オープンアドレス法
前回は、チェイン法について学びましたが、
ハッシュ値が同一の値で衝突してしまった場合の回避方法として、もう一つオープンアドレス法というものが存在するようです。
衝突が発生した際に再度同じハッシュ関数を行うことによって、
空いているバケットを探し出すという、割とシンプルな方法らしいですね。。
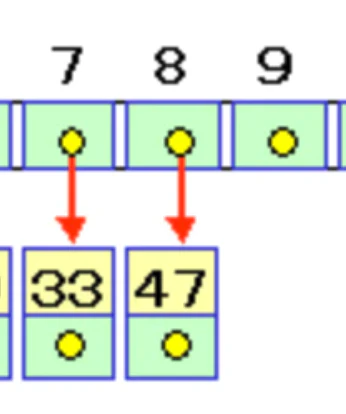
例えば下記のようなハッシュ表で、20というキー値を挿入したいとします。(ハッシュ値は13の剰余とします)

まずは20 ÷ 13 で 7がハッシュ値となりますが、[7]は既に33で埋まっています。
そこで、20に +1を行い、 21 ÷ 13 で8がハッシュ値となりますがこちらも既に47で埋まってしまっていますね、、
さらに 21 + 1と再ハッシュを行い、ようやく[9]に値を格納することができました。
このように、衝突が発生した場合、その1つ後ろのバケットを新たな格納位置として試し、
そこも使われていたら、さらに1つ後ろのバケットを試す。。というのを繰り返すのがオープンアドレス法の特徴です。
このように空きバケットに出会うまで再ハッシュを何度も繰り返すことから、線形探査法とも呼ばれます。
要素削除後の探索から考える注意点
空きがあるまでハッシュ関数を繰り返すシンプルな方法なので、そこまで難しくないのではと思いがちですが、
次にハッシュ表から要素が削除された後に探索する際の流れを追ってみましょう。
シンプルに削除するなら、33のハッシュ値である[7]の要素を空にすればそれで良さそう。。
と感じるかもしれませんが、
この削除後に20という値を探索したいときはどうすれば良いでしょうか??
20を追加したときは、33と同じハッシュ値を持っていたため、
衝突回避のために2度再ハッシュを行い、[9]に格納にしていました。
しかし、20のハッシュ値が7であることに代わりはないので、[7]の要素が空となってしまった今、
このままだと、「ハッシュ値[7]のデータは存在しない = 20は存在しない」と勘違いされて探索に失敗してしまいます。
もし、探索対象と同じバケット値を持っていて、自分より前に格納されていた値が既に削除されていることが分かっていれば、
再ハッシュを行い探索を続けられていたかもしれません。。
そこで、各バケットに次のいずれかの属性を与えてみましょう。
- データが格納されている
- 空
- 削除済
削除済みであることが分かれば、その先に値があるかもしれないということで再ハッシュを行って探索を続けることができます。
値が空であっても、削除済みなのか、何の値も格納されていないのかを判別できればこの問題は回避できそうですね。。!
オープンアドレス法の流れがイメージできたところで、今度は実際にコードに落とし込んで考えてみましょう。
コードで表現してみる
まずは大元となるハッシュ表を表すクラスを作ります。
public class OpenHash<K,V> {
private int size; // ハッシュ表の大きさ
private Bucket<K,V>[] table; // ハッシュ表
//--- コンストラクタ ---//
public OpenHash(int size) {
try {
table = new Bucket[size];
for (int i = 0; i < size; i++)
table[i] = new Bucket<K,V>();
this.size = size;
} catch (OutOfMemoryError e) { // 表を生成できなかった
this.size = 0;
}
}
//--- ハッシュ値を求める ---//
public int hashValue(Object key) {
return key.hashCode() % size;
}
//--- 再ハッシュ値を求める ---//
public int rehashValue(int hash) {
return (hash + 1) % size;
}
ハッシュ表の要素数であるsizeと、ハッシュ表を表すBucket型の配列をフィールドに持っています。
コンストラクタでは、引数に与えられた数分だけBucketオブジェクトをを生成していますが、
このBucketの中身に先ほど言及した削除済みが、空かの属性を与えることで、衝突後の混乱を避けることができそうです。
(チェーン法では、ここの要素は線形リストのためNodeとして表現されていましたが、ここではBucketクラスとしています)
rehashValue関数が、衝突時に行う再ハッシュ用の関数となります。
次にバケットのオブジェクトを作ってみましょう。
//--- バケット ---//
static class Bucket<K,V> {
private K key; // キー値
private V data; // データ
private Status status; // 状態
//--- コンストラクタ ---//
Bucket() {
status = Status.EMPTY; // バケットは空
}
//--- 全フィールドに値を設定 ---//
void set(K key, V data, Status status) {
this.key = key; // キー値
this.data = data; // データ
this.status = status; // 状態
}
//--- 状態を設定 ---//
void setStatus(Status status) {
this.status = status;
}
//--- キー値を返す ---//
K getKey() {
return key;
}
//--- データを返す ---//
V getValue() {
return data;
}
//--- キーのハッシュ値を返す ---//
public int hashCode() {
return key.hashCode();
}
}
enum Status {OCCUPIED, EMPTY, DELETED}; // {データ格納, 空, 削除ずみ}
扱うデータは、チェーン法と同様に会員番号と氏名がセットとなったdataと氏名をkeyとして構成していきます。
バケットが持つフィールドには、key(氏名)と、data(会員番号 + 氏名)と、
空か、削除済みか、データが格納されているかの3つの状態を表すstatusを持たせておきます。
※Dataの詳細は前記事のチェーン法を参考のこと
statusの値は、enumのStatusに持たせておき、コンストラクタで初期値はEMPTY(空)として、
具体的な要素の追加、削除、探索を行ってみましょう。
要素の探索、追加、削除
まずは要素の探索です!
