Goodfellow先生が紹介していた面白い手法。シンプルかつ強力なCNNの計算コストの削減手法。精度も上がるらしい。サクッと実装できちゃったので試してみました。
OctConv is a simple replacement for the traditional convolution operation that gets better accuracy with fewer FLOPs https://t.co/5CSylHVdA2 pic.twitter.com/kTK96gNj1i
— Ian Goodfellow (@goodfellow_ian) April 15, 2019
元の論文
Y. Chen, H. Fang, B. Xu, Z. Yan, Y. Kalantidis, M. Rohrbach, S. Yan, J. Feng. Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution. (2019) https://arxiv.org/abs/1904.05049
2019/4/10に公開された論文なので、2週間前のできたてホヤホヤの論文です。画像はこの論文から。FacebookのAIチームとシンガポール国立大学のメンバーが中心となって書いたものです。
やっていること
画像の低周波成分と高周波成分の分解。低周波と高周波の成分それぞれに畳み込みを加えるというものです。
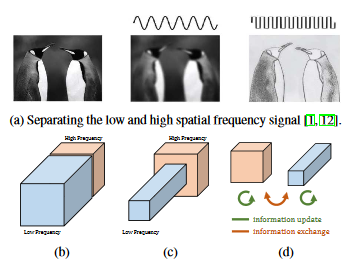
ここで、$\alpha$というハイパーパラメータにより、低周波と高周波のチャンネル数の割り振りを決めます。$\alpha=0$なら高周波だけ、つまりConv2Dと同じになり、$\alpha=1$なら低周波だけの畳み込みになります。
Octave Convolution(OctConv)
Octave Convolutionは従来の畳込み(Conv2D)を置き換えるものとして開発されたものです。以下の構成の畳み込みをOctConvといいます。
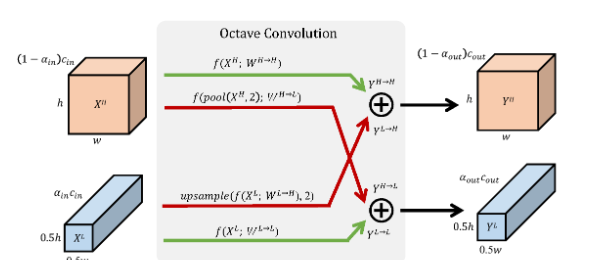
$X^H$が高周波成分、$X^L$が低周波成分。高周波部分は高解像度で、低周波成分は低解像度のテンソルからなります。緑字のような$X^H, X^L$それぞれに畳み込みを行うのに加えて、赤字のような低周波と高周波の交換を随時行うというのがポイント。ネットワーク内でミックスをしていきます。
したがって1レイヤー間に4つの畳み込み操作があるというのがわかります。低周波部分をLow,高周波部分をHighとします。
- High→High(緑字):$W^{H\to H}$のカーネルで畳み込み
- High→Low(赤字):1/2のAveragePoolingをしてから、$W^{H\to L}$のカーネルで畳み込み
- Low→High(赤字):$W^{L\to H}$のカーネルで畳み込みしてから、2倍のアップサンプリング
- Low→Low(緑字):$W^{L\to L}$のカーネルで畳み込み
これだけ。入力テンソルが2種類になってはいるものの、InceptionやNASNetのような配線芸と大して変わらないことがわかります。InceptionやNASもブロックの内部でPoolingは使っているものの、OctConvのほうがもっと明示的に低周波・高周波の分離をやっているため、この点においてOctConvは明瞭であるといえるでしょう。
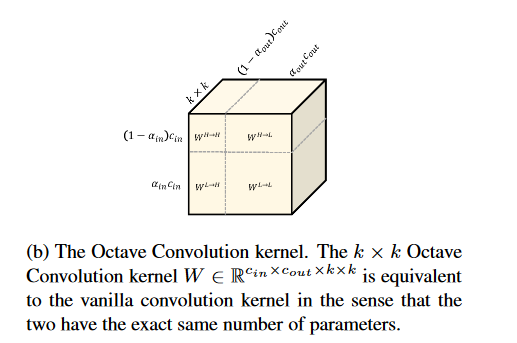
パラメーターの数が従来のConv2Dと変わらないというのも面白いです。やっていることはConv2DのパラメーターをHigh→High、……、Low→Lowと4種類に割り振っているだけです。
論文のオフィシャルなコードは4/20現在準備中とのことですが、正直こんなの楽勝なので、オフィシャル実装を待たずしてサクッと実装している方が世界中で散見されます(日本人ではやっているの自分ぐらいしかいないですが)。自分も1から書いてみました。こんな感じになるのではないでしょうか。
4/26追記:公式の実装(MXNet)ができています。自分のリポジトリをサードパーティーの実装として載せていただきました! ありがとうございました!
