- 初めに
限界開発鯖のアドベントカレンダー19日目です。おはようございます。
よわよわ高専生代表 kosakaeというものです。
この記事ではMLP-mixerの概要説明とちょっと応用してみた件について書きます。
ここに書いてある内容のうち解説は多分ほとんど間違えてるので参考にはしないでください
今回使ったipynbファイルは一番下にあるので、動かしたいならそれをどうぞ
- 概要
・MLP-mixerの特徴の解説
・MLP-mixerのモデル図の解説
・MLP-mixerの実装
・判別結果
・MNISTのGANをやってみる
- 対象
・DNN、完全に理解した人
・colabでやったのでcolab使ってほしいな
・pythonなのでほかの言語の方は頑張って読み替えてください
・pytorchのコードをある程度読める人
- 特徴
まずMLP-mixerってなんぞってところをちょっと説明
MLP-mixerってのは画像用の特徴抽出機的なものですね。
画像分類タスクではこれまでCNNが主流で、最近になってvision transformerとかいうやつが流行りつつありますよね
そんな中突然現れたのがMLP-mixer
モデルの構造は名前のまんまで、基本的には多層パーセプトロンの出力を混ぜ混ぜして特徴量を拡大していく構造ですね
大きな特徴として、Conv層、Pooling層を一切使っていないことが挙げられます
多層パーセプトロンだけの構造なので、単純な計算だけで学習を行えます
このモデルの登場は少しだけ話題になりました。一応SoTAに届くらしいです
- モデル構造

入力をchannel height width -> (height width) channel 形式にします(hwは結合され、channelがpatch数と等しくなります)
今回の実装では、畳み込みを使って特徴を圧縮(per-patch fully-connected) 64x64 → 8 x 8 (kernel=8, stride=8)
それらを行列と見なして転置します
geluに通して再度転置
Skip-connectionで元のデータと足し合わせる
layer normしてそれぞれgeluに
もう一度skip-connection
図見たらわかる気はするので一応それで
- 実装
はい。実装というかgithubからコピペしてきただけですので、僕はなんもしてないです
import torch.nn as nn
import torchvision
from einops.layers.torch import Rearrange
import numpy as np
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class MixerBlock(nn.Module):
def __init__(self, dim, num_patch, token_dim, channel_dim, dropout = 0.):
super().__init__()
self.token_mix = nn.Sequential(
nn.LayerNorm(dim),
Rearrange('b n d -> b d n'),
FeedForward(num_patch, token_dim, dropout),
Rearrange('b d n -> b n d')
)
self.channel_mix = nn.Sequential(
nn.LayerNorm(dim),
FeedForward(dim, channel_dim, dropout),
)
def forward(self, x):
x = x + self.token_mix(x)
x = x + self.channel_mix(x)
return x
class MLPMixer(nn.Module):
def __init__(self, in_channels, dim, num_classes, patch_size, image_size, depth, token_dim, channel_dim):
super().__init__()
assert image_size % patch_size == 0, 'Image dimensions must be divisible by the patch size.'
self.num_patch = (image_size// patch_size) ** 2
self.to_patch_embedding = nn.Sequential(
nn.Conv2d(in_channels, dim, patch_size, patch_size),
Rearrange('b c h w -> b (h w) c'),
)
nn.Conv2d(in_channels=in_channels, out_channels=dim,
kernel_size=patch_size, stride=patch_size)
self.mixer_blocks = nn.ModuleList([])
for _ in range(depth):
self.mixer_blocks.append(MixerBlock(dim, self.num_patch, token_dim, channel_dim))
self.layer_norm = nn.LayerNorm(dim)
self.mlp_head = nn.Sequential(
nn.Linear(dim, num_classes)
)
def forward(self, x):
#print((x.shape[2]//16)**2)
x = self.to_patch_embedding(x)
#print(x.shape)
for mixer_block in self.mixer_blocks:
x = mixer_block(x)
#print(x.shape)
#print(mixer_block)
x = self.layer_norm(x)
x = x.mean(dim=1)