private Bucket<K,V> searchBucket(K key) {
int hash = hashValue(key); // 探索するデータのハッシュ値
Bucket<K,V> p = table[hash]; // 着目バケット
for (int i = 0; p.status != Status.EMPTY && i < size; i++) {
if (p.status == Status.OCCUPIED && p.getKey().equals(key)) {
return p;
}
hash = rehashValue(hash); // 再ハッシュ
p = table[hash];
}
return null;
}
//--- キー値がkeyの要素の探索(データを返却)---//
public V search(K key) {
Bucket<K,V> p = searchBucket(key);
if (p != null) {
return p.getValue();
} else {
return null;
}
}
実際に探索を行っているのは searchBucketメソッドですが、
探索したいキー値(氏名)を引数に持ってきて、ハッシュ関数を通してバケット値を求めて、対象バケットを絞っています。
ハッシュ表の最後の要素がEMPTY(空)であるところまで探索を続けます。
もし、探索対象のバケットのステータスがOCCUPIED(データ格納済)で、キー値(氏名)も一緒であればその要素を返しています。
そうでなければ、そのままrehashValueメソッドを使って再ハッシュをおこない、次のハッシュ値を持つバケットに
探索対象を移し、最後まで見つからなければ nullを返すようにしています。
searchメソッドでは、入力されたキー値をそのままsearchBucketメソッドに渡して、返り値を返すようにしています。
次に要素を追加してみましょう。
public int add(K key, V data) {
if (search(key) != null) {
return 1; // このキー値は登録ずみ
}
int hash = hashValue(key); // 追加するデータのハッシュ値
Bucket<K,V> p = table[hash]; // 着目バケット
for (int i = 0; i < size; i++) {
if (p.status == Status.EMPTY || p.status == Status.DELETED) {
p.set(key, data, Status.OCCUPIED);
return 0;
}
hash = rehashValue(hash); // 再ハッシュ
p = table[hash];
}
return 2; // ハッシュ表が満杯
}
searchメソッドにて、nullが返されなければ、既に同じkeyを持つバケットがあるので、returnしています。
もしなければ、そのままハッシュ値を求めていますが、
if(p.status == Status.EMPTY || p.status == Status.DELETED)にて、バケットのステータスを確認しています。
もしEMPTY(空)か、DELETED(削除済)だった場合は、値を格納できるということなので、
そのままkeyとdata,とOCCUPIED(データ格納済)のstatusをセットして終了します。
もし、データが格納済みだった際は、rehashValueにて再ハッシュを行い、次のバケットに着目するという流れになります。
最後に削除を行いましょう!
public int remove(K key) {
Bucket<K,V> p = searchNode(key); // 着目バケット
if (p == null)
return 1; // このキー値は登録されていない
p.setStatus(Status.DELETED);
return 0;
}
searchNodeメソッドにて、削除対象であるバケットを持ってきて、もしnullであればそもそも存在しないので、returnし、
存在すれば、指定のバケットインスタンスのstatusをDELETED(削除済)にすることで、
keyとdataを更新せずとも、削除という扱いにすることができます。
このような形で、各バケットに状態を持たせることによって、衝突時の再ハッシュを行っても正確にデータを管理することができました!
空きバケットが見付かるまで再ハッシュを行うだけといえばだけなので、チェーン法よりも単純ですが、
この方法では、いずれはハッシュ表が一杯になって、格納できる場所が無くなるという事態が起こり得ます。。
そのため、ハッシュ表に登録する要素の最大数を正確に把握できないのであれば使えないというのも
覚えておきたいところです。。!
学んだこと
- 空き要素は再ハッシュを繰り返し探して、各バケットに状態を表す属性を持たせることで、同じハッシュ値を持つ値も管理することができる
- 要素数の最大数が把握できていなければ使わない方がいい
- ハッシュ値で格納する値を決める点はチェーン法と一緒だが、データの持ち方は全く違う!
ハッシュという管理方法のうち、衝突を回避するためのチェーン法とオープンアドレス法と学んでみましたが
似て非なるどころか、データの扱い方は線形リストと、状態を持ったバケットなどなどかなり異なるようです。。
線形探索よりも、探索速度は上がりますが、それぞれのメリット、デメリットも把握しながら
こんなデータの扱い方があったな。。と思い出せるようにはしておきたいので、引き続き頑張っていきます!