Optuna+LightGBMでハイパーパラメータを探しながらモデルを保存できたら便利だったので考えてみました。ふと思いついたのですが、
<「試行にUUID貼ればよくね?」
実際に試したらうまくいきました。見ていきましょう。
set_user_attrで試行ごとのUUIDを記録する
Optunaではtrial.set_user_attr()を使うことで、試行ごとにユーザーが設定した値を記録することができます。この値にはチューニングには使われません。
例えばここに訓練誤差やテスト誤差や、評価値とは別の評価尺度(F1スコアやAUC)を記録すれば後で参照することもできますし、UUIDを記録すれば試行を後で一意に識別することができます。そのUUIDをファイル名として、objectives()の中でモデルを保存すれば、ファイル名と対応できるというわけです。
UUIDはPython組み込みのUUIDモジュールで発生させることができます。UUIDv4は122ビット(5.32e+36)なのでまずハッシュの衝突は考えなくていいと思います。
>>> import uuid
>>> uuid.uuid4()
UUID('fac028b4-b632-44ef-b16a-18365d1788d5')
>>> uuid.uuid4()
UUID('a486dac3-0148-4537-b0cf-5f5019ffb7ea')
このようにランダムなUUIDは簡単に発生させることができます。
Optunaの中ではこのようします。objectivesの最初でUUIDを記録しておくといいですね。
def objectives(trial):
# 試行にUUIDを設定
trial_uuid = str(uuid.uuid4())
trial.set_user_attr("uuid", trial_uuid)
またLightGBMはモデルをPickleとして書き出すことで、モデルの保存/読み込みができます。書き出し方は普通のPickleと同じです。詳しくはLightGBMの公式Exampleにあります。
具体例
BrestCancerをLightGBMで分類してみました。結局Optuna公式のLightGBMの例とほとんど同じになってしまって、パラメーターの範囲はかなり参考にしました。ただ、UUIDを張ったり、モデルを保存したりするのは公式例では書かれていません。
import lightgbm as lgb
import optuna, os, uuid, pickle
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
def train_optuna():
data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(data["data"], data["target"], test_size=0.3, random_state=19)
def objectives(trial):
# 試行にUUIDを設定
trial_uuid = str(uuid.uuid4())
trial.set_user_attr("uuid", trial_uuid)
params = {
'boosting_type': trial.suggest_categorical('boosting', ['gbdt', 'dart', 'goss']),
'objective': 'binary',
'metric': {'binary', 'binary_error', 'auc'},
'num_leaves': trial.suggest_int("num_leaves", 10, 500),
'learning_rate': trial.suggest_loguniform("learning_rate", 1e-5, 1),
'feature_fraction': trial.suggest_uniform("feature_fraction", 0.0, 1.0),
'device' : 'gpu',
'verbose' : 0
}
if params['boosting_type'] == 'dart':
params['drop_rate'] = trial.suggest_loguniform('drop_rate', 1e-8, 1.0)
params['skip_drop'] = trial.suggest_loguniform('skip_drop', 1e-8, 1.0)
if params['boosting_type'] == 'goss':
params['top_rate'] = trial.suggest_uniform('top_rate', 0.0, 1.0)
params['other_rate'] = trial.suggest_uniform('other_rate', 0.0, 1.0 - params['top_rate'])
# 枝刈りありの訓練
pruning_callback = optuna.integration.LightGBMPruningCallback(trial, "binary_logloss") # 正式名で呼ばないとダメなので注意
gbm = lgb.train(params, lgb.Dataset(X_train, y_train), num_boost_round=500,
valid_sets=lgb.Dataset(X_test, y_test), callbacks=[pruning_callback])
# 訓練、テスト誤差
y_pred_train = np.rint(gbm.predict(X_train))
y_pred_test = np.rint(gbm.predict(X_test))
error_train = 1.0 - accuracy_score(y_train, y_pred_train)
error_test = 1.0 - accuracy_score(y_test, y_pred_test)
