こんにちは。2021年のディープラーニング論文を1人で読むAdvent Calendar1日目の記事です。今回紹介するのは、ICCV2021のWorkshopにアクセプトされた「Edge Flow」という論文です。研究メンバーは主にBaiduとニューヨーク大学です。
- タイトル:EdgeFlow: Achieving Practical Interactive Segmentation With Edge-Guided Flow
- URL:https://openaccess.thecvf.com/content/ICCV2021W/ILDAV/html/Hao_EdgeFlow_Achieving_Practical_Interactive_Segmentation_With_Edge-Guided_Flow_ICCVW_2021_paper.html
- 出典:Yuying Hao, Yi Liu, Zewu Wu, Lin Han, Yizhou Chen, Guowei Chen, Lutao Chu, Shiyu Tang, Zhiliang Yu, Zeyu Chen, Baohua Lai; Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, 2021, pp. 1551-1560
- コード:https://github.com/PaddlePaddle/PaddleSeg/tree/develop/EISeg

※プロジェクトページからの引用
セマンティックセグメンテーションはとても強力なディープラーニングの手法ですが、アノテーションコストがとても高いことがネックになっています。Edge Flowは数クリックするだけで教師データのマスクをいい感じに作ってくれるというものです。
もちろん数クリックなので、時間をかけて作ったマスクよりかは正確性が落ちますが、上の図を見ている限りだとかなり使い物になりそうですね。
この論文の良いところは、**EISeg**というを配布していて、すぐにアノテーションや切り抜きツールとして使えるところです。まずはこのツールを体験してみましょう。
EISegの導入
ダウンロード
EISeg(Efficient Interactive Segmentation)の配布ページに行きます
ReadMeが中国語で書かれていますが、「English」というリンクがあるので英語に切り替えます。英語が読めなければDeepL等使って読んでください。
「Installation」というところに、ダウンロード方法が書かれています。ダウンロード方法は、
- gitからのclone
- PIPからのインストール
- Windowsのバイナリ(exe)
