概要
新卒3ヶ月目です。この記事も3回目になりました。
前回の記事→【Python】新卒入社して2ヶ月経ったのでKaggleのTitanicにチャレンジする②【決定木】
前々回の記事→【Python】新卒入社して2ヶ月経ったのでKaggleのTitanicにチャレンジする【KNN】
今回も前回,前々回に引き続き,Pythonと機械学習の練習です。
KNN,決定木と来たので,今回は「ランダムフォレスト」を使っていこうと思います。
それではやっていきます。
今回のやること一覧
1.データ概観,モデル構築用データ確認
2.ランダムフォレストによる予測モデル構築
3.テストセットの生存予測,結果
環境
- Windows10
- Anaconda
- Python 3.6.5
- JupyterNotebook
1.元データ概観,モデル構築用データ確認
モデル構築に入る前に,まずは使うデータの内容を確認していきます。前回に引き続き,Kaggleが提供してくれる以下12列,891行のデータを使います。
使用データ:train.csv(全12列,891行)
| カラム | 内容 | 説明 |
|---|---|---|
| PassengerId | 搭乗者番号 | |
| Survival | 生死 | 0なら死亡,1なら生存 |
| Pclass | チケットの等級 | 1 = 1st,2 = 2nd,3 = 3rd |
| Name | 名前 | 「First name , 敬称 . Last name(旧姓)」のフォーマット |
| Sex | 性別 | maleかfemale |
| Age | 年齢 | 1歳未満の場合は少数表記,推定した年齢なら「~.5」の表記 |
| SibSp | 同乗してた兄弟姉妹,配偶者の人数 | |
| Parch | 同乗してた両親,子供の人数 | |
| Ticket | チケット番号 | |
| Fare | 運賃 | |
| Cabin | 客室番号 | |
| Embarked | 搭乗した港 | C = Cherbourg,Q = Queenstown,S = Southampton |
これらの変数からなるtrainデータを処理していって,モデル構築に必要なData Frameにしていきます。具体的には
PassengerId,Survived,Pclass,First(NameのFirstNameの部分のみ),Title(NameのTitle(敬称)の部分のみ),Last(NameのLastNameの部分のみ),Sex,Age(欠損値にはTitleの平均年齢を補完),SibSp,Parch,Fare,Cabin(欠損値は0,そうでなければ1に変換),Embarked(欠損値の行は除外),Family(SibspとParchと自分(1)を足した人数)
の,14列889行にしました。
手順等はぜひ,前回の記事を参考にしてみて下さい(宣伝)。
2.ランダムフォレストによる予測モデル構築
特徴量作成
いつも通り,まずは特徴量作成,予測に必要な変数のみにして,各変数をダミー変数化します。この辺りも前回と同じですね。
df_train['Sex'] = df_train['Sex'].where(df_train['Sex'] == 'male', 1)
df_train['Sex'] = df_train['Sex'].where(df_train['Sex'] == 1, 0)
df_train.loc[:, 'Sex'] = df_train.loc[:, 'Sex'].astype(np.int64)
df_train.loc[:, 'Cabin'] = df_train.loc[:, 'Cabin'].astype(np.int64)
df_train.loc[:, 'Age'] = df_train.loc[:, 'Age'].astype(np.float64)
df_train_x = df_train[['Pclass', 'Age', 'Sex', 'Cabin', 'Fare', 'Embarked', 'Family']]
df_train_y = df_train['Survived']
df_train_category_x = pd.get_dummies(df_train_x)
これで準備完了です。
なぜランダムフォレストなのか
さて,モデル構築に入る前に,なぜランダムフォレストを使うのか?を考えなくてはいけません。
前回の記事で使用した決定木(Decision Tree)という手法は,いくつもの枝を持つ,木のようなモデルを構築することで,データを分類していました。
分類手法が可視化しやすく,理解しやすい,各データを標準化,正規化せずそのまま使える為手間がかからない,というようなメリットがある一方で,トレインデータに出来る限り適合しようと,複雑なモデルを構築するため,汎化性能が低くなる傾向にある,という欠点も抱えていました。
そこで,決定木のような分かりやすい,理解しやすい手法を用いながら,その欠点であるトレインデータに対する過剰適合を抑えられるような手法を用いたい,というのが,ランダムフォレストを選択する理由になります。
では,ランダムフォレストとは?
