概要
新卒2ヶ月目です(自己紹介)。
まだ色々と勉強中ですが,早いものでデータ分析会社に入ってから2ヶ月が経過し,Python歴も1ヶ月を超えました。
そこで,今回はPythonによる機械学習の練習として,KaggleのTitanic生存予測にチャレンジしていこうと思います。
公式ページはこちら→https://www.kaggle.com/c/titanic
TrainデータとTestデータをダウンロードして,Trainデータを処理して予測モデルを構築してTestデータの予測をして提出,スコア確認,という流れになります。
日本広しといえど,未経験からKaggleに挑戦する新卒2ヶ月目というのは,中々自分以外にはいないんじゃないかと思いますので,この記事を見た未来の新卒の人などは,ぜひ参考にしてください。
また,この記事をみたデータ分析やプログラマの諸先輩方におかれましては,拙い部分もあるかと思いますが,ぜひ,アドバイス等いただければ幸いです。
それではやっていきます。
今回のやること一覧
1.データ概観,前処理,EDA
2.KNNによる予測モデル構築
3.テストセットの生存予測,結果
環境
- Windows10
- Anaconda
- Python 3.6.5
- JupyterNotebook
1.データ概観,前処理,EDA
まずは使うデータの内容を確認していきます。今回Kaggleが提供してくれるデータは以下12列,891行のデータ(今回の記事では簡単のためNameとTicketは使いません,あしからず)。
使用データ:train.csv(全12列,891行)
| カラム | 内容 | 説明 |
|---|---|---|
| PassengerId | 搭乗者番号 | |
| Survival | 生死 | 0なら死亡,1なら生存 |
| Pclass | チケットの等級 | 1 = 1st,2 = 2nd,3 = 3rd |
| Name | 名前 | 今回は使わない |
| Sex | 性別 | maleかfemale |
| Age | 年齢 | 1歳未満の場合は少数表記,推定した年齢なら「~.5」の表記 |
| SibSp | 同乗してた兄弟姉妹,配偶者の人数 | |
| Parch | 同乗してた両親,子供の人数 | |
| Ticket | チケット番号 | 今回は使わない |
| Fare | 運賃 | |
| Cabin | 客室番号 | |
| Embarked | 搭乗した港 | C = Cherbourg,Q = Queenstown,S = Southampton |
train_csvはひとまず「df_train_raw」でDataFrame化して,行数や欠損数と,データの先頭5行を確認します。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
df_train_raw = pd.read_csv('C:/~hoge~/train.csv')
display(df_train_raw.info(), df_train_raw.head())
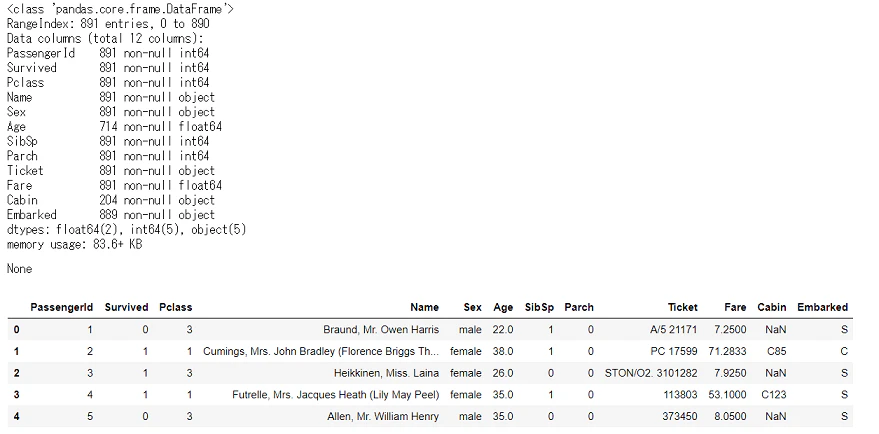
全体は891行,欠損値が含まれてるのはAge,Cabin,Embarkedですが,Cabinは8割くらい欠損しています。
どうやらCabinが欠損している人は客室がなかった,という事のようです。このまま欠損値を除外するには数が多すぎるので,取り敢えずCabinは「あったかなかったか」の0,1にしておきましょう。
for index, values in enumerate(df_train_raw['Cabin']):
try:
if np.isnan(values) == True:
df_train_raw.loc[index, 'Cabin'] = 0
except TypeError:
df_train_raw.loc[index, 'Cabin'] = 1
