1. はじめに
Google Colabを利用に有用なTipsを纏めます。
2. 課題
Google Colab Proを使う場合、実行時間が最長24時間である制限があります。従ってモデルの計算量が24時間を過ぎてしまうと、計算結果が途中で消えてしまう問題があります。
例えば、200 epochsの計算に約24時間かかると見積し、実際に計算を走らせたら、少し時間がかかってしまい、190 epochsの付近で、Google Colabの接続が切れてしまうことがあります。
3. 解決方法
これを解決するために、下記の方法を採用します。
- KerasのModelCheckpoint()を利用し、細目にモデルを保存する。
- モデルの保存先は、Google Driveのtempフォルダー (参考:Google Colab Tips整理)
- 途中からモデルを呼び出し、計算が終わった時点から学習を再開する。
3.1. ModelCheckpoint()の設定
from tensorflow.keras.callbacks import ModelCheckpoint
checkpoint = ModelCheckpoint(filepath = 'XXX.h5',
monitor='loss',
save_best_only=True,
save_weight_only=False,
mode='min'
period=1)
引数説明###
1.filepath: 文字列,モデルファイルを保存するパス
2.monitor: 監視する値
3.save_best_only: save_best_only=Trueの場合,監視しているデータによって最新の最良モデルが上書きされません
4.mode: {auto, min, max}の内の一つが選択されます
5.save_weights_only: Trueなら,モデルの重みが保存されます そうでないなら,モデルの全体が保存されます
6.period: チェックポイント間の間隔(エポック数)
3.2. 一回目の学習→途中結果をGoogle Driveに保存
KerasのMNISTの事例でコードを作成します。
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.datasets import mnist
Google Drive Mount、モデル保存フォルダーの設定
from google.colab import drive
drive.mount('/content/drive')
MODEL_DIR = "/content/drive/My Drive/temp"
if not os.path.exists(MODEL_DIR): # ディレクトリが存在しない場合、作成する。
os.makedirs(MODEL_DIR)
checkpoint = ModelCheckpoint(
filepath=os.path.join(MODEL_DIR, "model-{epoch:02d}.h5"), save_best_only=True)
学習実行###
history = model.fit(Xtrain, Ytrain, batch_size=BATCH_SIZE, epochs=NUM_EPOCHS, validation_split=0.1, callbacks=[checkpoint])
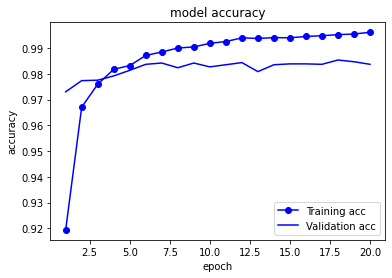
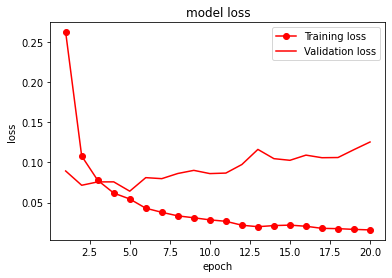
上記のコードを実行すると、モデルファイルがtempフォルダに保存されます。
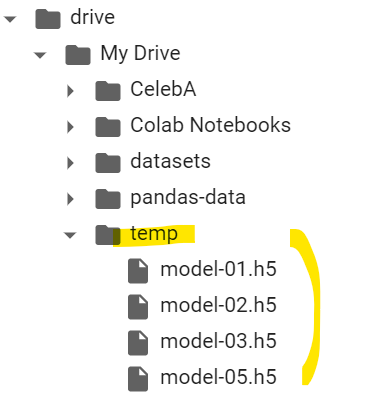
3.3. 2回目の学習→1回目のモデルを呼び出し、途中から学習を再開
model-05.h5を呼び出すことから始まります。
モデルの読み込み
# モデルの読み込み
model.load_weights(os.path.join(MODEL_DIR, "model-05.h5")) # のモデルを指定
2回目の学習モデルの名前変更
model-XX.hを model_new-XX.hに変更します。
if not os.path.exists(MODEL_DIR): # ディレクトリが存在しない場合、作成する。
os.makedirs(MODEL_DIR)
checkpoint = ModelCheckpoint(
filepath=os.path.join(MODEL_DIR, "model_new-{epoch:02d}.h5"),
monitor = 'loss',
save_best_only=True,
mode='min',
period=1)
続けて学習実行###
history = model.fit(Xtrain, Ytrain, batch_size=BATCH_SIZE, epochs=NUM_EPOCHS, validation_split=0.1, callbacks=[checkpoint])
Training accの値を見ると、前回の学習が終わった時点から学習が再開されたことが分かります。
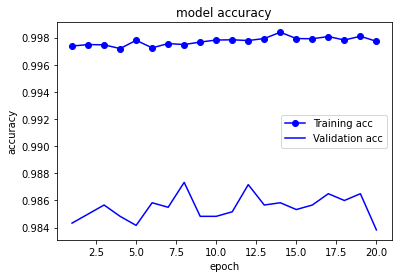
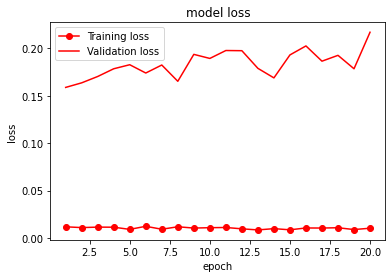
新しく学習されたモデルも保存されます。
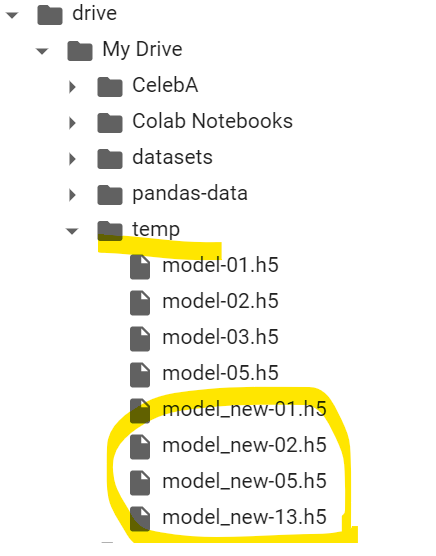
4. まとめ
- Google Colab Proの24時間接続切れの問題があります。
- KerasのModelCheckpoint()とGoogle Driveのマウントでこの問題を解決することにしました。
- 提案した方法の動作・実効性を確認しました。
4.全体コード
1回目の学習
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.utils import to_categorical
import os
import matplotlib.pyplot as plt
from google.colab import drive
drive.mount('/content/drive')
MODEL_DIR = "/content/drive/My Drive/temp"
if not os.path.exists(MODEL_DIR): # ディレクトリが存在しない場合、作成する。
os.makedirs(MODEL_DIR)
checkpoint = ModelCheckpoint(
filepath=os.path.join(MODEL_DIR, "model-{epoch:02d}.h5"), save_best_only=True)
BATCH_SIZE = 128
NUM_EPOCHS = 20
