はじめに
ITエンジニア向け転職サイト転職ドラフトでプロダクトマネージャーをしている、koseiKGです。
プロダクト企画や審査体験の改善などなどを行なっています。
これまでに約5000人のエンジニアのレジュメを見てきた中で、
”実力が伝わり指名をもらいやすいレジュメ”
というのもある程度パターンがあります。
そんなパターンをトピックモデルを用いて紹介します
前提
文書が複数の潜在的なトピックから確率的に生成されると仮定したモデルをトピックモデルとする
これを用いる理由は、転職ドラフトのレジュメはフォーマット化されていないフリースタイル形式であり、潜在的な意味は三者三様。
もちろん、指名数が集まる理由はレジュメ以外に当然あるが、CTO経験などは極小なために排除できるものとする。
結果
指名数上位は極端に、”チームでの開発経験”、”設計や要件定義”、”フルスタックで業務、役割を横断する”などチームでの開発経験や、BE,FE,インフラの知識を活かした開発経験での貢献などをレジュメに積極的に盛り込んでいる傾向。
一方で、下位となるとチームでの開発経験に触れるケースは減少し、特定のシステムでの開発を特定の技術要件で実装した経験が盛り込まれている傾向
より、企業にとって魅力的に、かつポジションに沿うような経歴・経験というのはいかにしてチームでの開発経験を盛り込むかが重要な要素だったりする。
分析
データセット
転職ドラフトでの1開催あたりの平均指名数をDecilで分割し上位10%のレジュメを抽出
https://job-draft.jp/users から実際の参加者のレジュメは公開しているユーザーに限り閲覧することができます。
プロセス
LDAで「文書-トピック分布」と「トピック-単語分布」。クラスターをとりあえず6個にして分割
トピック-単語分布の可視化
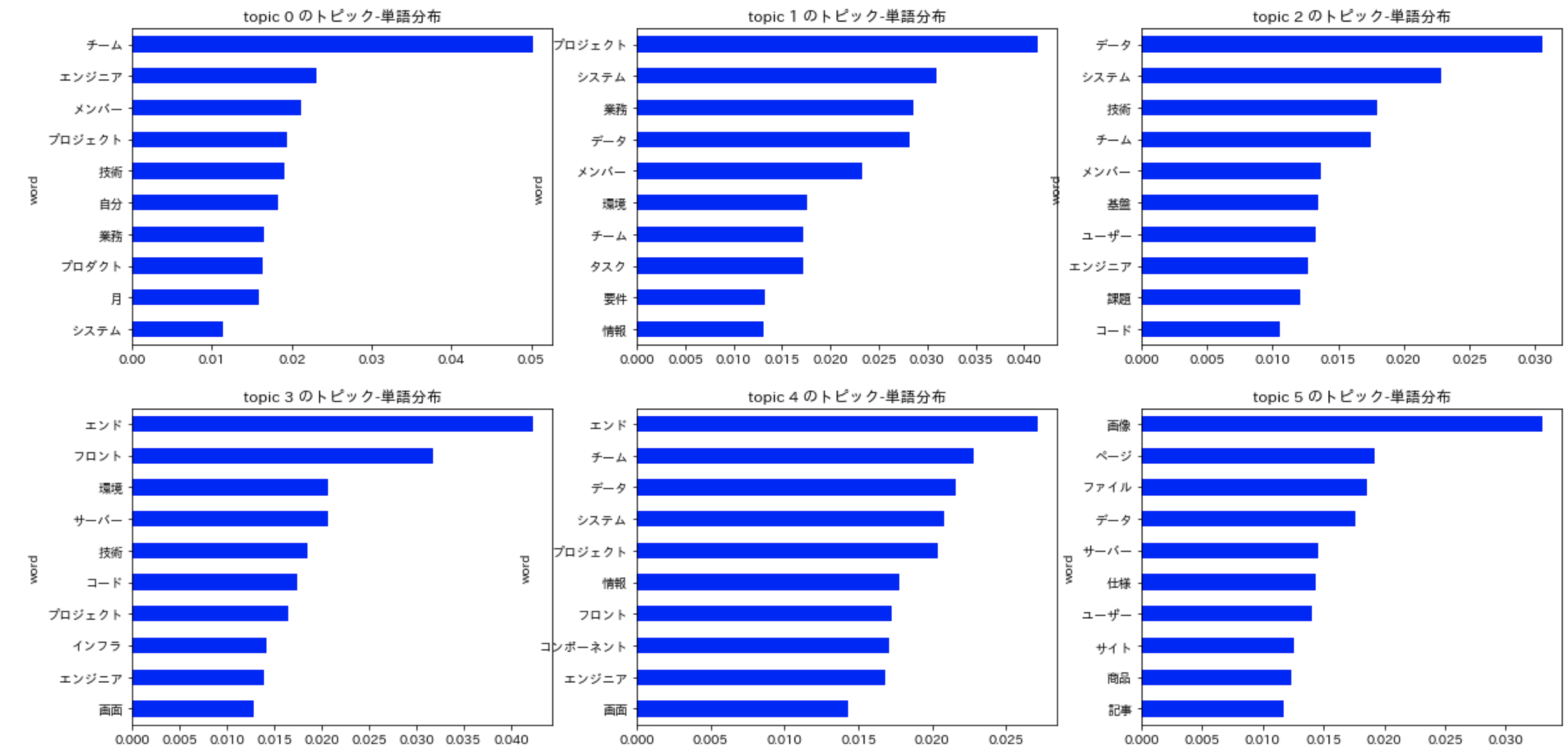
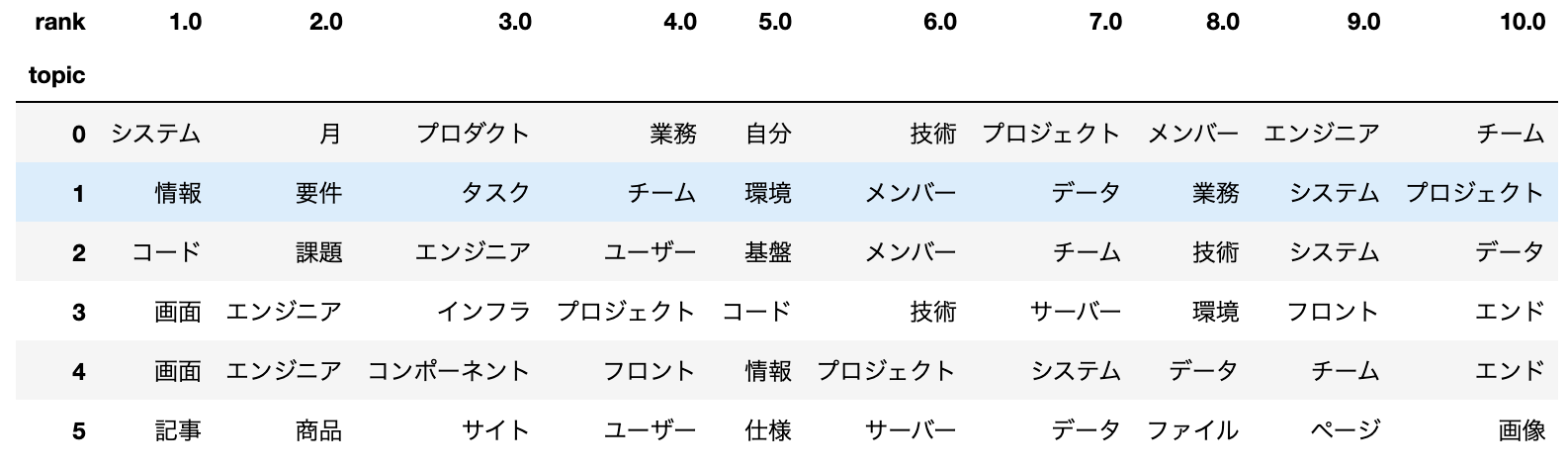
topic1はプロジェクトでのチームでの要件定義、システム開発に関するトピック、
topic2はユーザーの課題の解決を軸にデータウェアハウスなどのシステム基盤の構築・コーディング業務に関するトピック
