概要
対話システムとは、コンピュータが人間と会話することを目的としたシステムです。
コンピュータ側が入力文に対してどのように応答文を決定するかには様々な手法がありますが、その一つに用例ベースの手法があります。
用例ベースの手法ではあらかじめ対話データとして、入力文と応答文のペアをいくつか用意します。ユーザからの入力文と最も類似する対話データ中の入力文を求め、そのペアに当たる応答文を返すという仕組みです。
つくるもの
以下の画像のようなものです。

プログラムの手順としては、
1.対話データを用意する。
2.ユーザから入力文を受け取る。
3.ユーザからの入力文と対話データ中の各入力文の類似度を計算。
4.最も類似する対話データ中の入力文のペアとなる応答文を出力。
5.2~4をグルグル回していく。
手順1と3については以下で詳細を説明します。
入力文と応答文のペアを作成する
雑談対話コーパス(https://sites.google.com/site/dialoguebreakdowndetection/chat-dialogue-corpus)を用いて対話データを作成します。
システムの発話1→ユーザの発話1→システムの発話2...というように会話がjson形式で格納されています。
今回はjson中の会話を分解し以下の表のようにcsv形式の対話データを作成します。
| 入力文 | 応答文 |
|---|---|
| システムの発話1 | ユーザの発話1 |
| ユーザの発話1 | システムの発話2 |
| システムの発話2 | ユーザの発話2 |
| ユーザの発話2 | システムの発話3 |
| ... | ... |
文章間類似度
ある文章とある文章がどのくらい類似しているかを算出する方法はいくつかあると思いますが、今回はWMD(Word Mover's Distance)という手法を用います。
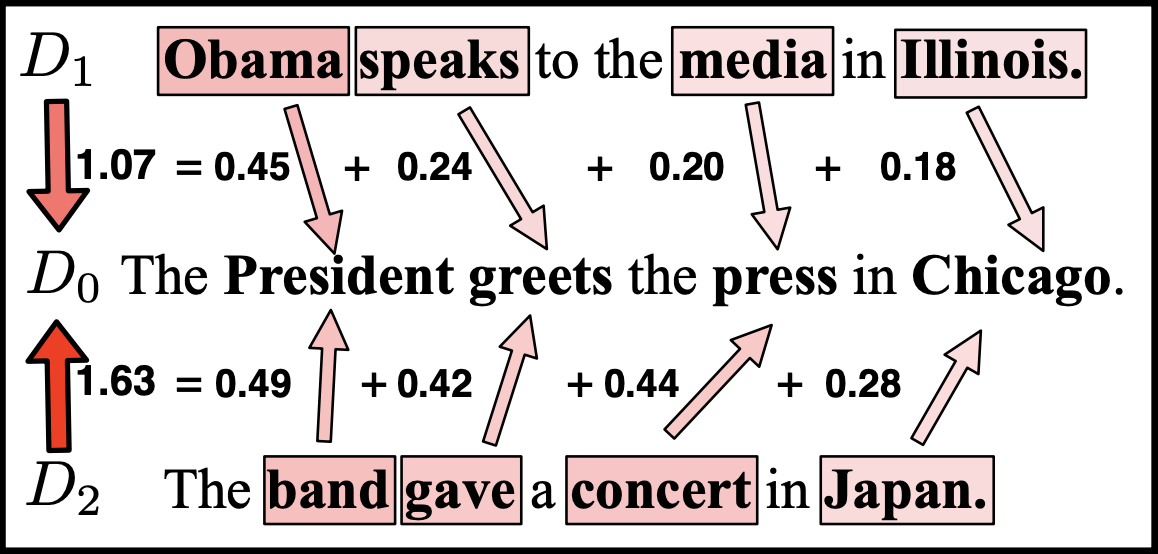
例えば文書D0と文書D1間の距離を計算する際、文書D1のある意味語(Obamaとか)を文書D0のある意味語(Presidentとか)に置き換えた時のコストを計算し、そのコストの総和が最も低い場合のスコアを文書D0、D1の距離として計算しています。単語の分散表現から得た単語間の類似度を意味語の置き換えのコストとして考えることで計算することができます。
今回は意味語の定義として、助動詞、助詞、記号以外の語を意味語としています。
学習済みの単語埋め込みベクトルがあれば文章間類似度を計算できるので、doc2vecのように学習してモデルを用意するといった手間を省ける利点があります。
学習済みの日本語単語埋め込みベクトルには白ヤギコーポレーションより公開されている単語埋め込みベクトル(https://aial.shiroyagi.co.jp/2017/02/japanese-word2vec-model-builder/)を使用します。日本語のものは他でもいくつか公開されていますが上記は他のものと比べファイルサイズが小さいです。
使用パッケージ
対話データはcsvファイルに保存します。csvの操作にはpandasを用いています。またWMDの実装のためにgensim、日本語の形態素解析のためにMeCabを用いています。
MeCabを入れるのが手間だ!という人はjanomeでも実装できると思います。
データの準備
コードはこちらにあります。対話コーパスと埋め込みベクトルは含まれてないので別途ダウンロードしてディレクトリに入れる必要があります。ディレクトリの構造は以下のようになっています。
examplebase_bot
├ main.py
├ item.py
├ make_csv.py
└ model/
雑談対話コーパスをダウンロードしzipファイルを解凍するとjsonという会話データの入ったフォルダがあるのでexamplebase_bot/に入れます。
白ヤギコーポレーションより公開されている単語埋め込みベクトルはダウンロードすると、word2vecのmodelとnpyファイル2つが手に入ると思います。3つまとめてmodel/に入れます。
$ python3 make_csv.py
上記のようにmake_csv.pyを実行して対話データとなるdata.csvをexamplebase_bot/に生成します。これで準備は完了です。
実装
本体のmain.pyは以下のように実装しています。
import pandas as pd
import MeCab
from gensim.models.word2vec import Word2Vec
from gensim.models.keyedvectors import KeyedVectors
import item #自作モジュール
mecab = MeCab.Tagger('-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')
print("学習済みモデル読み込み")
model_path = 'model/word2vec.gensim.model'
model = Word2Vec.load(model_path)
print("読み込み終わり")
df = pd.read_csv('data.csv')
df = df.dropna()
def ans(text, df):
text_wakati = item.morpheme_list(text)#入力文の形態素解析
wmd = lambda x: model.wv.wmdistance(text_wakati, x)
result = df['input_wakati'].map(wmd).idxmin()
return df['output'].iloc[result]
while True:
text = input(">>>")
if text == "quit":
break
r = ans(text, df)
print(r)
main.pyを実行すると話ができます。文章が入力されるたびに各文との類似度を計算しているので応答までに10秒ほどかかってしまいます。
$ python3 main.py
学習済みモデル読み込み
読み込み終わり
>>>こんにちは!
元気ですか?
>>>僕は元気ですよ
退屈でしかたないですか
>>>いえ、最近は毎日が楽しいです。
退屈でしょうがないです
>>>
噛み合わない時もありますがなかなか面白いです。