はじめに
早速ですが、先日リリースされた機械学習ライブラリーPyCaretを使用してみました。
誰でも簡単にモデリングができるなと実感しました。本当にめちゃくちゃ簡単でした!
10行もコードを書かずに前処理から、チューニング、予測ができます!
引数などまだ把握できていない部分が多くありますが、PyCaretの記事を1番に書こうと思い書きました。
気づいた点があればコメントお願いします。
0. 環境とversion
- PyCaret 1.0.0
- Google Colaboratory
1. まずはインストールから
下記のコードを実行しインストールします。
体感ですが、2,3分で終わりました。
ローカルでインストールしたらエラーが出てきたので、一旦断念しています。
! pip install pycaret
2. データの取得
今回はbostonのデータを使用していきます。以下のコードでデータを取得できます。
from pycaret.datasets import get_data
boston_data = get_data('boston')
3. 前処理
前処理を行います。
setup()にデータとターゲット変数を定義し、初期化しています。
今回は回帰問題を解くので、pycaret.regressionを指定しています。
分類問題の場合は、pycaret.classificationを指定してください。
自然言語処理、クラスタリングなどのタスクを行うこともできます。
setup()は欠損値処理や、カテゴリーデータのエンコーディング、train-test-splitなどを行なってくれます。
詳しくは、こちらを参照ください。
from pycaret.regression import *
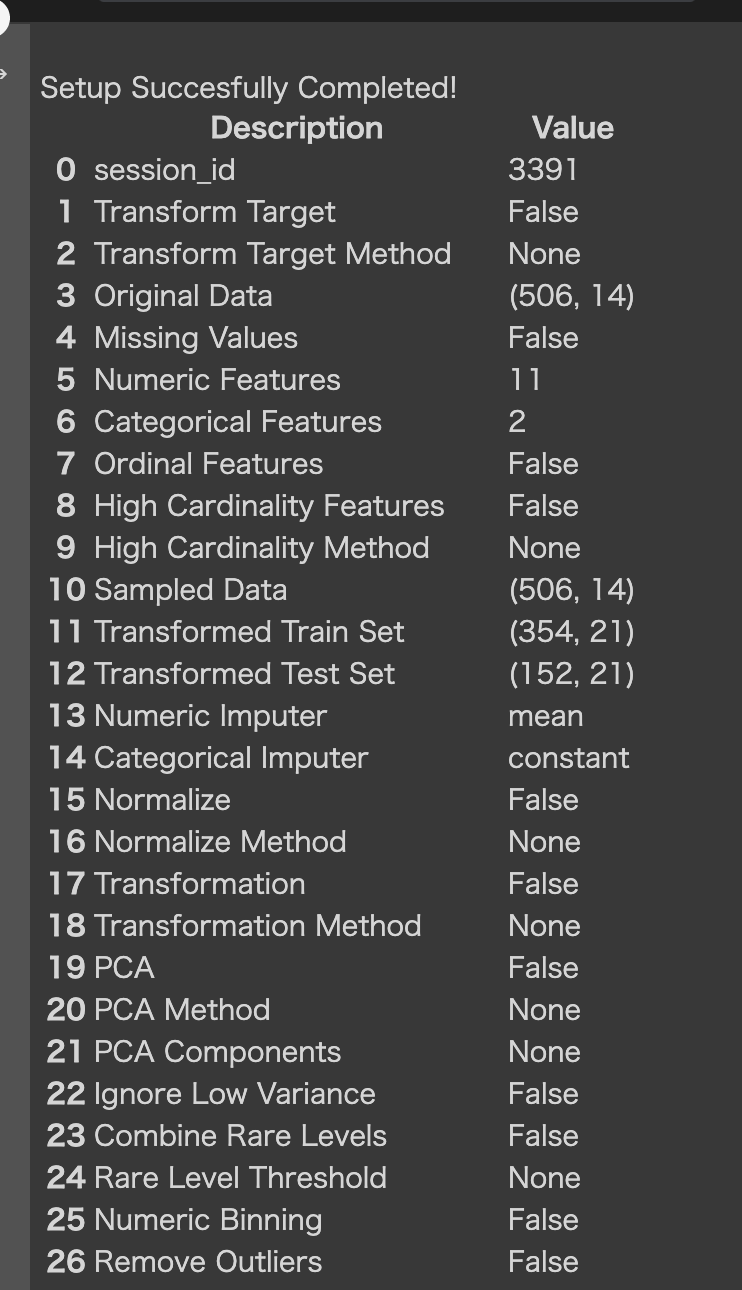
exp1 = setup(boston_data, target = 'medv')
実行するとセットアップが完了します。
