TensorFlowのいろいろな書き方「Keras API」「Custom train loop」「Custom layer」についてMNISTの例を解説します。また、TF2.0+KerasでColab TPUを使った訓練方法も解説していきます1。
TensorFlow2.0での書き方
TensorFlow2.0の書き方は何種類かあります。Kerasの作者によるColab Notebookによると、

縦軸に注目してください。上に行くほど高レベルAPI、下に行くほど低レベルAPIとなります。各項目が何を表すかと言うと、
-
Built in training/eval loops : Kerasの
fit()やevaluate()といった関数を使うものです。TF1.X時代のKerasとほぼ同じです。 -
Customized step-by-step loops : Kerasの
fit()などを使わずに、forループで訓練する方法。ただし、モデル定義はこれまでのKerasと同じ。 - Custom Layers : 2に加えて、モデルの定義をカスタムレイヤーでする方法。ざっくりというとTF2.0で追加されたPyTorchみたいな書き方。
- Training/eval loops from scratch : 従来の非KerasのTensorFlowの書き方(たぶん)。この記事では扱いません。
(図のトリックで、もしかしたらCustom layerは縦軸ではなく横軸なのかもしれません)
今回は1~3の方法でMNISTサンプルを書いてみました。自分が動かした限りでは、1~3までTF2.0で全てCPU/TPU(Colab TPU)で動くことを確認しました。TPUのサポートは2.0では試験的なのでケースによっては動かないことがあるかもしれません。
ただし、GPUサポートについては2019/10/16時点では、Nightlyバージョンが必要です。そのため、今回はCPUとTPUのみ書きます。以下がTF2.0時点でのサポート状況です。
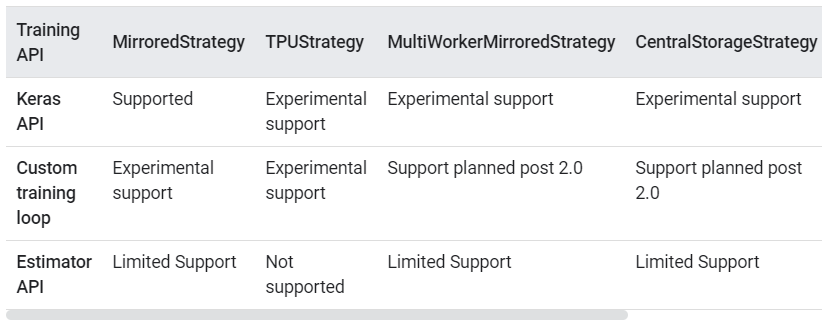
https://www.tensorflow.org/guide/distributed_trainingより
左から2番目の「TPUStrategy」がTPUの対応状況です。先程の4分類に対応させると、「Keras API=1,2、Custom training loop=2, 3、Estimator API=4」に対応すると思われます。つまり、この記事で紹介する1~3の書き方の、TF2.0でのTPUのサポート状況は「Experimental Support(実験段階)」ということになります。
ColabでのTFアップデート
2019/10/16時点では、ColabではTF1.X系がインストールされています。TF2.0を使うには、以下のようにアップデートします。
CPU/TPUの場合
!pip install tensorflow==2.0.0
import tensorflow as tf
tf.__version__ # '2.0.0'
TF2.X系がバージョンアップされたら値を変えましょう。
GPUの場合(TF2.0時点)
この方法は、TF2.Xが正式にGPUをサポートしたら不要です。
!pip install tf-nightly
import tensorflow as tf
tf.__version__ # '2.1.0-dev20191014'
詳しいインストール方法については以下のURLを参照してください。
https://www.tensorflow.org/install
CPUでのMNIST
(1) Builtin train loop
昔からのKerasの書き方です。KerasのMNISTの解説は腐るほどあるので省略します。
import tensorflow as tf
import tensorflow.keras.layers as layers
import numpy as np
def create_model():
inputs = layers.Input((784,))
x = layers.Dense(128, activation="relu")(inputs)
x = layers.Dense(64, activation="relu")(x)
x = layers.Dense(10, activation="softmax")(x)
return tf.keras.models.Model(inputs, x)
def main():
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
X_train = X_train.astype(np.float32).reshape(-1, 784) / 255.0
X_test = X_test.astype(np.float32).reshape(-1, 784) / 255.0
model = create_model()
loss = tf.keras.losses.SparseCategoricalCrossentropy()
acc = tf.keras.metrics.SparseCategoricalAccuracy()
optim = tf.keras.optimizers.Adam()
# train
model.compile(optimizer=optim, loss=loss, metrics=[acc])
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=5, batch_size=128)
# eval
val_loss, val_acc = model.evaluate(X_test, y_test, batch_size=128)
print(val_loss, val_acc)
if __name__ == "__main__":
main()
損失関数のSparseCategoricalCrossentropyはOnehotエンコーディングせずにクラスインデックスからダイレクトに計算するためのものです。
展開して出力を表示
Epoch 1/5
60000/60000 [==============================] - 3s 49us/sample - loss: 0.3381 - sparse_categorical_accuracy: 0.9050 - val_loss: 0.1744 - val_sparse_categorical_accuracy: 0.9506
Epoch 2/5
60000/60000 [==============================] - 2s 36us/sample - loss: 0.1335 - sparse_categorical_accuracy: 0.9609 - val_loss: 0.1132 - val_sparse_categorical_accuracy: 0.9653
Epoch 3/5
60000/60000 [==============================] - 2s 36us/sample - loss: 0.0912 - sparse_categorical_accuracy: 0.9724 - val_loss: 0.0877 - val_sparse_categorical_accuracy: 0.9726
Epoch 4/5
60000/60000 [==============================] - 2s 36us/sample - loss: 0.0683 - sparse_categorical_accuracy: 0.9794 - val_loss: 0.0829 - val_sparse_categorical_accuracy: 0.9742
Epoch 5/5
60000/60000 [==============================] - 2s 37us/sample - loss: 0.0532 - sparse_categorical_accuracy: 0.9841 - val_loss: 0.0791 - val_sparse_categorical_accuracy: 0.9734
10000/1 [==============================] - 0s 16us/sample - loss: 0.0431 - sparse_categorical_accuracy: 0.9734
0.07910709745511413 0.9734
(2) Custom train loop
ここからがTF2.0っぽい書き方です。訓練ループを書きます。
import tensorflow as tf
import tensorflow.keras.layers as layers
import numpy as np
def create_model():
inputs = layers.Input((784,))
x = layers.Dense(128, activation="relu")(inputs)
x = layers.Dense(64, activation="relu")(x)
