VAE(Variational Auto Encoder)は学習が簡単な生成モデルとして知られますが、解像度が大きな画像に対して出力画像がぼやけてしまうというデメリットがあります。この記事では、GoogLeNetやInception Networkで用いられる「Inceptionモジュール」を参考に、高解像度のモノクロ画像に対して、ぼやけにくいVAEを作ることに成功しました。arXivやGoogle Scholarで見ても特になかったので、おそらく世界初ではないかと思います(他にやった例があったら教えてください)。
コード(PyTorch)はこちらにあります。https://github.com/koshian2/inception-vae
Variational Auto Encoderについて

元の論文:Diederik P Kingma, Max Welling. "Auto-Encoding Variational Bayes"
まずはAuto Encoderについて。EncoderとDecoderという2つのネットワークを用意し、Encoderの入力画像とDecoderの出力画像が等しくなるように訓練するモデルです。今回はEncoderとDecoderのネットワークに画像認識でよく用いられるCNNを用います。EncoderがConv2dを中心とした構造になるのに対して、DecoderはConvTranspose2dを中心とした構造になります。
ただし、プレーンなAuto Encoderには潜在空間がスカスカになってしまうというデメリットがあるので、Variational Auto Encoder(VAE)ではEncoderの入力とDecoderの出力を等しくするのと同時に、潜在空間からサンプリングした変数をDecoderの入力に食わせたときの出力画像が、元の画像に対して尤もらしくなるようにするという制約を加えます。潜在空間とは漠然とした用語ですが、Encoderの入力がRGBのピクセル値であるのに対して、潜在空間は上の図で言えば「猫」という画像の意味を表す変数です。VAEでは計算を簡単にするために、潜在変数が標準正規分布に従うという仮定をおきます。
これは別の言い方をすれば、標準正規乱数から(例えば、np.random.randn)ランダムかつ連続的に画像を生成できるということを意味します。したがって、VAEは生成モデルの1つとして扱われます。
しかしこのVAE、同じ生成モデルで近年流行のGAN(Generative Advisory Networks)と比べるといまいち人気がありません。理由はいくつかありますが、一番大きいのはGANが上手く訓練できたときの(ここ重要!)の生成画像が本物レベルにそっくりだからだと思います。ただこのGANは学習がとても不安定で収束する保証がない、という大きなデメリットがあり、自分でDCGANをやったときもMNISTはできてもCIFARはうまくできませんでした。大抵GANの論文に出てくる鮮明な画像は上手く行ったときのをピックアップしていて、実際にGANを訓練させると相当大変なんですよね。
上手く行っている例は大抵似たような学習率を使っているという話は聞いたことあるのですが、「じゃあその学習率ってどこから出てきたの?通常のディープラーニングの学習率のように発散したら学習率を下げて…というようなシステマティックなパラメーター選択ってできるの?」というのが自分の大きな疑問です1。もしこういう理論が既に存在していたら、自分の不勉強なだけなので教えていただければ幸いです。
一方で、VAEは収束に関しては、通常のCNNと同様に学習率を選べばほぼ必ず収束するため、訓練の安定性というメリットがあります。しかし、その一方でVAEは出力画像がぼやけてしまう、最新鋭のGANと比べるとだいぶ(人間の目で見て一発でわかるほど)見劣りするというデメリットがあります。しかし、GANが実用面でまだまだ発展途上であることを考えると、現時点では学習が安定しているVAEはまだまだ捨てたものではないと個人的には思います。
以下では、Inceptionモジュールを用いてVAEのぼやけを改善し、高解像度の出力モデルを作ることにチャレンジしてみます。
Inceptionモジュール