"""
Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution
https://arxiv.org/abs/1904.05049
"""
from tensorflow.keras import layers
from tensorflow.keras.models import Model
import tensorflow.keras.backend as K
class OctConv2D(layers.Layer):
def __init__(self, filters, alpha, kernel_size=(3,3), strides=(1,1),
padding="same", kernel_initializer='glorot_uniform',
kernel_regularizer=None, kernel_constraint=None,
**kwargs):
"""
OctConv2D : Octave Convolution for image( rank 4 tensors)
filters: # output channels for low + high
alpha: Low channel ratio (alpha=0 -> High only, alpha=1 -> Low only)
kernel_size : 3x3 by default, padding : same by default
"""
assert alpha >= 0 and alpha <= 1
assert filters > 0 and isinstance(filters, int)
super().__init__(**kwargs)
self.alpha = alpha
self.filters = filters
# optional values
self.kernel_size = kernel_size
self.strides = strides
self.padding = padding
self.kernel_initializer = kernel_initializer
self.kernel_regularizer = kernel_regularizer
self.kernel_constraint = kernel_constraint
# -> Low Channels
self.low_channels = int(self.filters * self.alpha)
# -> High Channles
self.high_channels = self.filters - self.low_channels
def build(self, input_shape):
assert len(input_shape) == 2
assert len(input_shape[0]) == 4 and len(input_shape[1]) == 4
# Assertion for high inputs
assert input_shape[0][1] // 2 >= self.kernel_size[0]
assert input_shape[0][2] // 2 >= self.kernel_size[1]
# Assertion for low inputs
assert input_shape[0][1] // input_shape[1][1] == 2
assert input_shape[0][2] // input_shape[1][2] == 2
# channels last for TensorFlow
assert K.image_data_format() == "channels_last"
# input channels
high_in = int(input_shape[0][3])
low_in = int(input_shape[1][3])
# High -> High
self.high_to_high_kernel = self.add_weight(name="high_to_high_kernel",
shape=(*self.kernel_size, high_in, self.high_channels),
initializer=self.kernel_initializer,
regularizer=self.kernel_regularizer,
constraint=self.kernel_constraint)
# High -> Low
self.high_to_low_kernel = self.add_weight(name="high_to_low_kernel",
