はじめに
Twitterやpixivなどでイラストを収集していると、キャラクターごとにフォルダ分けしたり、後から推しキャラが描かれているイラストを検索したくなりますよね?
でもイラストをダウンロードするたびにタグ付けするのも面倒だし、ましてや既に収集してある大量のイラストにタグ付けなんてもってのほか…。
ということで今回からは、描かれているキャラクターによって大量のイラストを自動的に分類してくれるツールを頑張って開発していきたいと思います。
ツール
(追記:2020.03.19)
こちらの記事で紹介したアプローチでイラストの分類を行うツールと学習済みモデルをGithubに公開しました。現状CUIツールしかありませんが、ご興味がある方は試してみてください。
アプローチ
分類なら適当にイラスト集めて分類器学習すればいいんじゃないの?と思いたくなりますが、以下のような問題点があります。
- 人によって分類対象のキャラクターは違う
- 分類対象のキャラクターは日々増えていく
- 新しい作品・キャラクターが生まれたり、推しキャラが増えたりしますよね。
こうした問題点を考慮すると、今回の目的を達成するためには学習時に未知なキャラクターに対しても分類を上手くやっていかなければならないことがわかります。
Person Re-Identification
私自身は専門ではないのですが、実は顔認証などの生体認証に応用されるようなPerson Re-Identificationと呼ばれるタスクも同じような課題を抱えているようです。それも当然で、世界の全人間に対してラベルを与えて分類器を学習するのは不可能なので、どうしても学習時には未知な人物に対しても認証が可能なような手法を作らなくてはならないわけです。
Person Re-Identificationについてはこちらの記事の冒頭で軽く解説されていますが、『複数の写真に写っている人物が同一かどうかを判断する』ようなタスクのようです。
今回は、このPerson Re-Identificationの技術を応用して、『複数のイラストに描かれているキャラクターが同一かどうか』を判断してくれるようなタスク(Character Re-Identification?)を解くことを目標とすることにします。
『描かれているキャラクターが同一かどうか』を判断するモデルさえ学習しておけば、仮に学習時に未知なキャラクターであっても、リファレンスとなる1枚のイラストを基に同一キャラのイラストをフォルダ分けしてくれそうですよね…?
実装/実験
手法
残念ながら私はPerson Re-Identificationの分野は素人なので、ひとまず決め打ちでベースラインとなりそうな以下の論文の手法を参考にしてみました。
Schroff, Florian, Dmitry Kalenichenko, and James Philbin. "Facenet: A unified embedding for face recognition and clustering." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
この手法では、各画像 $x$ をCNN $f(\cdot)$ に入力して高次元空間への埋め込み(embedding) $e=f(x)\in \mathbb{R}^d$ を計算します。
その後、同一人物(キャラクター)が描かれている2つの画像 $x^a, x^p$と、それ以外の人物(キャラクター)の画像$x^n$の三つ組(triplet) $(x^a, x^p, x^n)$ に対して、以下のtriplet lossを最小化することによって学習を行います(ここで$[\cdot]_+$は$\max(\cdot, 0)$の略です):
\big[||f(x^a)-f(x^p)||_2^2 - ||f(x^a)-f(x^p)||_2^2 + \alpha \big]_+
この損失は、同一人物が描かれている2つの画像 $x^a, x^p$ のembedding同士の距離が、異なる人物が描かれている2つの画像 $x^a, x^n$ のembedding同士の距離よりも $\alpha$ 以上近くさせようとするような損失になっています。
このような枠組みでの学習は metric learning と呼ばれる分野で研究されており、こちらの記事でわかりやすく解説されています。
データ
今回の学習のためにはキャラクターのラベルが付いたイラストのデータが必要となったため、pixivからイラストとタグのデータを収集しました。
(pixivのサーバーに負担をかけないようにかなり間を空けて収集したため、データの収集に数カ月かかってしまいました。)
ただしタグにはキャラクター名以外のものも多く存在するため、今回はピクシブ百科事典の要約文部分の文章を基にルールベースでキャラクター名に対応するタグをフィルタリングしました。
以上のデータを、キャラクターごとに3:1:1程度の割合でtrain, development, testに分けました。そのため、評価時には学習時に未知なキャラクターに対して同一かどうかの判定を行わなければならなくなります。
以下は今回利用したデータの統計情報です。(ただしpixivの全イラストから一様に収集したわけではないため、あくまで今回のデータの統計量であるにとどまります。)