オリジナルのInceptionモジュールはGoogLeNetで使われた畳み込みモジュールです。図はGoogLeNetの論文からのものです。いろいろなカーネルサイズの畳み込みを使っているのが特徴で、最初の1x1はパラメーター数や計算量を削減するための次元削減です(Incpetionに限らずResNetファミリーでよく見られます)。
このモジュールを生成モデルで使うことを考えましょう。プログラム的にはこれを移植するのは別に難しいことではないのですが、もう少し直感的な動機づけをしてみます。例えば、絵を描くときに線を引きますが、そこで使う線というのは1種類の太さのみを使わないですよね。複数の太さの線を使って、それらを重ね合わせて複雑な絵を描きますよね。先に限らずとも、デッサンなんかは漠然とした大きい部分から描き始めて、細かい部分は後で詰めていきますよね。なので、Inceptionのような複数のカーネルサイズを使うというのは、本質的に絵を描くときのプロセスにそぐうものだと自分は思います。
そこでVAEの実装時にはオリジナルのInceptionモジュールを少し変更してみます。

大きな変更点は**オリジナルのInceptionがフィルター結合(Concat)であるのに対して、ここでのInceptionは単純な加算(Add)**にしたこと。Res-NetファミリーでもDenseNetのようにConcat派と、オリジナルのResNetのようにAdd派があるので、ConcatをAddに変えるのは珍しいことではありません。また、絵を描くことへのアナロジーと照らし合わせると、最終的には結合よりも加算のほうが生成モデルとしては適切なのではないかなという理由付けです。
また、オリジナルのGoogLeNetでは、カーネルサイズ間でのチャンネルの割り振りの規則性がなく、これ自体が大きなハイパーパラメータ問題となっているので、以下のように簡略化しました。
- bottle-neckでは入力のチャンネル数の1/2になるように、1x1畳み込みを使って次元圧縮する
- モジュールの入力と出力のチャンネル数は一緒。bottle-neck→Convでは1/2に圧縮されたチャンネル数を元に戻す。
今、bottle-neck(BN)はBN→Convのように前のみ入れましたが、BN→Conv→BNのように畳み込みの前後を挟んでも良いと思います。後者の場合では、Convでのチャンネル数は1/2のままで、後ろのBNでチャンネル数を復元します。もしかすると、後者のほうがモデルの表現力は高いかもしれません。
データ
The Japanese Female Facial Expression (JAFFE) Databaseを使いました。10人の日本人女性の7種類の表情をともなったモノクロ画像のデータ・セットです。256x256のモノクロ画像が213枚あります。写真は九州大学で撮られたものだそうです。手軽なモノクロの高解像度のデータセットがなかなか見つからなかったのでこれはありがたかったです。
Data Reference
Michael J. Lyons, Shigeru Akemastu, Miyuki Kamachi, Jiro Gyoba.
Coding Facial Expressions with Gabor Wavelets, 3rd IEEE International Conference on Automatic Face and Gesture Recognition, pp. 200-205 (1998).
このようなデータです。