ランダムフォレストは,その名の通り森のように,いくつもの,それぞれ異なった決定木を作成し,それらの平均を取ることで,個々の決定木の過剰適合している部分が均された予測モデルを構築する手法です(ランダムフォレストの詳しい解説は,[Pythonではじめる機械学習]
(https://www.amazon.co.jp/Python%E3%81%A7%E3%81%AF%E3%81%98%E3%82%81%E3%82%8B%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92-%E2%80%95scikit-learn%E3%81%A7%E5%AD%A6%E3%81%B6%E7%89%B9%E5%BE%B4%E9%87%8F%E3%82%A8%E3%83%B3%E3%82%B8%E3%83%8B%E3%82%A2%E3%83%AA%E3%83%B3%E3%82%B0%E3%81%A8%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%81%AE%E5%9F%BA%E7%A4%8E-Andreas-C-Muller/dp/4873117984)と[Python機械学習プログラミング]
(https://www.amazon.co.jp/Python-%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9F%E3%83%B3%E3%82%B0-%E9%81%94%E4%BA%BA%E3%83%87%E3%83%BC%E3%82%BF%E3%82%B5%E3%82%A4%E3%82%A8%E3%83%B3%E3%83%86%E3%82%A3%E3%82%B9%E3%83%88%E3%81%AB%E3%82%88%E3%82%8B%E7%90%86%E8%AB%96%E3%81%A8%E5%AE%9F%E8%B7%B5-impress-gear/dp/4295003379/ref=dp_ob_title_bk)を参考にしました)。
ハイパーパラメータ
それでは,ランダムフォレストによるモデル構築に入っていこうと思いますが,その前に,もう一つだけ触れておかなければならないことがあります。
ハイパーパラメータです。
ハイパーパラメータとは?
前々回の記事,KNNでモデル構築をした際に,Kの数は自分で1から41まで実際に試して,一番スコアのいいものを選びました。
また,前回の決定木の際には,決定木の深さ(max_depth)を,同じように1から10まで実際に試して,スコアもよく,過剰適合と適合不足のバランスが取れていそうなものを自分で選び,モデルを構築しました。
これらのように,機械学習の手法において,モデルを構築する際に自身で調整し,選択するパラメータのことを,ハイパーパラメータと呼びます。
今回のランダムフォレストにもいくつかのハイパーパラメータが存在するため,それらをどう設定するか,どう設定すれば最適なモデルが構築できるかを考え,調整していかなければいけません。
今回は特に「max_depth」,「n_estimators」,「max_features」,「min_samples_split」の4つを調整していきます。max_depthは前回用いた「木の深さ」です。深ければ深いほど,モデルは複雑になるためトレインデータに過剰適合しやすくなりました。
他の3種はそれぞれ…
n_estimators:作成する決定木の数。デフォルトは10。
単独の決定木の場合には過剰適合が問題になったが,ランダムフォレストではここで作成した複数の決定木の平均を取って最終的なモデルを構築する為,多ければ多いほど個々の決定木内の過剰適合が均され,汎化性能が高いモデルが構築できる。
max_features:個々の決定木作成時に用いる変数の数の最大値。デフォルトはデータセットに含まれる変数の数の平方根。例えば,max_features=3ならば,複数ある変数の内から3つが選択され,それをもとに決定木が構築される。
用いる変数の数が多ければ個々の決定木の構造は似たようなものになり,トレインデータに適合しやすくなる。一方で,用いる変数の数が少なすぎればトレインデータに対して適合不足となりやすい。
min_samples_split:個々の決定木において,分岐の続行を判断するためのサンプル数。デフォルトは2。例えば,min_samples_split=2ならば,一つの分岐によって各分岐後の葉にサンプルが2つ以上あった場合はまだ分岐を続行し,そうでないならそこで終わる。
分岐続行の判断のためのサンプル数が小さすぎれば,モデルがトレインデータに過剰適合する可能性が高く,逆に,大きなサンプル数を許すと,適合不足になる可能性もある。
こんな感じです。
前回や前々回は,このハイパーパラメータは実際に色々試して,結果を見比べて選択していました。しかし,今回の4つのパラメータの組み合わせでもそれをやろうとすると,かなり手間がかかってしまいます。
そこで,今回は「グリッドサーチ」という手法を用いて,モデル構築に最も適したパラメータの組み合わせを検討し,モデルの検証に「交差検証」という手法を用いて,より妥当性の高いモデルを構築していきます(グリッドサーチによる特徴量探索,交差検証によるモデル検証の解説,詳細については,[Pythonではじめる機械学習]