| 値 | コメント | |
|---|---|---|
| イラスト数 | 175127 | |
| キャラクター数 | 6101 | 36000程度のキャラクターラベルのうち、今回収集したイラストで2回以上現れたものの個数 |
| 1キャラあたりの平均イラスト数 | 28.7 |
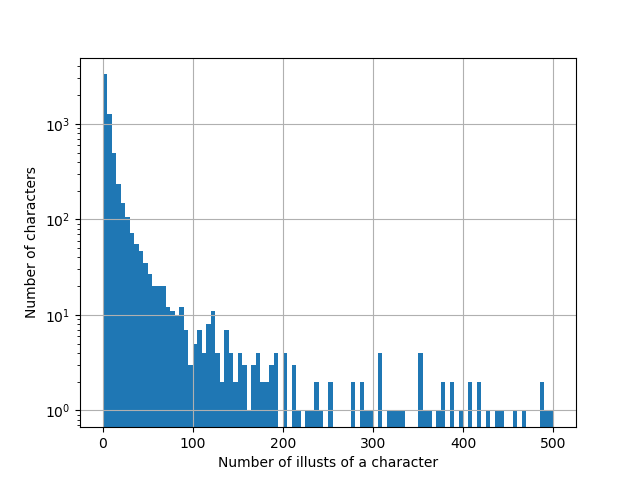
ある程度予想できたことですが、やはりキャラクターによってイラストの個数が大きく異なる結果となりました。以下は出現するイラストの枚数ごとのキャラクター数を表したヒストグラムです。グラフの範囲外ですが5600回以上出現したキャラクターもある一方、1832人のキャラクターは2回しか出現していないことから、かなり偏った分布であることがわかります。
実装
Pytorchを用いた学習コードをGithubのレポジトリで公開しています。
CNN
今回はImageNetで事前学習済みのResNet18を、embeddingを計算するモデルとして用いてfine-tuningしました。
前処理としてキャラクターが描かれている部分や、キャラクターの顔などを切り出したほうが良いのかもしれませんが、今回はベースラインということでイラスト全体をCNNに突っ込んでいます。
距離指標
上の論文ではembedding間のL2距離を用いていましたが、今回はembeddingをノルム1に正規化した上で内積を取ったものを距離として用いてtriplet lossを計算しました。
mini-batchに含める画像のサンプル
今回のような学習では、mini-batchに含まれる各人物ごとにその人物が写っている画像のペアを作らなければならないため、各人物に対して最低限の枚数の画像がmini-batchに含まれている必要があります。
そこで今回はSamplerを実装して、各mini-batchに1人のキャラクターごとに最大で10枚までの画像を、複数のキャラクターについて合計して全部で100枚程度になるまでサンプルし、さらに負例用として追加で全イラストから100枚ランダムにサンプルを追加するようにしました。(util.pyのMetricBatchSamplerに実装してあります。)
metric learning部分
Triplet lossなどのmetric learningに関する部分は、今後の発展を考えてpytorch-metric-learningライブラリを利用しました。Trainerなども実装されており、実装がすっきりするのでmetric learningを使う際にはおすすめです。
今回は利用しませんでしたが、学習を促進するためにtripletを選別するMinerも実装されており、さらに今回利用したTriplet Loss以外にも最新の手法で利用されているような損失も実装されています。
ハイパーパラメータ
今回の実験ではmomentum付きのSGD (momentum=0.9)を用いて最適化し、embeddingの次元は500、triplet lossのマージン$\alpha$は0.1としました。学習率とweight decayについては簡単なグリッドサーチを行い、それぞれ1e-3, 1e-6としました。
結果
評価指標
今回は評価指標としてEqual Error Rate (EER)を用いました。
EERとは、False Reject Rate (FRR)とFalse Acceptance Rate (FAR)が同一となるようなモデルのしきい値(同一キャラクターと判定するembedding間の最大距離)設定でのFRRもしくはFARの値です。
FRRはFalse Negative Rate (FNR)と等しく、FARは False Positive Rate (FPR)と等しいです。
結果
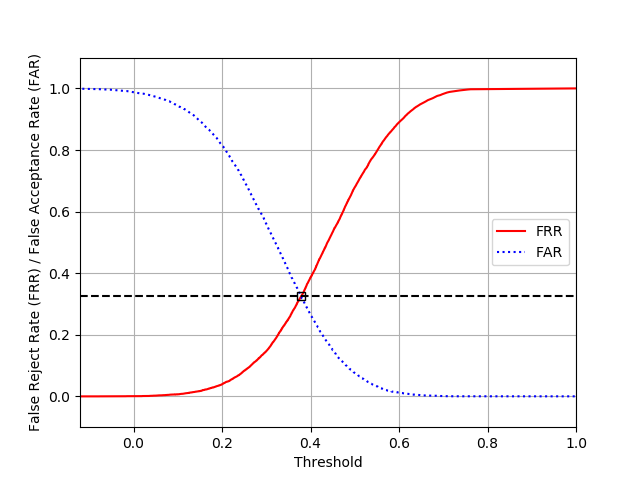
テストデータにおける2つの画像ペアについて、同一キャラクターが描かれているようなもの(正例)とそうでないもの(負例)をそれぞれ一様に10000個サンプルした際のFRR, FARのトレードオフは以下のようになりEERは32.4%となりました。
性能的には正直まだまだな気がしますが、今後Person Re-Identificationやmetric learningの最新の研究成果を反映することで改善していきたいと思います。
ちなみに上で述べたように今回のデータセットではキャラクターごとに出現回数が大きく異なる問題点がありました。その影響が無いかを確認するため、出現回数が多いキャラクターの画像ペアを正しく同一キャラだと判断できるかどうかも調べました。
結果的には、少なくともEERを見る限りはそこおまで大きな影響は無いようにに見えます。
| 出現回数 $N$ | EER |
|---|---|
| $2\le N<5$ | 29.2% |
| $5\le N < 10$ | 29.3% |
| $10\le N < 50$ | 29.0% |
| $50\le N$ | 32.1% |
さいごに
今回はキャラクター分類システム構築に向けて、Person Re-Identificationの手法をイラストデータに適用してみました。
モデルや学習法などまだまだ洗練しきれていないところがほとんどなので、今後勉強を進めつつ精度を改善していきたいと思います。