#概要
新卒3ヶ月目になりました(自己紹介)。Python歴も2ヶ月目に突入です。
前回の記事→【Python】新卒入社して2ヶ月経ったのでKaggleのTitanicにチャレンジする【KNN】
の続きです。
前回は「新卒2ヶ月目にしてTitanicスコアカンストする自分,最強では…?」という内容の記事になる予定でしたが,別にカンストしたりしなかったので,今回も機械学習とPythonのTitanic生存予測にチャレンジして,研鑽に努めていこうと思います。
それではやっていきます。
###今回のやること一覧
1.データ概観,前処理,EDA
2.決定木による予測モデル構築
3.テストセットの生存予測,結果
###環境
- Windows10
- Anaconda
- Python 3.6.5
- JupyterNotebook
#1.データ概観,前処理,EDA
まずは使うデータの内容を確認していきます。前回に引き続き,Kaggleが提供してくれる以下12列,891行のデータを使います。
###使用データ:train.csv(全12列,891行)
| カラム | 内容 | 説明 |
|---|---|---|
| PassengerId | 搭乗者番号 | |
| Survival | 生死 | 0なら死亡,1なら生存 |
| Pclass | チケットの等級 | 1 = 1st,2 = 2nd,3 = 3rd |
| Name | 名前 | 「First name , 敬称 . Last name(旧姓)」のフォーマット |
| Sex | 性別 | maleかfemale |
| Age | 年齢 | 1歳未満の場合は少数表記,推定した年齢なら「~.5」の表記 |
| SibSp | 同乗してた兄弟姉妹,配偶者の人数 | |
| Parch | 同乗してた両親,子供の人数 | |
| Ticket | チケット番号 | |
| Fare | 運賃 | |
| Cabin | 客室番号 | |
| Embarked | 搭乗した港 | C = Cherbourg,Q = Queenstown,S = Southampton |
train.csvを「df_train_raw」でDataFrame化して,行数や欠損数と,データの先頭5行を確認します。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
df_train_raw = pd.read_csv('C:/~hoge~/train.csv')
display(df_train_raw.info(), df_train_raw.head())
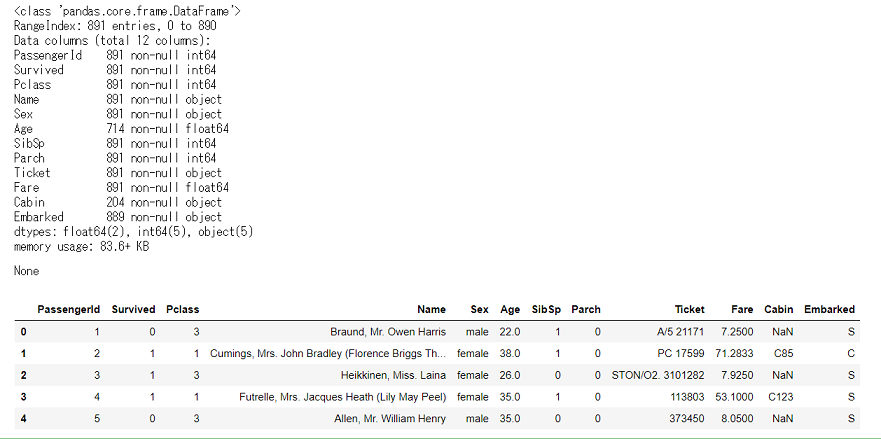
全体は891行,欠損値が含まれているのはAge,Cabin,Embarkedです。この辺りも前回と同じです。
欠損値の多いCabinを「あったかなかったか」の0,1にしておきましょう。
df_train_raw['Cabin'].fillna(0, inplace=True)
df_train_raw['Cabin'] = df_train_raw['Cabin'].where(df_train_raw['Cabin'] == 0, 1)
さて,次は2番目に欠損値の多いAgeです。
前回は欠損していた場合には搭乗者全体の平均値(29.67)を入れていましたが,他のカラムを上手く使って,その人の年代をもう少し正確に予測できるといいですよね。
今回は,前回使わなかったNameを使って,Ageの欠損値を補完していきましょう。
Nameは,各行**「First name , 敬称 . Last name(旧姓)」**という,カンマとピリオドで区切られたフォーマットになっているので,まずは名前を分割して,それぞれのFirst name,敬称,Last nameの入った新しいカラムを追加したData Frameを作りましょう。
df_train_name1 = df_train_raw['Name'].str.split(',', expand=True).rename(columns={0:'First', 1:'Other'})