自分はWindows環境なので、3番目の方法をしました。「Windows exe」と書かれているところにバイナリのリンクがあります。
このときは「EISeg0.3.0.1.7z」というファイルが落ちてきました。7zの解凍はWinRAR等でできます。
※Windowsのバイナリがいつの間にかなくなっていたので、PIPからインストールしました。PaddlePaddleのインストールが必要です。
ImportError: cannot import name '_registerMatType' from 'cv2.cv2' (c:\program files\python37\lib\site-packages\cv2\cv2.cp37-win_amd64.pyd)
というエラーは「opencv-python」のバージョンによるものなので、
pip uninstall opencv-python
pip install opencv-python
と再インストールすることで解決できます。
起動まで
解凍すると「Release」というフォルダが出てきます。「启动程序.exe」というファイルをクリックしましょう。
コマンドラインが出てきますが、初回起動時は必要なライブラリをインストールするので時間がかかります。インストールが終わるとGUIが立ち上がります。
中国語→英語化
デフォルトの言語設定は中国語ですが、設定をいじれば英語に変更できます。中国語よりかは英語のほうが使いやすいでしょう。
メニューの一番右の「幇助」→「氵吾 言」をクリックすると「English」と出てきて英語に変更できます。
ダイアログが表示されますが、「言語設定は再起動後に反映されます」的な意味なので一旦終了しましょう。
モデルの係数のダウンロード
訓練済みのモデルはデフォルトでは組み込まれておりません。これは実行時に必要になるので、プロジェクトページからダウンロードします。
「Model Preparation」に訓練済みモデルがあります。4種類モデルがありますが、「High Performance Model」の「Image annotation in generic scenarios」(hrnet18_ocr64_cocolvis)をダウンロードします。今回はこれで説明します。
スペックの低いPCならLightweight Modelでも良いです。人間のセグメンテーションを多くするなら「Annotation in portrait scenarios」でも良いでしょう。
訓練済みモデルの保存先はどこでもいいですが、今回はカレントディレクトリ直下に「weights」というフォルダを作って保存します。
モデルの読み込み
中国語→英語化後に再起動します。使用開始するにはモデルを読み込ませる必要があります。