(https://www.amazon.co.jp/Python%E3%81%A7%E3%81%AF%E3%81%98%E3%82%81%E3%82%8B%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92-%E2%80%95scikit-learn%E3%81%A7%E5%AD%A6%E3%81%B6%E7%89%B9%E5%BE%B4%E9%87%8F%E3%82%A8%E3%83%B3%E3%82%B8%E3%83%8B%E3%82%A2%E3%83%AA%E3%83%B3%E3%82%B0%E3%81%A8%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%81%AE%E5%9F%BA%E7%A4%8E-Andreas-C-Muller/dp/4873117984)と[Python機械学習プログラミング]
(https://www.amazon.co.jp/Python-%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9F%E3%83%B3%E3%82%B0-%E9%81%94%E4%BA%BA%E3%83%87%E3%83%BC%E3%82%BF%E3%82%B5%E3%82%A4%E3%82%A8%E3%83%B3%E3%83%86%E3%82%A3%E3%82%B9%E3%83%88%E3%81%AB%E3%82%88%E3%82%8B%E7%90%86%E8%AB%96%E3%81%A8%E5%AE%9F%E8%B7%B5-impress-gear/dp/4295003379/ref=dp_ob_title_bk)を参考にしました。本当に助かっています。ありがとう。)。
また,グリッドサーチにおけるハイパーパラメータの検討については,scikit_learnとTensorFlowによる実践機械学習を参考にしました。
それでは,長くなりましたが,ランダムフォレストによる予測モデルを構築していきましょう。
予測モデル構築
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.grid_search import GridSearchCV
X_train, X_test, y_train, y_test = train_test_split(df_train_category_x, df_train_y, random_state=1)
rf_model = RandomForestClassifier(random_state=1)
# max_featuresを1から9で試す
features = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# n_estimatorsを以下の6つで試す
estimates = [10, 100, 200, 300, 400, 500]
# min_samples_splitを以下の5つで試す
min_sample = [2, 4, 6, 8, 10]
# max_depthを以下の5つで試す
depthes = [1, 3, 5, 10, 15]
params = {'n_estimators':estimates, 'max_features':features, 'min_samples_split':min_sample, 'max_depth':depthes}
# グリッドサーチで,上記の9*6*5*5(1350)通りを全て試す。
# cv=5:入力したデータを5分割し,その内4つをトレインデータに,1つをテストデータにしてモデルを構築,精度を出力することを5回繰り返す。
# 5回のスコアの平均値を,モデルのスコアとする(層化5分割交差検証)
grid_cv = GridSearchCV(estimator=rf_model, param_grid=params, cv=5)
grid_cv.fit(X_train, y_train)
# 全組み合わせの内,最もスコアの高かった組み合わせと,そのスコアを表示
display(grid_cv.best_params_, grid_cv.best_score_,
grid_cv.score(X_test, y_test))
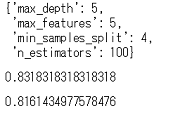
こんな感じでした。
それぞれのパラメータの組み合わせを全検討した結果,以上の組み合わせが最適のようです。
スコアはそれぞれ,最適な組み合わせのモデルを用いた,交差検証によるトレインデータに対する精度と,そのモデルを用いたテストデータに対する精度です。
前回の決定木で起きた様なトレインデータに対する過剰適合も起きてないようですし,テストデータに対しても前回より高い精度を出しています。いい感じですね。
今回は,この組み合わせのモデルを採択することにします。
因みに,ランダムフォレストのもう一つの利点は,「複数(今回は100)作成した決定木において,各変数がどのくらい重要だったか(特徴量重要度)が分かる」ことだそうです。