x = layers.Dense(10, activation="softmax")(x)
return tf.keras.models.Model(inputs, x)
def main():
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
X_train = X_train.astype(np.float32).reshape(-1, 784) / 255.0
X_test = X_test.astype(np.float32).reshape(-1, 784) / 255.0
# tf.dataによるデータセットを作る(訓練データ)
trainset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
trainset = trainset.shuffle(buffer_size=1024).batch(128)
model = create_model()
loss = tf.keras.losses.SparseCategoricalCrossentropy()
acc = tf.keras.metrics.SparseCategoricalAccuracy()
optim = tf.keras.optimizers.Adam()
@tf.function # 高速化のためのデコレーター
def train_on_batch(X, y):
with tf.GradientTape() as tape:
pred = model(X, training=True)
loss_val = loss(y, pred)
# backward
graidents = tape.gradient(loss_val, model.trainable_weights)
# step optimizer
optim.apply_gradients(zip(graidents, model.trainable_weights))
# update accuracy
acc.update_state(y, pred) # 評価関数に結果を足していく
return loss_val
# train
for i in range(5):
acc.reset_states() # 評価関数の集積をリセット
print("Epoch =", i)
for step, (X, y) in enumerate(trainset):
loss_val = train_on_batch(X, y)
if step % 100 == 0:
print(f"Step = {step}, Loss = {loss_val}, Total Accuracy = {acc.result()}")
# テストデータ
testset = tf.data.Dataset.from_tensor_slices((X_test, y_test))
testset = testset.batch(128)
acc.reset_states()
for step, (X, y) in enumerate(testset):
pred = model(X, training=False)
acc.update_state(y, pred)
print("Final test accuracy : ", acc.result().numpy()) # acc自体はSparseCategoricalAccuracyなのでresult()を呼び出す
if __name__ == "__main__":
main()
展開して出力を表示
Epoch = 0
Step = 0, Loss = 2.349836826324463, Total Accuracy = 0.0703125
Step = 100, Loss = 0.49310579895973206, Total Accuracy = 0.8054609894752502
Step = 200, Loss = 0.21866394579410553, Total Accuracy = 0.8584810495376587
Step = 300, Loss = 0.2134859412908554, Total Accuracy = 0.8815147280693054
Step = 400, Loss = 0.1796931028366089, Total Accuracy = 0.8949306607246399
Epoch = 1
Step = 0, Loss = 0.16721254587173462, Total Accuracy = 0.9375
Step = 100, Loss = 0.14392973482608795, Total Accuracy = 0.9503403306007385
Step = 200, Loss = 0.10738439112901688, Total Accuracy = 0.9536691308021545
Step = 300, Loss = 0.1793646365404129, Total Accuracy = 0.9555647969245911
Step = 400, Loss = 0.12783676385879517, Total Accuracy = 0.9561837315559387
Epoch = 2
Step = 0, Loss = 0.15466900169849396, Total Accuracy = 0.9453125
Step = 100, Loss = 0.1323060840368271, Total Accuracy = 0.9697555899620056
Step = 200, Loss = 0.17651598155498505, Total Accuracy = 0.969916045665741
Step = 300, Loss = 0.06538371741771698, Total Accuracy = 0.9699958562850952
Step = 400, Loss = 0.14646577835083008, Total Accuracy = 0.9699773788452148
Epoch = 3
Step = 0, Loss = 0.05882181227207184, Total Accuracy = 0.9765625
Step = 100, Loss = 0.052190858870744705, Total Accuracy = 0.9755569100379944
Step = 200, Loss = 0.1526053547859192, Total Accuracy = 0.976057231426239
Step = 300, Loss = 0.042926862835884094, Total Accuracy = 0.9769777655601501
Step = 400, Loss = 0.08797476440668106, Total Accuracy = 0.9768547415733337
Epoch = 4
Step = 0, Loss = 0.10619714856147766, Total Accuracy = 0.984375
Step = 100, Loss = 0.042468976229429245, Total Accuracy = 0.9823638796806335
Step = 200, Loss = 0.103146992623806, Total Accuracy = 0.9823538661003113
Step = 300, Loss = 0.08124838024377823, Total Accuracy = 0.9826100468635559
Step = 400, Loss = 0.09324003756046295, Total Accuracy = 0.982309877872467
Final test accuracy : 0.9707
tf.data
モデル定義はKeras APIのままですが、まずデータセットの扱い方が違います。Kerasのfit()を使う場合はNumpy配列のままで良かったですが、訓練ループを書く場合や、Data Augmentationが複雑になってくる場合は(後述)tf.dataの形式の方が良いです。tf.image以下が充実しているので、前処理が簡単にかけます。
@tf.function
そして@tf.functionというデコレーターが大きな特徴です。このデコレーターをつけると静的グラフにコンパイルされるため、呼び出しが高速になります(逆につけないと遅い)。
何が起こっているのかは簡単な例で試してみるとわかりやすいです。デコレーターなしの場合:
def some_function(x):
y = x * 2
print(x)
print(y)
some_function(tf.ones(shape=(2,)))
# tf.Tensor([1. 1.], shape=(2,), dtype=float32)
# tf.Tensor([2. 2.], shape=(2,), dtype=float32)
テンソルの中身の値が表示され、デバックがやりやすくなったのがTF2.0の大きな特徴です。逆にデコレーターをつけてみると、