return self.mlp_head(x)
if __name__ == "__main__":
img = torch.ones([50, 3, 224, 224])
model = MLPMixer(in_channels=3, image_size=224, patch_size=16, num_classes=1000,
dim=512, depth=3, token_dim=256, channel_dim=2048)
parameters = filter(lambda p: p.requires_grad, model.parameters())
parameters = sum([np.prod(p.size()) for p in parameters]) / 1_000_000
print('Trainable Parameters: %.3fM' % parameters)
out_img = model(img)
print("Shape of out :", out_img.shape) # [B, in_channels, image_size, image_size]
いかにもなコピペ臭がただよってますね
コードのどの部分が何なのか説明しますね
class MLPMixer(nn.Module):
def __init__(self, in_channels, dim, num_classes, patch_size, image_size, depth, token_dim, channel_dim):
super().__init__()
assert image_size % patch_size == 0, 'Image dimensions must be divisible by the patch size.'
self.num_patch = (image_size// patch_size) ** 2
self.to_patch_embedding = nn.Sequential(
nn.Conv2d(in_channels, dim, patch_size, patch_size),
Rearrange('b c h w -> b (h w) c'),
)
nn.Conv2d(in_channels=in_channels, out_channels=dim,
kernel_size=patch_size, stride=patch_size)
self.mixer_blocks = nn.ModuleList([])
for _ in range(depth):
self.mixer_blocks.append(MixerBlock(dim, self.num_patch, token_dim, channel_dim))
self.layer_norm = nn.LayerNorm(dim)
self.mlp_head = nn.Sequential(
nn.Linear(dim, num_classes)
)
def forward(self, x):
#print((x.shape[2]//16)**2)
x = self.to_patch_embedding(x)
#print(x.shape)
for mixer_block in self.mixer_blocks:
x = mixer_block(x)
#print(x.shape)
#print(mixer_block)
x = self.layer_norm(x)
x = x.mean(dim=1)
return self.mlp_head(x)
これがモデルを呼び出すクラス
patch数ぶん、画像を分けそれぞれconvで圧縮
layer norm
mixer_blockをdepth回重ねる
layer norm
global average pooling
具体的になにやってるのかことばで言うなら、入力をpatchで切って、mixer_blockにぶちこんで、全結合
みたいな。
class MixerBlock(nn.Module):
def __init__(self, dim, num_patch, token_dim, channel_dim, dropout = 0.):
super().__init__()
self.token_mix = nn.Sequential(
nn.LayerNorm(dim),
Rearrange('b n d -> b d n'),
FeedForward(num_patch, token_dim, dropout),
Rearrange('b d n -> b n d')
)
self.channel_mix = nn.Sequential(
nn.LayerNorm(dim),
FeedForward(dim, channel_dim, dropout),
)
def forward(self, x):
x = x + self.token_mix(x)
x = x + self.channel_mix(x)
return x
さっき言ってたmixer block
x2 = skip connection
layer norm(x)
特徴量とチャンネルを転置(x)
多層パーセプトロン(x)
特徴量とチャンネルを転置(x)
x = x2 + x
x3 = skip connection
layer norm(x)
多層パーセプトロン(x)
x = x3 + x
特徴量(w,h)を圧縮して引き延ばしたやつをチャンネルベクトルと転置(転置行列)してMLP通して戻して
残差ブロックで2回転置する前の特徴量持ってきて、MLP通してもう一回残差ブロックから特徴量持ってくる
言っててわけわかんねぇな???
FeedForwardに関しては読めると思うので省略
今回はこのモデルでcifar10をクラス分類してみます
net = MLPMixer(in_channels=3, image_size=32, patch_size=4, num_classes=10,
dim=120, depth=16, token_dim=60, channel_dim=480)

