FaceVTuberの紹介
FaceVTuberは2018/3/12にリリースされた,ブラウザとWebカメラのみで誰でも簡単にVTuberになれるアプリです.
デフォルトで3Dのモデルも入っており,ブルーバック機能,動画生成機能,MMD/FBX/VRMのモデルのロード機能を搭載しています.これらがブラウザのみで動きます.
「最近流行のバーチャルユーチューバーになりたい!!」
— FaceVTuberOfficial (@FaceVTuber) 2018年3月12日
でも,特別なハードウェアが必要だったり,ソフトウェアの設定が大変だったり,難しい!!
そんな悩みを解決するのがFaceVTuber!!
ブラウザで動く,簡単バーチャルユーチューバー体験をみんなでしよう!! https://t.co/bcTbdr36UR#FaceVTuber pic.twitter.com/NCyxe31oK3
Qiitaに他にも記事を書かせてもらっています.
他にも色々反響をいただいており,ファミ通さんのコラムに載せていただいたり,VTuberハッカソン展で発表させていただいたり,サポーターズさんで発表させていただいたりしています.
- FaceVTuberの開発者が見た バーチャルYoutuberの世界 ~バーチャルYoutuberのイママデとコレカラ~
- FaceVTuberの開発者が見たバーチャルYoutuberの世界 ~バーチャルYoutuberとファンとビジネスと~
- FaceVTuberの開発者が見た バーチャルYoutuberの世界 ~VRMのセカイとVTuberアプリの変遷~
FaceVTuberで導入している誰でも簡単にVTuberになるための技術をご紹介したいと思います.
FaceVTuberの課題
課題に関しては割とシンプルです.
全てがWebカメラによる顔の誤認識の戦いです.
Webカメラで,いかに誤認識を減らすか?誤認識をしてもいかに不自然な動きをさせないか?いかに認識がずれている中でも美しいムーブをさせるか?そういった,ちょっとしたVTuberシステムに関する隠し味のようなノウハウを公開したいと思います.
顔認識の移動制限処理
以下は初期のFaceVTuberの動画です.
やべぇ https://t.co/2TBD36gNlj#FaceVTuber pic.twitter.com/V0z3cKGzHW
— ina_ani (@ina_ani) 2018年3月12日
途中で顔が突然外れモデルが動き出しています.そのため,かなり不自然な動きをしています.それを低減するための施策が「顔認識の移動制限処理」です.
t=iの時点で観測したデータをx[i]とし,移動制限処理をしたデータをy[i]としたとき,以下のような処理をしています.
d = abs(x[i] - y[i-1])
if d < limit:
y[i] = x[i]
else:
if x[i] > x[i-1]:
y[i] = y[i-1] + limit
else:
y[i] = y[i-1] - limit
1フレーム前のデータと差分をとり,それをlimitと比較して小さい場合は,処理したデータとして採用します.そうでない場合,ノイズの影響で大きく動いて不自然な動きの可能性があります.そのため,最大でもlimitしか動かないように調整します.
