ハッシュとは?
これまではデータの集合から特定の値を見つける探索を主に扱ってきましたが
データというのは探索だけでなく、追加や削除という操作を行うことも多く
そんな追加と削除を効率的に行う方法がハッシュ法と呼ばれる考え方だそうです。
データが格納されている位置は配列のインデックスを前から順番に指定するのがベーシックでしたが
このインデックスを指定するための演算を各値で行い、格納する場所を管理するという方法です。
例えば、配列の要素が13個数ある下記配列を考えてみましょう。
(実際には8要素しかありませんが、余分に空要素が5個あると考えます)
このとき、それぞれの値を要素数13で割り、剰余をインデックスとして指定してみます。
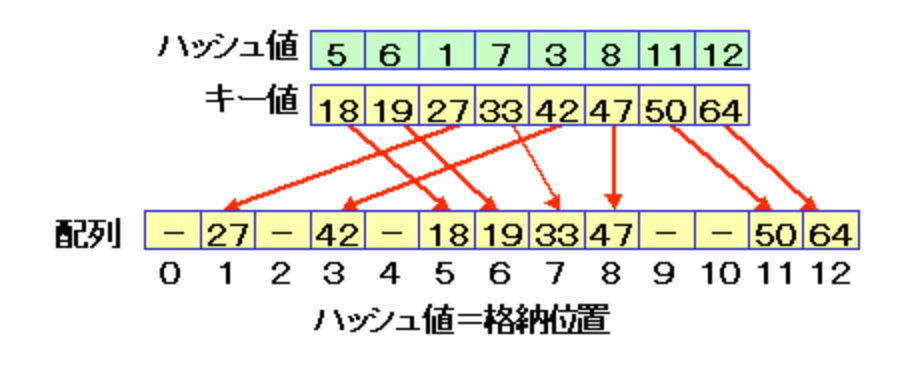
18であれば 18÷13 の剰余が 5、42であれば 42 ÷ 13の剰余が 3 といった感じに
求められた剰余をそのまま配列のインデックスとして格納していきます。
こうすることによって、例えば33という値を見つけたければ、ハッシュ関数を通じてインデックスは7となるので
そのまま[7]の要素を引っ張ってくれば良く、線形探索よりも効率的に探索を行うことができるということです。
格納位置を決定するハッシュ関数があれば、取り出す時も同じハッシュ関数を使って位置を割り出すことができるので、処理速度も上がるよねというお話ですね。。!
ハッシュ法における独特の言い回しにおいてもまとめておきます。
- ハッシュ値:要素を格納する配列の位置、インデックスのこと
- ハッシュ関数:ハッシュ値を求める関数のこと
- バケット:配列の各要素のこと
衝突という危険性
と、ここだけみると万能ハッシュ君と思いがちですが、ある危険性も存在します。。
仮に先の配列に14という値を加えたい! となったとき、14 ÷ 13 なので [1]に追加すればいいか
となりますが、[1]は既に27で埋まっており、こういったバケットの重複が衝突と呼ばれたりします。
と、そんな衝突が発生した場合の対処方法 は既に決められており、下記2つが挙げられます。
- チェイン法:同一のハッシュ値を持つ要素を線形リストで管理する
- オープンアドレス法:空きバケットを見つけるまで、ハッシュを繰り返す
今回はその内のチェイン法について理解も兼ねて、書いてみたいと思います!