ネットワーク構成
以下のようなネットワーク構成をしました。
| ネットワーク | 名称 | Input shape | 出力ch | 処理 |
|---|---|---|---|---|
| エンコーダー | 導入 | (1, 256, 256) | 32 | 1x1 Conv |
| stage1 | (32, 256, 256) | 32 | Inception Encoder 1 | |
| downsampling1 | (32, 256, 256) | 64 | AvgPool (stride4) + 1x1 Conv | |
| stage2 | (64, 64, 64) | 64 | Inception Encoder 2 | |
| downsampling2 | (64, 64, 64) | 128 | AvgPool (stride4) + 1x1 Conv | |
| stage3 | (128, 16, 16) | 128 | Inception Encoder 3 | |
| downsampling3 | (128, 16, 16) | 256 | AvgPool (stride2) + 1x1 Conv | |
| stage4 | (256, 8, 8) | 256 | Inception Encoder 4 | |
| GAP | (256, ) | 256 | Global Average Pooling | |
| 中間層 | 平均μ | (256, ) | 64 | Linear |
| 対数分散σ | (256, ) | 64 | Linear | |
| デコーダー入力 | (64, ) | 256 | Linear | |
| デコーダー | 導入 | (256, ) | 256 | Upsampling : (256, ) -> (256, 8, 8) |
| stage1 | (256, 8, 8) | 256 | Inception Decoder 1 | |
| upsampling1 | (256, 8, 8) | 128 | ConvT(stride 2) + 1x1 ConvT | |
| stage2 | (128, 16, 16) | 128 | Inception Decoder 2 | |
| upsampling2 | (128, 16, 16) | 64 | ConvT(stride 4) + 1x1 ConvT | |
| stage3 | (64, 64, 64) | 64 | Inception Decoder 3 | |
| upsampling3 | (64, 64, 64) | 32 | ConvT(stride 4) + 1x1 ConvT | |
| stage4 | (32, 256, 256) | 32 | Inception Decoder 4 | |
| 出力 | (32, 256, 256) | 1 | 1x1 ConvT + sigmoid |
実験
Inceptionの有無で、出力画像を比較します。Incpetionなしの場合は、各モジュールをkernel_size=3のただのConv2d(デコーダーの場合はConvTrasnpose2d)に置き換えます。
また、ネットワークの表現力の調整のために、stageごとにモジュールを重ねる回数(# repeat)を導入します。この回数が大きいほど、パラメーター数が増えモデルは大きくなります。Inceptionの有無にかかわらず、エンコーダーのConv2dはConv2d→BatchNormalization→ReLUの順で、デコーダーのConvTranspose2dはConvTranspose2d→BatchNormalization→ReLUの順で処理させます。
Incpetionの有無と重ねる回数を、パラメーター数を基準に比較してみます。
| Name | Inception | # repeat | # params(M) | F/B pass size(MB) | batch_size |
|---|---|---|---|---|---|
| Normal-1 | No | 1 | 1.96 M | 227.07 | 32 |
| Normal-2 | No | 2 | 3.53 M | 337.32 | 32 |
| Normal-3 | No | 3 | 5.10 M | 447.57 | 32 |
| Normal-4 | No | 4 | 6.67 M | 557.82 | 32 |
| Normal-5 | No | 5 | 8.24 M | 668.07 | 32 |
| Normal-6 | No | 6 | 9.81 M | 778.32 | 32 |
| Normal-8 | No | 8 | 12.95 M | 998.82 | 16 |
| Normal-10 | No | 10 | 16.09 M | 1219.32 | 16 |
| Inception-1 | Yes | 1 | 5.95 M | 709.41 | 32 |
| Inception-2 | Yes | 2 | 11.51 M | 1302.00 | 16 |
F/B pass size(MB)はForward Backwardの計算時のメモリ使用量です。パラメーター数とともにpytorch-summaryというライブラリで計算しています。
パラメーター数の大きいモデルはGoogle ColabだとGPUメモリが溢れてしまうので、バッチサイズを32から16に変更しました。Inceptionは若干メモリ食いますね。7x7Convとか5x5poolとか外したり、bottle-neckをConvの後ろにもつけると少し改善されると思います。Inception-1のパラメーター数がNormal-3とNormal-4の間ぐらいというのを覚えておきましょう。
結果(エラー推移)
訓練誤差の推移をプロットしました。誤差はサンプル1枚あたりの誤差に変換しています。
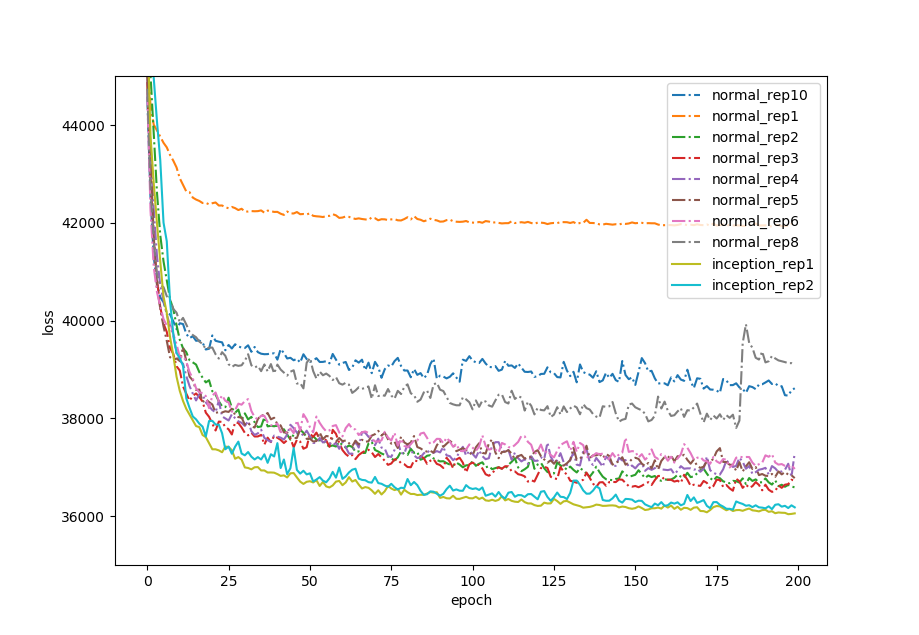
結果は、Inception圧勝。他のInceptionを使わないどのモデルよりもエラーが低くなりました。
個々に画像を見ていきます。
結果(出力)
出力画像は、入力画像をDecoderで復元したreconstruction、中間層に乱数を与えてランダムに生成したsamplingの2種類があります。recontructionのほうがsamplingよりもくっきりとした画像が出てくることが多いですが(入力画像と出力画像を等しくするように最適化しているからそれはそう)、VAEでランダムに顔画像を作ったといえるのはsamplingのほうです。
Reconstruction
Inceptionなし(Normal)