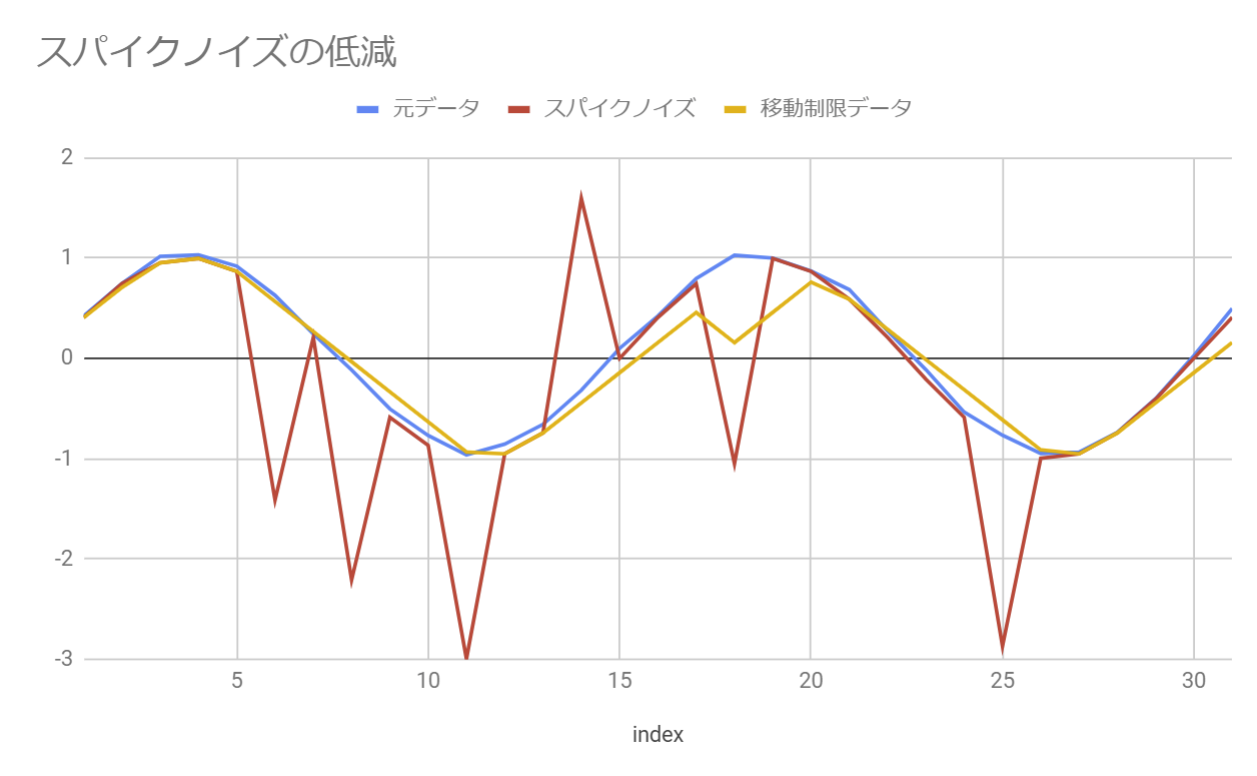
シミュレーションしたデータとしてはこんな感じになります.青い線が元データ,赤い線が顔認識が大きく外れた想定のデータ.そして,先ほどの手法を適用したのが黄色の線になります.これを見てわかるように黄色の線が青い線に近づいていることが分かります.そのため,突然顔認識が外れても,なめらかに動かすことができます.
顔認識の移動の移動平均フィルタによるローパス処理
先ほどの移動制限処理で大きく外れる処理を防止することができました.しかし,美しいVTuberのモーションを作るためには全体的な滑らかさが足りません.また,先ほどの移動制限処理を加えたといえ,外れた瞬間に,ガクッとなる感じは否めません.そのため,FaceVTuberでは移動平均フィルタによるノイズ低減を行っています.ここでは基本的な考え方だけ説明いたします.
t=iの時点で観測したデータをx[i]とし,処理をしたデータをy[i]としたとき,以下のような処理をしています.
y[i] = 0.25 * x[i] + 0.25 * x[i-1] + 0.25 * x[i-2] + 0.25 * x[i-3]
実際シミュレーションしたグラフが以下のようになります.

青い線が元データとしたとき,赤い線がノイズが含まれたデータとなっています.それを上記式でノイズ低減を行った場合,黄色の線になります.このグラフを見ても分かるように,赤い線に比べて,黄色の線がなめらかになっていることが分かります.このようにノイズのある中でもなめらかな動きになるように調整しています.
実際,x[i]の係数や,いくつ過去のデータを見るかはかなり調整しています.これらはデータの取得間隔や,見え方にも左右されるので,パラメータのチューニングが必要になります.
リップシンクのための口形の認識アルゴリズム
FaceVTuberでは画像による口形の認識アルゴリズムを搭載してます.おそらく他のVTuberシステムでは搭載していないシステムだと思います.一応ファーストリリースの時からあったりする機能です.
アルゴリズム自体は非常にナイーブなモノだったりします.