@tf.function
def some_function(x):
y = x * 2
print(x)
print(y)
some_function(tf.ones(shape=(2,)))
# Tensor("x:0", shape=(2,), dtype=float32)
# Tensor("mul:0", shape=(2,), dtype=float32)
従来のTensorFlowで見慣れた形になりました。デコレーターありの場合は、関数全体を1つの計算グラフとして見ているのだと思われます。
デコレーターなしでデバッグして、デコレーターありで訓練するのが良いでしょう。
tf.GradientTape
「スコープ以下を自動微分計算しなさい」という意味だと思います(ちょっと自信ない)。PyTorchのwith torch.no_grad()の逆バージョンみたいなものではないでしょうか。詳しくはこちらの記事参照。
次の行のtape.gradient()は偏微分の計算です。$\partial y/\partial x$という値を計算したければ、tape.gradient(y, x)でOKです。PyTorchだとloss.backward()に当たるでしょう。
その次のoptim.apply_gradients()は勾配降下法の反映です。PyTorchのoptim.step()と同じようなものだと思います。
Metricsのupdate_state(), reset_states()
精度のような評価指標に適用する関数です。reset_states()するまでの間累積して計算されます。過去の値との平均処理をいちいち書く必要がないのが便利ですね。TF1系のKerasのカスタム損失関数と同様に、update_state(y_true, y_pred)の順番になります(PyTorchと微妙に違う)。
(3) Custom layers
(2)のCustom train loopをベースにモデルの定義を変えます。
import tensorflow as tf
import tensorflow.keras.layers as layers
import numpy as np
class Model(tf.keras.layers.Layer):
def __init__(self):
super().__init__()
self.linear1 = layers.Dense(128, activation="relu")
self.linear2 = layers.Dense(64, activation="relu")
self.dropout = layers.Dropout(0.2)
self.linear3 = layers.Dense(10, activation="softmax")
def __call__(self, inputs, training=None):
x = self.linear1(inputs)
x = self.linear2(x)
x = self.dropout(x, training=training) # trainingモードの指定
x = self.linear3(x)
return x
def main():
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
X_train = X_train.astype(np.float32).reshape(-1, 784) / 255.0
X_test = X_test.astype(np.float32).reshape(-1, 784) / 255.0
# tf.dataによるデータセットを作る(訓練データ)
trainset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
trainset = trainset.shuffle(buffer_size=1024).batch(128)
model = Model()
loss = tf.keras.losses.SparseCategoricalCrossentropy()
acc = tf.keras.metrics.SparseCategoricalAccuracy()
optim = tf.keras.optimizers.Adam()
@tf.function # 高速化のためのデコレーター
def train_on_batch(X, y):
with tf.GradientTape() as tape:
pred = model(X, training=True) # Train mode
loss_val = loss(y, pred)
# backward
graidents = tape.gradient(loss_val, model.trainable_weights)
# step optimizer
optim.apply_gradients(zip(graidents, model.trainable_weights))
# update accuracy
acc.update_state(y, pred) # 評価関数に結果を足していく
return loss_val
# train
for i in range(5):
acc.reset_states() # 評価関数の集積をリセット
print("Epoch =", i)
for step, (X, y) in enumerate(trainset):
loss_val = train_on_batch(X, y)
if step % 100 == 0:
print(f"Step = {step}, Loss = {loss_val}, Total Accuracy = {acc.result()}")
# テストデータ
testset = tf.data.Dataset.from_tensor_slices((X_test, y_test))
testset = testset.batch(128)
acc.reset_states()
for step, (X, y) in enumerate(testset):
pred = model(X, training=False) # Eval mode
acc.update_state(y, pred)
print("Final test accuracy : ", acc.result().numpy()) # acc自体はSparseCategoricalAccuracyなのでresult()を呼び出す
if __name__ == "__main__":
main()
展開して出力を表示
Epoch = 0
Step = 0, Loss = 2.3099162578582764, Total Accuracy = 0.125
Step = 100, Loss = 0.4274976849555969, Total Accuracy = 0.7736695408821106
Step = 200, Loss = 0.41979914903640747, Total Accuracy = 0.833527684211731
Step = 300, Loss = 0.26905927062034607, Total Accuracy = 0.859504759311676
Step = 400, Loss = 0.20944154262542725, Total Accuracy = 0.8752142786979675
Epoch = 1
Step = 0, Loss = 0.17907443642616272, Total Accuracy = 0.953125
Step = 100, Loss = 0.329035222530365, Total Accuracy = 0.9433786869049072
Step = 200, Loss = 0.17258229851722717, Total Accuracy = 0.9469449520111084
Step = 300, Loss = 0.16210991144180298, Total Accuracy = 0.948530912399292
Step = 400, Loss = 0.12263013422489166, Total Accuracy = 0.9495207071304321
Epoch = 2
Step = 0, Loss = 0.17200025916099548, Total Accuracy = 0.9453125
Step = 100, Loss = 0.22431272268295288, Total Accuracy = 0.9627939462661743
Step = 200, Loss = 0.12039072811603546, Total Accuracy = 0.9633861780166626
Step = 300, Loss = 0.12257488071918488, Total Accuracy = 0.9636368155479431