4. モデルの比較
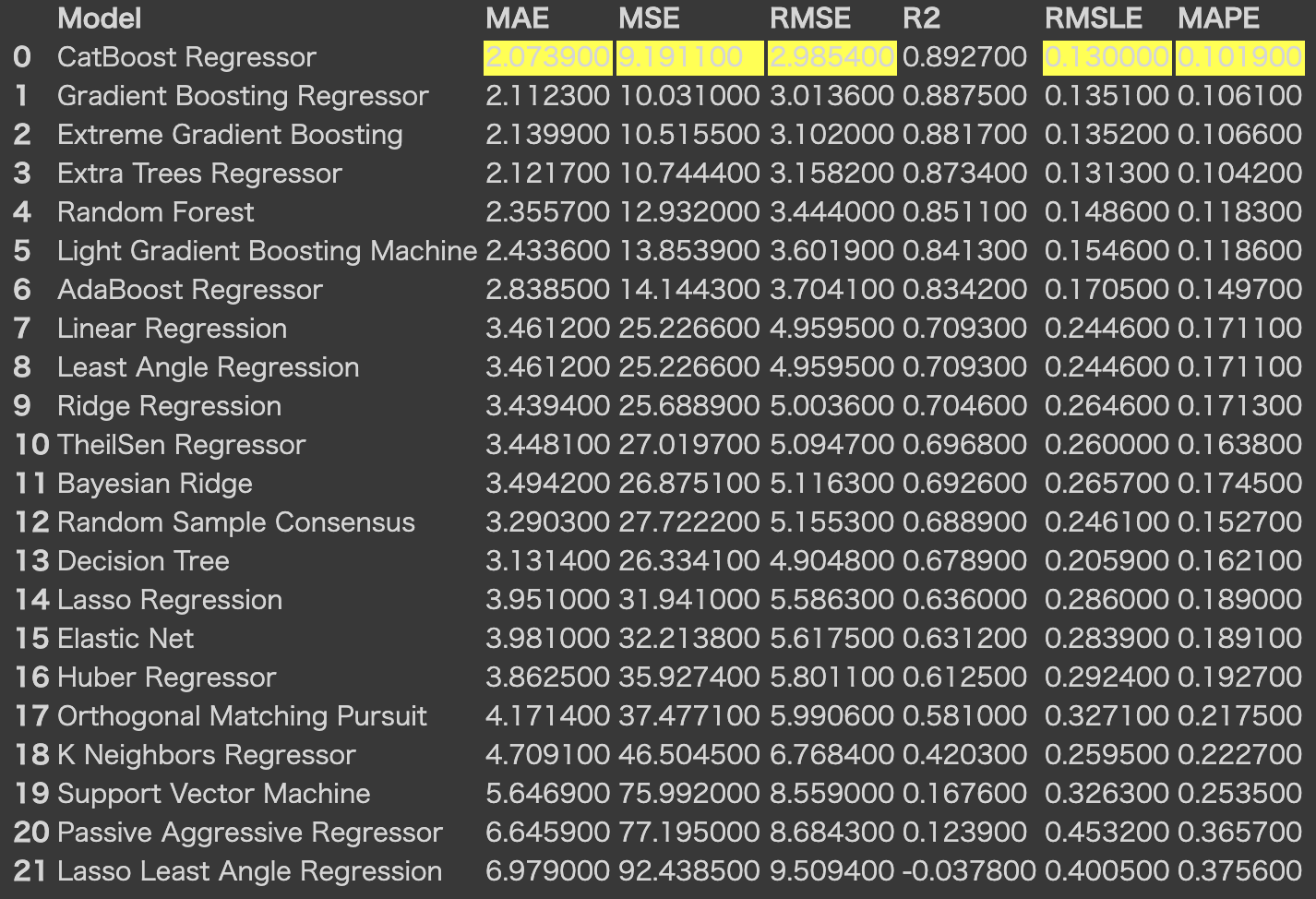
モデルの比較し選択していきましょう。
モデルの比較については、下記の1行で行えます。2、3分で終了しました。
評価指標も一覧で確認できて便利ですね!デフォルトで、k-foldを10分割で行なっています。
引数で、fold数や、ソートする指標を指定できます。(実行はデフォルトで行なっています。)
compare_models()
実行結果はこちら
5.モデリング
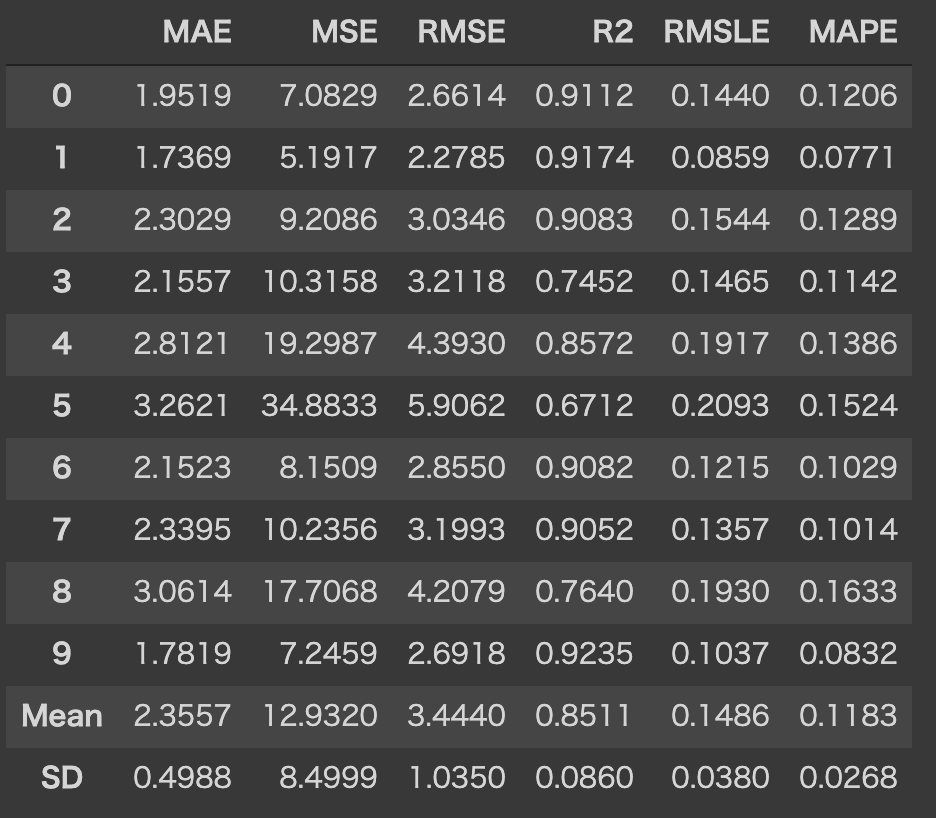
モデルを選択してモデリングを行います。今回はRandom Forestを使用しています。(完全に気分ですね。)
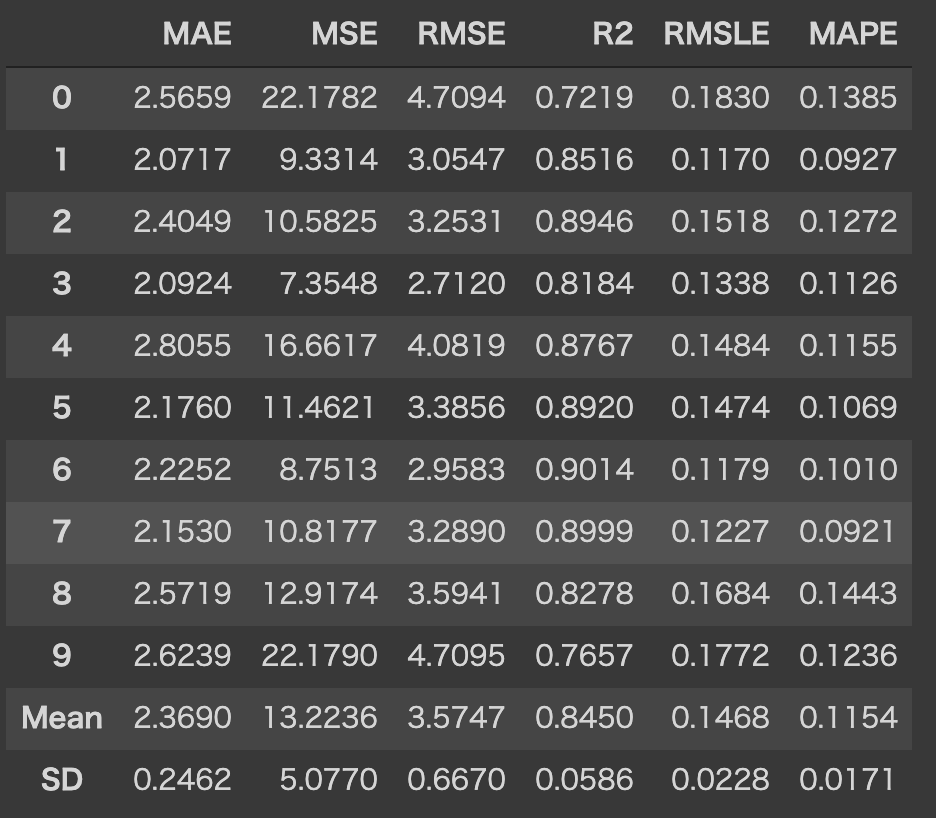
この関数は、k-foldしたスコアとトレーニング済みモデルオブジェクトを含むテーブルを返します。
SDも確認できてとても便利ですね!
