はじめに
皆さん、コーディング支援AIは使用していますか?
GitHub CopilotやCursorが人気ですが、機密情報取り扱いの問題もあり、業務への導入に二の足を踏む企業も多いようです。
そこで今回は、サーバーにデータを送信せず、完全オフラインで実行可能なオープンソースLLMを使用した開発環境を構築する方法を紹介します。
既に優秀な記事がいくつか出ておりますので、オープンソースLLMの比較は行いません。
ローカルで動くLLMを使用した開発環境の作り方
今回使用する環境は以下です。
- OS: Ubuntu 22.04 LTS
- CPU: AMD Ryzen 5 5600u
- Memory: 16GB
1. llama.cppをインストールする
llama.cppは、CPUのみでLLMを動かすことができるライブラリです。(詳しい説明はこちら)
通常、LLMを動かそうとすると高性能のGPUが必要ですが、llama.cppを使用するとノートパソコンでも実行が可能になります。
もともとはLlamaのみでしたが、今ではStableLM、Mixtralといった多くのローカルLLMに対応しています。
今回は開発環境ということもありノートパソコンで動くことを前提としているため、GPUを必要としないllama.cppを使用します。
Macでllama.cppをmakeする場合はデフォルトでmetal(Mac用の設定)が選択されて、GPUが利用できるようになっています。
$ git clone https://github.com/ggerganov/llama.cpp
$ cd llama.cpp
$ make
python3のLLM用環境を作成して、requirement.txtをインストールします。
$ python3 -m venv env_llm
$ source env_llm/bin/activate
$ pip install -r requirements.txt
// 終了時
$ deactivate
インストール完了後、modelsフォルダに移動します。llama.cppで使用したいモデルは全てここに配置します。
$ cd models
// 以降、モデルのダウンロードを行う
$ git clone ~
2. Hugging Faceに登録する
Hugging Faceとは「AI・画像生成に特化したGithub的プラットフォーム」であり、今回のモデルのダウンロードもここから行います。
登録完了後、設定よりアクセストークンを作成してください。
3. コーディング用LLMモデルをダウンロードする
モデルに関する注意事項
モデルのフォーマットについて
llama.cppではGGUFというフォーマットのモデルしか利用できません。
ダウンロードするモデルはGGUFを選択するか、モデルの変換処理を行ってください。変換処理の記事はこちら。
パラメータ数について
LLMのパラメータ数とは、そのモデルが持つ重みとバイアスの総数であり、モデルのサイズと能力の指標になっています。
モデル名としては7B(70億パラメータ)というふうに〇Bと表されることが一般的です。
パラメータ数が上がるほど処理するために要求されるスペックが高くなっていきます。
量子化について
LLMの量子化とは、モデルのパフォーマンスと効率を改善するための技術の一つであり、モデルのサイズを減少させ、推論速度を向上させることができます。詳しくはこちら。
圧縮と性能のバランスをある程度担保するため、llama.cppのコメントによると、[Q4_K_M]、[Q5_K_S]、[Q5_K_M]が推奨されています。
詳しくはこちら。
llama.cppでも量子化のためのコマンドがデフォルトで用意されています。
今回ダウンロードするするモデル
今回実行を試すLLM一覧はこちらです。もっと多くのモデル比較を知りたい場合はこちらの記事をどうぞ。
- CodeLlama: Metaが出しているコーディング用モデル
- ELYZA-japanese-CodeLlama: 日本語での性能が高いとされるモデル
- StableCode: 画像生成で有名なstable diffusionが出しているコーディング用モデル
- Mixtral 8x7B: MoEという技術を用いた高い性能と生成速度を持つモデル
今回、ノートパソコンの開発環境での使用を想定しているため、パラメータは最大7B、量子化方式はQ4_K_M、プログラミングの質問も可能なInstruct(あれば)のモデルを使用します。
私の環境では13BのQ4_K_Mではまともに動きませんでした。
CodeLlamaのインストール
一番有名なオープンソースLLMであり、性能も良いモデルになります。
今回はパラメータ7B、量子化方式Q4_K_Mのモデルを使用します。
$ curl -OL https://huggingface.co/TheBloke/CodeLlama-7B-Instruct-GGUF/resolve/main/codellama-7b-instruct.Q4_K_M.gguf
ELYZA-japanese-CodeLlama
先程のCodeLlamaを日本語に特化させたモデルです。
今回モデルがGGUFフォーマットでないため、変換処理と量子化処理を行う必要があります。
こちらのissueにあるように、llama.cppの変換処理が失敗することがあるためgit-lfsをインストールします。
$ sudo apt-get install git-lfs
$ git lfs install
今回はパラメータ7B、量子化方式Q4_K_Mのモデルを使用します。
$ git clone https://huggingface.co/elyza/ELYZA-japanese-CodeLlama-7b-instruct
// llama.cppのconvert.pyを使用してモデルをGGUFに変換する
$ python3 convert.py --outfile models/elyza-japanese-codellama-7b-instruct.gguf models/ELYZA-japanese-CodeLlama-7b-instruct
// llama.cppの量子化処理により、Q4_K_Mで量子化する
$ ./quantize models/elyza-japanese-codellama-7b-instruct.gguf models/elyza-japanese-codellama-7b-instruct.Q4_K_M.gguf Q4_K_M
StableCode
llama.cppではStableCodeにまだ対応していないため、continueでモデルを使用できません。
pythonコードでの直接実行になるのですが、GPUが必要になるため実行できませんでした。
モデルのダウンロード方法に詰まる箇所があったので、モデルは動かないのですが一応記しておきます。
StableCodeに新しいものがリリースされたようですので、試してみることにしました。パラメータ数は3Bと少なめですが、公式が性能はCodeLlamaと同等と謳っています。
StableCodeを利用する際は規約に同意する必要があるので注意してください。
また、StableCodeの場合認証された状態でないとモデルのダウンロードが行えません。
以下を参考に取得したアクセストークンを使って、huggingface-cliにログインしてください。
$ pip install -U "huggingface_hub[cli]"
$ huggingface-cli login
// アクセストークンをペースト
$ mkdir stablecode-instruct-alpha-3b
$ cd stablecode-instruct-alpha-3b
$ huggingface-cli download stabilityai/stablecode-instruct-alpha-3b --local-dir .