Step = 400, Loss = 0.13071051239967346, Total Accuracy = 0.9635286927223206
Epoch = 3
Step = 0, Loss = 0.20443567633628845, Total Accuracy = 0.9453125
Step = 100, Loss = 0.09431470185518265, Total Accuracy = 0.971147894859314
Step = 200, Loss = 0.049680013209581375, Total Accuracy = 0.9719760417938232
Step = 300, Loss = 0.16454264521598816, Total Accuracy = 0.9716829061508179
Step = 400, Loss = 0.09620708227157593, Total Accuracy = 0.9718087315559387
Epoch = 4
Step = 0, Loss = 0.0800112634897232, Total Accuracy = 0.9765625
Step = 100, Loss = 0.09071961045265198, Total Accuracy = 0.9784963130950928
Step = 200, Loss = 0.049672070890665054, Total Accuracy = 0.9776896834373474
Step = 300, Loss = 0.06164955720305443, Total Accuracy = 0.9772113561630249
Step = 400, Loss = 0.055377036333084106, Total Accuracy = 0.9768157601356506
Final test accuracy : 0.9732
変更点はモデルです。tf.keras.models.Model(...)ではなくtf.keras.layers.Layerを継承した1つのモデルとして定義しています。カスタムレイヤーの書き方はPyTorchやChainerでおなじみの書き方です。TF1.X系のDefine and runの形式よりかは、forwardの中でif文使えたりとモデルの発展性が上がりました。
注意点は、DropoutやBatchNormのようにTrainとTest時に挙動が違うものは明示する必要があります。ご注意ください。PyTorchのようなtrain()やeval()関数をカスタムレイヤーに用意して、訓練モードをメンバ変数で切り替えるといいかもしれません。
tf.dataによるData Augmentation
一旦休憩。TF1.XのKerasではImageDataGeneratorを使ってData Augmentationをすることが一般的でした。しかし、TPUの利用を考えるとImageDataGeneratorではなくtf.dataでData Augmentationした方がいいかもしれません。
TF1.14以降ImageDataGeneratorはTPU非対応になり、10/16現在のTF2.0でも対応されていません。ただし、tf.dataで書くとTF2.0+TPUでもData Augmentationしながら動かすことができます。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# Data augmentation
def data_augmentation(image):
x = tf.cast(image, tf.float32) / 255.0 # uint8 -> float32
x = tf.image.random_flip_left_right(x) # horizontal flip
x = tf.pad(x, tf.constant([[2, 2], [2, 2], [0, 0]]), "REFLECT") # pad 2 (outsize:36x36)
# 黒い領域を作らないようにReflect padとしている(KerasのImageDataGeneratorと同じ)
x = tf.image.random_crop(x, size=[32, 32, 3]) # random crop (outsize:32xx32)
return x
def main():
# Numpy配列のロード
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.cifar10.load_data()
# Dataset + augmentation
trainset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
trainset = trainset.map(
lambda image, label: (data_augmentation(image), label) # mapで画像とラベルの分解をし、画像側だけにAugmentationをかける
).batch(64)
# Augmentationの結果の可視化
X, y = next(iter(trainset)) # 1バッチだけ呼び出し
X = X.numpy() # Tensor -> Numpy array
print(X.shape) # (64,32,32,3)
for i in range(X.shape[0]):
ax = plt.subplot(8, 8, i + 1)
ax.imshow(X[i])
ax.axis("off")
plt.show()
if __name__ == "__main__":
main()
1バッチ分可視化すると次のようになります。

ポイントをかいつまんで説明していきます。
基本的な使い方:(画像, ラベル)→map関数
データセットを定義すると、「画像、ラベル」という2つのフローができることが多いです(この例ではtf.data.Dataset.from_tensor_slicesという関数を使っています)。Data Augmentationはかなりが画像だけで完結するので(Mixupなど例外はありますが)、Augmentation全体のフローを1つの関数で定義し、引数に画像を与えるのがわかりやすいでしょう。
# Data augmentation
def data_augmentation(image):
x = tf.cast(image, tf.float32) / 255.0 # uint8 -> float32
x = tf.image.random_flip_left_right(x) # horizontal flip
x = tf.pad(x, tf.constant([[2, 2], [2, 2], [0, 0]]), "REFLECT") # pad 2 (outsize:36x36)
# 黒い領域を作らないようにReflect padとしている(KerasのImageDataGeneratorと同じ)
x = tf.image.random_crop(x, size=[32, 32, 3]) # random crop (outsize:32xx32)
return x
imageをuint8のテンソルとします。これを、
- float32にキャスト→255で割って0-1に変換
- ランダムに左右反転
- Random Cropでサイズが縮んでしまうため、先にPaddingを入れる。ここではReflect paddingとしている。縦横に左右2pxずつ(最後の0はチャンネル方向だが指定しないとエラーになる)。解像度は36x36となる。
- 32x32のサイズになるように、ランダムでクロップ
というAugmentationです。そしてこの関数をどう使うのかというと、
trainset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
trainset = trainset.map(
lambda image, label: (data_augmentation(image), label) # mapで画像とラベルの分解をし、画像側だけにAugmentationをかける
).batch(64)
trainsetに対してmapで画像とラベルを分離し、画像だけにAugmentationをかければOKです。これを可視化すると先程の図の通りになります。
TPUでの訓練
本題に戻ります。先程のMNISTの例をTPUで訓練してみましょう。
TPU下準備(共通)
ColabでTPUを利用する前に必要なコード(おまじない)です。TFのバージョンの度に変わっていますがTF2.0では以下の通りです。
import tensorflow as tf
import tensorflow.keras.layers as layers
import numpy as np
import os
# tpu用
# 詳細 https://www.tensorflow.org/guide/distributed_training#tpustrategy
tpu_grpc_url = "grpc://" + os.environ["COLAB_TPU_ADDR"]