rf = create_model('rf')
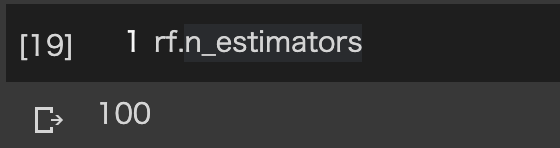
トレーニング済みオブジェクトの後ろにピリオドで指定することで、下記に様に確認できます。
6.チューニング
チューニングも1行で行えます。
tuned_rf = tune_model('rf')
パラメータの取得は下記でできます。
tuned_rf.get_params

7.モデルの可視化
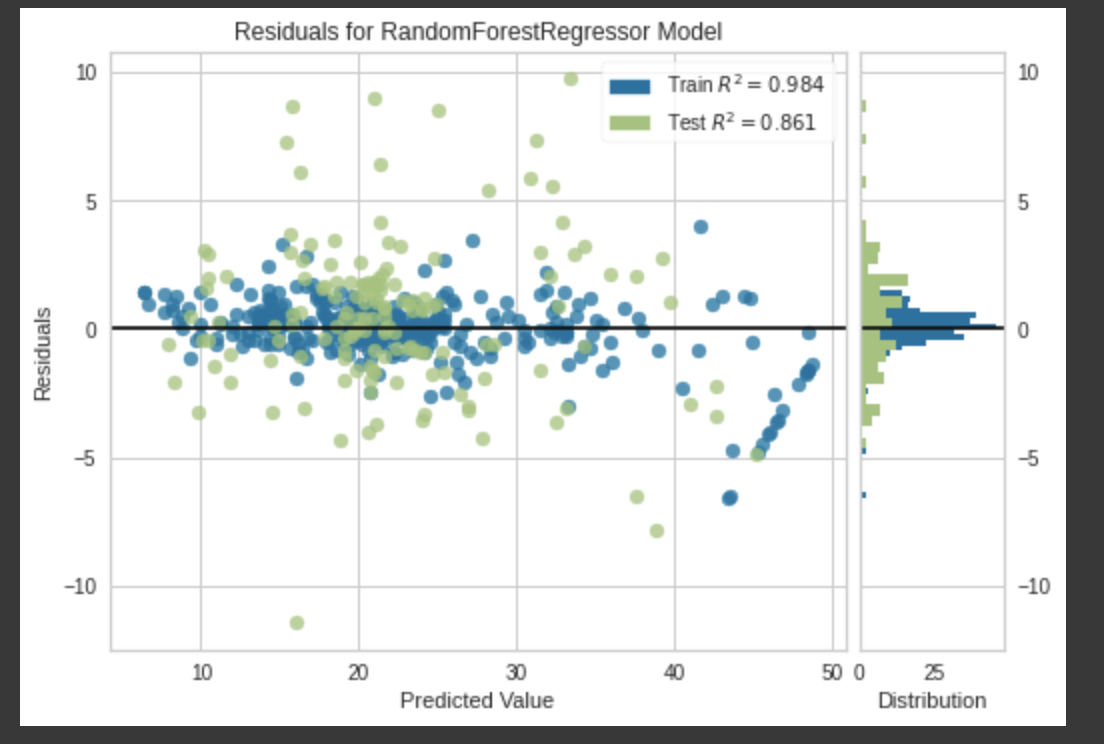
モデルの精度を可視化してみましょう。回帰のプロットは以下の図ですが、分類問題の場合は、指標に合わせてアウトプットを選択できます。
分類問題の可視化のバリエーションが豊富なので、ここにきて分類問題を選択しておけばよかったと少し後悔しました。。。
plot_model(tuned_rf)
8.モデルの解釈