llama.cppではStableCodeにまだ対応していないため、continueでモデルを使用できません。
pythonコードでの実行になるのですが、GPUが必要になるため実行できませんでした。
Mixtral 8x7B
パラメータが57Bであり私のPCではおそらくまともに動かないのですが、性能が良いためとりあえず紹介することにしました。
最大限にモデルサイズを小さくしてあるQ2_Kを利用します。
$ curl -OL https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q2_K.gguf
4. vscodeにcontinueを導入する
continueは、Github Copilotやcursorの代わりとなるオープンソース版Copilotです。
Github CopilotやCursorでは好きなモデルを選ぶことはできませんが、continueではOllamaといったローカルLLMも使用できます。
CursorのコミュニティでもローカルLLMの要望が出ているようですが、実装はまだ先になりそうです。
拡張機能のcontinueをクリックし、下部にある設定アイコンからconfig.jsonを編集します。
llama.cppの追加と情報収集の同意をfalseにします。
{
"models": [
{
"title": "Llama Cpp",
"provider": "llama.cpp",
"model": "llama",
"apiBase": "http://localhost:8080"
},
// ~~snip~~
],
// ~~snip~~
"allowAnonymousTelemetry": false,
}
5. continueとLLMを使用してコーディングする
llama.cppではHTTP Server機能が用意されており、OpenAI APIとの互換性を持っています。
そのため、Continue以外にも、既存の生成系サービスでも簡単に移行することができます。
// llama.cppのルートディレクトリに戻る
$ cd ../
// -c でプロンプトのトークン数を指定
$ ./server -m models/<好きなモデル>.gguf -c 2048
continueでChatGPTのように質問すると答えてくれます。
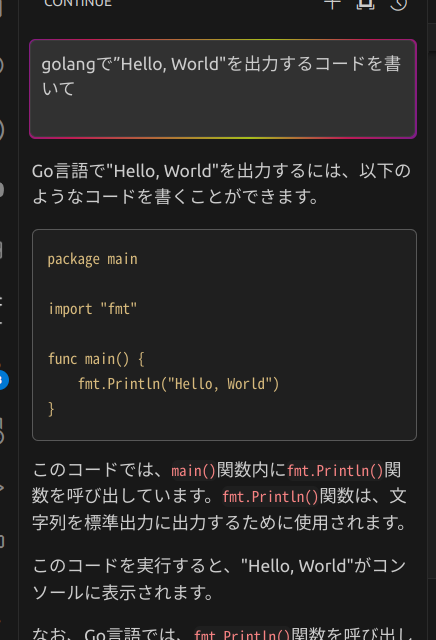
オープンソースLLMを使ってみた所見
今回は環境構築が主であるため、各モデルの細かな性能比較は行いません。
別の方が書かれた比較記事を参照下さい。
CodeLlama
- 13B,Q4_K_M
- 量子化されているとはいえども、私のPCスペックでは遅すぎて使い物になりませんでした。一文字7秒ほどかかっていました。
- 7B, Q4_K_M
- 7BかつQ4_K_Mで量子化した結果、ChatGPTより少し遅い程度のレスポンスが返ってきました。
- コードの精度についてはまだまだ及ばずですが、簡単なものであれば作成可能でした。
ELYZA-japanese-CodeLlama
- 7B, Q4_K_M
- 速度はCodeLlamaと同じくらいでした。
- コードの精度に関しては、やはり日本語特化もあってか、日本語での質問にも流暢に答えてくれました。
- しかし、文章での回答は正しいものの、実際のコードが間違っていたりまだ精度には難ありと感じました。
StableCode
- llama.cppではStableLMには対応しているのですが、StableCodeには未対応です。そのため実行できませんでした。
Mixtral 8x7B
- Q2_Kで量子化していることもあってか、CodeLlamaの13Bよりは速度が出ていました。しかし、その分精度が落ちるため、実用には使用できないかなと感じました。
終わりに
現状ですと、やはり性能という点でOpenAIに劣ってしまいますが、想像以上に動くLLMであったので驚いています。
Mixtral 8x7Bの他にもBitnet 1.58Bのような新たな圧縮技術も出てきているため、今後さらにローカルで高性能なLLMが動くようになっていくと思います。
一人一つのLLM、誰もが自分だけの執事を持つ。そんな時代が来たら最高ですね。
参考