Ageの欠損値には平均値を入れて,Embarkedの欠損は2件なのでひとまず除外して,今回使う9列だけにして,処理後のData Frame「df_train」を作成。
df_train_raw['Age'] = df_train_raw['Age'].fillna(df_train_raw['Age'].mean())
df_train = df_train_raw[['Survived', 'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Cabin', 'Embarked']].dropna()
df_train.info()
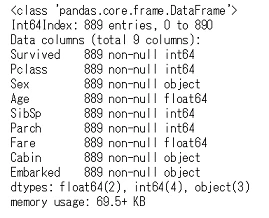
3列と2行落ちて,全部で889行になりました。
それでは,df_trainをもとに,各変数とSurvivedとの関係を簡単に見ていきます。
まずはPclass。
ax = plt.axes()
sns.countplot(x='Pclass', data=df_train, hue='Survived', ax=ax)
ax.set_title('Pclassごとの死亡者,生存者数')
ax.set_ylabel('count(人)')
plt.show()
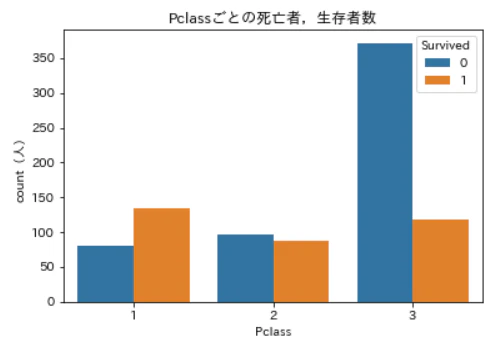
青が死亡者,橙が生存者です。
Pclassの等級が下がると死亡者数は増え,生存者数が減っているのが分かりますね。この変数は生死に大いに関係ありそうです。
次はCabin。
ax = plt.axes()
sns.countplot(x='Cabin', data=df_train, hue='Survived', ax=ax)
ax.set_title('Cabinごとの死亡者,生存者数')
ax.set_ylabel('count(人)')
plt.show()
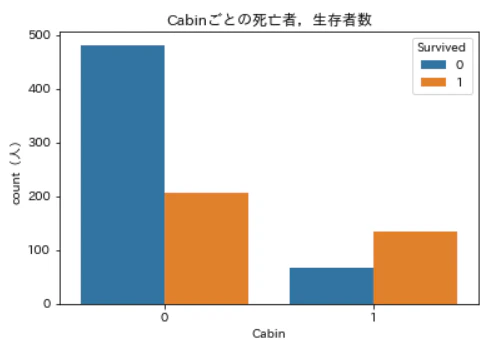
Cabinがない場合には生存者の2倍以上の死亡者が出ていますが,Cabinがあるとちょうどその逆で,生存者数が死亡者数を2倍近く上回っていますね。
これも生存予測に役立ちそうです。
次はSex。これも,あとで分類しやすいように,maleだったら0,femaleだったら1に置換しておきます。
ax = plt.axes()
sns.countplot(x='Sex', data=df_train, hue='Survived', ax=ax)
ax.set_title('Sexごとの死亡者,生存者数')
ax.set_ylabel('count(人)')
plt.show()
for index, values in enumerate(df_train['Sex']):
if values == 'male':
df_train.loc[index, 'Sex'] = 0
else:
df_train.loc[index, 'Sex'] = 1
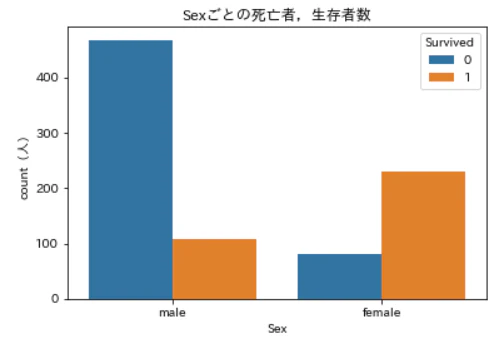
男性の場合は生存者数の3倍以上の死亡者が出ていますが,女性の場合には死亡者数の4倍近い生存者が出ています。
性別がどっちだったかも,生存予測に役立つでしょう。
次はSibSp,Parchですが,これも取り敢えず全部合計して,搭乗時に何人でいたかで分類できるようにします。
家族人数で分類するカラムを追加した新しいData Frameを作成し,そのカラムについての死亡者,生存者数の要約統計量と,それぞれの度数分布を作成していきます(以降はこのData Frameを使います)。
## index振り直し
df_train = df_train.reset_index(drop = True)
## 'SibSp'と'Parch'と自分を足した家族人数のSeriesを作成
family_series = pd.Series(df_train['SibSp'] + df_train['Parch'] + 1)
