スマートグラスの動向と考察
11/16の技術書典19で「スマートグラスの動向と考察 2025年版」という本を頒布いたしました。
そもそもスマートグラスとは何か。というと、これは書籍でも迷いましたが、
スマートグラスとは「眼鏡型のガジェット」
としています。これは、「スマートグラスと呼ばれるもの」が多すぎるためにこのような定義をしました。最近の話題では、Even G2という非常に軽くディスプレイのついた評判のいいスマートグラスが日本で取り扱われることが話題になっていました。
そのような中で、私はスマートグラスについて仮説がありました。
- スマートグラスは普通の眼鏡に対して重すぎるため常時着用できない
- スマートグラスは電池の容量が少ないため1日中利用できる製品がない
という2つです。これは、あくまで仮説にすぎません。私の妄想かもしれません。では、それをちゃんと検証してみよう。ということが私の執筆の取り組みの1つでした。この記事では1の「スマートグラスは普通の眼鏡に対して重すぎるため常時着用できない」について数理モデルを立てて考えた話について書きたいと思います。
普通の眼鏡ってなに。
私自身、眼鏡ユーザーであり起きている時間は常に眼鏡をかけています。そのため、なんとなく眼鏡について知った気にはなっていました。しかし、スマートグラスを何個か買ったり試したりする中で、「スマートグラスって重たくて付け心地悪いなぁ」という課題を感じていました。しかし、それは私の主観、体感にすぎないかもしれません。実は、スマートグラスと一般的なメガネは重量的には同じで、それ以外の要因で付け心地が悪い。と感じているのかもしれません。そう考えたとき、普通の眼鏡の重さってどれくらい? という疑問が生まれました。
ChatGPTに聞いてみたところ、以下のような回答でした。

おおよそメガネは20~40gという結果になっています。AIはうそをつくこともあるので、どれくらいこの話が普通なのか自分で調べてみようと思いました。
JINSにみる眼鏡の重量分布
例えば、JINSのBasic Matteという製品を見てみます。

このようにJINSのページにはサイズやスタイル、性別、重さといった情報が書かれています。ということは、JINSの眼鏡の情報を集めれば、眼鏡の標準的な重さの範囲が分かるのではないか? と思いました。そこで、2025年10月18日時点でオンライン在庫のある製品475種類について調査いたしました。
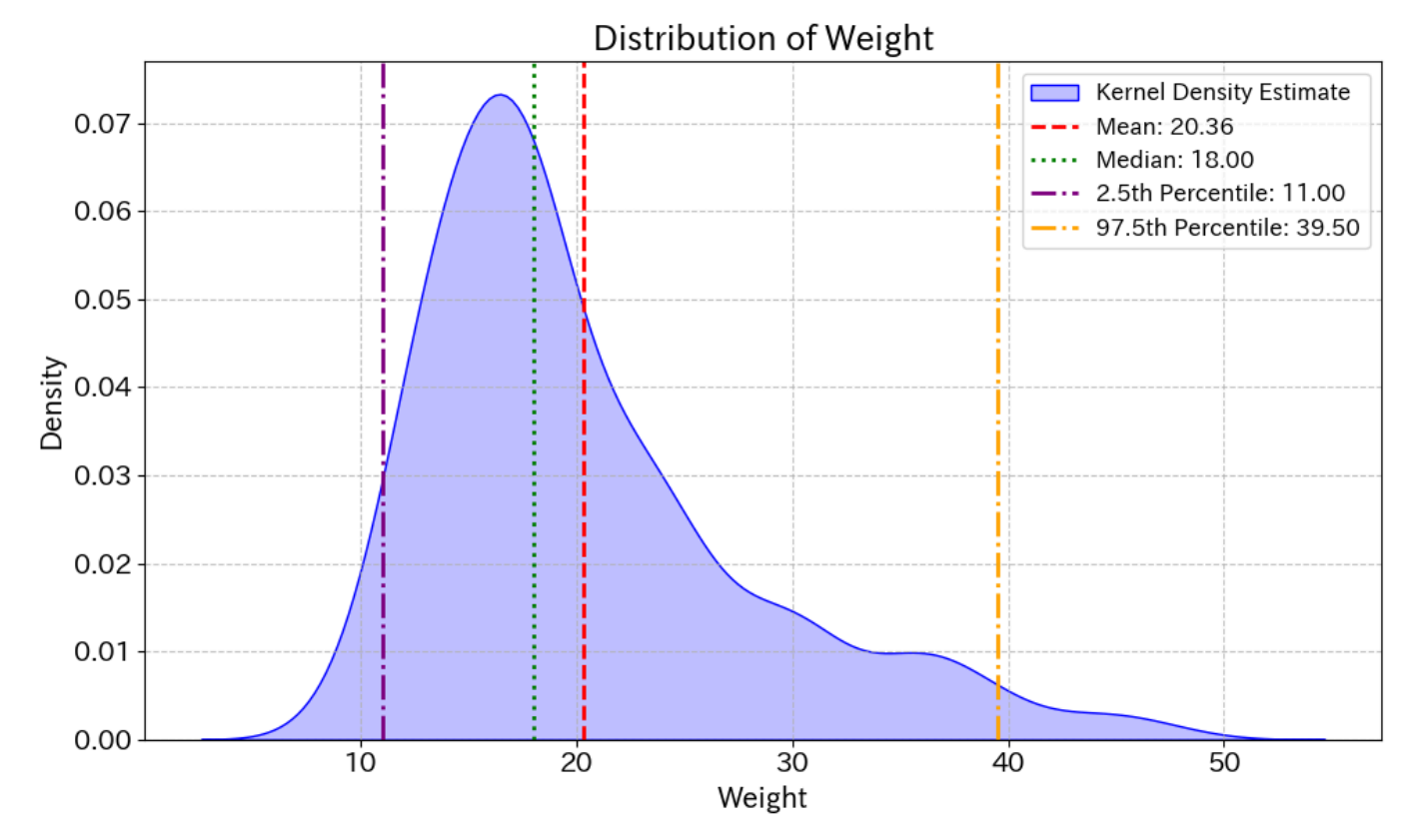
そうすると、一般的なメガネ(JINS)の重さの平均は20.36g、2.5パーセンタイル値が11.00g、97.5パーセンタイル値が39.50gとなりました。こう考えると、先ほどのChatGPTの答えはかなりあってる。ということになります。
先ほど、Even G2というスマートグラスを話題に上げましたが、以下のURLでレビュー記事があります。
これにより、G2は36gとわずかに軽量化されただけでなく、よりスタイリッシュになっています。