df_train_name2 = df_train_name1['Other'].str.split('.', expand=True).rename(columns=({0:'Title', 1:'Last', 2:'Other'}))
df_train_names = pd.concat([df_train_name1, df_train_name2], axis=1)[['First', 'Title', 'Last']]
df_train_name = pd.concat([df_train_raw, df_train_names], axis=1)
display(df_train_name.head())
新しいData Frame「df_train_name」はこんな感じです。
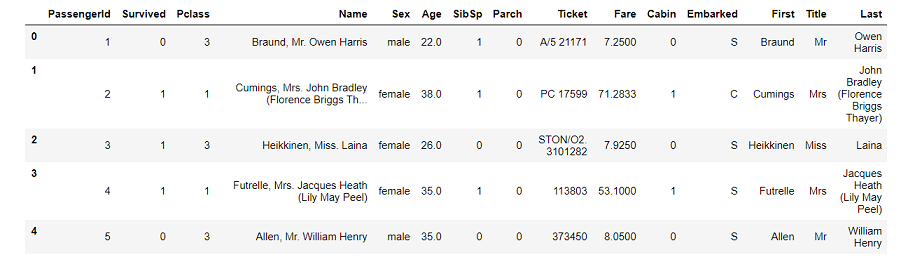
今回注目するのは名前の中央にあったTitleです。
Titleが,各搭乗者の敬称です。日本人にはあまり馴染みのないものかもしれません。
今回train.csvに入っていた搭乗者の敬称全17種類はこんな感じになっていました(和訳,説明はGoogle調べ,間違ってたらすいません)
#####搭乗者の敬称一覧
| 敬称 | 和訳 | 正式名,説明 |
|---|---|---|
| Mr | 男性 | |
| Mrs | 既婚の女性 | |
| Miss | 未婚の女性 | |
| Master | 少年,青年男性 | |
| Don | ドン | スぺイン貴族 |
| Rev | 聖職者 | Reverend |
| Dr | 医者 | Doctor |
| Mme | 既婚女性 | Madame |
| Ms | 女性 | |
| Major | 少佐 | |
| Lady | 貴族の夫人 | |
| Sir | 勲爵士 | |
| Mlle | 未婚の女性 | Mademoiselle |
| Col | 大佐 | Colonel |
| Capt | 船長 | Captain |
| the Countess | 女伯爵 | |
| Jonkheer | ヨンクヘール | オランダ貴族 |
新しく作ったデータフレームをもとに,Titleごとの人数,生存率,平均年齢をまとめたData Frameを作成して,どんな感じになってるか見てみましょう。
## Titleごとの人数,生存率を算出,Data Frame作成
title_list = []
survived_par_list = []
for titles in df_train_name['Title']:
if titles not in title_list:
title_list.append(titles)
survived_par_list.append('{:.3%}'.format(df_train_name.where(df_train_name['Title'] == titles)['Survived'].sum() / df_train_name.where(df_train_name['Title'] == titles)['Survived'].count()))
else:
pass
df_title_survived_count = pd.merge(pd.DataFrame(df_train_name['Title'].value_counts()).reset_index(),
pd.DataFrame(survived_par_list, title_list).reset_index(), on='index')
## Titleごとの平均年齢を算出,Data Frame作成
title_list = []
age_mean_list = []
for titles in df_train_name['Title']:
if titles not in title_list:
title_list.append(titles)