赤い線が"唇"だと思ってみてください."あ"の口は横の幅に対し,縦の幅が大きくなっています."い"の口は縦の幅に対し,横の幅が大きくなっています.それらに対し,"う"の口は,縦と横の幅がほぼほぼ同じになっています.この事実をプログラムに落としただけです.
rate = mouse_height / mouse_width
if i_limit > rate:
return "i"
elif a_limit < rate:
return "a"
else:
return "u"
これを見て,具体的な値は?とか思われるかもしれませんが,正確な値はよくわかりません.FaceVTuberでは自分の"あ","い","う","え","お"を発話して,そのパラメータを埋め込んでいます.本来であれば色々な人のデータを集めて,顔認識のパラメータをチューニングするのが良いですが,個人では限界があります.そのため,FaceVTuberのリップシンクのデータは作者の私のデータを利用しています.したがってFaceVTuberのリップシンクを一番うまく扱えるのは私だったりします(笑)
パカパカ問題
これはいろんなプロダクトでありがちな問題ですが,リップシンクが高速でパカパカする問題があります.もしくはしゃべってもいないのに,口元がもごもごする.みたいな挙動をするVTuber.もしくはVTuberアプリがあったりします.これは主にノイズが原因で,その画像認識・音声認識の結果をVTuberのモーションとして適用しすぎていることが原因だったりします.そのため,ある程度,データを鈍す必要があります.
if mouse_height > limit: # 口を開けたとき
open_count += 1
else: # 口が閉じてるとき
open_count -= 1
if open_count > n: #ある一定回数,口を開けてると判定されたとき
state = detect_emotion()
if state == "a": # "あ"を認識した場合
a_face += face_diff
elif state == "i": # "い"を認識した場合
i_face += face_diff
elif state == "u": # "う"を認識した場合
u_face += face_diff
else: # それ以外は,口を閉じる判定
a_face -= face_diff
i_face -= face_diff
u_face -= face_diff
ある一定回数,口を開けている判定が走らないと,リップシンクをしない設定にしています.また,リップシンクで判定した後も,face_diffの分だけしかモーフのパラメータを進めず,滑らかに動くように調整しています.
リップシンクの課題
「一応ファーストリリースの時からあったりする機能です.」といったのは理由がありまして,それには,リップシンクの機能が認知されていないからです.そこには2つの原因があります.
1つ目はデフォルトモデルの口が小さい
FaceVTuberのデフォルトモデルでは中野シスターズさんのモデルを使わせてもらっています.モデルの都合でもあるのですが,顔の面積に比べて,口のサイズが小さいです.そのため,動きが小さくなってしまってます.

例えば,MMDのキズナアイさんのモデルでやってみた場合,以下のような表示になります.

これを見てわかるように顔のサイズに比べて,口のサイズが大きいことが分かります.そのため,"しゃべりが分かりやすい"モデルになっていることが分かります.このようにモデルによって,口のサイズによって,リップシンクが"映える",”映えない”の差があることが分かります.
もう一つは
2つ目は遅延問題
です.先ほどの「パカパカ問題」のため,データを鈍すことをして,なめらかに動かすことができました.しかし,一方で,応答性能が犠牲になっています.これが割と致命的な部分があります.先ほど軽く実験してみたところ,「あいうえお」と話すのに1.2秒かかりました.平均的なWebカメラのフレームレートが30fpsとすると36フレーム.1文字あたり,7フレーム未満で判断する必要があります.体や顔等のモーションは大雑把なモノでも違和感はありませんが,口はあまりにも速く動きすぎなのです.そのために遅延がひどく,あまり認識してる感が少なくなっている.という問題があります.
プロダクトデザインとのトレードオフ
おそらく「音声認識でやればいいのでは?」と思われたと思います.例えばOVRLipsyncなどのリップシンクエンジンは音声認識です.またこれをベースに作られているAniLipSync,それを採用している東雲めぐさんなども音声認識です.
では,**「なぜわざわざ画像認識にこだわるのか?」**という疑問があります.**これはFaceVTuberがVTuberアプリの最初期に出たこと.**に起因しています.