引用文は翻訳したものですが、Even G2は36gだそうです。そう考えると、いかに最新のスマートグラス製品でも、眼鏡としては重い部類であるかが分かると思います。
眼鏡を表すパラメータ
先ほどのJINSのページには色々なデータが書かれています。例えば、
サイズ: 54□16-149○31
と書かれています。これは、JINSのページにも書かれており、
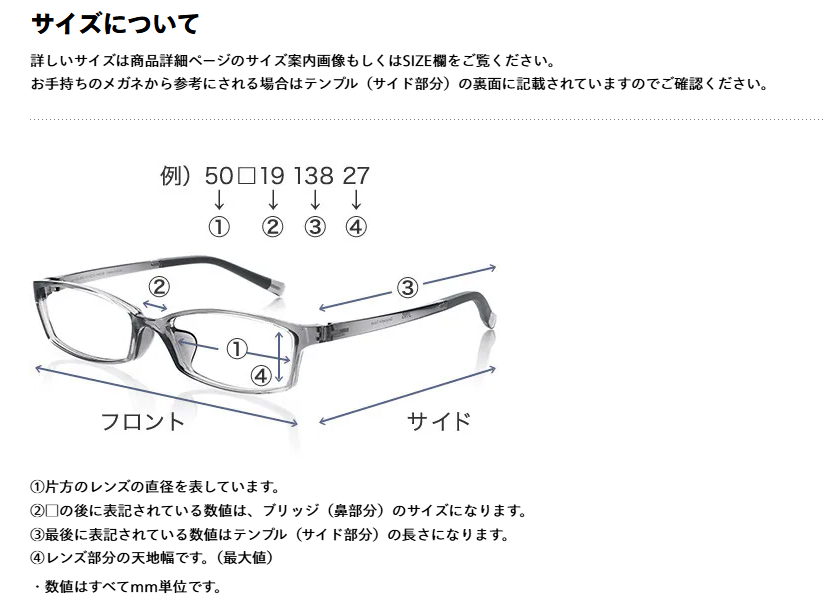
このようにそれぞれの形を特徴づけるパラメーターとして、この4つが表記されています。今回、執筆にあたり、いろんなスマートグラスについても調べてみましたが、おおむねこのような表記がされています。
例えば、HTC社のスマートグラスであるVIVE Eagleにも似たような表記があります。

先ほどのJINSのサイトを見てもらうと分かるのですが、かなり細かい情報が書かれています。このような4つの眼鏡の寸法、性別、鼻パッドなど記載が色々とあります。そこで、私は思いましたこれパラメーターから回帰モデル作れるんじゃね? と。
JINSのデータを整理すると以下のような値になります。
- カテゴリ変数
- スタイル
- シリーズ
- 性別
- ノーズパッド形状
- 材質
- フロント
- テンプル
- 数値変数
- レンズの横幅①
- ブリッジ部の長さ②
- テンプルの長さ③
- レンズの縦幅④
これらの値から重量に関する回帰モデルを作れるのでは?という直感がありました。
重量の回帰モデルの作成
今回、執筆最中に思いついたので、そこまで時間をかけてられないというのが現実問題としてありました。そこで、前々から興味を持っていたAutoML系を使ってみようと思いました。今回使ったのはpycaretというライブラリです。
s = setup(data = df, target = 'weight', ignore_features = available_ignore_features
, session_id = 123, verbose = True)
models = compare_models(exclude=['lightgbm'], verbose = True, n_select=10)
for model in models:
tune_model(model, search_library="optuna", verbose=True, tuner_verbose=True, n_
iter=10)
best_model = automl()
執筆最中に色々な調整はしましたが、本質的にはこれくらいしかやっていません。目的変数をweightとして、ignore_featuresでidなど内部的に利用していたパラメーターを削除。それをcompare_modelsで最適化し、TOP10を取り出します。lightgbmは時間がかかりすぎたので除外しました。そして、先ほどのmodelsに対して、optunaを用いてtune_modelを用いて最適化します。そして、最後にautomlでベストなモデルを選定させます。