右タブの「Model selction」から「High precision model」に切り替え、Load Model Parameterをクリックします。ファイル選択ダイアログが出てくるので、先程ダウンロードしweightsフォルダに保存した係数を読み込ませます。
EISegでマスクを作る
画像の読み込みとラベルの作成
アノテーションしたい画像を読み込みます。メニュー左の「File」から、
- Open Image:画像を1枚だけ読み込みます
- Open Dir:ディレクトリ内の画像をすべて読み込みます
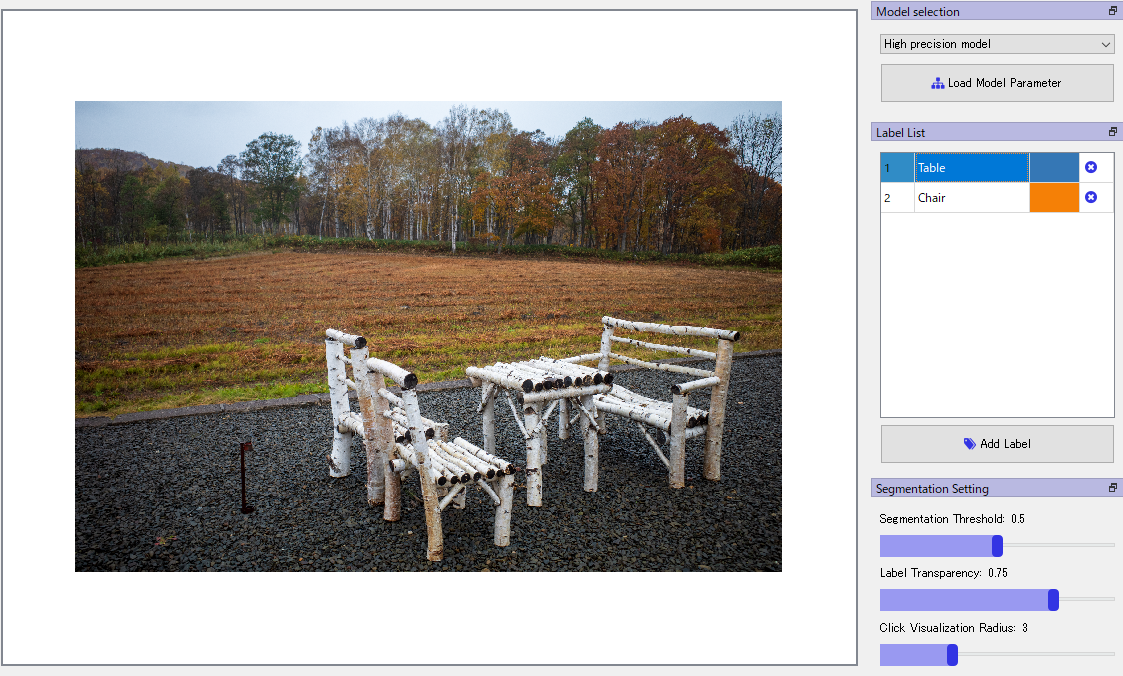
次にラベルのクラスを作ります。ラベルのクラスとは「人」「車」のような分類の種類のことです。次の画像1を例にとります。

今回椅子と机のマスクを作ってみましょう。「Label list」をクリックして、「Table」と「Chair」を追加します。
領域内は左クリック、領域外は右クリック
Label listから「Table」を選択し、テーブルのマスクを作っていきます。テーブル内をいくつか左クリックしていくと、だんだん領域が狭まっていくのがわかります。
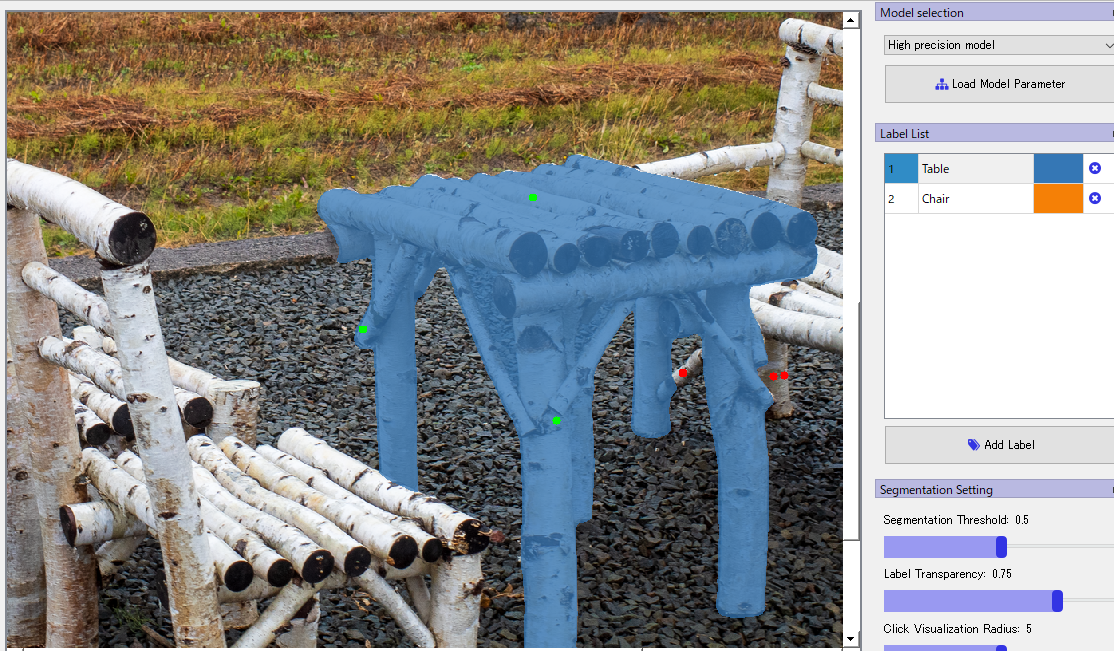
領域内は左クリック、領域外は右クリックしていきます。5~6回クリックするとほぼほぼ正解になっていますね。画像の拡大はCtrl押しながらマウスホイールです。
椅子のマスクを作る前に、スペースキーを押して現在のセグメントを確定させます。これをしないとLabel listを椅子に切り替えたときに、机も椅子として認識されてしまうからです。
確定するとセグメントがポリゴンで囲まれます。確定後も頂点を任意に動かすことができます。
次にLabel listから「Chair」に切り替え、同様にクリックしてマスキングしていきます。

このようにセマンティックセグメンテーションのマスクを簡単に作ることができました。
保存
左側の「Save」をクリックしましょう。保存先の選択が出てくるのでフォルダを指定すると、
- 背景
- 前景(foreground)
- ラベル(pseudo)
- JSON(coco.json)
が出てきます。前景とラベルは以下の通り。


セマンティックセグメンテーションをやらなくても、単なる透過切り抜きツールとしても使えそうです。これはディープラーニングをしない人でも便利ではないでしょうか。
ところでPhotoshopだと
この技術は不思議に思えますが、実はPhotoshopでも近い技術は使われています。例えば「オブジェクト選択ツール」ですね。

