。)
環境構築
OS:macOS Mojave(10.14.5)
Unity
まずは、Unityのインストール。既に2018.03が入っていたがバージョンアップしてみる。。(バージョンアップで非対応コードが出ないか心配。。)=>Unity-Hubを導入。
https://unity3d.com/get-unity/update
今まで使ってなかったけど、各種バージョンを一元管理できるので便利ですね。
(前バージョンからのマイグレーションも自動。。)
※大したことしていなかったので、マイグレーションが問題なく完了。
ML-Agents
UnitySDKのサンプルを動かしてみる
次は、ML-Agents Toolkitをclone。適当にディレクトリを作成して。
git clone https://github.com/Unity-Technologies/ml-agents.git
落としてきたら、Unityでサンプルを動かしてみる。
- UnityHubで「リスト追加」→ml-agents/UnitySDKを開く
- Unityバージョンを最新に設定
開いたあとは(とりあえず3DBallでも・・・)
- Assets/ML-Agents/Examples/3DBall/Scenesの3DBallを開いてシーンをロード
- Ball 3D AcademyにセットされいてるBrains Assets/ML-Agents/Examples/3DBall/Brains/3DBallLearningのModelにAgents/Examples/3DBall/TFModels/3DBallLearningをセッ
- Playを実行
プレートがバランスを取りながらボールを落とさないように動くサンプルが確認できる!!
PythonとmlagentsPackageを入れる
Pythonは既にpyenvを入れていたので、ml-agentsを入れたディレクトリ配下のpython環境を3.6.6に設定
$ pyenv local 3.6.6
$ python --version
Python 3.6.6
$ pip3 install mlagents
※ここで”You are using pip version 10.0.1, however version 19.1.1 is available.”アップグレードしろと。
$ pip3 install --upgrade pip setuptools
※依存関係の諸々で”pip3 install --upgrade pip ”だとうまく更新できず。。色々ググったらこれでいけた。(upgradeの方にもpip"3"付けたくなりますよね。。。)
あとはそれぞれのフォルダ配下でインストール
$ cd ml-agents-envs
$ pip3 install -e ./
$ cd ..
$ cd ml-agents
$ pip3 install -e ./
ml-agentsを起動して学習の確認
Unity側
AcademyのControlチェックボックスのチェックを入れる(入れないと学習したBrainsをロードして動く)
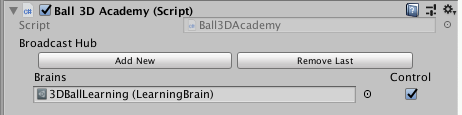
ml-agent側:
$ mlagents-learn ../config/trainer_config.yaml --run-id=sample[これはなんでもOK] --train
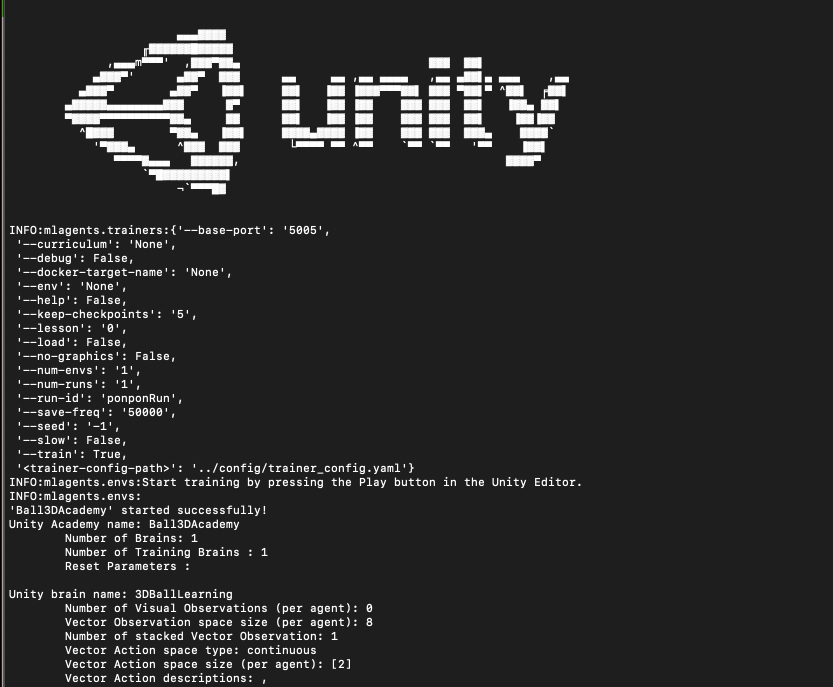
こんな具合に実行されてれ以下メッセージが出るのでUnity側を実行すると動く!!
INFO:mlagents.envs:Start training by pressing the Play button in the Unity Editor.
INFO:mlagents.trainers: ponponRun-0: 3DBallLearning: Step: 1000. Time Elapsed: 11.224 s Mean Reward: 1.207. Std of Reward: 0.728. Training.