これは構築したランダムフォレストのモデルの「feature_importance_」で分かりますので,試しに見てみて,可視化してみましょう。
grid_cv_train = RandomForestClassifier(max_depth=5, max_features=5, min_samples_split=4, n_estimators=100, random_state=1)
grid_cv_train.fit(X_test, y_test)
display(grid_cv_train.feature_importances_)
fi = pd.Series(grid_cv_train.feature_importances_, index=X_test.columns).sort_values(ascending=True)
plt.title('random forestの各特徴量重要度')
plt.xlabel('重要度')
fi.plot.barh()
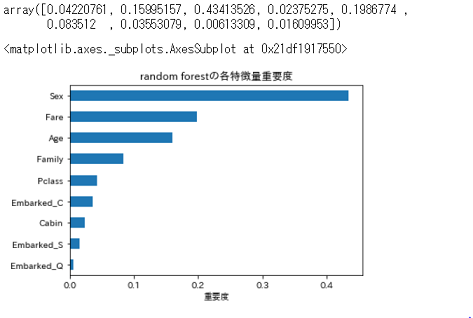
こんな感じでした。
重要度の数値は,モデル構築の際にその変数がどの程度重要だったかを表し,合計で1.0になるようになっています。0ならばデータの分類に全く使われていない,1ならばそれだけで完全に分類ができる,という感じです。
これを見ると,やはりSexがデータの分類にかなり重要なのが分かります。前回の決定木の記事,深さが1で使用する変数がSexのみのモデルでもそこそこの精度が出ていたことの裏付けですね。雑に「男性なら死亡,女性なら生存」と分類出来てしまうくらい,性別の影響は強いようです。
また,Fareが次点で重要なことは少し意外ですね。EDAの際には,払った運賃が7.5より高かったか低かったかで少し生存予測に役立つかな,と思っていましたが,モデル構築の際にはおそらくそれ以上により詳細に,数値データをもとに分類できたものと思われます。
しかし,ここで実際にどのような分類を行ったのか,を確かめようとすると,100個の決定木をそれぞれ見てみなくてはいけませんので,実質不可能ですね。この辺りは,決定木の可視化と理解の簡便性を削ってしまったランダムフォレストの弱みでしょうか。
それ以外については,前々回のEDA通り,という感じですね。EmbarkedもCの場合が一番重要度が高いですが,これはS,C,Qの内Cだけが「死亡者数より生存者数が多かった」という結果からくるものでしょう。
モデル構築の際に特徴量重要度を見ると,全く寄与していない変数があった場合には,それを削除してまたモデルを構築しなおして…という試行錯誤にも役立ちますね(今回は取り敢えずこのままやっていきます)。
それでは,テストセットの生存予測をやっていきましょう。
3.テストセットの生存予測,結果
まずはいつもどおり,testデータをモデル構築に使用したデータと同様になるように処理していきます。
データの処理はtrainデータと同じですので,こちらもぜひ,前回の記事を参考にしてみて下さい(宣伝)。
それが出来たら,各変数をダミー変数化して,前項で構築した予測モデルで生存予測をしていきましょう。
df_test['Sex'] = df_test['Sex'].where(df_test['Sex'] == 'male', 1)
df_test['Sex'] = df_test['Sex'].where(df_test['Sex'] == 1, 0)
df_test.loc[:, 'Sex'] = df_test.loc[:, 'Sex'].astype(np.int64)
df_test.loc[:, 'Cabin'] = df_test.loc[:, 'Cabin'].astype(np.int64)
df_test.loc[:, 'Age'] = df_test.loc[:, 'Age'].astype(np.float64)
df_test_x = df_test[['Pclass', 'Age', 'Sex', 'Cabin', 'Family', 'Fare', 'Embarked']]
df_test_category_x = pd.get_dummies(df_test_x)
rf_test = RandomForestClassifier(max_depth=5, max_features=5, min_samples_split=4, n_estimators=100, random_state=1)
rf_test.fit(X_train, y_train)
rf_predict = rf_test.predict(df_test_category_x)
rf_predict = pd.Series(RF_predict)
submit = pd.concat([df_test_raw['PassengerId'], rf_predict], axis=1).rename(columns={0:'Survived'})
submit.to_csv('gender_submission.csv', index=False)
出来ました。スコアは...