age_mean_list.append('{:.3f}'.format(df_train_name.where(df_train_name['Title'] == titles)['Age'].mean()))
else:
pass
## 作成した2つのData Frameを結合
df_title = pd.merge(df_title_survived_count, pd.DataFrame(age_mean_list, title_list).reset_index(), on='index').rename(columns=({'index':'Title', 'Title':'count', '0_x':'survive', '0_y':'age_mean'}))
display(df_title)
こんな感じです。
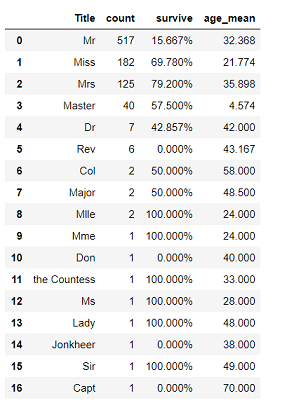
後半のTitleは人数が少ないので,生存率等あまり参考にはなりませんが,上から4種類の平均年齢が分かったのはとてもありがたいですね。
これが分かれば,例えばAgeの欠損した「Master」の人に,全体平均の29歳は入れるべきでなさそうだ,など,欠損値の補完をよりその人の属性に近づいたものに出来ます。
今回は,Ageの欠損している各行には,それぞれのTitleの平均値を入れていくことにしましょう。
df_null_in = pd.merge(df_train_name, df_title[['Title', 'age_mean']], on='Title')
for indexes, values in enumerate(df_null_in['Age']):
if values != values:
df_null_in.iloc[indexes, 5] = df_null_in.iloc[indexes, 15]
else:
pass
df_null_in.head()
こうなります。
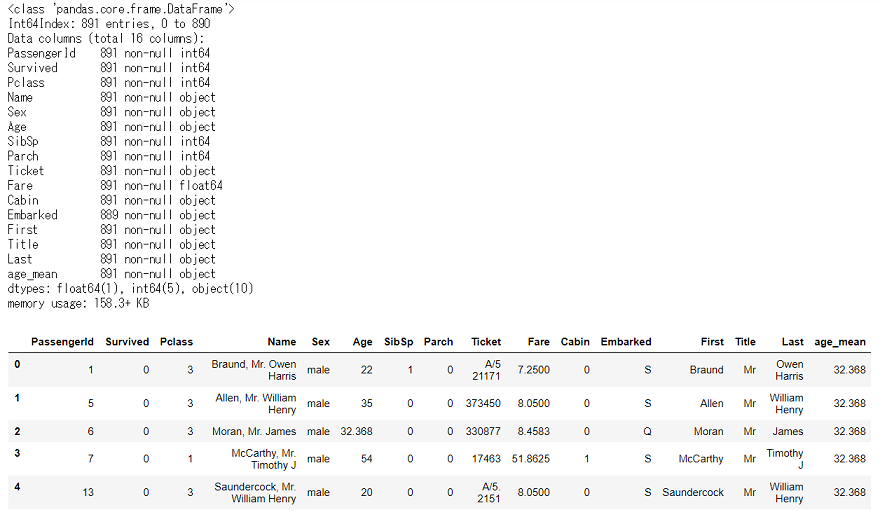
Ageの欠損がなくなりました。5行だけ出したData Frameの,上から3行目が欠損していた行ですね。ちゃんと「Mr」の平均値が入っているのが分かります。
最後に,Embarkedの欠損は2件だけなのでひとまず除外して,モデル構築に必要なカラムだけのData Frameにしましょう。前回同様,家族人数のカラムも作成していきます。
df_train = df_null_in[['PassengerId', 'Survived', 'Pclass', 'First', 'Title',
'Last', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Cabin', 'Embarked']].dropna()
## 家族人数の列FamilyはSibSp,Parchに1(自分)を足して算出
df_train['Family'] = df_train['SibSp'] + df_train['Parch'] + 1
df_train.info()
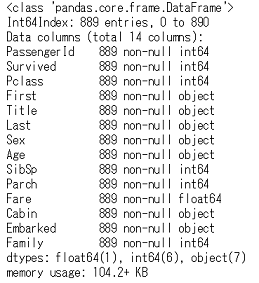
全部で14列,889行です。
それでは,このData Frameを使って,生存予測のためのモデルを作っていきましょう。
#2.決定木による予測モデル構築
モデル構築をする前に,前回調べた各変数とSurvivedの関係をおさらいします。
Pclass:Pclassが高いほど生存率が高い
Cabin:Cabinがあるグループはないグループよりも生存率が高い
Sex:女性は,男性よりも生存率が高い
Family:家族(複数人)で搭乗したグループは,一人で搭乗したグループより生存率が高い
Fare:運賃を7.5より少なく払っているグループは死亡者の数が生存者を上回っている
Embarked:EmbarkedがCのグループでは,生存者の数が死亡者を上回っている
Age:0歳代~10歳代のグループでは,生存者の数が死亡者を上回っている
こんな感じでした。
前回同様,モデル構築に使う変数は上記の7つです。