topic3はフルスタック的にフロント、バックエンド、インフラを横断し、特定の技術を用いて画面などの開発を行うトピック
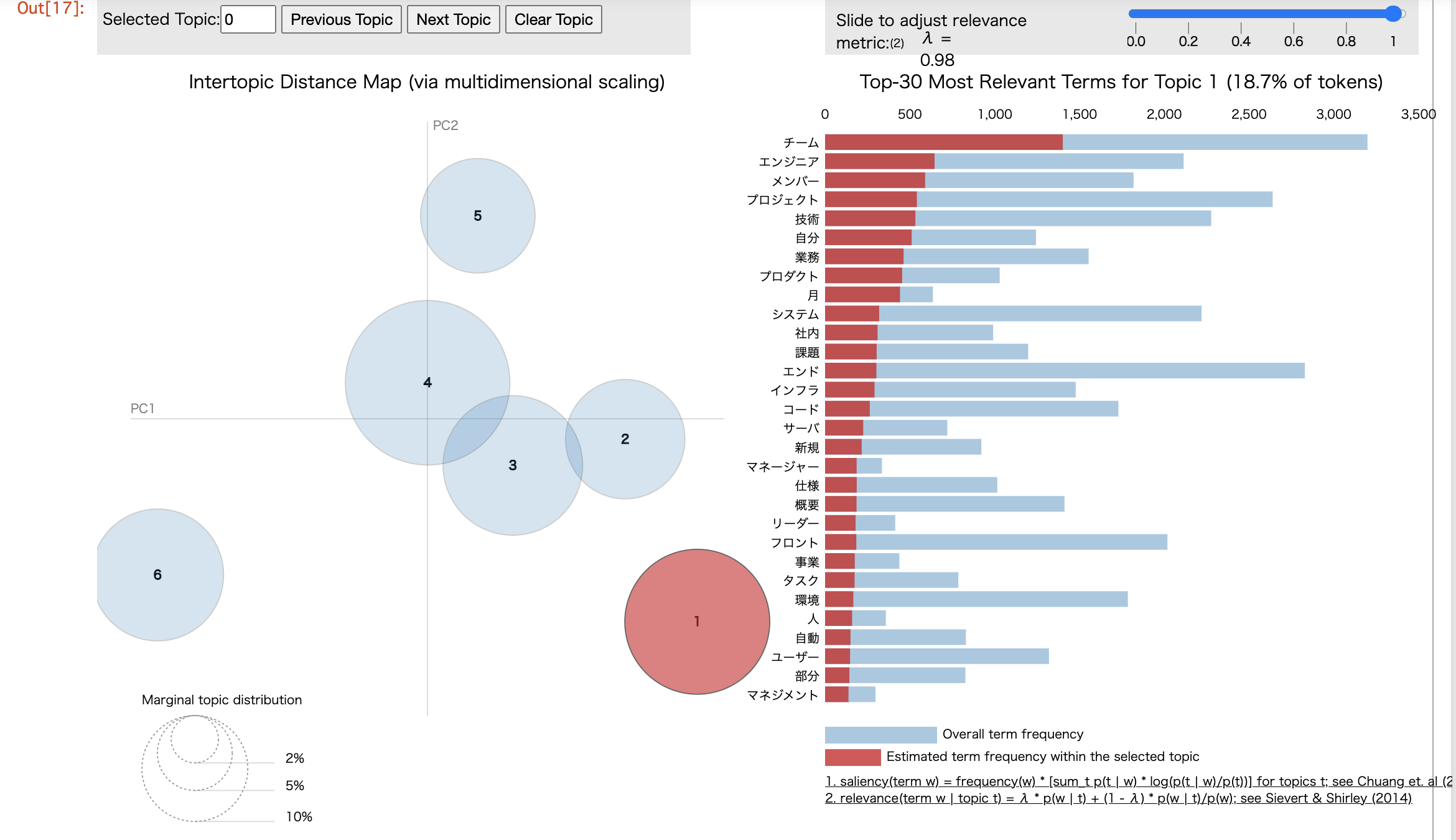
pyLDAvisを用いて、もう少しトピックを可視化してみます
コード
import pandas as pd
import MeCab
import gensim
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
def parse(tweet_temp):
t = MeCab.Tagger()
temp1 = t.parse(tweet_temp)
temp2 = temp1.split("\n")
t_list = []
for keitaiso in temp2:
if keitaiso not in ["EOS",""]:
word,hinshi = keitaiso.split("\t")
t_temp = [word]+hinshi.split(",")
if len(t_temp) != 10:
t_temp += ["*"]*(10 - len(t_temp))
t_list.append(t_temp)
return t_list
def parse_to_df(tweet_temp):
return pd.DataFrame(parse(tweet_temp),
columns=["単語","品詞","品詞細分類1",
"品詞細分類2","品詞細分類3",
"活用型","活用形","原形","読み","発音"])
def make_lda_docs(texts):
docs = []
for text in texts:
df = parse_to_df(text)
extract_df = df[(df["品詞"]+"/"+df["品詞細分類1"]).isin(["名詞/一般","名詞/固有名詞"])]
extract_df = extract_df[extract_df["原形"]!="*"]
doc = []
for genkei in extract_df["原形"]:
doc.append(genkei)
docs.append(doc)
return docs
texts = livedoor["content"].values
docs = make_lda_docs(texts)
dictionary = gensim.corpora.Dictionary(docs)
corpus = [dictionary.doc2bow(doc) for doc in docs]
# 学習
n_cluster = 6
lda = gensim.models.LdaModel(
corpus=corpus,
id2word=dictionary,
num_topics=n_cluster,
minimum_probability=0.001,
passes=20,
update_every=0,
chunksize=10000,
random_state=1
)
corpus_lda = lda[corpus]
arr = gensim.matutils.corpus2dense(
corpus_lda,
num_terms=n_cluster
).T
lists = []
for i in range(n_cluster):
temp_df = pd.DataFrame(lda.show_topic(i),columns=["word","score"])
temp_df["topic"] = i
lists.append(temp_df)
topic_word_df = pd.concat(lists,ignore_index=True)
fig, axes = plt.subplots(nrows=2, ncols=3, figsize=(20, 10))
for i,gdf in topic_word_df.groupby("topic"):
gdf.set_index("word")["score"].sort_values().plot.barh(
ax=axes[i//3, i%3],
title="topic {} のトピック-単語分布".format(i),
color="blue")