FaceVTuberは2018/03/12に出たVTuberアプリです.その当時,「FaceRigとLive2DというものでVTuberになれるらしい」「HTC Viveを買って,UnityでプログラミングをしないとVTuberになれない」といった,現時点から考えれば,「VTuberになる」というのは,かなりのハードルの高いものでした.そこで,私がFaceVTuberを作り,リップシンクを見て,改良しようと思いました.しかし,ある疑念が頭をもたげました.
「Webカメラの他にマイクまでユーザーに用意させてしまうとハードルが上がって使われないのではないか?」
このあたりの"プロダクトデザインのさじ加減"は非常に難しかったです.この時期,私からすればお手本にすべきVTuberアプリなど"無い"のです.ここでプロダクトデザインの最初に立ち返りました.
「もっと簡単にVTuberになりたい」
ということを考えたとき,できる限りハードウェアの購入を少なくすることが一番良い選択肢だ.やはりマイクではなく画像認識で行うべきだ.という判断をし,画像認識で突き通し,今に至ります.
顔認識技術の限界
現在使用しているライブラリの実装
顔認識技術はFaceVTuberでの基盤技術になります.そのため,一部論文のサーベイもしていました.
これは,FaceVTuberが使っているclmtrackrの元となった顔認識のライブラリの論文ですが,ここにpoint distribution modelの記載があります.
https://ci2cv.net/media/papers/2011_IJCV_Saragih.pdf
point distribution modelの解説自体はこれが分かりやすいです.
https://www.slideshare.net/takmin/201205016-deformablemodelfitting
一部,スライドを引用するとPDMは点群の教師データからPCAで基底をとります.
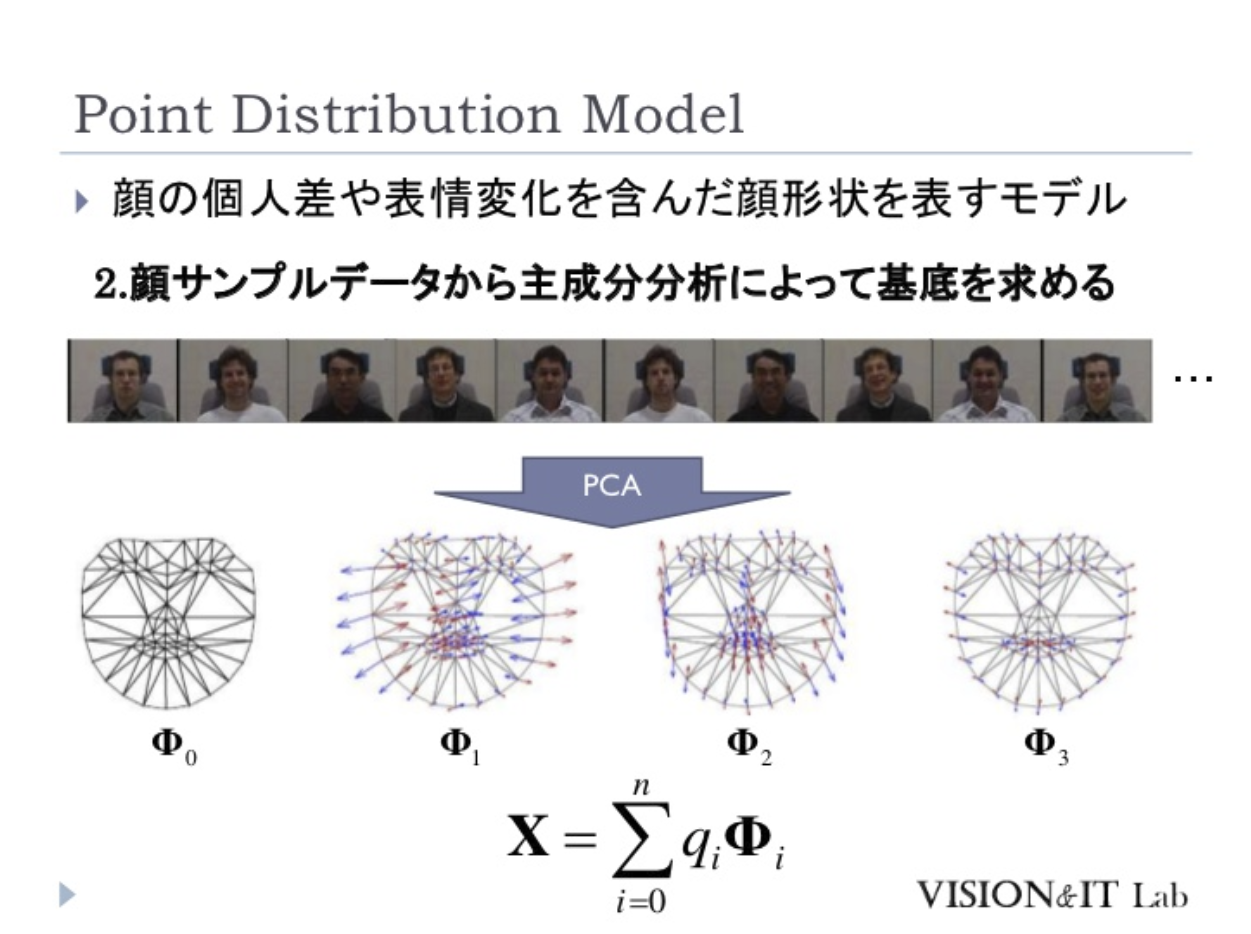
その後,形状パラメータを回転や移動などのパラメータで変形させたものとフィッティングしているんだろうと流し読みしていました.

そうすると基底から外れた顔の画像の認識,横向きの顔画像は厳しいものがあるんだろうな.と認識していました.