そして今回は,機械学習アルゴリズムの1つである決定木(Decision Tree)を使います。
決定木によるモデル構築に関しては,今回も[Pythonではじめる機械学習]
(https://www.amazon.co.jp/Python%E3%81%A7%E3%81%AF%E3%81%98%E3%82%81%E3%82%8B%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92-%E2%80%95scikit-learn%E3%81%A7%E5%AD%A6%E3%81%B6%E7%89%B9%E5%BE%B4%E9%87%8F%E3%82%A8%E3%83%B3%E3%82%B8%E3%83%8B%E3%82%A2%E3%83%AA%E3%83%B3%E3%82%B0%E3%81%A8%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%81%AE%E5%9F%BA%E7%A4%8E-Andreas-C-Muller/dp/4873117984)と[Python機械学習プログラミング]
(https://www.amazon.co.jp/Python-%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9F%E3%83%B3%E3%82%B0-%E9%81%94%E4%BA%BA%E3%83%87%E3%83%BC%E3%82%BF%E3%82%B5%E3%82%A4%E3%82%A8%E3%83%B3%E3%83%86%E3%82%A3%E3%82%B9%E3%83%88%E3%81%AB%E3%82%88%E3%82%8B%E7%90%86%E8%AB%96%E3%81%A8%E5%AE%9F%E8%B7%B5-impress-gear/dp/4295003379/ref=dp_ob_title_bk)を参考にしました。
決定木はその名の通り,いくつもの枝を持つ木のようなモデルを構築することで,データを分類していくモデルです。
それではやっていきましょう。
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
df_train['Sex'] = df_train['Sex'].where(df_train['Sex'] == 'male', 1)
df_train['Sex'] = df_train['Sex'].where(df_train['Sex'] == 1, 0)
df_train.loc[:, 'Sex'] = df_train.loc[:, 'Sex'].astype(np.int64)
df_train.loc[:, 'Cabin'] = df_train.loc[:, 'Cabin'].astype(np.int64)
df_train.loc[:, 'Age'] = df_train.loc[:, 'Age'].astype(np.float64)
df_train_x = df_train[['Pclass', 'Age', 'Sex', 'Cabin', 'Fare', 'Embarked', 'Family']]
df_train_y = df_train['Survived']
df_train_category_x = pd.get_dummies(df_train_x)
X_train, X_test, y_train, y_test = train_test_split(df_train_category_x, df_train_y, random_state=1)
tree = DecisionTreeClassifier(random_state=1)
tree.fit(X_train, y_train)
tree_trainscore = round(tree.score(X_train, y_train), 5)
tree_testscore = round(tree.score(X_test, y_test), 5)
display(tree_trainscore, tree_testscore)