## family_seriesを追加した新たなData Frameを作成,新カラム名は'Family'
df_train_with_family = pd.concat([df_train, family_series], axis=1).rename(columns={0:'Family'})
## 死亡者,生存者ごとのFamilyの要約統計量
display(df_train_with_family.query('Survived == 0')['Family'].describe(),
df_train_with_family.query('Survived == 1')['Family'].describe())
## 死亡者,生存者数ごとのFamilyの度数分布
ax = plt.axes()
sns.countplot(x='Family', data=df_train_with_family, hue='Survived', ax=ax)
ax.set_title('Family人数ごとの死亡者,生存者数')
ax.set_ylabel('count(人)')
plt.show()
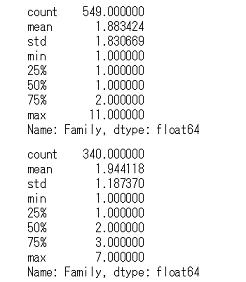
上が死亡者,下が生存者です。平均値などそんなに違いはなさそうですね。
分布はこんな感じです。
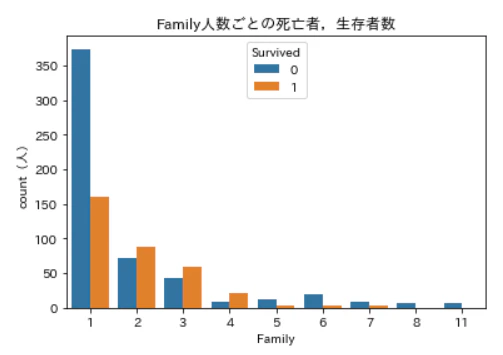
一人で搭乗した人の死亡率は高いですが,複数人だと生存者数の方が高くなっていますね。
搭乗時に一人だったか,それとも誰かと一緒だったかも,生存予測に役立ちそうです。
次はFareです。まずは死亡者と生存者で,それぞれの支払った運賃に関する要約統計量を見ていきます。
display(df_train_with_family.query('Survived == 0')['Fare'].describe(),
df_train_with_family.query('Survived == 1')['Fare'].describe())
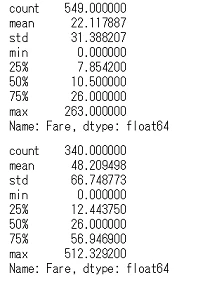
上が死亡者,下が生存者です。
パッと見ると生存者の方が払った運賃は高いようですね。ただ,どちらについても平均値の10倍ほどある最大値が気になります。
分布も確認すると
ax = plt.axes(ylabel='count(人)')
sns.distplot(df_train_with_family.query('Survived == 0')['Fare'], kde=False, bins=10, ax=ax)
sns.distplot(df_train_with_family.query('Survived == 1')['Fare'], kde=False, bins=10, ax=ax)
ax.set_title('Fareごとの死亡者,生存者数')
ax.legend(df_train_with_family['Survived'])
plt.show()
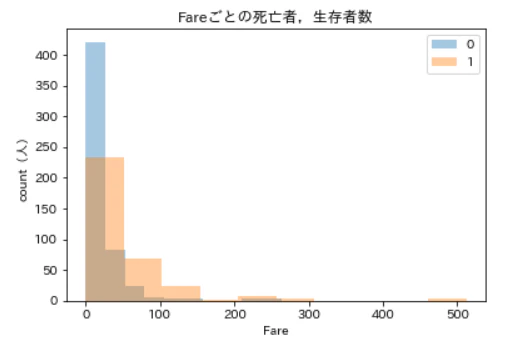
青が死亡者,橙が生存者ですが,やっぱり範囲が広すぎますね。Fareが100以上の人のデータは少なすぎて全然見えません。
しかし100より下の方では何か面白いことが起きていそうですので,Fareを100未満に絞って分布をみてみます。
ax = plt.axes(ylabel='count(人)')
sns.distplot(df_train_with_family.query('Survived == 0 and Fare < 100')['Fare'], kde=False, bins=10)
sns.distplot(df_train_with_family.query('Survived == 1 and Fare < 100')['Fare'], kde=False, bins=10)
ax.set_title('Fareごとの死亡者,生存者数')
