はじめに
先日、リリースされた機械学習ライブラリーPyCaretを使ってみました。
データの特徴量分析や複数のモデルとの性能比較作業が自動化され、これまでのデータサイエンティストの作業時間がだいぶ減ると思います。
今回は、タイタニック生存予想問題を、PyCaretにかけて、予測結果をKaggleにSubmissionし、その結果を見てみます。
**前回に掲載した、PyCaretでワインの品質を分類してみた の後続記事です。 **
1. PyCaretのインストール
下記のコードを実行しインストールします。
Anacondaを使っていますが、PyCaret専用の仮想環境を立ち上げてインストールしました。
既存のCondaで管理されてる仮想環境では、エラーが発生する場合があります。(恐らくpipとcondaとの衝突が原因)
pip install pycaret
2.データの取得
KaggleのTitanicサイトで、train.csvとtest.csvがダウンロード可能です。
https://www.kaggle.com/c/titanic/data
import pandas as pd
train_data = pd.read_csv("train.csv")
train_data.head()
結果

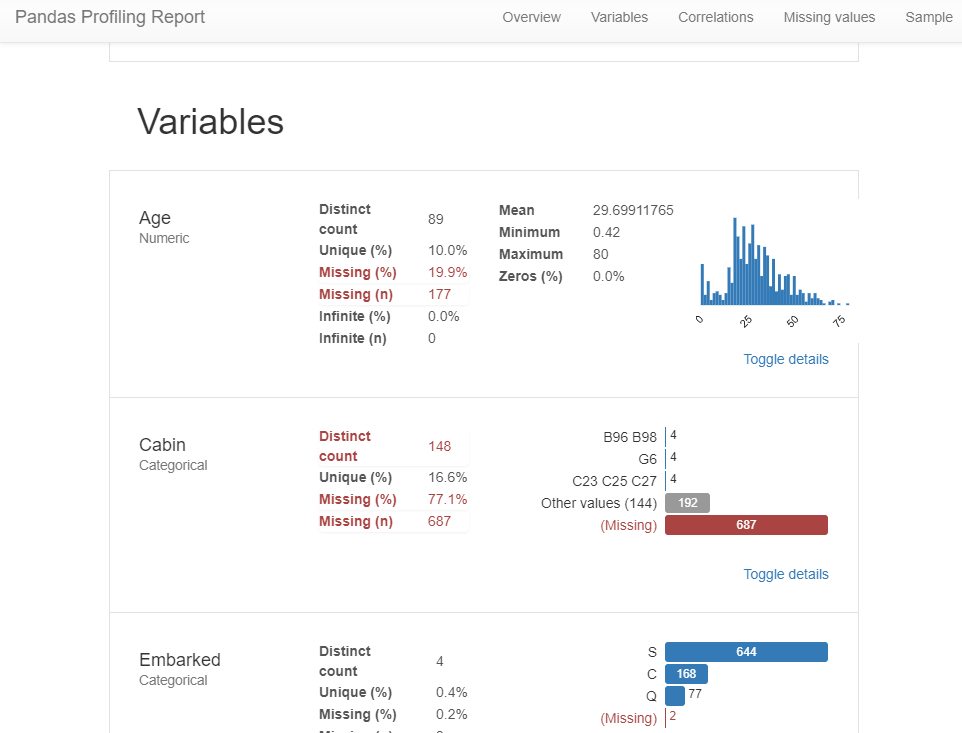
Pandasのprofile_report()を使い、データの中身を見てみます。
import pandas_profiling
train_data.profile_report()
結果
3.データの前処理
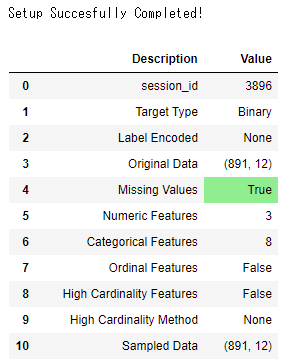
setup()を利用して、データの前処理を行います。その時、目的変数を引数でSurvivedと指定します。
from pycaret.classification import *
exp_titanic = setup(data = train_data, target = 'Survived')
結果 (10項目まで表記)