結果は…

上がtrainデータ,下がtestデータに対してのスコアです。trainに対しての精度は高いですが,testの精度が低くなっています。
実際に,分類の為にどのようなモデルを構築したのかを確認してみましょう。
## 必要に応じてpip install
from pydotplus import graph_from_dot_data
from sklearn.tree import export_graphviz
features = ['Pclass', 'Sex', 'Age', 'Fare', 'Cabin', 'Family', 'Embarked_C', 'Embarked_Q', 'Embarked_S']
dot_data = export_graphviz(tree, filled=True, rounded=True, class_names=['0', '1'], feature_names=features, out_file=None)
graph = graph_from_dot_data(dot_data)
graph.write_png('tree.png')
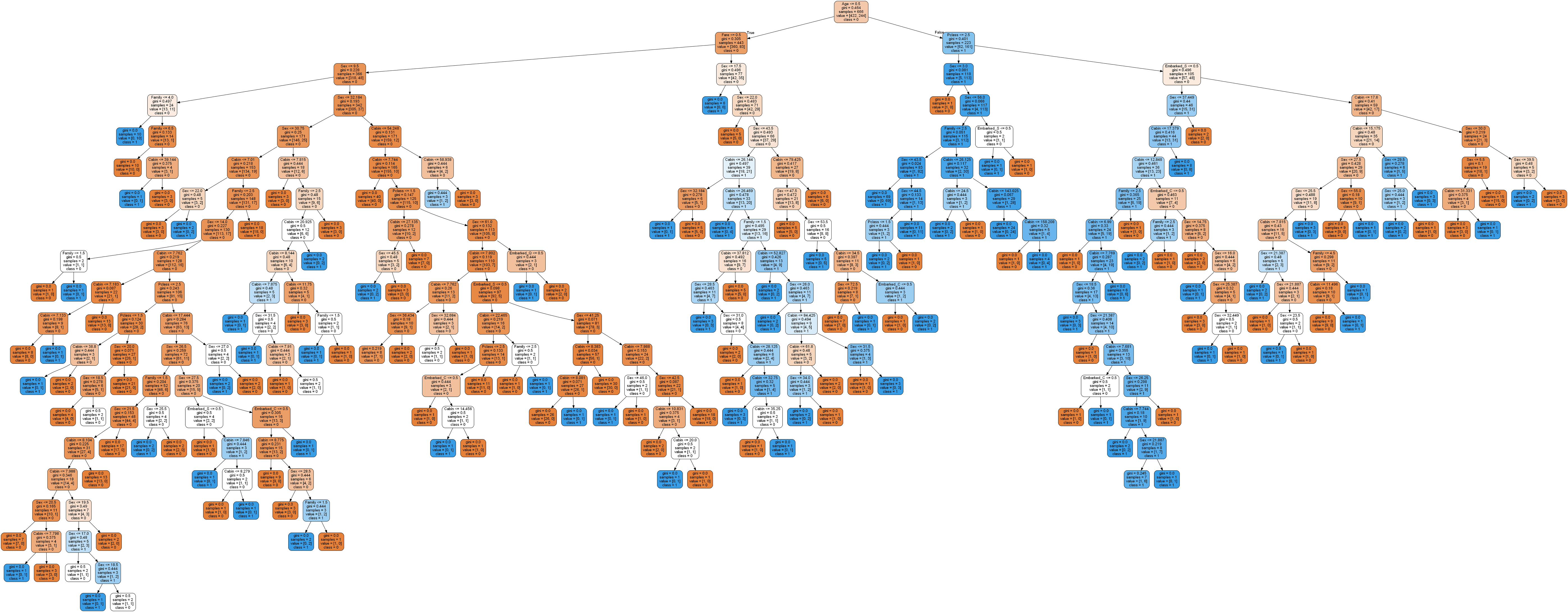
とんでもないことになっていますね。
trainデータを出来るだけ正確に分類できるようにと,多くの枝に別れた,かなり複雑なモデルになっているのが分かります。
しかし,この内の多くは,testデータの分類には必要ない枝かもしれません。
trainデータとtestデータのスコアの乖離は,どうやらこれが原因で生じるようです。
trainデータにだけ過剰に適合するのではなく,それ以外のデータにも上手く適合させられるような,汎化性能の高いモデルを構築しなくては,testデータに対する正確な予測はできないので,このままではいけませんね。
今回は,木の深さを変えてモデルを作っていきましょう。
深さを1から10までの間で試して,trainとtest両データに対するスコアがどう変動するか確認していきます。
ついでに,両スコアがどのくらい離れているのかもわかるようにしましょう。
X_train, X_test, y_train, y_test = train_test_split(df_train_category_x, df_train_y, random_state=1)
train_score_list = []
test_score_list = []
kairi_list = []
for depth in range(1, 10):
tree = DecisionTreeClassifier(max_depth=depth, random_state=1)
tree.fit(X_train, y_train)
train_score_list.append(round(tree.score(X_train, y_train), 5))
test_score_list.append(round(tree.score(X_test, y_test), 5))
kairi_list.append(round(tree.score(X_train, y_train), 5) - round(tree.score(X_test, y_test), 5))
ax = plt.axes(ylabel='スコア', xlabel='木の深さ')
ax.set_title('木の深さごとのtrain,testデータスコア')
plt.plot(range(1, 10), train_score_list, label='train_score')
plt.plot(range(1, 10), test_score_list, label='test_score')
ax.legend()
display(test_score_list.index(max(test_score_list)), max(test_score_list), pd.Series(kairi_list))
結果は…