shape=(*self.kernel_size, high_in, self.low_channels),
initializer=self.kernel_initializer,
regularizer=self.kernel_regularizer,
constraint=self.kernel_constraint)
# Low -> High
self.low_to_high_kernel = self.add_weight(name="low_to_high_kernel",
shape=(*self.kernel_size, low_in, self.high_channels),
initializer=self.kernel_initializer,
regularizer=self.kernel_regularizer,
constraint=self.kernel_constraint)
# Low -> Low
self.low_to_low_kernel = self.add_weight(name="low_to_low_kernel",
shape=(*self.kernel_size, low_in, self.low_channels),
initializer=self.kernel_initializer,
regularizer=self.kernel_regularizer,
constraint=self.kernel_constraint)
super().build(input_shape)
def call(self, inputs):
# Input = [X^H, X^L]
assert len(inputs) == 2
high_input, low_input = inputs
# High -> High conv
high_to_high = K.conv2d(high_input, self.high_to_high_kernel,
strides=self.strides, padding=self.padding,
data_format="channels_last")
# High -> Low conv
high_to_low = K.pool2d(high_input, (2,2), strides=(2,2), pool_mode="avg")
high_to_low = K.conv2d(high_to_low, self.high_to_low_kernel,
strides=self.strides, padding=self.padding,
data_format="channels_last")
# Low -> High conv
low_to_high = K.conv2d(low_input, self.low_to_high_kernel,
strides=self.strides, padding=self.padding,
data_format="channels_last")
low_to_high = K.repeat_elements(low_to_high, 2, axis=1) # Nearest Neighbor Upsampling
low_to_high = K.repeat_elements(low_to_high, 2, axis=2)
# Low -> Low conv
low_to_low = K.conv2d(low_input, self.low_to_low_kernel,
strides=self.strides, padding=self.padding,
data_format="channels_last")
# Cross Add
high_add = high_to_high + low_to_high
low_add = high_to_low + low_to_low
return [high_add, low_add]
def compute_output_shape(self, input_shapes):
high_in_shape, low_in_shape = input_shapes
high_out_shape = (*high_in_shape[:3], self.high_channels)
low_out_shape = (*low_in_shape[:3], self.low_channels)
return [high_out_shape, low_out_shape]
def get_config(self):
base_config = super().get_config()
out_config = {
**base_config,
"filters": self.filters,
"alpha": self.alpha,