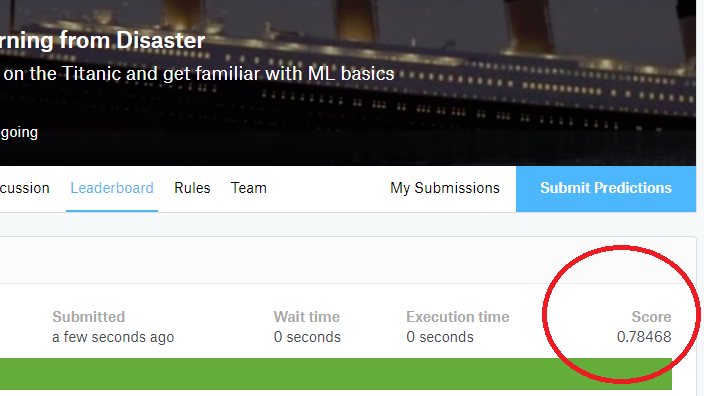
上がってました(前回は0.779)。うれしい。
うれしいのですが…
実は今回,グリッドサーチによるハイパーパラメータ探索,及び交差検証によるモデル検証を行うのに,実行開始から終了まで,かなりの時間がかかりました(30分ほど)。
全試行をしらみつぶしに探索してくれているので,それはありがたいのですが,30分間腕を組んで耐え忍ぶ時間は,かなり苦痛です。
また,今回はscikit_learnとTensorFlowによる実践機械学習を参考に,965*5の組み合わせを試しましたが,今回グリッドサーチで検討しなかった(例えばn_estimators=101や,min_samples_split=3など)パラメータが,ひょっとしたら最適だったかもしれません(これを知るためにもっと多くのパラメータで検討しようとすると,先述の時間の問題が降りかかるジレンマ)。
これらを考えると,出来ればもう少し早く,より恣意的な判断の少ない手法で,ハイパーパラメータの探索を行いたいですね。
まとめ
今回は,機械学習,Pythonの練習として,ランダムフォレストを用いたTitanic生存予測にチャレンジしました。
ランダムフォレストは決定木の欠点を補った,より正確な予測の出来る手法でしたので,スコアは最も高くなりましたが,その反面ハイパーパラメータを検討するのにかなりの時間を要しました。
どの手法を選択するのかだけではなく,その手法をどの様に調整していくのかも,より深く考えていかなければいけませんね。
参考サイト,文献
https://www.kaggle.com/c/titanic
[Pythonではじめる機械学習]
(https://www.amazon.co.jp/Python%E3%81%A7%E3%81%AF%E3%81%98%E3%82%81%E3%82%8B%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92-%E2%80%95scikit-learn%E3%81%A7%E5%AD%A6%E3%81%B6%E7%89%B9%E5%BE%B4%E9%87%8F%E3%82%A8%E3%83%B3%E3%82%B8%E3%83%8B%E3%82%A2%E3%83%AA%E3%83%B3%E3%82%B0%E3%81%A8%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%81%AE%E5%9F%BA%E7%A4%8E-Andreas-C-Muller/dp/4873117984)
[Python機械学習プログラミング]
(https://www.amazon.co.jp/Python-%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9F%E3%83%B3%E3%82%B0-%E9%81%94%E4%BA%BA%E3%83%87%E3%83%BC%E3%82%BF%E3%82%B5%E3%82%A4%E3%82%A8%E3%83%B3%E3%83%86%E3%82%A3%E3%82%B9%E3%83%88%E3%81%AB%E3%82%88%E3%82%8B%E7%90%86%E8%AB%96%E3%81%A8%E5%AE%9F%E8%B7%B5-impress-gear/dp/4295003379/ref=dp_ob_title_bk)
scikit_learnとTensorFlowによる実践機械学習