チェイン法
チェイン法と呼ばれるくらいなので、その名の通り、同じハッシュ値で衝突したときに
同一のハッシュ値を持つデータを線形リストによって鎖状につないでいく方法です。
※線形リスト
リストというと、データが順序づけられて並んだデータ構造ですが
線形リストはその中でも単純なリスト構造の一種です。
線形リストは連結リストとも呼ばれ、A,B,Cという要素があれば、A→B→C という順にアクセスしていくので、
構造上どこかの要素を飛ばしてアクセスしたりすることはできません。
リストの個々の要素はノードと呼ばれ、各ノードは、データと後続ノードを指すポインタで構成されています
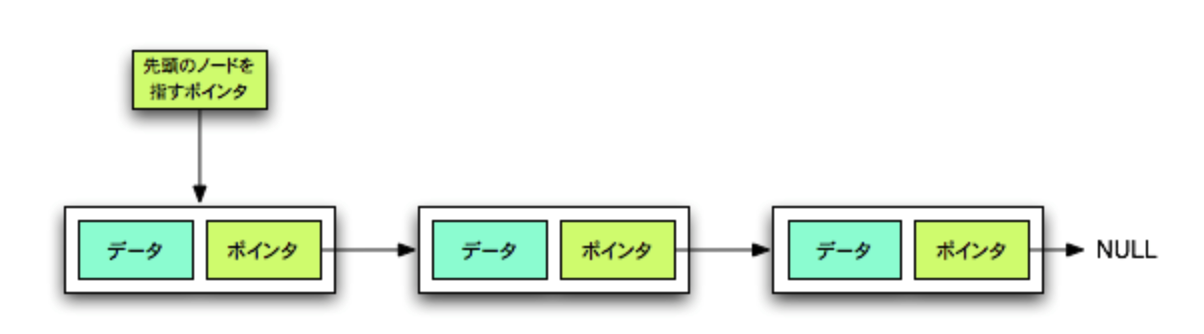
このノードという部分には、それよりも前にいた要素の参照を格納することによって、
左から読み込んだときに「自身の後ろに繋がれている要素の参照」を各ノードが持っているということになります。
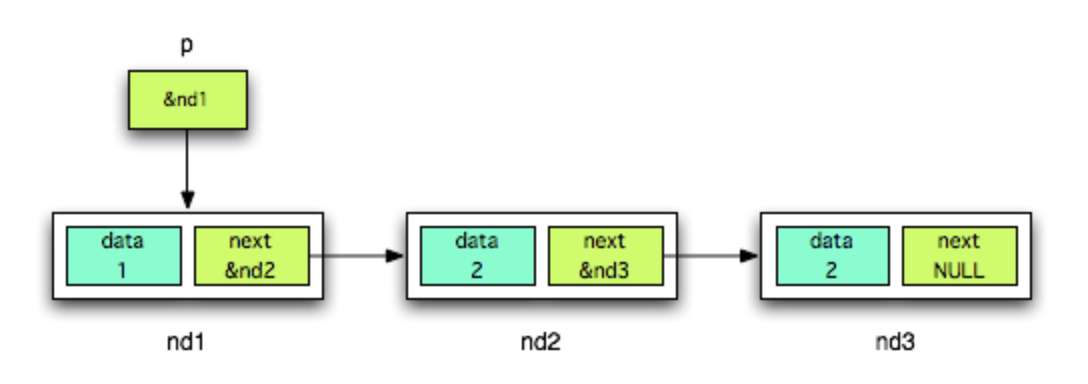
nd3は要素が何もないnullの次に格納されたので、nullという参照を
nd2はnd3の後に格納されたので、nd3の参照を。。という感じで、格納された順番的には右から左に繋がれていますが
矢印のように左から読み込んだ時は、自分の後続ノードの参照を持っているという言い方もできます
(考え方としては分かりにくいですが、どんどん値を押し出して右に繋げていくみたいな感覚だと思います。)
チェイン法ではこの線形リストというデータ型を使って衝突する値をうまく管理していきます。
例えば、以下のようなハッシュ表があったして、各要素には後続ノードの参照も含まれているとします。
(ハッシュ値が1の要素はnullが入っていましたが、その後に格納された27には nullという後続ノードが格納されているという構造です)
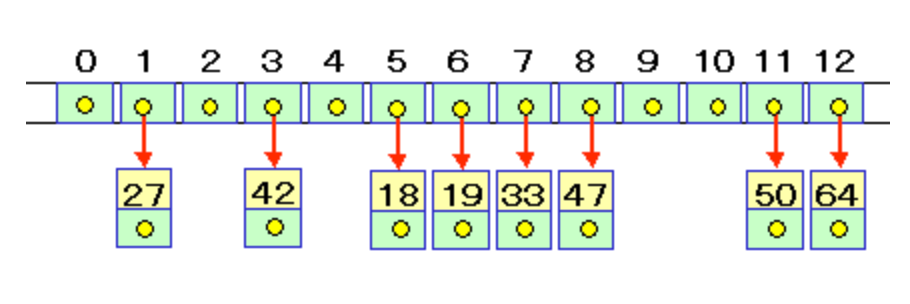
ここに、32を追加したい!としたとき、ハッシュ値は 32%13 6なので 19と衝突してしまいます。
そこで。互いのハッシュ値は6なので、それらを連結した線形リストへの先頭ノードへの参照を[6]に格納することによって
同じ位置に別々の値を格納することができます。
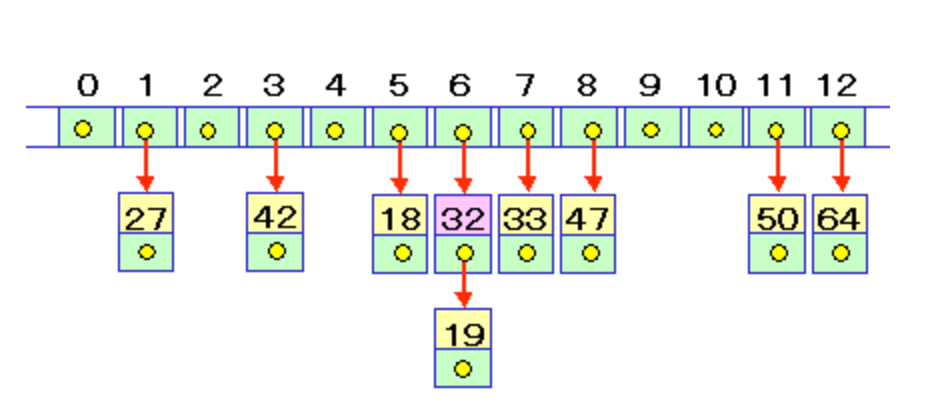
[6]には 32という要素があり、ポインタには19という値が入っていて、
19という値にはポインタである nullが入っている。。という構造になります。
このように、各要素に線形リストの鎖がぶら下がっているような構造になってくのが特徴といえます。
コードで表現してみる
まずは大元となるハッシュ表を一つのクラスで表現してみます。
public class ChainHash<K,V> {
private int size; // ハッシュ表の大きさ
private Node<K,V>[] table; // ハッシュ表
//--- コンストラクタ ---//
public ChainHash(int capacity) {
table = new Node[capacity];
this.size = capacity;
}
//--- ハッシュ値を求める ---//
public int hashValue(Object key) {
return key.hashCode() % size;
}
ハッシュ表の大きさを表すsizeと、線形リスト(ノードで構成された配列)のtableをフィールドとして持っています。
コンストラクタでは、引数で持ってきたハッシュ表のサイズ数の要素数を持つNode型の配列を生成しており、
Nodeオブジェクトの具体的な中身は下記のような感じになります。
hashValue関数は実際にハッシュ値を求める関数で、指定の要素をハッシュ表の要素数で割ったときの剰余を返すようにしています。
class Node<K,V> {
private K key; // キー値
private V data; // データ
private Node<K,V> next; // 後続ポインタ(後続ノードにとっての先行ノードに自身を参照させる)
//--- コンストラクタ ---//
Node(K key, V data, Node<K,V> next) {
this.key = key;
this.data = data;
this.next = next;
}
}