ax.legend(df_train_with_family['Survived'])
plt.show()
今度は見やすくなりました。
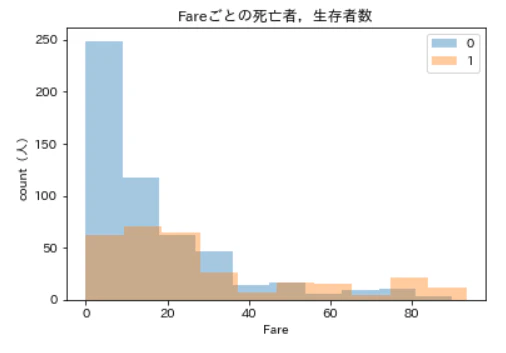
Fareが20より下のあたりで死亡者数がグンと減っていますね。もう少し詳しく見るために,今度はFareを20未満に絞って分布をみてみます。
ax = plt.axes(ylabel='count(人)')
sns.distplot(df_train_with_family.query('Survived == 0 and Fare < 20')['Fare'], kde=False, bins=10)
sns.distplot(df_train_with_family.query('Survived == 1 and Fare < 20')['Fare'], kde=False, bins=10)
ax.set_title('Fareごとの死亡者,生存者数')
ax.legend(df_train_with_family['Survived'])
plt.show()
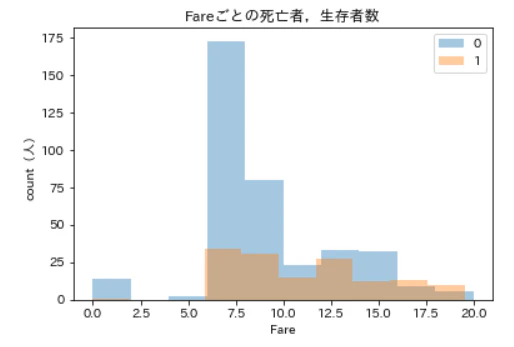
もっと見やすくなりました。生存者数はそこまで変化していませんが,Fareが7.5より大きくなるあたりで,死亡者数が大きく減っているのが分かります。
次はEmbarked。
ax = plt.axes()
sns.countplot(x='Embarked', data=df_train_with_family, hue='Survived', ax=ax)
ax.set_title('Embarkedごとの死亡者,生存者数')
ax.set_ylabel('count(人)')
plt.show()
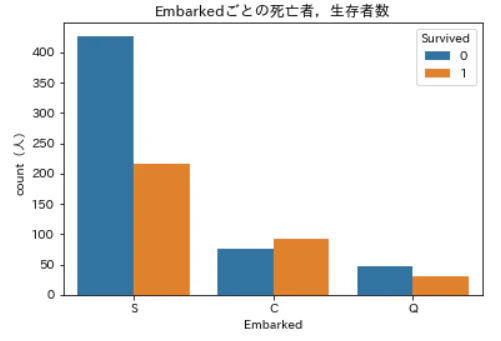
EmbarkedがS,Qの場合では生存者より死亡者の方が多いですが,Cだけは生存者の方が多くなっていますね。
最後はAgeです。まずは死亡者,生存者それぞれについての年齢の要約統計量を確認します。
display(df_train_with_family.query('Survived == 0')['Age'].describe(),
df_train_with_family.query('Survived == 1')['Age'].describe())
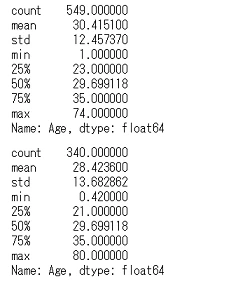
要約統計量は両方とも同じくらい,という感じですが,それぞれの年齢の度数分布も確認します。
ax = plt.axes(ylabel='count(人)')
sns.distplot(df_train_with_family.query('Survived == 0')['Age'], kde=False, bins=7)
sns.distplot(df_train_with_family.query('Survived == 1')['Age'], kde=False, bins=8)
ax.set_title('Ageごとの死亡者,生存者数')
ax.legend(df_train_with_family['Survived'])
plt.show()
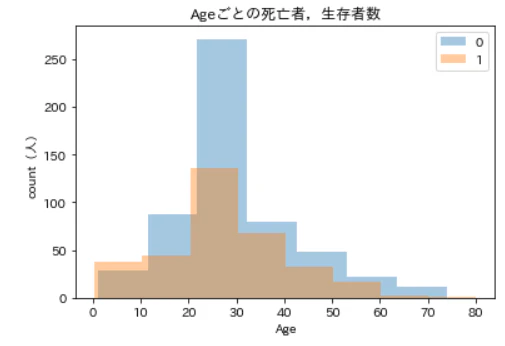
青が死亡者,橙が生存者です。どちらも30代あたりが最も多くそれ以外は段々に減っていく,という感じですが,0歳代~10歳代の区間では,生存者数の方が死亡者数を上回っているようです。
それでは,各変数とSurvivedとの関係を一通り確認できましたので,これらの変数を使って生存予測のためのモデルを作っていきましょう。
2.KNNによる予測モデル構築
実際に予測モデルを作っていきます。今回は,機械学習アルゴリズムの1つであるKNN(K-Nearest Neighbor)を使います。