実際,FaceVTuberでの現象として基底からのずれの大きそうな斜めの顔,横の顔が非常に弱いです.
比較的新しい論文の実装
また,Dlibの実装を調べているうちに見つけた記事があって,
Face Alignment at 3000 FPS via Regressing Local Binary Features
などが一番示唆的でした.これは顔認識の論文を実際にC++で実装をしてみた方の感想ですが,
この手法も含め、顔特徴点検出では学習時に正解形状を正規化するものがほとんどだと思います。
そのため実際に学習済みモデルを運用すると、実データの顔の正規化ができないため精度が悪くなります。
ウェブカメラの映像を入力にして自分の顔で実験してみると、おおよそ顔の向きは合っているものの細かいパーツのアライメントがうまくいきませんでした。
このあたりの実運用時のテクニックがよくわからないので、まだDlib並の精度は達成できていません。
このあたり,割と新しい論文でも厳しかったり,別のノウハウが必要なのだなぁ.という臭いを感じ取りました.
DeepLearning?
精度=DeepLearningの話になりがちですが,これもなかなか厳しい話があります.
Real-time Human Pose Estimation in the Browser with TensorFlow.js

今年の5月にTensorflowのモデルがブラウザのjsで動くようになりました.このgifアニメのようにWebカメラからボーンの推定が出来るようになりました.そういう状況下であるならば,VTuberアプリなど簡単なのでは?と思うかもしれません.
実際のデモを見てもらえばわかるのですが,私の手元のVRReadyでないマシンで動かすと20fpsを切っています.腐ってもプログラマなので,そこそこ良いマシンを使っていますが,一般の方はどうでしょうか?そういうことを考えた場合,Tensorflowをブラウザで"リアルタイム使用"というのは結構厳しい.という判断をしました.
モーションブラーを想定していない設計
FaceVTuberを開発しているうちに,画像認識において2つの問題があることに気づきました.その1つは前にあげた「横顔に弱い」という点でした.これは今のclmtrackrの実装を別のものに差し替えることで何とかなると思います.しかし,そうでないパターンで顔認識が外れていることに気づきました.