結果、Gradient Boosting Regressorが選択され、R2係数が0.8643と比較的精度の良いモデルが得られました。
| Model | MAE | MSE | RMSE | R2 | RMSLE | MAPE |
|---|---|---|---|---|---|---|
| Gradient Boosting Regressor | 1.8446 | 7.827 | 2.7977 | 0.8643 | 0.1144 | 0.0906 |
実際の値と、予測値をプロットしたグラフを描いてみると以下のようになっています。

こう見ると何件かの外れ値はあるものの、かなり精度のいい予測をしています。では、どの変数がどれくらい影響を与えているのか。という話は、紙面(電子書籍)の方で解説しています。
回帰モデルの勘
この場合、回帰はうまくいくだろうな。という予感がありました。理由は3つあります。
- レンズの縦横の長さデータがあること
- テンプルの長さのデータがあること
- フロント・テンプルの材質のデータがあること
まず1についてですが、レンズの縦横の長さデータがあるということは面積が分かります。メガネのフロント自体の厚さが約3~5mm程度であると考えると、ある程度の体積が分かります。そして、3のフロントの材質のデータがあるので、1立方センチメートル当たりの重さ、比重が分かります。そう考えると、ある程度、眼鏡のフロント部分の重さは推定できるだろう。という予感がありました。
2に関しても同様でテンプル部の長さに対し、3のテンプルの材質のデータがあります。テンプルに関しては、曲がっていたり、デザインも変わりますが、そこまで大きなブレがないだろう。という予測がありました。そう考えると、長さや比重のデータさえ分かれば、おおむね重さが予測できることに不思議はないと思っていました。
これは処理途中のデータの一部ですが、一般的な線形回帰でもR^2=0.756のデータが出ていました。
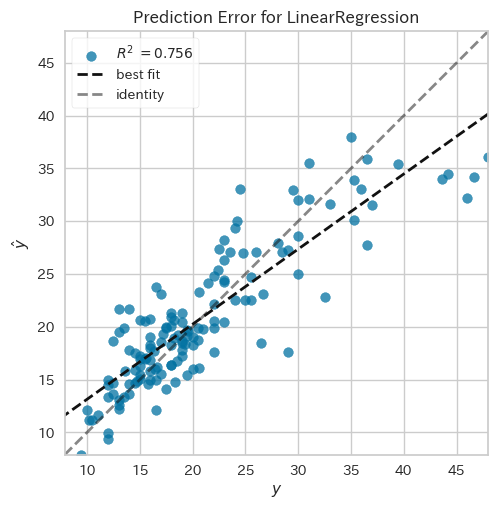
しかし、先ほど書いた話で、レンズの縦横のサイズが分かっている。厚さも3~5mm程度だろう。というようなことを書きました。そのため、重さ=レンズの縦 * レンズの横 * レンズの厚さ * 比重といった式になります。しかし、これは非線形です。これがどこまで影響があるのか。というところでした。最初は、線形回帰やるより、RidgeやLassoで回帰するのがいいのかな。とほんのり思っていました。これには理由はないです。ただの妄想です。しかし、少しやってみると、それほどいい精度が出ないな。という感触がありました。そうして、だんだん面倒だなぁ。と思い始めたので、pycaretに手を出して、やってもらった結果、Gradient Boosting Regressorで、そこそこ精度のよい内容になりました。先ほども書いた通り、ある程度、非線形効果が記述できるモデルが必要なのだな。と思いました。
感想
私は、雑にデータ解析をするときにはOrangeというツールを使っています。それを利用した記事も書いていました。