KNNによるモデル作成に関しては[Pythonではじめる機械学習]
(https://www.amazon.co.jp/Python%E3%81%A7%E3%81%AF%E3%81%98%E3%82%81%E3%82%8B%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92-%E2%80%95scikit-learn%E3%81%A7%E5%AD%A6%E3%81%B6%E7%89%B9%E5%BE%B4%E9%87%8F%E3%82%A8%E3%83%B3%E3%82%B8%E3%83%8B%E3%82%A2%E3%83%AA%E3%83%B3%E3%82%B0%E3%81%A8%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%81%AE%E5%9F%BA%E7%A4%8E-Andreas-C-Muller/dp/4873117984)と[Python機械学習プログラミング]
(https://www.amazon.co.jp/Python-%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9F%E3%83%B3%E3%82%B0-%E9%81%94%E4%BA%BA%E3%83%87%E3%83%BC%E3%82%BF%E3%82%B5%E3%82%A4%E3%82%A8%E3%83%B3%E3%83%86%E3%82%A3%E3%82%B9%E3%83%88%E3%81%AB%E3%82%88%E3%82%8B%E7%90%86%E8%AB%96%E3%81%A8%E5%AE%9F%E8%B7%B5-impress-gear/dp/4295003379/ref=dp_ob_title_bk)を参考にしました。
また,詳しい仕組みについては,
[K近傍法(多クラス分類)]
(https://qiita.com/yshi12/items/26771139672d40a0be32)
こちらの記事を参考にさせていただきました。
KNNはその仕組みがとても分かりやすく,取り敢えず機械学習やってみたい!という方にはおススメです。
それではやっていきましょう。
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
df_train_with_family.loc[:, 'Cabin'] = df_train_with_family.loc[:,'Cabin'].astype(np.int64)
df_train_with_family.loc[:, 'Sex'] = df_train_with_family.loc[:, 'Sex'].astype(np.int64)
## カテゴリ変数(今回はEmbarked)をダミー変数化したData Frameを新たに作成する
df_train_knn_x = pd.get_dummies(df_train_with_family[['Pclass', 'Sex', 'Age', 'Fare', 'Cabin', 'Embarked', 'Family']])
## 使用する変数の標準化
scaler = StandardScaler()
df_train_knn_std_x = scaler.fit_transform(df_train_knn_x)
df_train_knn_y = df_train_with_family['Survived']
## Data Frameをtrainデータとtestデータに分割
X_train, X_test, y_train, y_test = train_test_split(df_train_knn_std_x, df_train_knn_y, random_state=1)
list_kn = []
list_testscore = []
## Kの数を1から41で試してみる
for k in range(1, 41):