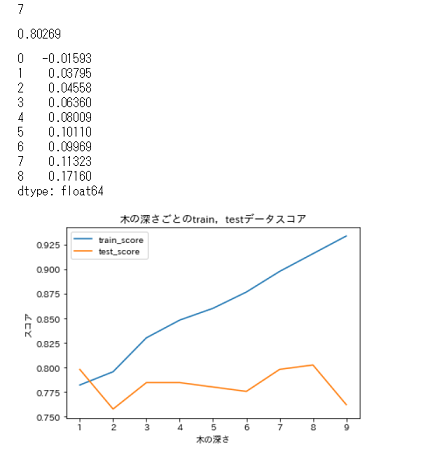
こんな感じでした。深さが8の時,testスコアが最大で0.80になっています。
しかし,深さ8の時も,先ほどと同様にtrainとtestの乖離が大きく,これではやはり過剰適合に対する不安が残ります。かといって次にスコアが高いのは深さが1の場合,これは,木を見ると分かるのですが,性別だけで生死を分類している2択ですのでちょっと…
というわけで,今回はtestスコアも高く,trainスコアとの乖離も比較的小さい深さ3でやってみることにします。
モデルも決まったので,早速test.csvの予測をしていきましょう。
#3.テストセットの生存予測,結果
まずはtrain.csv同様,データの確認から始めます。
df_test_raw = pd.read_csv('C:/~hoge~/test.csv')
display(df_test_raw.info(), df_test_raw.head())
全体は418行,欠損値が含まれているのはAge,Cabin,Fareでした。
Ageの欠損はtrainデータ同様にTitleごとの平均値を,Fareの欠損には全体の平均値を入れるようにしましょう。
まずはtrain同様,Cabinの変換とTitleの確認を行います。
df_test_raw['Cabin'].fillna(0, inplace=True)
df_test_raw['Cabin'] = df_test_raw['Cabin'].where(df_test_raw['Cabin'] == 0, 1)
df_test_name1 = df_test_raw['Name'].str.split(',', expand=True).rename(columns={0:'First', 1:'Other'})
df_test_name2 = df_test_name1['Other'].str.split('.', expand=True).rename(columns=({0:'Title', 1:'Last', 2:'Other'}))
df_test_names = pd.concat([df_test_name1, df_test_name2], axis=1)[['First', 'Title', 'Last']]
display(df_test_names.head(), df_test_names['Title'].unique())
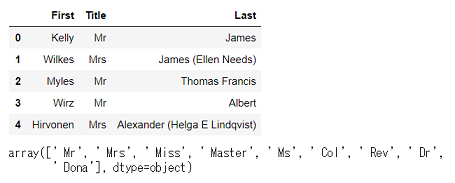
うまく分割できました。testの方は,敬称の種類が少ないですね。
ちなみに新しい敬称「Dona」は,Donの女性形だそうです。
Titleごとの人数と平均年齢もみてみましょう。
df_test_name = pd.concat([df_test_raw, df_test_names], axis=1)
title_list = []
age_mean_list = []
for titles in df_test_name['Title']:
if titles not in title_list:
title_list.append(titles)
age_mean_list.append('{:.3f}'.format(df_test_name.where(df_test_name['Title'] == titles)['Age'].mean()))
else:
pass
df_title = pd.merge(pd.DataFrame(df_test_name['Title'].value_counts()).reset_index(),
pd.DataFrame(age_mean_list, title_list).reset_index(), on='index').rename(columns=({'index':'Title', 'Title':'count', 0:'age_mean'}))
display(df_title)
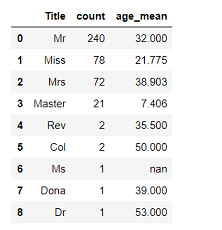