「動いたときに顔認識がはずれる」
ということでした.あまりにも速い動きの場合,画像認識できないというのは想像に難くないと思います.しかし,それにしても認識が悪いと感じてます.そこには実は2つ問題があると予想しています.「Webカメラである」「顔認識のライブラリや実装のメインターゲットが静止画である」ということです.前者はカメラの性能の問題です.一般的なデジカメに比べて,Webカメラはシャッタースピードなどが遅く,ぶれてる絵になりがちです.そのため,モーションブラーがかかったような絵になり,認識精度が悪くなっています.また,後者の話にもかかってきますが,顔認識のデータセットは静止画が多く,動画に対応したものは私は見たことがないです.この辺の動画像への対応は,論文が,論理体系が.というより,自分でモーションブラーの削減等を前処理で挟むべきです.しかし,この部分を触るにはライブラリのコードから画像処理の該当部分を探し当て,変更し,精度評価をするという作業が発生し,かなり骨の折れる作業です.もしくはフルスクラッチで顔認識を勉強し直し,組んでみる.というのも1つでありますが,VTuberのビジネスの動きの速度感などを考えると現実的ではないです.実際,clmtrakrの実装を少し読んでみようとチャレンジをしましたが,clmtrackrは内部的にビデオ映像を取る実装にServiceWorkerやWebGLを使っている様だったので,さらにハードルが高くなってしまい断念しました.
誰でもVTuberになれる世界
**「誰でもVTuberになれる世界」は,実現されました.え?と思われるかもしれませんが,ほぼほぼ事実です.
1年前,VTuberになるには,ほぼ2つの選択肢しかありませんでした.「FaceRigとLive2Dで自作する」「3Dモデルをモデリングし,Unity+FinalIK,HTC Viveで自作する」この2つでした.これらは一般の人にはあまりにもハードルが高く,技術者しかVTuberになれないレベルでした.しかし,現在,Vカツ,カスタムキャスト,Reality Avatar等々,VTuberになれるアプリは30を超えています.2017年末に夢見た「誰でもVTuberになれる世界」は,ほぼほぼ実現されました.一方で,「VTuberになれること自体には価値がなくなった」とも言えます.**少なくとも,この夏ぐらいには,多くの人の興味が「恋声」などの音声変換系に向き始め,このあたりから,**本当に画像認識を極めて,FaceVTuberに組み込むことが正しいのか疑問に感じ始めました.**上記した画像認識の論文の調査の文章を見て,少しロジックに破綻があったり,調査不足な感じを受けると思いますが,このあたりが影響しています.もし極めたとしても,それがVTuberに対して良い結果を生むんだっけ?と.
FaceVTuberの誤算,VTuberアプリの今,コレカラ.
**無料でVTuberになれる"だけ"のアプリというのはビジネスが崩壊している.**ということを割と痛感しました.自分の周りの人にインタビューしてもらいたいですが,何人がプライベートで創作活動をしていますでしょうか?何人が生放送をしたことがあるでしょうか?そもそもプライベートで創作活動を行っている人数が少なすぎるのです.そのような,マーケットが小さい部分で無料でアプリを提供し,広告モデルで稼ぐ.というのはかなり無理があり,アップセルを出せないプロダクトは自走するのが難しいということを痛感いたしました.そのような分野で稼ぐには,そこそこ高い値段でアプリを公開する.もしくは,月額課金のモデルが王道なんだろうと思います.したがって,本当に"VTuberになれる"ことだけに特化して,しかもそれを無料で行い,広告モデル(もしくはビジネスモデルなし)で回収はかなり無茶な話になります.
そういうことを考えると,VTuber+配信(+投げ銭)の形は,整っていると感じます.ちゃんとしたマネタイズのポイントを持ち,クリエイターだけでなく消費者を巻き込む形で,そもそものアプリを使用するユーザーの母数を増やせる.ということで正しく回せるビジネスモデルなんだろうな.と感じています.
少なくとも2017年末では「VTuberになれる」というのが,このVTuber周辺の第一目標でしたが,その次のフェーズ「VTuberアプリで収益化できる」というフェーズに移ったように思います.この記事を書いているうちにもVRoidHubやthe Seed onlineが公開され,もう一段,進み始めていると思います.しかし,一方で,「マリオ」が存在しない.という課題があるように思います.「VTuberアプリ」(ファミコン)が出ている状態で,その上に載ってくる「爆発的に流行るキャラクター」(マリオ)が存在しないように思えます.どうしても強いIPのキャラクターはYoutubeがメインの活動場所になってしまっている印象で,むしろ強いIPになればなるほど母数の効果が出てしまうので,Youtubeに出てしまう方が稼げる.といった懸念も若干感じます.みんなが「マリオ」をやりたいがために「ファミコン」を欲しがるような状況になるのが理想だと思います.