tpu_cluster_resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu_grpc_url)
tf.config.experimental_connect_to_cluster(tpu_cluster_resolver) # TF2.0の場合、ここを追加
tf.tpu.experimental.initialize_tpu_system(tpu_cluster_resolver) # TF2.0の場合、今後experimentialが取れる可能性がある
strategy = tf.distribute.experimental.TPUStrategy(tpu_cluster_resolver) # ここも同様
詳細については割愛しますが、TF2.0の時点ではあくまで「Experimental Support」なので、今後experimentalなどが外れることがあります。これをJupyterの1つのセルにおいて実行しておきましょう。
以下、CPUのコードと整合性を取るためにスクリプトでの実行ベースで書いてあるため、Jupyerではいらないif __name__ == "__main__"などが入っていますが、適宜置き換えて読んでください。
(1) Builtin train loop with TPU
TF2.0でのKerasのfit()を使ったTPUの例です。
def create_model():
inputs = layers.Input((784,))
x = layers.Dense(128, activation="relu")(inputs)
x = layers.Dense(64, activation="relu")(x)
x = layers.Dense(10, activation="softmax")(x)
return tf.keras.models.Model(inputs, x)
def main():
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
X_train = X_train.astype(np.float32).reshape(-1, 784) / 255.0
X_test = X_test.astype(np.float32).reshape(-1, 784) / 255.0
y_train, y_test = y_train.astype(np.float32), y_test.astype(np.float32) # uint8のままだとエラー起こすのでfloatに変えたほうが良い
with strategy.scope():
model = create_model()
loss = tf.keras.losses.SparseCategoricalCrossentropy()
acc = tf.keras.metrics.SparseCategoricalAccuracy()
optim = tf.keras.optimizers.Adam()
# train
model.compile(optimizer=optim, loss=loss, metrics=[acc])
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=5, batch_size=128,
steps_per_epoch=X_train.shape[0] // 128, validation_steps=X_test.shape[0] // 128)
# numpyの場合:ValueError: The number of samples 60000 is not divisible by batch size 128.と怒られるのでstepを指定
# eval
val_loss, val_acc = model.evaluate(X_test, y_test, batch_size=128)
print(val_loss, val_acc)
if __name__ == "__main__":
main()
展開して出力を表示
Train on 468 steps, validate on 78 steps
Epoch 1/5
468/468 [==============================] - 13s 27ms/step - loss: 0.3358 - sparse_categorical_accuracy: 0.9076 - val_loss: 0.1693 - val_sparse_categorical_accuracy: 0.9492
Epoch 2/5
468/468 [==============================] - 6s 14ms/step - loss: 0.1393 - sparse_categorical_accuracy: 0.9590 - val_loss: 0.1258 - val_sparse_categorical_accuracy: 0.9605
Epoch 3/5
468/468 [==============================] - 6s 13ms/step - loss: 0.0960 - sparse_categorical_accuracy: 0.9714 - val_loss: 0.1097 - val_sparse_categorical_accuracy: 0.9641
Epoch 4/5
468/468 [==============================] - 6s 14ms/step - loss: 0.0709 - sparse_categorical_accuracy: 0.9789 - val_loss: 0.0977 - val_sparse_categorical_accuracy: 0.9700
Epoch 5/5
468/468 [==============================] - 6s 14ms/step - loss: 0.0543 - sparse_categorical_accuracy: 0.9836 - val_loss: 0.0864 - val_sparse_categorical_accuracy: 0.9723
79/79 [==============================] - 2s 26ms/step - loss: 0.0854 - sparse_categorical_accuracy: 0.9723
0.08541072898727099 0.9723
CPUと違う点は以下の通りです。
- Numpyのuint8配列をそのまま食わせるとうまくいかない。ラベルもfloat32にキャストするとうまくいく。
-
TPUStrategyで
with strategy.scope():と訓練コードを囲む(重要)。これは分散訓練をするためのもので、複数GPUでも同様のスコープは行う。 - tf.dataを使わずにNumpy配列で
fit()する場合は、steps_per_epochやvalidation_stepsを指定する
この書き方はTF1.XのKeras+TPUとほとんど変わらないのでおすすめです(データ部分をtf.dataに置き換えてもいいかもしれない)。訓練ループを書く場合はもう少しコードが長くなります。
(2) Custom train loop with TPU
下準備のおまじないは済ませた上でのコードです。
def create_model():
inputs = layers.Input((784,))
x = layers.Dense(128, activation="relu")(inputs)
x = layers.Dense(64, activation="relu")(x)
x = layers.Dense(10, activation="softmax")(x)
return tf.keras.models.Model(inputs, x)
def main():
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
X_train = X_train.astype(np.float32).reshape(-1, 784) / 255.0
X_test = X_test.astype(np.float32).reshape(-1, 784) / 255.0
y_train, y_test = y_train.astype(np.float32), y_test.astype(np.float32) # uint8のままだとエラー起こすのでfloatに変えたほうが良い
# tf.dataによるデータセットを作る(訓練データ)
trainset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
trainset = trainset.shuffle(buffer_size=1024).batch(128)
# テストデータ
testset = tf.data.Dataset.from_tensor_slices((X_test, y_test))