Nodeクラスというオブジェクトですが、(実際はChainHashクラスの内部クラスとして定義しています)keyとdataと、後続の参照を持つnextというフィールドを持たせています。
実際に持てるキーとデータは、ジェネリクスにしてますが、
今回はint型の会員番号とString型の氏名をdataとして持ち、keyは氏名を設定しているというシンプルなオブジェクトで表現してみましょう。
//--- データ(会員番号+氏名) ---//
static class Data {
private Integer no; // 会員番号
private String name; // 氏名(キー値)
//--- キー値として氏名を返す ---//
String keyCode() {
return name;
}
//--- 文字列表現を返す ---//
public String toString() {
return Integer.toString(no);
}
大元のハッシュ表、ノードオブジェクト、扱うデータ、が準備できたので、具体的な要素の探索、追加、削除などをメソッドで表現していきます。
探索・追加・削除
public V search(K key) {
int hash = hashValue(key); // 探索するデータのハッシュ値(探索対象の値が格納されたインデックス)
Node<K,V> p = table[hash]; // 着目ノード
while (p != null) {
if (p.getKey().equals(key)) {
return p.getValue(); // 探索成功
}
p = p.next; // 一致しなければ後続ノードの参照を探索対象にする
}
return null; // 探索失敗
}
引数のkeyという値を探索したい!というときのメソッドです。
今回扱うデータのkeyは氏名になるので、ここではString型の氏名が入ってきますが、
まずやるべきはhashValue関数でハッシュ値(インデックス)を求めることです。
ハッシュ値がでたら、今度は探索対象である値が入っているであろうノードに注目して、あとはそのノードに格納されている
keyが一致するまで無限ループで線形探索を実施する。。という流れになります。
もしノードがnullであれば、指定のノードにはどの値も格納されていないか、値が見つからないまま、最後の要素まで探索してしまったということで、そのままnullを返し探索失敗としています。(while(p != null)という条件式が判定部分です。)
もしnullでなければkeyが一致するか、nullになるまで繰り返し、一致しない場合は p = p.nextで後続ノードの参照を次の探索対象としています。(ここがnullだと最後まで探索したことになるということです。)
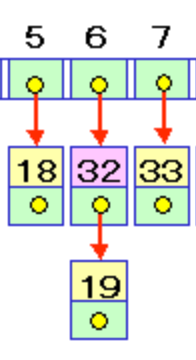
例えば、上記のハッシュ表似て、32 → 19 → null というノードが[6]という位置にあったとしたとき
19という値を探索する場合は、32という値とは一致しないので、後続の参照である19を返します。
すると次にくる19とは同値なので探索が完了するといった流れです。
次に値の追加を見てみましょう。
public int add(K key, V data) {
int hash = hashValue(key); // 追加するデータのハッシュ値
Node<K,V> p = table[hash]; // 着目ノード
while (p != null) {
if (p.getKey().equals(key)) { // このキー値は登録ずみ
System.out.println("この名前は登録済みです");
return 1;
}
p = p.next; // 後続ノードに着目
}
//table[hash]は自分の1個前のノードなのでポインタとしてその参照を入れておく
Node<K,V> temp = new Node<K,V>(key, data, table[hash]);
table[hash] = temp; // ノードを挿入
return 0;
}
まずは追加したいkey値のハッシュ値を求めて、格納先のノードを決めます。
格納先のノードが特定できれば、まずは探索と同様の方法で頭から同じ名前がないかを確認します。
もしなければ、現状のノードであるtable[hash]の参照を持った新しいノードを生成し、追加します。
同じNodeオブジェクトであるものの、中身は指定した要素の鎖が増えた線形リストであるということですね。。!