机と椅子のところで矩形選択するとそれっぽい領域が選択されます。しかし、椅子の隙間もセットで含んでいたりと精度があまり良くないです。切り抜きするにしても、ここから「選択とマスク」でちまちま削っていくのは大変です2。EISegが透過切り抜きツールとしても有用なのはこのあたりです。
Photoshopはセマンティックセグメンテーションを目的としたものではないので、アノテーションツールとしての使い勝手は遅れを取っても仕方ないと思います。
論文解説
EISegがとても強力というところを見た所で、背景技術として使われているEdge Flowの論文を見ていきましょう。以下の図は論文からの引用です。

この論文のキーはEISegで見たような、クリックベースのインタラクティブのセグメンテーションです。セマンティックセグメンテーションのアノテーションを1ドットずつやっていたら大変なので、このやり方はとても便利です。
ディープラーニングを使ったインタラクティブなセグメンテーションは、以前から研究されていましたが、最適化に時間がかかったり、後処理が必要だったり計算量の問題がありました。これを解決したのがEdge Flowの手法です。
モデル全図
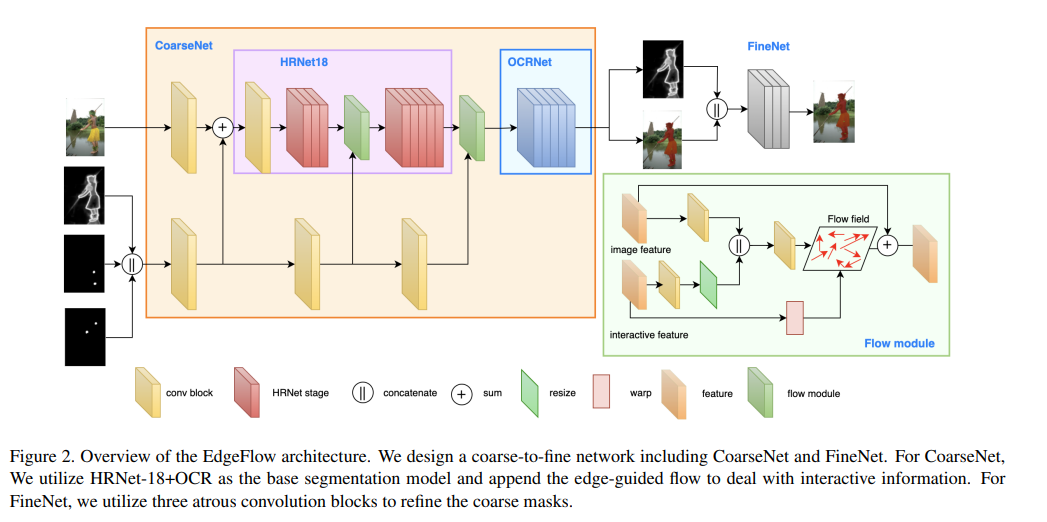
Coarse to Fineの二段構造になっています。Coarse Netで大まかなセグメントをして、Fine Netでより正確な出力を得るというよくある形です。
Coarse NetはHRNet18をバックボーンとし、OCRNetでセグメンテーションしています。Fine Netは軽量化された3つのAtrous Conv Blockからなります。クリックやエッジの情報が、Coarse Netで適宜挿入されている点が特徴です(Early-late fusion)。GANでありがちな形ですね。
クリック情報の扱い
領域内のクリック(EISegでは左クリック)をPositive、領域外のクリック(右クリック)をNegativeとします。Positive, Negativeのクリックはそれぞれ別々のチャンネルとして入力で与えられます。
クリックされた点は、半径5の円として0/1で塗りつぶして入力に与えられます。これをdisk mapやbinary disk mapと呼んでいます。この発想はこの論文からのものです。点間の距離を計算して与えると、より直接的にNNへ情報を伝えられますが、点が増えたときの安定性はdisk mapのほうが高いとのことです。
エッジ画像の扱い
この論文のタイトルの「Edge Flow」の通り、クリックするたびにエッジ画像を更新していくのがこのモデルの特徴です。
最初の状態では、エッジ画像は持っていません。ここからクリックしてセマンティックマップを計算し、そこからエッジ画像を作ります。このエッジ画像を再び入力に持っていき、クリック数の増加に合わせてエッジ画像をアップデートしていきます。このエッジの更新はより安定したアノテーションを可能にします。