testset = testset.batch(128)
with strategy.scope():
model = create_model()
# training loopを書く場合はreductionを追加
# https://www.tensorflow.org/tutorials/distribute/custom_training
loss = tf.keras.losses.SparseCategoricalCrossentropy(reduction=tf.keras.losses.Reduction.NONE)
acc = tf.keras.metrics.SparseCategoricalAccuracy()
optim = tf.keras.optimizers.Adam()
trainset = strategy.experimental_distribute_dataset(trainset)
testset = strategy.experimental_distribute_dataset(testset)
def train_on_batch(X, y):
with tf.GradientTape() as tape:
pred = model(X, training=True)
per_sample_loss = loss(y, pred)
loss_val = tf.reduce_sum(per_sample_loss, keepdims=True) * (1. / 128.0) # 要注意
# backward
graidents = tape.gradient(loss_val, model.trainable_weights)
# step optimizer
optim.apply_gradients(zip(graidents, model.trainable_weights))
# update accuracy
acc.update_state(y, pred) # 評価関数に結果を足していく
return loss_val
# distribute training用のラップを作る
@tf.function
def distributed_train_on_batch(X, y):
per_replica_losses = strategy.experimental_run_v2(train_on_batch, args=(X, y))
return strategy.reduce(tf.distribute.ReduceOp.SUM, per_replica_losses, axis=None) # lossのreduceをなくした分ここでreduceする
def test_on_batch(X, y):
pred = model(X, training=False)
acc.update_state(y, pred)
@tf.function
def distributed_test_on_batch(X, y):
return strategy.experimental_run_v2(test_on_batch, args=(X, y))
# train
for i in range(5):
acc.reset_states() # 評価関数の集積をリセット
print("Epoch =", i)
for step, (X, y) in enumerate(trainset):
loss_val = distributed_train_on_batch(X, y)
if step % 100 == 0:
print(f"Step = {step}, Loss = {loss_val}, Total Accuracy = {acc.result()}")
acc.reset_states()
for step, (X, y) in enumerate(testset):
distributed_test_on_batch(X, y)
print("Final test accuracy : ", acc.result().numpy()) # acc自体はSparseCategoricalAccuracyなのでresult()を呼び出す
if __name__ == "__main__":
main()
展開して出力を表示
Epoch = 0
Step = 0, Loss = 2.334045886993408, Total Accuracy = 0.109375
Step = 100, Loss = 0.4330994486808777, Total Accuracy = 0.8118038177490234
Step = 200, Loss = 0.33422940969467163, Total Accuracy = 0.8623290061950684
Step = 300, Loss = 0.36165785789489746, Total Accuracy = 0.8843438625335693
Step = 400, Loss = 0.15515992045402527, Total Accuracy = 0.8975023627281189
Epoch = 1
Step = 0, Loss = 0.23134846985340118, Total Accuracy = 0.9453125
Step = 100, Loss = 0.11427933722734451, Total Accuracy = 0.9532023668289185
Step = 200, Loss = 0.170352041721344, Total Accuracy = 0.9541744589805603
Step = 300, Loss = 0.14540918171405792, Total Accuracy = 0.9554609656333923
Step = 400, Loss = 0.13882485032081604, Total Accuracy = 0.9560084342956543
Epoch = 2
Step = 0, Loss = 0.16898515820503235, Total Accuracy = 0.9296875
Step = 100, Loss = 0.09195484220981598, Total Accuracy = 0.9680538177490234
Step = 200, Loss = 0.08695673197507858, Total Accuracy = 0.9696828126907349
Step = 300, Loss = 0.11648894846439362, Total Accuracy = 0.969554603099823
Step = 400, Loss = 0.10399648547172546, Total Accuracy = 0.9692955017089844
Epoch = 3
Step = 0, Loss = 0.08930248767137527, Total Accuracy = 0.96875
Step = 100, Loss = 0.04020076245069504, Total Accuracy = 0.9767945408821106
Step = 200, Loss = 0.1336292028427124, Total Accuracy = 0.9766790866851807
Step = 300, Loss = 0.04366832599043846, Total Accuracy = 0.9767701625823975
Step = 400, Loss = 0.10038425773382187, Total Accuracy = 0.9765235185623169
Epoch = 4
Step = 0, Loss = 0.081525057554245, Total Accuracy = 0.96875
Step = 100, Loss = 0.06433926522731781, Total Accuracy = 0.9826732873916626
Step = 200, Loss = 0.09129377454519272, Total Accuracy = 0.9830146431922913
Step = 300, Loss = 0.07375292479991913, Total Accuracy = 0.9827138781547546
Step = 400, Loss = 0.02634371444582939, Total Accuracy = 0.9822903871536255
Final test accuracy : 0.9715
(1)のBuilt in train loop with TPUよりもさらに付け足す点があります。fit()の場合はTPU間の分散(Distribution)訓練をいい感じにやってくれましたが、訓練ループを自分で書く場合はmap→reduce(特にreduce)をそれぞれ配慮する必要があります。詳細は以下の記事を参照してください。
Distributed training with TensorFlow
https://www.tensorflow.org/guide/distributed_training