"filters": self.filters,
"kernel_size": self.kernel_size,
"strides": self.strides,
"padding": self.padding,
"kernel_initializer": self.kernel_initializer,
"kernel_regularizer": self.kernel_regularizer,
"kernel_constraint": self.kernel_constraint,
}
return out_config
全体のコードはこちらになります。
https://github.com/koshian2/OctConv-TFKeras
計算コストの削減効果とImageNetの精度
これは論文に書いてあった内容です。$\alpha=0$ならConv2Dと同じ高周波成分だけ、$\alpha=1$なら1/2にダウンサンプリングした低周波成分だけのConv2Dと同じになるので、$\alpha=1$なら計算コストは1/4になります。
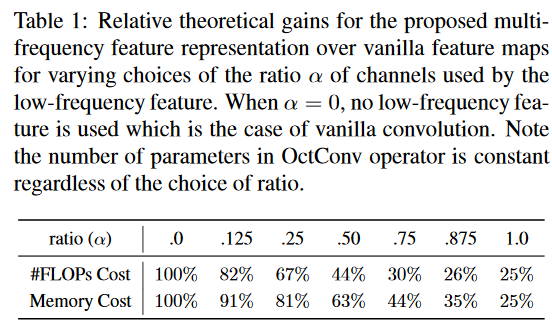
αを0~1の中間に取れば、それに見合ったFLOPs、メモリーといった計算コストは削減されます。ここからがミソなのですが、計算量MAXの$\alpha=0$よりもαが0~1の中間の値のほうが精度が上がるということなのです。これはImageNetのTop1精度です。
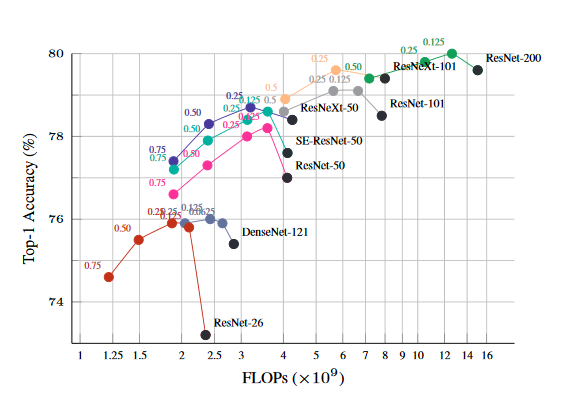
黒い点は$\alpha=0$のケースで、従来のConv2Dで定義したネットワークでの精度です。他の点はOctConvに置き換えてαの値別にプロットしています。特に、ResNet-26やResNet-50といったシンプルなResNetで効果が高いということがわかりますね。
この結果の直感的な理解は、あくまで自分の意見ですが、結局低周波成分は大域特徴量で、高周波成分は局所的な特徴量になりがちなので、低周波と高周波を随時ミックスさせるというのは、浅い層と深い層にSkip Connectionを入れて配線したものと直感的には似ている(DenseNetのような深さの配線芸が層レベルで再現される)のではないかと思うのです。事実、DenseNetや、Block内での横展開が充実しているResNeXtなんかは、シンプルなResNetよりOctConvの効果が薄くなっていますよね。論文読み返していたら、DenseNetとの差について言及していた部分があったので、多分そういうことではないかなと思います。
CIFAR-10で検証してみた
ここからは自分の実験です。論文ではCIFAR-10の検証がなかったので自分でやってみました。以下の条件です。
- WideResNet N=4, k=10とした
- バッチサイズは128、学習率0.1のモメンタム(論文のImageNetでは、普通のSGD+コサインアニーリング)
- α=0, 0.25, 0.5, 0.75で調べた。α=0は普通のWide Res-Net、それ以外はOctConvのWide Res-Net。
- 200エポック訓練させる。100エポック目と150エポック目で学習率を1/5に減衰。
- 左右反転、上下左右4ピクセルクロップというStandard Data Augmentationを使用(論文のImageNetでは特にAugmentationはしていないっぽい)
- Google ColabのTPU環境で訓練
バッチサイズや学習率はよくありがちな設定です。詳しくはこちらのコードを参照ください。
https://github.com/koshian2/OctConv-TFKeras/blob/master/train.py
結果は次のようになりました。
| alpha | テスト精度 |
|---|---|
| 0 | 88.68% |
| 0.25 | 94.25% |
| 0.5 | 94.06% |
| 0.75 | 93.66% |
$\alpha=0$はWideResNetのN=4, k=10。その他はOctConvに置き換えた同様のWideResNetです。OctConvちょっと精度出過ぎというか、普通のWideResNetの精度がえらい低いですね(原因は不明)。WideResNetの論文とは完全に同じ設定にしていないので、$\alpha=0$はあと3~4%は出ても良さそうですが、なんとなくOctConvの論文の図っぽい感じにはなっています。ImageNetでは全般的に$\alpha=0.25$のときが一番精度が出ていることが多かったですが、CIFAR-10でも同様の結果を確認できました。
学習曲線は以下の通り。
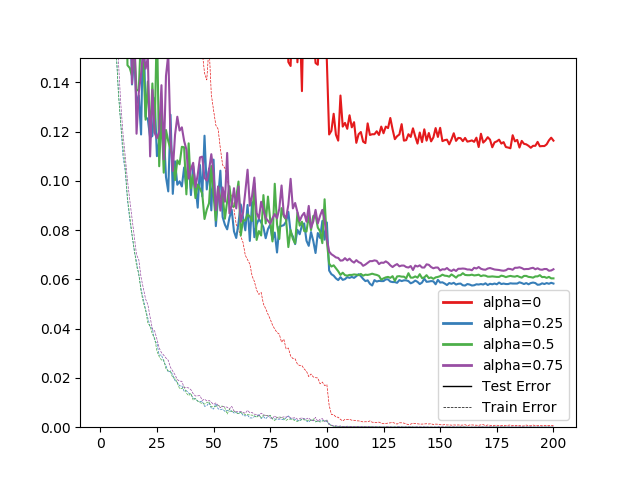