TitleがMsの人は,1件だけで欠損してますね。仕方ないのでここにはtrainの方の平均年齢を入れることにしましょう。
AgeとFareの欠損値を処理して,Familyも追加したData Frame「df_test」を作成します。
dftest_null_in = pd.merge(df_test_name, df_title[['Title', 'age_mean']], on='Title')
for indexes, values in enumerate(dftest_null_in['Age']):
if values != values:
dftest_null_in.iloc[indexes, 4] = dftest_null_in.iloc[indexes, 14]
else:
pass
dftest_null_in['Age'].replace('nan', df_null_in.query('Title == " Ms"').loc[:, 'age_mean'].item(), inplace=True)
df_test = dftest_null_in[['PassengerId', 'Pclass', 'First', 'Title', 'Last', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Cabin', 'Embarked']]
df_test['Family'] = df_test['SibSp'] + df_test['Parch'] + 1
df_test['Fare'] = df_test['Fare'].fillna(df_test['Fare'].mean())
df_test = df_test.sort_values('PassengerId')
df_test.info()
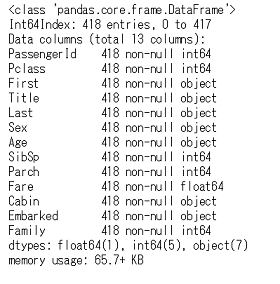
これで準備完了です。
それでは,Survivedの予測をして,Kaggleに提出するCSVファイルを作成していきます。
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
df_test['Sex'] = df_test['Sex'].where(df_test['Sex'] == 'male', 1)
df_test['Sex'] = df_test['Sex'].where(df_test['Sex'] == 1, 0)
df_test.loc[:, 'Sex'] = df_test.loc[:, 'Sex'].astype(np.int64)
df_test.loc[:, 'Cabin'] = df_test.loc[:, 'Cabin'].astype(np.int64)
df_test.loc[:, 'Age'] = df_test.loc[:, 'Age'].astype(np.float64)
df_test_x = df_test[['Pclass', 'Age', 'Sex', 'Cabin', 'Family', 'Fare', 'Embarked']]
df_test_category_x = pd.get_dummies(df_test_x)
tree = DecisionTreeClassifier(max_depth=3, random_state=1)
tree.fit(X_train, y_train)
decision_tree_predict = tree.predict(df_test_category_x)
decision_tree_predict = pd.Series(decision_tree_predict)
submit = pd.concat([df_test_raw['PassengerId'], decision_tree_predict], axis=1).rename(columns={0:'Survived'})
submit.to_csv('gender_submission.csv')
出来ました。
気になるスコアは...
