はじめに
先日、リリースされた機械学習ライブラリーPyCaretを使ってみました。
データの特徴量分析や複数のモデルとの性能比較作業が自動化され、これまでのデータサイエンティストの作業時間がだいぶ減ると思います。
1. PyCaretのインストール
下記のコードを実行しインストールします。
Anacondaを使っていますが、PyCaret専用の仮想環境を立ち上げてインストールしました。
既存のCondaで管理されてる仮想環境では、エラーが発生する場合があります。(恐らくpipとcondaとの衝突が原因)
pip install pycaret
2.データの取得
今回はWine Qualityデータセットを使います。
データセットには、説明変数として11項目、ワインの品質を表す目的変数(Quality)1項目で整理されています。
説明変数
1 - fixed acidity (固定酸度)
2 - volatile acidity (揮発性酸性)
3 - citric acid (クエン酸)
4 - residual sugar (残糖)
5 - chlorides (塩化物)
6 - free sulfur dioxide (遊離二酸化硫黄)
7 - total sulfur dioxide (総二酸化硫黄)
8 - density (密度)
9 - pH
10 - sulphates (硫酸塩)
11 - alcohol (アルコール)
目的変数
12 - quality (品質)(score between 0 and 10)
データセットは、下記のサイトでダウンロード可能です。
http://archive.ics.uci.edu/ml/datasets/Wine+Quality
http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv
from pycaret.datasets
import pandas as pd
dataset = pd.read_csv('winequality-white.csv',sep=";",encoding="utf-8")
dataset.head()

そして、95%を訓練データ、5%をテストデータ(Unseen Dataと呼ぶ)に分けます。
data = dataset.sample(frac =0.95, random_state = 786).reset_index(drop=True)
data_unseen = dataset.drop(data.index).reset_index(drop=True)
print('Data for Modeling: ' + str(data.shape))
print('Unseen Data For Predictions: ' + str(data_unseen.shape))
結果
Data for Modeling: (4653, 12)
Unseen Data For Predictions: (245, 12)
3.データの前処理
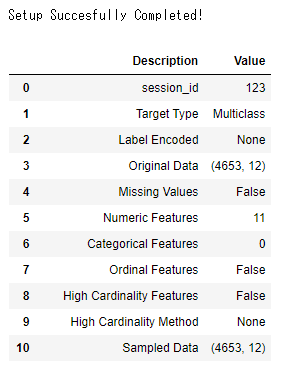
setup()を利用して、データの前処理を行います。その時、目的変数を引数でqualityと指定します。
from pycaret.classification import *
exp_clf101 = setup(data = data, target = 'quality', session_id=123)
結果 (10項目まで表記)
4.モデルの比較
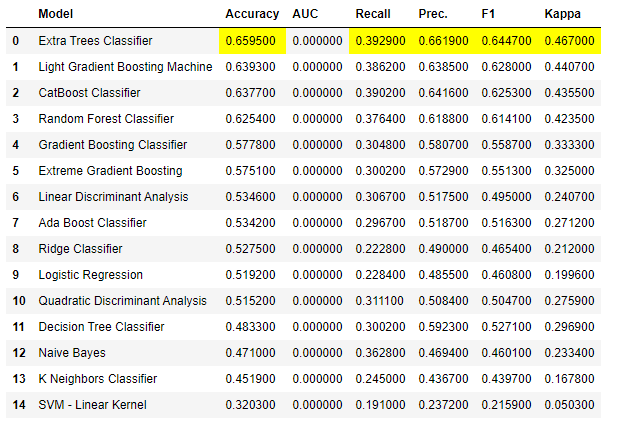
compare_models()で、データセットを複数の分類モデルを用いて分析を行い、その結果を表にまとめます。どの分類モデルを使うか検討の時、かなり役に立つ機能です。
Pycaretが提供する分類モデルは10種類以上で、下記のリンクで確認が可能です。
compare_models()
Extra Trees Classifierを使うと、Accuracy 65.95%でした。例えば、こういう機能を使わず、最初からSVMだけで分析をした場合、Accuracyは32.03%です。 ワインの品質データ、SVM分析事例
結果