tf.dataをdistribute_datasetに変える
Map-ReduceのMap部分ですね。Mapをいい感じにやってくれる分散訓練対応のtf.dataのデータセットに変換しましょう。
trainset = strategy.experimental_distribute_dataset(trainset)
ただし、このコードはTPUがTF2.0時点でExperimental Supportであるためで、正式実装になったときはコードが少し変わると思われます。
要注意:この変換を行わなくても、TF2.0では訓練が通ってしまいます。しかし、未変換の場合はバッチをデバイス間で分割せず、すべてのサンプルを全デバイスにコピーしてしまうので、あたかもデバイス数だけ(Colab TPUの場合は8倍)学習率が大きくしたような挙動をします。通常これは精度を下げます。この変換を怠ると、ここの部分をいい感じにやってくれるfit()とカスタムループの場合で、精度で1~2%のギャップを生むおそれがあります。
損失関数のreductionを指定
Reduce部分の対応です。最終的には、例えばtrain_on_batchという関数があったとして、それを分散訓練対応の関数(この例では、distributed_train_on_batchという関数)でラップします。Reduceはラップ側で行うため、損失関数でのReduceは不要となります。これは損失関数を、
loss = tf.keras.losses.SparseCategoricalCrossentropy(reduction=tf.keras.losses.Reduction.NONE)
とします(SUMでもOK)。ちなみにreduction以下を指定しないと、
ValueError: Please use `tf.keras.losses.Reduction.SUM` or `tf.keras.losses.Reduction.NONE` for loss reduction when losses are used with `tf.distribute.Strategy` outside of the built-in training loops. You can implement `tf.keras.losses.Reduction.SUM_OVER_BATCH_SIZE` using global batch size like:
```
with strategy.scope():
loss_obj = tf.keras.losses.CategoricalCrossentropy(reduction=tf.keras.losses.reduction.NONE)
....
loss = tf.reduce_sum(loss_obj(labels, predictions)) * (1. / global_batch_size)
```
Please see https://www.tensorflow.org/alpha/tutorials/distribute/training_loops for more details.
と怒られます。
また、損失関数をreduction=tf.keras.losses.Reduction.NONEとしたときは、train_on_batch側での損失計算でReduceします。
per_sample_loss = loss(y, pred)
loss_val = tf.reduce_sum(per_sample_loss, keepdims=True) * (1. / 128.0) # 要注意
取らないケースだと学習率があからさまに高くなってしまい(今後変わるかもしれません)、fit()でうまくロスが下がったケースでも、損失値が発散してしまいました。この症状は平均を取ると解消されます(ただしkeepdims=Trueを入れないとエラーになる)。
しかし、ここで罠なのは、「平均ならtf.reduce_meanですればいいじゃない?」と思ってしまうことです。ただしこれは推奨されません(公式ドキュメントに書いてある)。より正確には、サンプル単位の損失の和を取りグローバルなバッチサイズ(デバイス間の合計)で割るべきです。なぜなら、バッチサイズの端数がきたときに、学習率が大きくなってしまい、端数分の勾配が異様に大きく反映されてしまうからです。これは和をグローバルなバッチサイズで割れば発生しません。
訓練、テストの関数を分散訓練対応
訓練ループのtrain_on_batchやtest_on_batchを分散訓練対応させます。trainの場合、
# distribute training用のラップを作る
@tf.function
def distributed_train_on_batch(X, y):
per_replica_losses = strategy.experimental_run_v2(train_on_batch, args=(X, y))
return strategy.reduce(tf.distribute.ReduceOp.MEAN, per_replica_losses, axis=0) # lossのreduceをなくした分ここでreduceする
とします(一例)。今後のTPUが正式実装となったTFのバージョンでは、experimental部分が変更になる可能性があります。
1行目はtrain_on_batchという関数に対して、(X, y)をフィードさせなさい。returnの部分は、個々のデバイスで計算されたロスをまとめなさいという意味です。testの場合は、
@tf.function
def distributed_test_on_batch(X, y):
return strategy.experimental_run_v2(test_on_batch, args=(X, y))
ただ精度のMetricをアップデートしたいときはこれでOKです。
(3) Custom layers with TPU
最後にPyTorchみたいな書き方のモデル+TPUでの訓練です。これもできます。strategyの準備は終えた上で、
class Model(tf.keras.layers.Layer):
def __init__(self):
super().__init__()
self.linear1 = layers.Dense(128, activation="relu")
self.linear2 = layers.Dense(64, activation="relu")
self.dropout = layers.Dropout(0.2)
self.linear3 = layers.Dense(10, activation="softmax")
def __call__(self, inputs, training=None):
x = self.linear1(inputs)
x = self.linear2(x)
x = self.dropout(x)
x = self.linear3(x)
return x
def main():
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
X_train = X_train.astype(np.float32).reshape(-1, 784) / 255.0
X_test = X_test.astype(np.float32).reshape(-1, 784) / 255.0
y_train, y_test = y_train.astype(np.float32), y_test.astype(np.float32) # uint8のままだとエラー起こすのでfloatに変えたほうが良い
# tf.dataによるデータセットを作る(訓練データ)
trainset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
trainset = trainset.shuffle(buffer_size=1024).batch(128)
# テストデータ
testset = tf.data.Dataset.from_tensor_slices((X_test, y_test))
testset = testset.batch(128)
with strategy.scope():
model = Model()
# training loopを書く場合はreductionを追加
# https://www.tensorflow.org/tutorials/distribute/custom_training
loss = tf.keras.losses.SparseCategoricalCrossentropy(reduction=tf.keras.losses.Reduction.NONE)
acc = tf.keras.metrics.SparseCategoricalAccuracy()
optim = tf.keras.optimizers.Adam()
trainset = strategy.experimental_distribute_dataset(trainset)