通常のWideResNetがあからさまに収束が遅いのが謎。なにかが間違ってるのかしら。
注意点
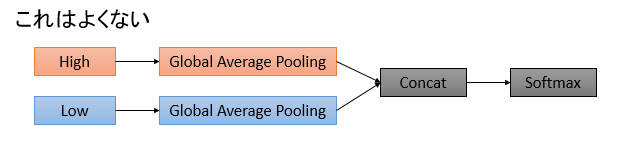
実装していてハマった点です。論文には特に書いていませんでしたが、出力層の近くのネットワークの構造に注意です。
このようにHighとLowでGlobal Average PoolingしてConcatするパターンは好ましくありません。精度が一定(8割とか)で頭打ちになったり、訓練の途中で8割近くまで上がっていた訓練精度が5割ぐらいまで落ちたりと、変な揺り戻しが起こります。
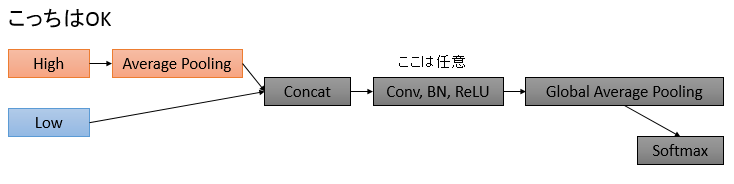
逆にこういうパターンはOKです。ConcatしてからGlobal Average Poolingしましょう。
推論速度(CPU/GPU)
OctConvは計算効率が良いのが売りですが、どの程度良くなるでしょうか。CPU/GPUの推論時間で比較してみます。TPUでの訓練時間は、エポックあたりの時間はほとんど差がなく、コンパイル時間が支配的になってしまったのでとりあえず考えないものとします。
CPU/GPUはそれぞれColabの環境で考えます。ネットワークは訓練に使ったWideResNetで、GPU環境では5万サンプル、CPU環境では256サンプルを推論させ、α別に各ケース20回ずつテストします。推論のバッチサイズはCPU/GPUとも128とします。
CPU
| α/秒 | 平均値 | 中央値 | 標準偏差 | 中央値/1サンプル[ms] | 実測相対値 | FLOPsコスト理論値 |
|---|---|---|---|---|---|---|
| 0 | 39.18 | 38.96 | 0.6807 | 152.19 | 100 | 100 |
| 0.25 | 29.79 | 29.55 | 0.7705 | 115.43 | 76 | 67 |
| 0.5 | 20.61 | 20.46 | 0.5052 | 79.92 | 53 | 44 |
| 0.75 | 14.38 | 14.17 | 0.7874 | 55.35 | 36 | 30 |
αが大きくなるほど推論時間が短くなるというわかりやすい結果になっています。FLOPsコストの理論値は論文から。実測値はほぼ理論値通りの結果になりました。
GPU
| α/秒 | 平均値 | 中央値 | 標準偏差 | 中央値/1サンプル[ms] | 実測相対値 |
|---|---|---|---|---|---|
| 0 | 60.43 | 59.94 | 1.693 | 1.20 | 100 |
| 0.25 | 62.24 | 62.09 | 0.6996 | 1.24 | 104 |
| 0.5 | 47.87 | 47.73 | 0.6224 | 0.95 | 80 |
| 0.75 | 34.15 | 34 | 0.6747 | 0.68 | 57 |
GPUの場合は$\alpha=0.25$の場合は逆に遅くなっています。デバイスへの転送の関係で、層が増えたことによるオーバーヘッドが若干支配的になったのでしょうか。ただ、$\alpha=0.5$以降はきちんと減っているので、あまり気にするようなことでもないと思います。
計算コストの理論値
OctConvのメモリコスト、FLOPsコストの理論値は次のようになります(論文から)
メモリコスト
$$1-\frac{3}{4}\alpha $$
FLOPsコスト
$$1-\frac{3}{4}\alpha(2-\alpha) $$
雑感
- OctConvすごい。FLOPs半分以下にしても精度がほとんど落ちないのはすごい。直感的にはJPEG圧縮で、高周波部分はえらい間引きし、低周波部分を重点的に残して、見た目の変化がないようにしつつ容量を削るのに似ているような気がする。
- 論文にも書いてあったけど、Depthwise Convの派生でDepthwise OctConvやSeparable OctConvにするのが面白そう
- 低周波と高周波を分けて考えているから、画像を生成するようなモデルでOctConvを使ったら画質がよくなるのでは?という妄想
ということでした。実装してみたら結構面白いネットワークでした。
お知らせ
技術書典6で頒布したモザイク本の通販を下記URLで行っています。会場にこられなかったけど欲しいという方は、ぜひご利用ください。
『DeepCreamPyで学ぶモザイク除去』通販
https://note.mu/koshian2/n/naa60d5c9ebba
ディープラーニングや機械学習における画像処理の基本や応用を学びながら、モザイク除去技術DeepCreamPyを使いこなし、自分で実装するまでを目指す解説書です。