最適化アルゴリズムはAdam (params: lr=0.0001 beta = 0.9, 0.999)
損失関数は交差エントロピー
もちろんDAもちょっとだけしてあります
- 結果
colabが途中で止まったので、学習曲線はないです

原因究明もやる気がないのでしません、まぁレイヤー数が少ないとかだとは思います
mlp-mixerにはmixupが結構有効っぽいので、最悪それを実装すればもう少し上がります
後今回は学習の速度を上げるために、レイヤーの数をめちゃくちゃ小さくしてます(めっちゃ早い)
先駆者曰くmixup、 レイヤー数上げをしたら、90%超えるらしい。普通にそこそこ強い
- 応用してみた
クラス分類しただけで終わりはさすがに寂しいので、GANを作ってみましょう
命名するなら、MLP-mixGANとかになるんですかね
このモデルには転置畳み込みだの普通の畳み込みだの入ってます。エンコードできないので。
昔やったアニメキャラ画像をPGGANで生成するやつで一応データはありますが、引っ張ってくるのがめんどい上に普通に難しいので、今回はMNIST手書き文字でやってみましょう
実装を乗せると長くなるので、使ったファイルは下に張っときます
- モデル構造
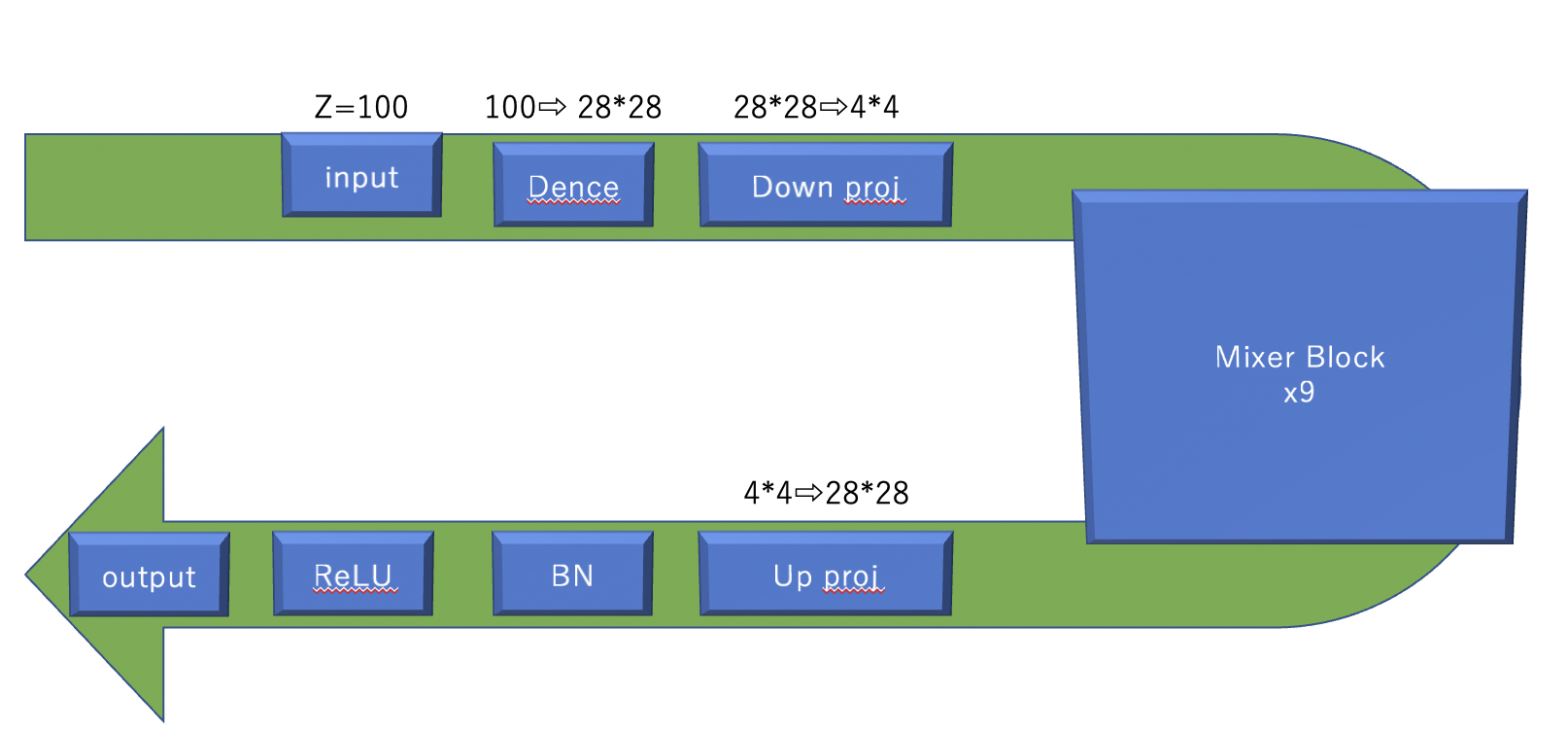
outputはtanhです。-1~1のやつです
- 結果

はい。一応昔かなり詰めた分野なんですが、無理です。これが100epoch目なんですけど..
勾配消失は起きるしうまく描画できないしで地獄のような有様です。
DCGANのほうが余裕で強いという結果になりました。
こっちはmixer = 1の結果です

mixerが少ないほうがマシということで、単純なGANに使うのは無理ですね。
- 考察
MLP-mixerは特徴量抽出機以外の役割を持つことが難しいんじゃないかなと思いました
チャンネルと特徴をこねこねしてるので、最初に持っていたベクトル情報が失われていそうです。
mixer blockに入れる前に畳み込みをすればよかったのかなと。あとこれ転置畳み込みの部分一つだけでupsampleしようとしているの良くないですね。
- 本当の応用
MLP-mixer、精度がカスいみたいになってますが、私はまだまだ未熟なのでいろいろ見逃してる点が多いと思います。
時間ないのでやりませんが、がちでMLP-mixerを応用したいなら、CycleGANのtransform layerの部分をMixer blockに変えるといい感じにできるらしい。CycleGANにはresblock(CNN)が使われてますが、いかんせんおもくてですね。
このモデルのほうが多分軽いんで、実用的なのは多分こっちです。先駆者(論文)いわく、特定タスクにおいては精度も勝てるらしい
論文です→https://arxiv.org/pdf/2105.14110.pdf
使用ファイル一覧だよ
MLP-mixer
MLP-mixGAN
- 所感
"いかがでしたでしょうか"
アドベントカレンダーの時期だったのでやってみたのですが、ひどい有様ですね
まるちれいやーぱーせぷとろんまぜまぜねっとわーくとか響きだけでおもしろそうなのでやってみました
十中八九、実装がおかしいですね。はい。
もう少し修行しますね...
kosakaeが提供しました
宣伝します
twitterもやってるので是非に
https://twitter.com/kosakae256
そのうちcycleganもやるので、ぜひ見てね