4.モデルの比較
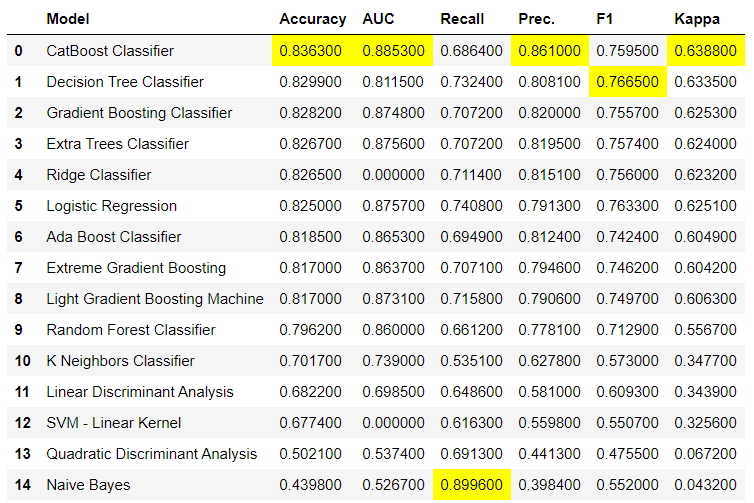
compare_models()で、データセットを複数の分類モデルを用いて分析を行い、その結果を表にまとめます。どの分類モデルを使うか検討の時、かなり役に立つ機能です。
Pycaretが提供する分類モデルは10種類以上で、下記のリンクで確認が可能です。
compare_models()
catBoost ClassifierのAccuracy 83.63%でした。今回は、PyCaretの性能評価ということで、9位のRandom Forest Classifierで話を進めます。
結果
5.分析モデルの生成
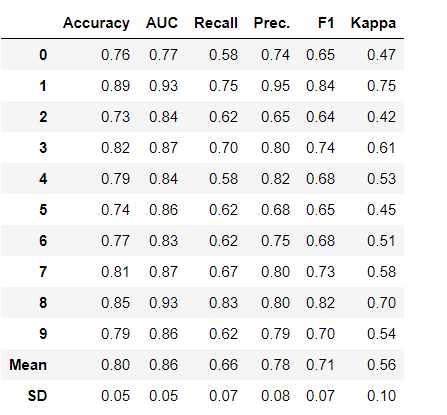
分類モデルを選択して、モデリングを行います。create_model()を使います。
今回は、Random Forest Classifierモデルを利用します。
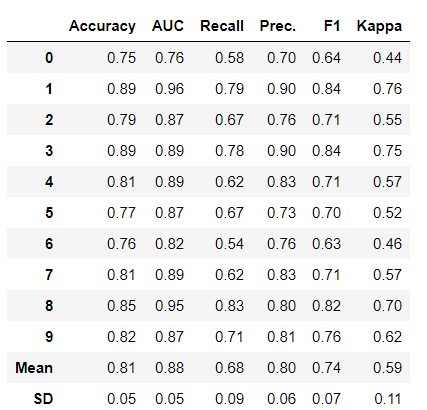
dt = create_model('rf', round=2)
結果
6.分析モデルのチューニング
tune_modelを用いて、モデルのチューニングも行います。
tuned_rf = tune_model('rf',round=2)
結果
チューニング前のAccuracyの平均が0.80、チューニング後のAccuracyの平均が0.81と改善されました。
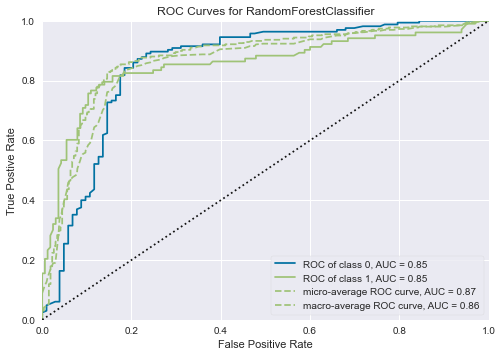
7.分析モデルの可視化
plot_modelを用いて、分析結果を可視化します。
まず、AUC曲線をプロットします。
plot_model(tuned_rf, plot = 'auc')
結果
!
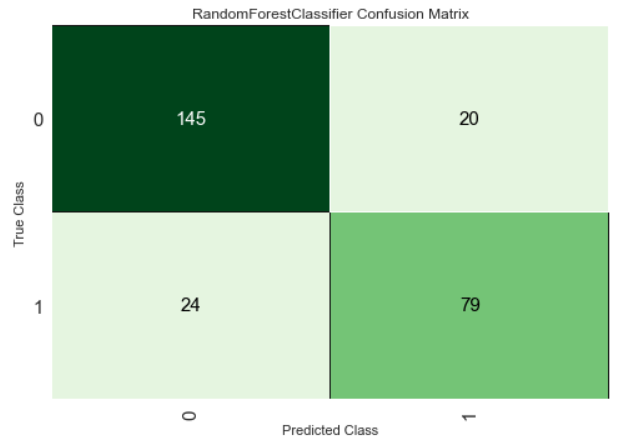
次に、混同行列をプロットします。
plot_model(tuned_lightgbm, plot = 'confusion_matrix')
結果
!