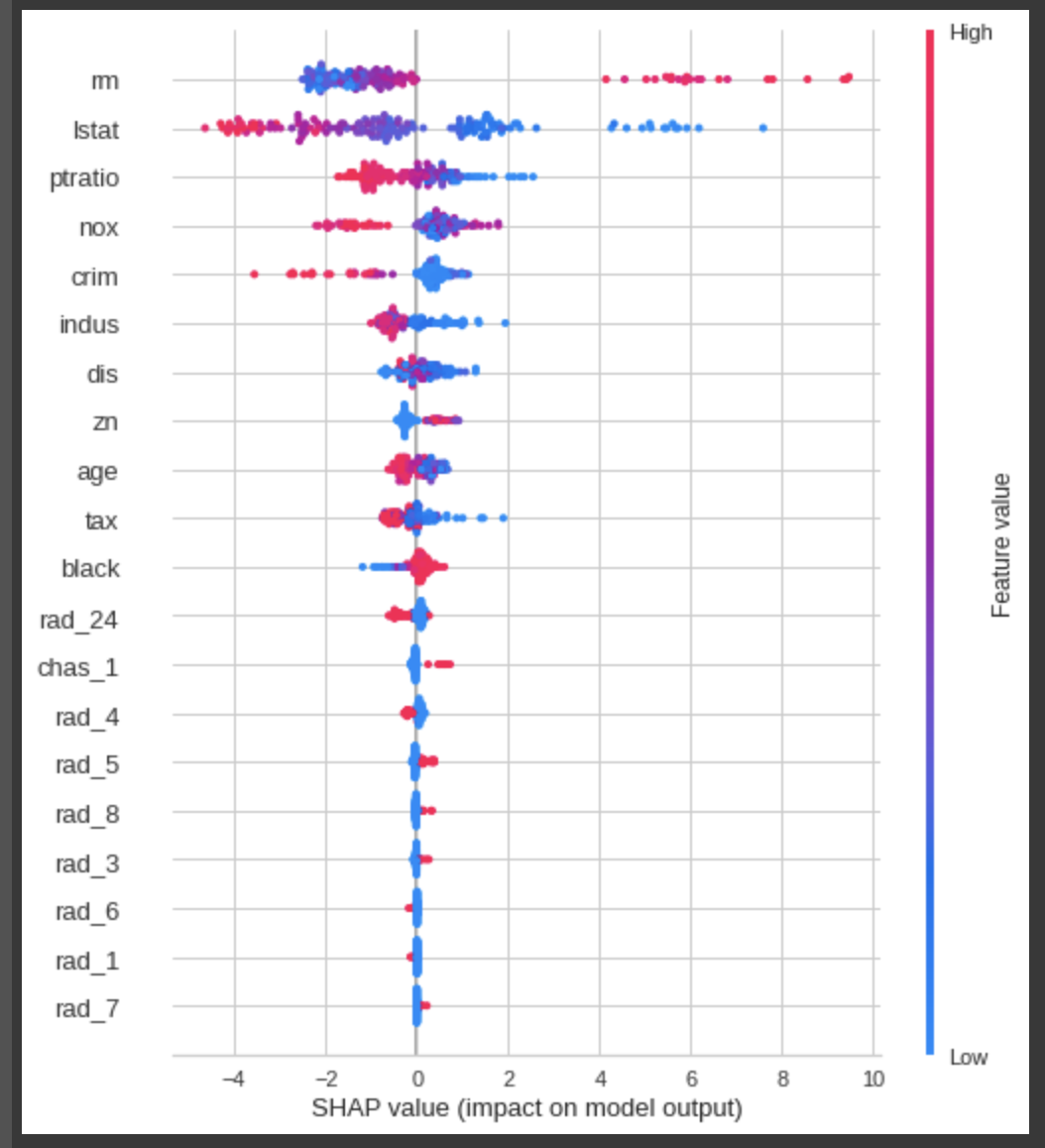
モデルの解釈はSHAPを用いて行なっております。
グラフの見方や、モデルの解釈方法については、SHAPのgitを確認ください。
interpret_model(tuned_rf)
9.予測
testデータに対しての予測は下記の様に書きます。
実行結果は、setup()でtrain-test-splitした30%のテストデータに対して予測した結果を返してくれます。
rf_holdout_pred = predict_model(rf)

新たなデータに対して予測を行う際には、dataの引数にデータセットを渡します。
※今回は元のデータを使い回しています。
predictions = predict_model(rf, data=boston_data)
一番右に予測結果が追加されます。
最後に
最後までお読みいただきありがとうございました。
何かありましたら、コメントよろしくお願いいたします。