# エラー率の記録
trial.set_user_attr("train_error", error_train)
trial.set_user_attr("test_error", error_test)
# モデルの保存
if not os.path.exists("lgb_output"):
os.mkdir("lgb_output")
with open("lgb_output/"+f"{trial_uuid}.pkl", "wb") as fp:
pickle.dump(gbm, fp)
return error_test
study = optuna.create_study()
# SQLiteに記録する場合は、ディスクアクセスが遅いとボトルネックになることもある
#study = optuna.create_study(storage="sqlite:///brestcancer_lgb.db", study_name="brestcancer_lgb")
study.optimize(objectives, n_trials=100)
print(study.best_params)
print(study.best_value)
# best_paramsにはuser_attrは表示されないのでtrialから呼ぶ(dict形式で記録されている)
print(study.best_trial.user_attrs)
df = study.trials_dataframe()
df.to_csv("optuna_lgb.csv")
公式例では枝刈り(途中打ち切り)はありませんが、枝刈りを入れています。1つ注意点ですが、コールバックでの監視対象の値はLightGBMでのエイリアスが効かないということです。例えばLightGBMでは「binary」と指定すればbinary_loglossにエイリアスされていますが、コールバック側では「binary_logloss」という正式名称で呼ばないとエラーになります。ここだけ気をつけてください。
UUIDの他に、訓練エラー率とテストエラー率をset_user_attrで記録しています。これは後でCSVからも参照できます(UUIDも参照できます)。
また、完走したモデルはUUIDをファイル名として「lgb_output」フォルダ内に出力しています。打ち切られたモデルは保存されません。
またユーザー属性の値は、「study.best_value」に記録されないので、「study_best_trial」からuser_attrを呼び出します。Trialの中身はほぼ辞書なので、特に難しいことはありません。
最後の最も良かったパラメーター類の出力は次のようになります。
{'boosting': 'goss', 'num_leaves': 107, 'learning_rate': 0.2961954668933604, 'fature_fraction': 0.9083100627743023, top_rate': 0.3942673902625826, 'other_rat': 0.4163942043366362}
0.040935672514619936
{'uuid': '2989bc46-7263-44c1-9fe7-e9cd475a511f', 'train_error': 0.0, 'test_error': 0.040935672514619936}
UUIDと紐付いているので、どのファイルか特定することができます。またこれはうっかり画面を閉じちゃってもCSVやSQLite(SQLiteはそのはず)に記録されているので、後から確認することができます。
書き出した「optuna_lgb.csv」を見てみましょう。
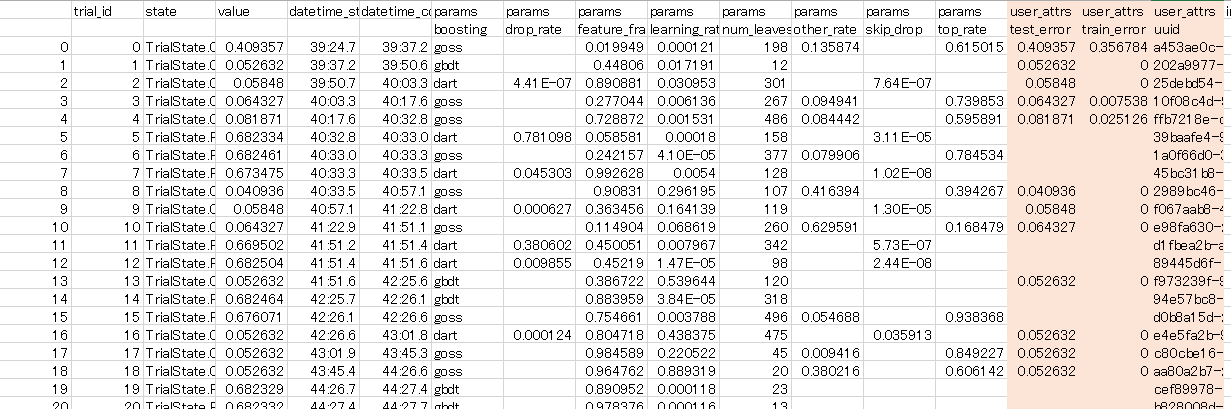
このようにユーザー属性で指定した「訓練エラー率、テストエラー率、UUID」が書き出されています(色で塗ったところです)。これで一目瞭然です。
ただ、SQLiteに書き出しながらやる場合では、今のバージョン(0.4.0)だと、ステップごとにDBにコミットしてるっぽくて、ディスクアクセスが遅いとボトルネックになることもあるかもしれません。自分の環境(HDD)ではそうなりました。ステップ単位ではなくて、試行単位でトランザクションを制御すると速くなるんじゃないかな(なんか副作用があるかもしれないのであくまで妄想)。インメモリで記録しておいて、任意のタイミングで永続化できるようになったら嬉しいですね。
モデルの復元
UUIDから最良のモデルを特定できたので、読み込んでみます。とても簡単です。
def load_model():
with open("lgb_output/2989bc46-7263-44c1-9fe7-e9cd475a511f.pkl", "rb") as fp:
gbm = pickle.load(fp)
data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(data["data"], data["target"], test_size=0.3, random_state=19)
y_pred = np.rint(gbm.predict(X_test))
print("Test Accuracy")
print(accuracy_score(y_test, y_pred))
Test Accuracy
0.9590643274853801
この通り。チューニング時の精度を完全に復元させることができました。勾配ブースティングは確定的な挙動をさせるのが難しいことがあるので、最良のハイパーパラメータをそのまま入れて再訓練したのでは、チューニング時の精度が出ないことがあります。そんなときにこの方法は便利で、チューニング時のモデルがそのまま復元できます。
まとめ
「trial.set_user_attr()でOptunaの試行とUUIDを紐付けると、保存したモデルを簡単に特定できて便利だよ」ということでした。完走したモデルは全部ファイルに残っているので、上位のモデルをいくつか取ってアンサンブル学習なんてこともできますね。Optunaすごすぎますね。