しかし,最近のVTuberアプリの多様性は非常に面白いな.と思っていて,VTuberになることに興味がなかった人をVTuberにする.というアプローチだと,VDRAWが素晴らしいアプローチですし,教育コンテンツとつなげるTeraconnectは別分野への筋道を開拓しており,非常に面白くなっています.個人的にはSlideGoなんかも好きです.順当な進化であると,VWorldなどのメタバース.アプリ同士をつなぐPFとしてのVRoidHubなど面白い動きもあります.このように"VTuberを知らない人が知れる.そしてVTuberになる理由がある"プロダクトは,今後,新たな分野を作ったり,別の方向で成長させるのではないでしょうか.
人生とFaceVTuber
大層な題名をつけていますが,それほどFaceVTuberとは自分の人生には大きなプロダクトでした.
リリースした初日,知り合いの先輩のツイートを皮切りに全てが走り始めました.
自分が思った以上にインパクトは強く,RTやイイねがガンガン回りはじめ,一部のプログラマの方々からは,「俺も作ってたのに!!」と阿鼻叫喚していたのも見てました.
自分で作品を作ったのは色々ありましたが,ユーザーに提供する形でプロダクトを出したのは,2つ目くらいでした.そんなものがいきなり24時間の内にWebメディアに掲載され,次の日にはガンガン問い合わせの入るようになるのです.
私は普通のフルタイムのサラリーマンですが,一番忙しかった日は,出社して午前中に仕事をして,昼休みに社外の人とヒアリングを兼ねたランチミーティング,そのあと午後の業務が終わった後,別の会社に出向いてミーティング,2時間ぐらい議論した後,家に戻り,Twitterの確認をしてみると,別の会社からの問い合わせがあり返信しつつ,ユーザー対応,サービスの数値確認し,午前3時までプロダクト開発.寝て,出勤.みたいな生活をしてました.
他にも,普通に仕事が終わった後,休日を含めて,月に10件ほどVTuberの相談やイベントに参加したときもありました.
リリースする前は,ほぼほぼ会社の後は家に帰るだけの生活でしたが,人間こんだけ無茶ができるものだな.とあらためて思いました.そして,一旦無茶すると無茶の仕方と力の抜き方を覚えて,意外に慣れるものだということが分かりました.
今は30を超えるVTuberアプリが出ています.その中で,FaceVTuberのようにWebで動くもの.というのはかなり珍しい部類です.3,4個あるかないかぐらいです.
FaceVTuberは今後どうするの?とよく聞かれますが,私にもわかりません.ここまで急速にVTuberアプリがコモディティ化するとは予測していませんでしたし,これほど大手が突っ込んでくるとも思っていませんでした.私もどう成長させようか.いろいろ思案しております.もし案があったり,自分の事業領域とあってる.みたいな話でFaceVTuber自体を事業譲渡してほしい.という話もありましたら,ご相談を承ります.
今ぐらいの時期でしょうか.「そろそろVTuberが来る.」と自分の中に確信になり,技術検証をちゃんとしようと思い始めたのは.FaceVTuberのプロトタイプは正月休みに生まれました.
この年末は次の一手につなげないといけないですね.Next FaceVTuberか.それともまた別のプロダクトか.
@Nekomasu さん曰く,
やらなければ,はじまらない
本当にこの言葉通りだと思います.やりたいことを明日やる理由はないです.今やるべきです.
色々と悩みも葛藤もありましたが,この一年間でFaceVTuberで普通ではあり得ない人生を経験させていただきました.勉強になりました.FaceVTuberをリリースして本当に良かったと思います.
では,みなさん良いクリスマスを!そして,良いお年を!