(Xtrain, ytrain), (Xtest, ytest) = mnist.load_data()
Xtrain = Xtrain.reshape(60000, 784).astype("float32") / 255
Xtest = Xtest.reshape(10000, 784).astype("float32") / 255
Ytrain = to_categorical(ytrain, 10)
Ytest = to_categorical(ytest, 10)
print(Xtrain.shape, Xtest.shape, Ytrain.shape, Ytest.shape)
# モデル定義
model = Sequential()
model.add(Dense(512, input_shape=(784,), activation="relu"))
model.add(Dropout(0.2))
model.add(Dense(512, activation="relu"))
model.add(Dropout(0.2))
model.add(Dense(10, activation="softmax"))
model.summary()
model.compile(optimizer="rmsprop", loss="categorical_crossentropy",
metrics=["accuracy"])
# 学習実行
history = model.fit(Xtrain, Ytrain, batch_size=BATCH_SIZE, epochs=NUM_EPOCHS, validation_split=0.1, callbacks=[checkpoint])
# グラフ描画
plt.clf()
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
plot_epochs = range(1, len(acc)+1)
# Accuracy
plt.plot(plot_epochs, acc, 'bo-', label='Training acc')
plt.plot(plot_epochs, val_acc, 'b', label='Validation acc')
plt.title('model accuracy')
plt.ylabel('accuracy') # Y軸ラベル
plt.xlabel('epoch') # X軸ラベル
plt.legend()
plt.show()
loss = history.history['loss']
val_loss = history.history['val_loss']
plot_epochs = range(1, len(loss)+1)
# Accuracy
plt.plot(plot_epochs, loss, 'ro-', label='Training loss')
plt.plot(plot_epochs, val_loss, 'r', label='Validation loss')
plt.title('model loss')
plt.ylabel('loss') # Y軸ラベル
plt.xlabel('epoch') # X軸ラベル
plt.legend()
plt.show()
2回目以降の学習
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.utils import to_categorical
import os
import matplotlib.pyplot as plt
from google.colab import drive
drive.mount('/content/drive')
MODEL_DIR = "/content/drive/My Drive/temp"
if not os.path.exists(MODEL_DIR): # ディレクトリが存在しない場合、作成する。
os.makedirs(MODEL_DIR)
checkpoint = ModelCheckpoint(
filepath=os.path.join(MODEL_DIR, "model-{epoch:02d}.h5"), save_best_only=True)
# モデルの読み込み
model.load_weights(os.path.join(MODEL_DIR, "model-05.h5")) # のモデルを指定
if not os.path.exists(MODEL_DIR): # ディレクトリが存在しない場合、作成する。
os.makedirs(MODEL_DIR)
checkpoint = ModelCheckpoint(
filepath=os.path.join(MODEL_DIR, "model_new-{epoch:02d}.h5"),
monitor = 'loss',
save_best_only=True,
mode='min',
period=1)
# 学習再開
history = model.fit(Xtrain, Ytrain, batch_size=BATCH_SIZE, epochs=NUM_EPOCHS, validation_split=0.1, callbacks=[checkpoint])
# グラフ描画
plt.clf()
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
plot_epochs = range(1, len(acc)+1)
# Accuracy
plt.plot(plot_epochs, acc, 'bo-', label='Training acc')
plt.plot(plot_epochs, val_acc, 'b', label='Validation acc')
plt.title('model accuracy')
plt.ylabel('accuracy') # Y軸ラベル
plt.xlabel('epoch') # X軸ラベル
plt.legend()
plt.show()
loss = history.history['loss']
val_loss = history.history['val_loss']
plot_epochs = range(1, len(loss)+1)
# Accuracy
plt.plot(plot_epochs, loss, 'ro-', label='Training loss')
plt.plot(plot_epochs, val_loss, 'r', label='Validation loss')
plt.title('model loss')
plt.ylabel('loss') # Y軸ラベル
plt.xlabel('epoch') # X軸ラベル
plt.legend()
plt.show()