Normal01~02はネットワークの表現力不足ですね。Normal04~06あたりが一番見れる感じ。08と10はネットワークが深くなりすぎて、勾配消失問題が出てきて逆にぼやけてしまっているのだと思われます。
Inceptionあり
-
Inception-01 Reconstruction

-
Inception-02 Reconstruction

ほくろなどは消えてしまっていますが、どちらもかなり自然な画像が出てきました。Inception-01のほうより、Inception-02のほうが若干後ろの髪の細かい部分が自然なような感じがします。
Sampling
Inceptionなし(Normal)

Reconstructionよりぼやけ気味ですが、Normal-04~06あたりが一番見れそうですね。ただ髪がハゲ短くなりがち…?
Inceptionあり
Gif動画とpng画像を比較しても不公平なので、Normal-04~06とInception-01, 02のpngを全て貼り付けてみます。
-
Normal-04 Sampling

-
Normal-05 Sampling

-
Normal-06 Sampling

-
Inception-01 Sampling

-
Inception-02 Sampling

Inception-01は髪の毛の末端部分がかなりあやふやな部分が多いですが(モデルの表現力が少し足りない?)、Inception-02は一番自然なような見えます。Inceptionなしと比べて鮮明にサンプリングできています。これは拡大して詳しく見てみます。
拡大してみる
ReconstructionとSamplingについて2倍ズームしてみました。ズームの補間はNearest Neighbour法で統一しています。「Inception-01→Inception-02→Normal-04→Normal-05→Normal-06」の順で表示しています。
Reconstruction(拡大)

Inceptionが明らかに自然なように見えます。Normalはのっぺりさというかピンぼけが目立ちますね。
Sampling(拡大)

どのモデルでも顎のあたりの輪郭がボケてしまうのは仕方がないですが、Inception-02が一番まともに行っているのよう見えます。
まとめ
VAEは訓練の簡単さだけではなく、ディープラーニングを教師なし学習や、半教師学習、ベイズ統計と繋げられる理論的に優れたモデルであると思います。この記事を通じて「VAEもInceptionモジュールを使うと結構戦えるのではないか」ということを伝えられたら幸いです。
-
この点については2016年の記事ですが、「How to Train a GAN」というページにまとまっています(リンクは日本語訳)。質疑の中で「登壇者によるhackは有意義だが,これらhackを越えたtheoretical prospectを得るにはどうすればいいの?」という指摘があります。 http://yusuke-ujitoko.hatenablog.com/entry/2017/05/28/220351 ↩