5.分析モデルの生成
分類モデルを選択して、モデリングを行います。create_model()を使います。
今回は、Light Gradient Boosting Machineモデルを利用します。
lightgbm = create_model('lightgbm')
結果
6.分析モデルのチューニング
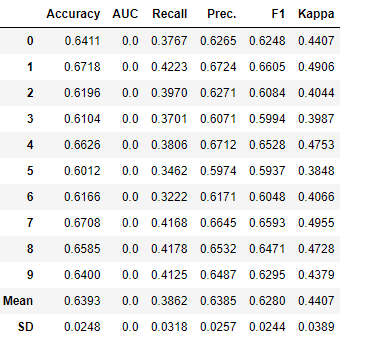
tune_modelを用いて、モデルのチューニングも行います。
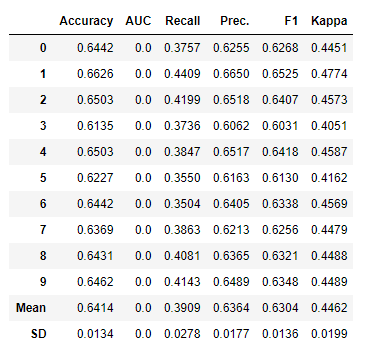
tuned_lightgbm = tune_model('lightgbm')
結果
チューニング前のAccuracyの平均が0.6393、チューニング後のAccuracyの平均が0.6414と改善されました。
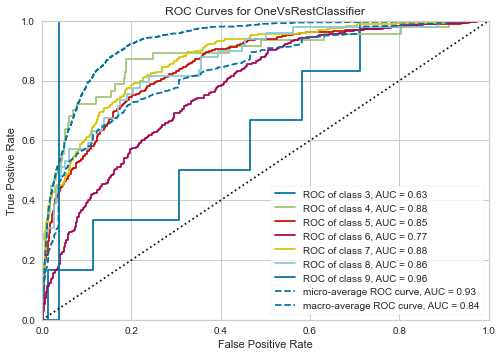
7.分析モデルの可視化
plot_modelを用いて、分析結果を可視化します。
まず、AUC曲線をプロットします。
plot_model(tuned_lightgbm, plot = 'auc')
結果
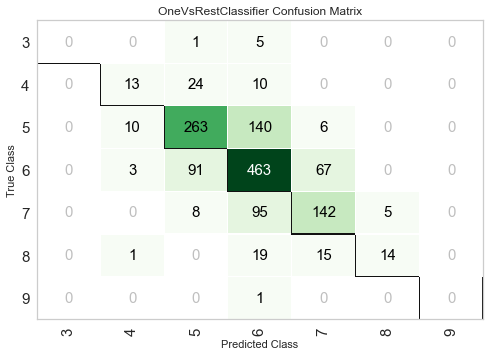
次に、混同行列をプロットします。
plot_model(tuned_lightgbm, plot = 'confusion_matrix')
結果
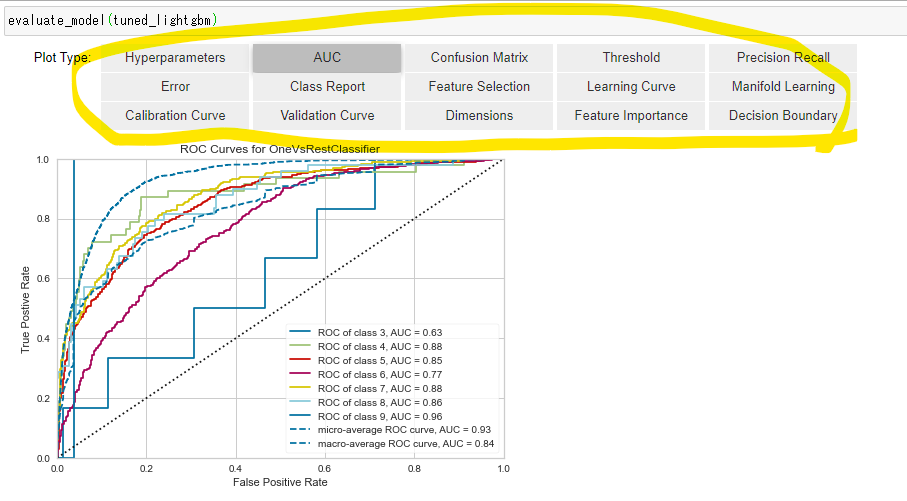
8.分析モデルの評価
evaluate_model()を使い、複数の評価を同時に行うことが可能です。
evaluate_model(tuned_lightgbm)
黄色い枠の中のボタンを押すと、各々の評価結果が表示されます。
結果
9.予測
finalize_model()でモデルをFinalizeした後、predict_model()で予測を行います。
予測の時には、テストデータ(ここでは、data_unseen)を使います。
final_lightgbm = finalize_model(tuned_lightgbm)
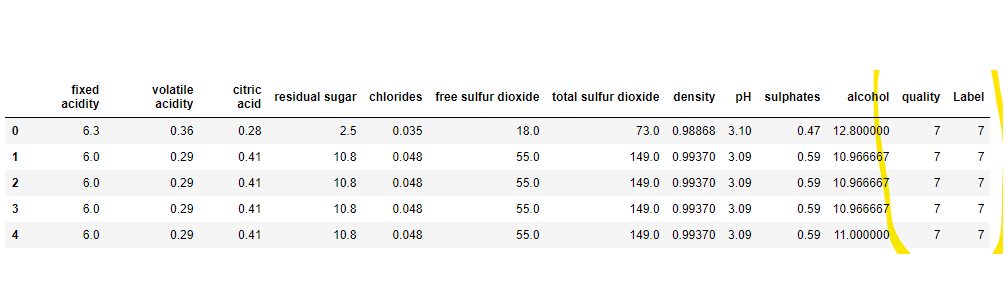
unseen_predictions = predict_model(final_lightgbm, data=data_unseen)
unseen_predictions.head()
最後のLabel列は、予測の結果を意味します。
結果
10.まとめ
- ワイン品質のデータセットを利用し、PyCaretで分析を行いました。
- 大変使いやすいです。商用分析ツールのAlteryx, DataRobotにも負けないほどの高い分析機能だと思います。
- 次回は、PyCaretの回帰問題に取り組んでみたいと思います。
後続記事を書きました。宜しければ、こちらの記事も読んで頂ければと思います。
PyCaretでタイタニック生存予想をしてみた
10.1 分析に使用したPycaret関数一覧
- データの前処理: setup()
- モデルの比較: compare_models()
- 分析モデルの生成: create_model()
- チューニング: tune_model()
- 可視化: plot_model()
- 評価: evaluate_model()
- 予測: finalize_model(), predict_model()
11.参考資料
1.PyCaret Home Page , http://www.pycaret.org/
2.Wine Quality Dataset, http://archive.ics.uci.edu/ml/datasets/Wine+Quality
3.PyCaret Classification, https://pycaret.org/classification/
4. 最速でPyCaretを使ってみた, https://qiita.com/s_fukuzawa/items/5dd40a008dac76595eea
5.【Python】機械学習でワインの品質を判定する, https://ymgsapo.com/2019/01/06/ai-wine-quality/