今回も、荒いデータ解析はOrangeで可視化して、そのデータの性質を見ていたりしました。しかし、
- 複数のモデルの比較が面倒
- 特定の値に対する予測値が出せない
といった部分があり、だんだん使いにくくなっていました。私は、データの分布をみることが多いので、その意味ではOrangeは手軽にできて便利だったりします。しかし、今回はOrangeでは手に余る内容でした。
どうしたもんかなぁ。と思った矢先、「確率分布のグラフはAIに書かせちゃえ」と思って、確率密度分布のグラフなどを書いてもらっていました。自分の中でなぜOrangeがいいか。というと、覚えることが少なくてグラフが描けたからでした。一方で、Pythonでmatplotlibやseabornを使ってグラフを書くのは、いちいちタイトルの構文や文字サイズの変更のやり方を1つ1つググりながら変更する必要があり、これが非常に面倒でした。でも、ある時から、「あぁ別にAIに指示して、タイトルの文字列大きくしてって言えば大体大きくしてくれるな」と成功体験が積みあがり始めると、こっちのほうが実は楽だったりします。今回も、いちいちスクショを取っていたのですが、本を書く際に文字が小さすぎて、一度大きくし直した後、再度スクショを取り直す。といっためんどくさい作業が発生しました。そう考えると、可視化作業もPythonで書いておく方が、あとで文字列のサイズを大きくするような一括変更をしても、執筆の都合上も良かったです。
ただ今回の件で思ったことは、さてAutoMLとの付き合い方とはどうすべきかな。と思ったことです。今回、書籍の都合上、モデルの内部に立ち入らなくても良い内容でした。なぜこのようなモデルだとよく予測できるのか。どうしてこういったことを説明する必要のない内容でした。したがって、AutoML一発出し。のようなものでも、まぁいいか。と思う面がありました。最近は、好きでいろんな数理モデルのモデル式を見ていたりします。そういうのってどこまで意味あるんだろうかなぁ。みたいなことは改めて思うことがありました。その1つには解釈性と制御性があると思っていて、例えば、広告を1000円分打つと1人の購買が発生する。といったことです。今回、書籍ではFeature Importanceにも議論しており、眼鏡の重量において何が重要なパラメーターか。ということは分かりました。これは解釈がある程度できる。ということです(何の変数を触れば重さが変わるか)。しかし、それがどれくらい出力に影響するのか。ということまでは分かりません(制御性)。実際、書籍でもそれに近いことはやっているのですが、なかなか難しいな。という気持ちでした。そもそもモデルが非線形であるため、所望の値に制御するための方法がなかなか人間の認知を超えている感触があります。
最近は、自分の中ではロジスティック関数やBassモデルなど飽和するモデルがマイブームなのですが、こういうのってAutoML系でかけないよなぁ。と思いつつ、さて、この辺をどのように混ぜると面白いのかな。みたいなことを思いました。