(オブジェクトの中に自分の前にあった参照があり、その参照にもその前の参照が。。という再帰的な構造をイメージすると分かりやすいかもしれません。)
全体のハッシュ表の値が変わっておらず、ハッシュ表の同じ位置に値を再代入しているだけなので
一見すると値を追加したとは思いにくいですが、衝突する可能性がある値を一括してノード内で管理しているというのを意識するのが大事かと思います。(自分はここのイメージができなく、理解に戸惑いました。。)
最後に要素の削除を書いてみたいと思います。
public int remove(K key) {
int hash = hashValue(key); // 削除するデータのハッシュ値
Node<K,V> p = table[hash]; // 着目ノード
Node<K,V> pp = null; // 前回の着目ノード
while (p != null) {
if (p.getKey().equals(key)) { // 同じkey値を見つけて
if (pp == null) { //先頭ノードであれば直後のノードをそのまま再代入する
table[hash] = p.next;
} else { // 先頭でなければ、1個前に探索したノードに自身の次の参照を代入し、自身の参照は無かったことにする
pp.next = p.next;
}
return 0;
}
//現在の探索対象を、前回の探索ノードとして代入する
pp = p;
//現在の探索対象のnextを探索対象に移す
p = p.next;
}
return 1; // そのキー値は存在しない
}
探索、追加と同じように削除したい値のハッシュ値を求めて、指定の値が含まれているであろうノードに着目します。
削除対象が先頭ノードではない可能性もあるので、指定の値の直前にあるノードを格納するためにppという変数も用意しています。
もしノードに何かしらの値が格納されていれば削除する値まで線形探索を行います。
if (p.getKey().equals(key))で、削除したい値が見つかったときの処理がありますが、
もし、先頭ノードであった場合、(pp == null)はtrueとなるので、そのまま後続ノード(next)を再代入します。
先頭ノードでない場合は、自身の一個前のノードに自身の次に来る参照を再代入することで自身の参照を削除しています。
例えば 14 → 27 → 40 → nullという順番で値が右から格納されていたとして、
探索は左から行いますが、27を削除したいというときに、 14のnextに40の参照を入れる必要があるので、
先頭ノードの14でif (p.getKey().equals(key))がfalseとなった後に、
14を pp に再代入し、 14の次の参照である27を次の探索対象として、p に再代入しています。
次のノードである27と一致した場合、ppは!nullとして、14のnextに、27のnext(40)を代入しているので、
14のnextが40となり 、 14 → 40 → nullとして27が削除されたことになるという流れです。
先頭ではないノードを削除するさいは若干ややこしくはなりますが、基本的には線形探索を行い、値が一致したものを無かったことにするという流れになりますね。
学んだこと
- ハッシュ法では値が衝突する可能性があり、回避方法の一つとしてチェイン法が存在する
- 線形リストという、自身の参照を繋げた鎖状のデータ構造が存在する
- 同じハッシュ関数を使用して格納位置を決めているので、探索効率は高く、追加や削除も行える
ハッシュ表と線形リストという配列の中に連続したオブジェクトが存在しているという
今までにないデータ構造と、その操作方法だったのでなかなか理解に苦しみましたが、
データを追加した順に鎖を繋げて、左から右に先頭~後続という流れでみると割とスッキリすることができました!
まぁこんなデータ構造もあるんだなという理解ができたのでよしとして、引き続き頑張っていきます!
※ 記事内の画像は下記2サイトから拝借致しました。ありがとうございます。
C#によるアルゴリズムとデータ構造
アドバンスプログラミング