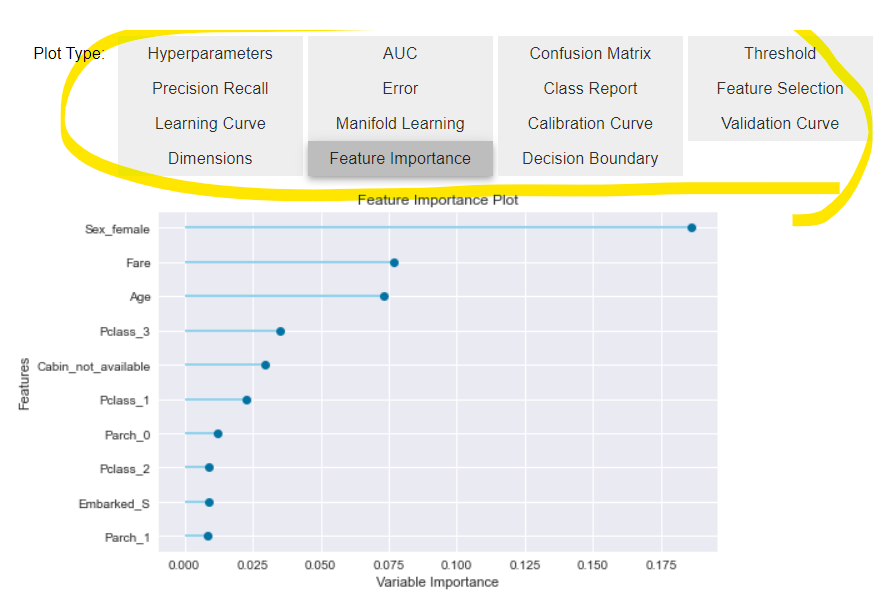
8.分析モデルの評価
evaluate_model()を使い、複数の評価を同時に行うことが可能です。
evaluate_model(tuned_rf)
黄色い枠の中のボタンを押すと、各々の評価結果が表示されます。
結果
!
9.予測
finalize_model()でモデルをFinalizeした後、predict_model()で予測を行います。
予測の時には、テストデータ(ここでは、test.csv)を使います。
final_rf = finalize_model(tuned_rf)
data_unseen = pd.read_csv('test.csv')
result = predict_model(final_rf, data = data_unseen)
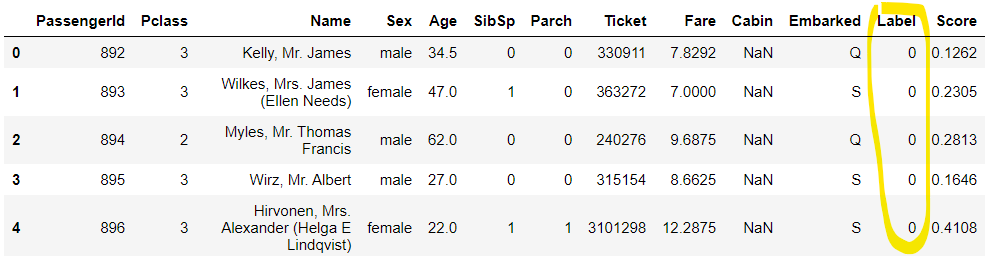
Label列は、予測の結果を意味します。
結果
!
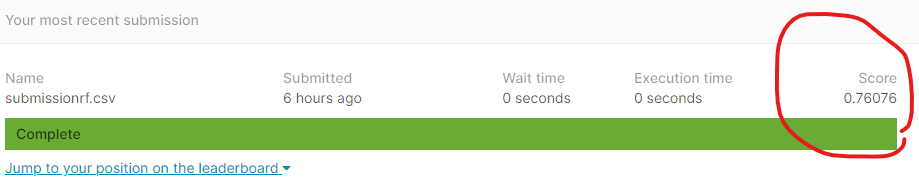
Kaggleにこの結果をUploadしました。Scoreは0.76076でした。
10.まとめ
- タイタニック生存予測のデータセットを利用し、PyCaretで分析を行いました。
- 大変使いやすいです。商用分析ツールのAlteryx, DataRobotにも負けないほどの高い分析機能だと思います。
10.1 分析に使用したPycaret関数一覧
- データの前処理: setup()
- モデルの比較: compare_models()
- 分析モデルの生成: create_model()
- チューニング: tune_model()
- 可視化: plot_model()
- 評価: evaluate_model()
- 予測: finalize_model(), predict_model()
11.参考資料
1.PyCaret Home Page , http://www.pycaret.org/
2.PyCaret Classification, https://pycaret.org/classification/
3. 最速でPyCaretを使ってみた, https://qiita.com/s_fukuzawa/items/5dd40a008dac76595eea
4.PyCaretでワインの品質を分類してみた. https://qiita.com/kotai2003/items/c8fa7e55230d0fa0cc8e