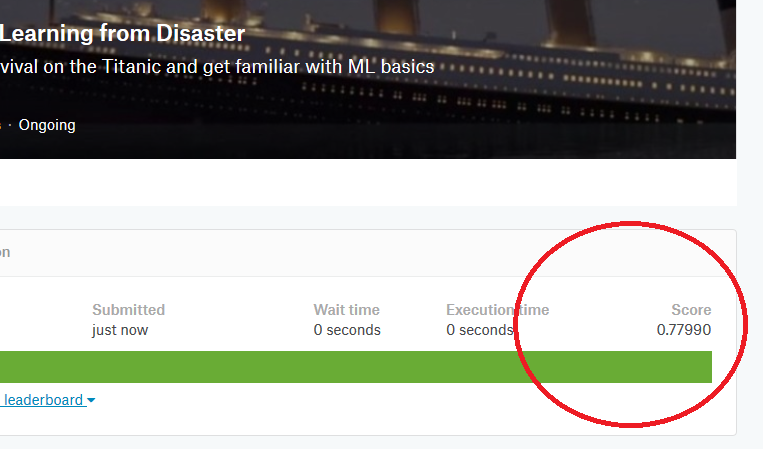
0.779でした。ちょっと上がってます(前回のKNNでは0.76でした)。
小数点以下の変動に一喜一憂するのは少し悔しいですが,やっぱりスコアが上がってると嬉しいですね。
しかし,そこまでガッツリ上がらなかったのは,やはり過剰適合と適合不足のバランスがうまく取れなかったせいでしょうか。
決定木ではこれが限界のようです…
#まとめ
今回は,前回に引き続き機械学習,Pythonの練習として,決定木を用いてTitanic生存予測にチャレンジしました。
決定木はデータに対して構築したモデルを可視化しやすい一方で,学習したデータに過剰に適合しやすく,汎化性能が低くなりがちなので,そのバランスを取って上手くテストデータにも使えるようなモデルを構築するのが難しいです。
次回は,今回用いた決定木のデメリットを補う,ランダムフォレストを使ってやっていこうと思います。
#参考サイト,文献
https://www.kaggle.com/c/titanic
[Pythonではじめる機械学習]
(https://www.amazon.co.jp/Python%E3%81%A7%E3%81%AF%E3%81%98%E3%82%81%E3%82%8B%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92-%E2%80%95scikit-learn%E3%81%A7%E5%AD%A6%E3%81%B6%E7%89%B9%E5%BE%B4%E9%87%8F%E3%82%A8%E3%83%B3%E3%82%B8%E3%83%8B%E3%82%A2%E3%83%AA%E3%83%B3%E3%82%B0%E3%81%A8%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%81%AE%E5%9F%BA%E7%A4%8E-Andreas-C-Muller/dp/4873117984)
[Python機械学習プログラミング]
(https://www.amazon.co.jp/Python-%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9F%E3%83%B3%E3%82%B0-%E9%81%94%E4%BA%BA%E3%83%87%E3%83%BC%E3%82%BF%E3%82%B5%E3%82%A4%E3%82%A8%E3%83%B3%E3%83%86%E3%82%A3%E3%82%B9%E3%83%88%E3%81%AB%E3%82%88%E3%82%8B%E7%90%86%E8%AB%96%E3%81%A8%E5%AE%9F%E8%B7%B5-impress-gear/dp/4295003379/ref=dp_ob_title_bk)