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
knn_predict = knn.predict(X_test)
knn_score = round(knn.score(X_test, y_test), 5)
list_kn.append(k)
list_testscore.append(knn_score)
## テストセットに対する最も高い精度とその場合のKを表示
print(max(list_testscore), list_testscore.index(max(list_testscore)))
結果は
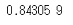
こんな感じです。K=10(インデックスは0から始まってるので,ややこしいですが9番目はKが10個の時です)で,0.84でした。
それでは,このモデルを用いて,実際にテストセットの予測をやってみましょう。
3.テストセットの生存予測,結果
前項で作成したモデルをもとに,今度はKaggle公式からダウンロードした2つ目のデータ,Test.csvのSurvivedを予測していきます。Test.csvは,11列,418行で,当然ながらSurvivedのカラムはありません。それ以外のカラムの情報はTrain.csvと同じですが,行数や欠損値の数が少し違います。
まずはTrain.csv同様,データの確認から始めます。
df_test_raw = pd.read_csv('C:/~hoge~/test.csv')
display(df_test_raw.info(), df_test_raw.head())
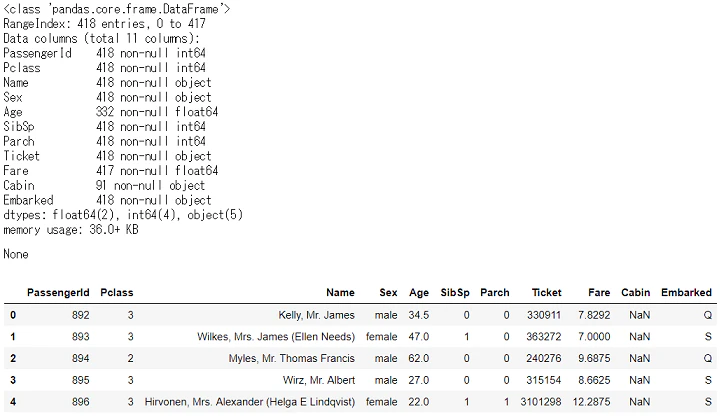
全体は418行,欠損値が含まれてるのはAge,Cabin,Fareでした。
Trainデータと同様に,Ageの欠損値にはAgeの平均値を入れます。Fareの欠損値にも同様に平均値を入れておきましょう。それ以外の変数も,先ほどと同じになるように処理していきます。
df_test = df_test_raw[['Pclass', 'Age', 'Sex', 'SibSp', 'Parch', 'Fare', 'Cabin', 'Embarked']]
for index, values in enumerate(df_test['Cabin']):
try:
if np.isnan(values) == True:
df_test.loc[index, 'Cabin'] = 0
except TypeError:
df_test.loc[index, 'Cabin'] = 1
for index, values in enumerate(df_test['Sex']):
if values == 'male':
df_test.loc[index, 'Sex'] = 0
else:
df_test.loc[index, 'Sex'] = 1
df_test['Age'] = df_test['Age'].fillna(df_test['Age'].mean())
df_test['Fare'] = df_test['Fare'].fillna(df_test['Fare'].mean())
family_series = pd.Series(df_test['SibSp'] + df_test['Parch'] + 1)
df_test_with_family = pd.concat([df_test, family_series], axis=1).rename(columns={0:'Family'})
df_test_with_family.loc[:, 'Cabin'] = df_test_with_family.loc[:,'Cabin'].astype(np.int64)
df_test_with_family.loc[:, 'Sex'] = df_test_with_family.loc[:, 'Sex'].astype(np.int64)