INFO:mlagents.trainers: ponponRun-0: 3DBallLearning: Step: 2000. Time Elapsed: 22.257 s Mean Reward: 1.296. Std of Reward: 0.759. Training.
INFO:mlagents.trainers: ponponRun-0: 3DBallLearning: Step: 3000. Time Elapsed: 33.052 s Mean Reward: 1.523. Std of Reward: 0.838. Training.
INFO:mlagents.trainers: ponponRun-0: 3DBallLearning: Step: 4000. Time Elapsed: 43.845 s Mean Reward: 1.806. Std of Reward: 1.128. Training.
INFO:mlagents.trainers: ponponRun-0: 3DBallLearning: Step: 5000. Time Elapsed: 54.400 s Mean Reward: 2.777. Std of Reward: 1.975. Training.
INFO:mlagents.trainers: ponponRun-0: 3DBallLearning: Step: 6000. Time Elapsed: 65.174 s Mean Reward: 3.922. Std of Reward: 3.448. Training.
INFO:mlagents.trainers: ponponRun-0: 3DBallLearning: Step: 7000. Time Elapsed: 75.998 s Mean Reward: 7.204. Std of Reward: 6.900. Training.
INFO:mlagents.trainers: ponponRun-0: 3DBallLearning: Step: 8000. Time Elapsed: 86.734 s Mean Reward: 9.579. Std of Reward: 10.298. Training.
INFO:mlagents.trainers: ponponRun-0: 3DBallLearning: Step: 9000. Time Elapsed: 97.146 s Mean Reward: 17.802. Std of Reward: 18.521. Training.
INFO:mlagents.trainers: ponponRun-0: 3DBallLearning: Step: 10000. Time Elapsed: 108.207 s Mean Reward: 22.553. Std of Reward: 23.049. Training.
INFO:mlagents.trainers: ponponRun-0: 3DBallLearning: Step: 11000. Time Elapsed: 119.127 s Mean Reward: 54.259. Std of Reward: 35.250. Training.
INFO:mlagents.trainers: ponponRun-0: 3DBallLearning: Step: 12000. Time Elapsed: 129.911 s Mean Reward: 58.905. Std of Reward: 35.462. Training.
INFO:mlagents.trainers: ponponRun-0: 3DBallLearning: Step: 13000. Time Elapsed: 140.319 s Mean Reward: 64.107. Std of Reward: 38.436. Training.
INFO:mlagents.trainers: ponponRun-0: 3DBallLearning: Step: 14000. Time Elapsed: 151.080 s Mean Reward: 73.244. Std of Reward: 33.077. Training.
INFO:mlagents.trainers: ponponRun-0: 3DBallLearning: Step: 15000. Time Elapsed: 161.689 s Mean Reward: 74.694. Std of Reward: 35.027. Training.
INFO:mlagents.trainers: ponponRun-0: 3DBallLearning: Step: 16000. Time Elapsed: 172.868 s Mean Reward: 94.123. Std of Reward: 20.358. Training.
INFO:mlagents.trainers: ponponRun-0: 3DBallLearning: Step: 17000. Time Elapsed: 183.989 s Mean Reward: 95.277. Std of Reward: 16.361. Training.
INFO:mlagents.trainers: ponponRun-0: 3DBallLearning: Step: 18000. Time Elapsed: 193.713 s Mean Reward: 94.962. Std of Reward: 17.454. Training.
INFO:mlagents.trainers: ponponRun-0: 3DBallLearning: Step: 19000. Time Elapsed: 204.282 s Mean Reward: 86.887. Std of Reward: 22.600. Training.

初めは落とす落とす。。。
からの

プレートがバランスを取るようになるのがわかる。。。
学習したファイルのロード
学習ファイルは以下フォルダに格納される。
./models/sample[起動時に指定したrun-id]/3DBallLearning.nn
ファイルをUnity側プロジェクトのAssetsにコピーして以下で読み込む。
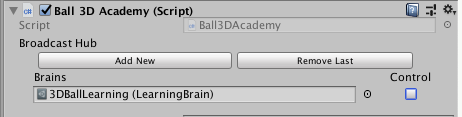
・AcademyのControlチェックを外す
・Brainsをダブルクリックする
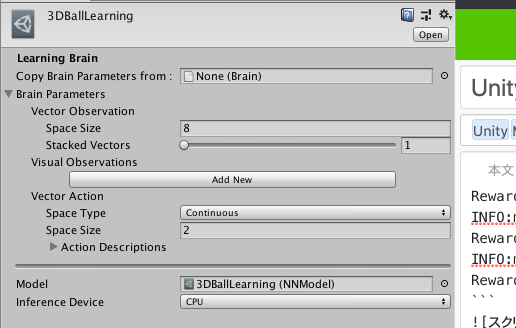
3DBallLearningがInspectorに表示されるので、ここのModelにコピーしたXXXX.nnファイルをドラック&ドロップする。
最後に実行すれば学習したデータが読み込めます。
参考
環境構築および動作確認
https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Installation.md