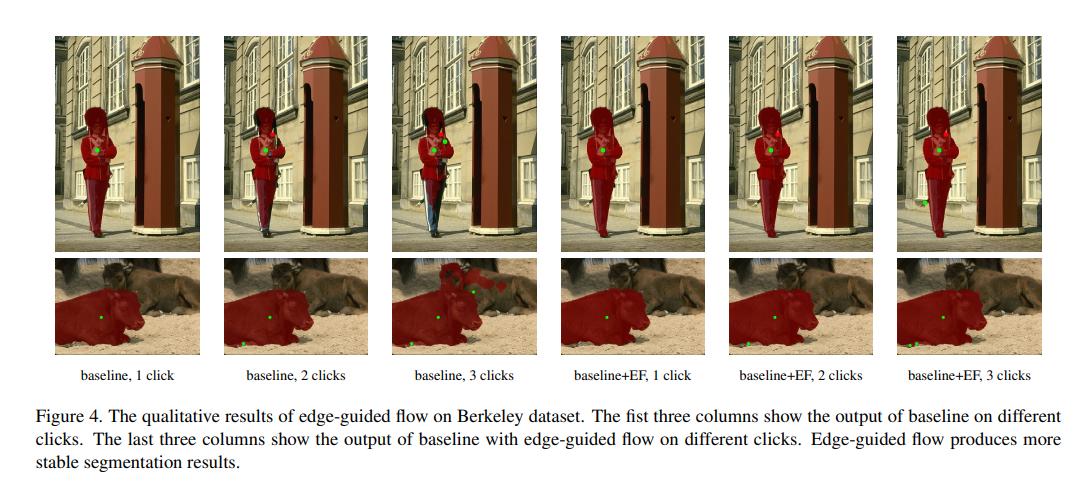
エッジによるガイドが効いているのがわかるのが上図です。下の動物(牛?)の例がわかりやすいのですが、baselineだと3クリックしても後ろの牛にかかっているのに対し、エッジガイドありだと後ろの牛にかかることがありません。上の人間の例でも、ガイドなしだとズボンの下の部分や帽子の紐がうまくマスクできていません。
「エッジではなく前回のマスク推論結果を入力として入れたらどうか?」という点は気になりますが、これだと局所解に陥る可能性があるそうです。その替わりにエッジを入力にいれつつ繰り返しアップデートするというスタイルを取っています。
また、エッジマスクと入力画像は特徴が異なるため、空間に大きなバイアスが生じるそうです。この解決法としてオプティカルフローlikeなモジュール(flow module)を導入しています。ここの実装が気になったのですが、詳細には書かれていませんでした。
損失関数
損失関数が面白いです。基本的にFocal lossなのですが、誤分類に重きをおいて正規化したFocal Lossです。

分母の部分は誤分類しているピクセルほど寄与度が大きくなります。クリック数が多くなって精度が上がってきても、誤分類を中心に分母にすれば勾配をちゃんと得られるよということでしょうか。
定量評価
この論文では「NoC@85、NoC@90」といった独特な評価指標が出てきます。NoCはNumber of Clicksの略で、「IoUが85や90になるまでのクリック回数」の意味です。少ないほうがいいです。
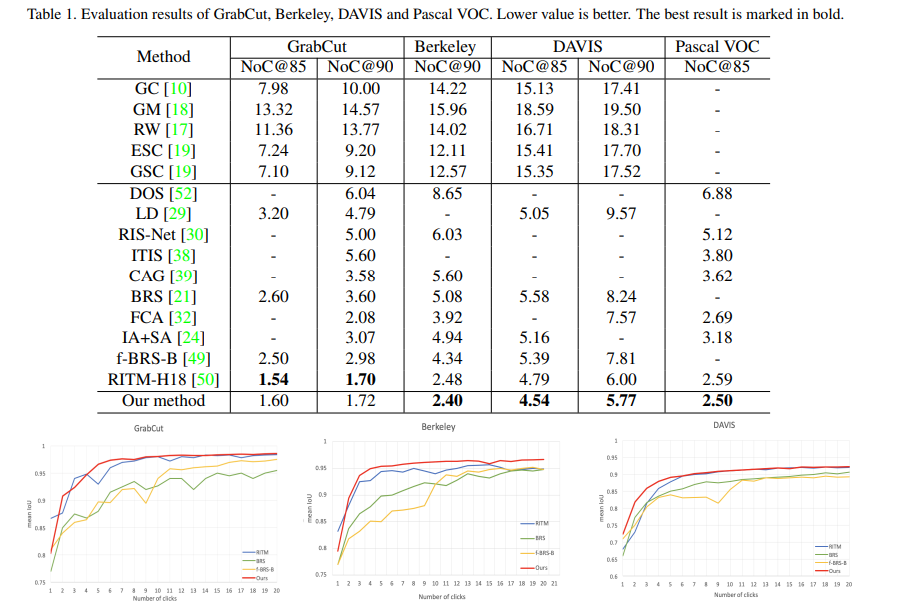
EISegで体験した通り、数回~多くても5・6回クリックすればIoU90のマスクはもう作れるようになっています。セマンティックセグメンテーションにとって画期的な話だと思います。
アノテーションツールまで用意してくれていて至れり尽くせりなので、ぜひ使ってみましょう。
まとめと感想
この記事では、どちらかというとEdge Flowの解説よりも「EISeg使おう」がメインになりましたが、アノテーションツールとしても、切り抜きツールとしても便利なのでぜひ使ってみてください。
「リモートセンシングに応用する」という使い方も論文にかかれていたので、機械学習外での活用も面白そうです。
告知
このアドベントカレンダーが本になりました!
https://koshian2.booth.pm/items/3595424
Amazonでも扱いあります詳しくは👉 https://shikoan.com