これで,Trainデータと同様に処理が出来ましたので,予測して,Kaggleに提出するCSVファイルを作成していきます。
df_test_knn_x = pd.get_dummies(df_test_with_family[['Pclass', 'Sex', 'Age', 'Fare', 'Cabin', 'Embarked', 'Family']])
df_test_knn_std_x = scaler.fit_transform(df_test_knn_x)
knn = KNeighborsClassifier(n_neighbors=10)
knn.fit(X_train, y_train)
knn_predict = knn.predict(df_test_knn_std_x)
## 提出するファイルを作成 CSV出力
knn_predict = pd.Series(knn_predict)
submit = pd.concat([df_test_raw['PassengerId'], knn_predict], axis = 1).rename(columns = {0:'Survived'})
submit.to_csv('gender_submission.csv')
出来ました。
スコアはこんな感じ。
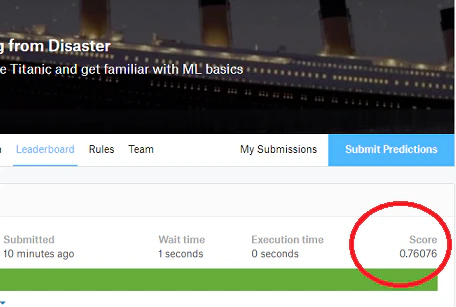
0.76でした。あんまり高くないですが,取り敢えず満足です。
まとめ
今回は機械学習の練習として,KNNを用いてTitanic生存予測にチャレンジしました。
前述したように,KNNはどうやって分類してるのか,という仕組みを理解しやすいので,取り敢えず機械学習やってみたい!という方にはおススメですね。
今後は,今回使わなかったName,Ticketの活用,また,SibSpやParchの処理,各欠損値に対するアプローチなどを工夫して,より正確な予測が出来るようにしていきたいです。
参考サイト,文献
https://www.kaggle.com/c/titanic
[Pythonではじめる機械学習]
(https://www.amazon.co.jp/Python%E3%81%A7%E3%81%AF%E3%81%98%E3%82%81%E3%82%8B%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92-%E2%80%95scikit-learn%E3%81%A7%E5%AD%A6%E3%81%B6%E7%89%B9%E5%BE%B4%E9%87%8F%E3%82%A8%E3%83%B3%E3%82%B8%E3%83%8B%E3%82%A2%E3%83%AA%E3%83%B3%E3%82%B0%E3%81%A8%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%81%AE%E5%9F%BA%E7%A4%8E-Andreas-C-Muller/dp/4873117984)
[Python機械学習プログラミング]
(https://www.amazon.co.jp/Python-%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9F%E3%83%B3%E3%82%B0-%E9%81%94%E4%BA%BA%E3%83%87%E3%83%BC%E3%82%BF%E3%82%B5%E3%82%A4%E3%82%A8%E3%83%B3%E3%83%86%E3%82%A3%E3%82%B9%E3%83%88%E3%81%AB%E3%82%88%E3%82%8B%E7%90%86%E8%AB%96%E3%81%A8%E5%AE%9F%E8%B7%B5-impress-gear/dp/4295003379/ref=dp_ob_title_bk)
https://qiita.com/yshi12/items/26771139672d40a0be32