testset = strategy.experimental_distribute_dataset(testset)
def train_on_batch(X, y):
with tf.GradientTape() as tape:
pred = model(X, training=True)
per_sample_loss = loss(y, pred)
loss_val = tf.reduce_sum(per_sample_loss, keepdims=True) * (1. / 128.0)
# backward
graidents = tape.gradient(loss_val, model.trainable_weights)
# step optimizer
optim.apply_gradients(zip(graidents, model.trainable_weights))
# update accuracy
acc.update_state(y, pred) # 評価関数に結果を足していく
return loss_val
# distribute training用のラップを作る
@tf.function
def distributed_train_on_batch(X, y):
per_replica_losses = strategy.experimental_run_v2(train_on_batch, args=(X, y))
return strategy.reduce(tf.distribute.ReduceOp.SUM, per_replica_losses, axis=None) # lossのreduceをなくした分ここでreduceする
def test_on_batch(X, y):
pred = model(X, training=False)
acc.update_state(y, pred)
@tf.function
def distributed_test_on_batch(X, y):
return strategy.experimental_run_v2(test_on_batch, args=(X, y))
# train
for i in range(5):
acc.reset_states() # 評価関数の集積をリセット
print("Epoch =", i)
for step, (X, y) in enumerate(trainset):
loss_val = distributed_train_on_batch(X, y)
if step % 100 == 0:
print(f"Step = {step}, Loss = {loss_val}, Total Accuracy = {acc.result()}")
acc.reset_states()
for step, (X, y) in enumerate(testset):
distributed_test_on_batch(X, y)
print("Final test accuracy : ", acc.result().numpy()) # acc自体はSparseCategoricalAccuracyなのでresult()を呼び出す
if __name__ == "__main__":
main()
展開して出力を表示
Epoch = 0
Step = 0, Loss = 2.392573356628418, Total Accuracy = 0.1171875
Step = 100, Loss = 0.4335239827632904, Total Accuracy = 0.8025216460227966
Step = 200, Loss = 0.2549169361591339, Total Accuracy = 0.8592972755432129
Step = 300, Loss = 0.24528104066848755, Total Accuracy = 0.8828125
Step = 400, Loss = 0.15728767216205597, Total Accuracy = 0.8959242701530457
Epoch = 1
Step = 0, Loss = 0.07042257487773895, Total Accuracy = 0.96875
Step = 100, Loss = 0.17119136452674866, Total Accuracy = 0.9528929591178894
Step = 200, Loss = 0.12418672442436218, Total Accuracy = 0.9557291865348816
Step = 300, Loss = 0.26172375679016113, Total Accuracy = 0.9576930999755859
Step = 400, Loss = 0.1092691421508789, Total Accuracy = 0.9582878947257996
Epoch = 2
Step = 0, Loss = 0.15685677528381348, Total Accuracy = 0.96875
Step = 100, Loss = 0.1824660301208496, Total Accuracy = 0.9693688154220581
Step = 200, Loss = 0.07719730585813522, Total Accuracy = 0.9702270030975342
Step = 300, Loss = 0.11145241558551788, Total Accuracy = 0.9706707000732422
Step = 400, Loss = 0.06380992382764816, Total Accuracy = 0.9708541035652161
Epoch = 3
Step = 0, Loss = 0.09988237172365189, Total Accuracy = 0.9765625
Step = 100, Loss = 0.07062038779258728, Total Accuracy = 0.9787283539772034
Step = 200, Loss = 0.06160537153482437, Total Accuracy = 0.9784281849861145
Step = 300, Loss = 0.0684187039732933, Total Accuracy = 0.9784052968025208
Step = 400, Loss = 0.0794132724404335, Total Accuracy = 0.978062629699707
Epoch = 4
Step = 0, Loss = 0.02855030633509159, Total Accuracy = 1.0
Step = 100, Loss = 0.009216376580297947, Total Accuracy = 0.9832147359848022
Step = 200, Loss = 0.0803249329328537, Total Accuracy = 0.9832866787910461
Step = 300, Loss = 0.07696796208620071, Total Accuracy = 0.9826619625091553
Step = 400, Loss = 0.028537439182400703, Total Accuracy = 0.9822903871536255
Final test accuracy : 0.9684
これまでの組み合わせです。trainingで訓練・テストモードを指定することに注意しましょう。
まとめ
TensorFlow2.0の書き方の3種類、「Keras API」「Custom train loop」「Custom layer」について見ていきました。同時に、この3種類の書き方全てが、実験段階ではあるもののTPU対応していることを確認しました。その上で、TF2.0以降をふまえ、tf.dataを使ったData Augmentationについて触れました。
TPUについては、かなりのケースでKeras APIで事足りるとは思いますが、Custom layerのように混み行ったケースでも、(速度はさておき)とりあえず動くというのは嬉しいことです。
参考
https://www.tensorflow.org/api_docs/python/tf
https://colab.research.google.com/drive/1UCJt8EYjlzCs1H1d1X0iDGYJsHKwu-NO#scrollTo=FjLI719fPfJi
https://qiita.com/mgmk2/items/59e070dfbdb95137e511
-
これを書いた時点(2019/10/16)ではColab TPUを使った公式ガイドがなかったので(「We will have a tutorial soon that will demonstrate how you can use TPUStrategy.」とあった)、多分この記事が一番早いと思います ↩