昨日は@kuma_nanaさんのアプリケーションロガーモジュールの試作で学んだことでした。結果だけでなく人が学んだ過程は参考になります。
25日最終日の今日はBEAR.SundayでのRESTアプリケーションを作成する手順を紹介します。CRUD "REST" APIではなく、HALメディアタイプを使ったハイパーメディアAPI、つまり本当のRESTアプリケーションの作成手順です。
ワークフロー
下記のように制作進行します。それぞれ簡単に解説します。
- プロファイル作成
- アプリケーションステートダイアグラム、ボキャブラリ作成
- JSONスキーマ作成
- FakeJSON作成
- Fakeサーバー作成
- RESTテスト作成
- 実装
プロファイル作成
最初にプロファイル (RFC 6906)を作成します。
RFC 6906
https://tools.ietf.org/html/rfc6906
プロファイルはアプリケーションで使われる固有の用語をセマンティックディスクリプタ(意味的記述子)として説明します。API利用者がAPIを利用するにあたって理解すべき情報が示されてる、言わばAPIの説明書です。1
以下のようにhttpヘッダーにrel="profile"として含む事ができます。
Link: <http://example.com/profile>; rel="profile"
プロファイルにはリソースで使われる用語の意味、アプリケーション状態遷移、データの内包関係についての情報を記します。
これを見れば、「ToDoリストからToDoアイテムを見る事ができる」などの遷移や、「ToDoリストとは」「ToDoアイテムを作成するためには何を送信すべきか」、それぞれの意味を知る事ができます。しかし詳細は記述しません。リソースの状態や遷移について全ての用語の意味(セマンティックディスクリプタ)を明確にするのが目的です。
これ以降、全ての設計、実装はこのプロファイルに基づいものになるべきです。
このプロファイルはバックエンド、フロントエンド、PO、UX、全ての関係者の共通理解の基盤になります。
プロファイルは本来は人間が読める自由なドキュメントでなんでも構いませんが(例XFN1.1)、JSONやXMLで記述するALPS(Application-Level Profile Semantics)フォーマットを用います。
ALPS
http://alps.io/
ALPSの例
以下はALPSで表現されたブログエントリー記事の例です。
{
"id": "BlogPosting",
"type": "semantic",
"def": "https://schema.org/BlogPosting",
"doc": {
"value": "Blog entry item page"
},
"descriptor": [
{
"id": "articleBody",
"type": "semantic",
"def": "https://schema.org/articleBody"
},
{
"id": "dateCreated",
"type": "semantic",
"def": "https://schema.org/BlogPosting#dateCreated"
},
{
"id": "collection",
"type": "safe",
"rt": "#Blog"
}
]
},
識別子はBlogPostingでtypeはsemantic。BlogPostingがどのようなもので表すかを表しています。2
-
docはドキュメントです。typeを指定してhtmlやmarkdownで記述することもできます。(デフォルトはtext) -
descriptorでBlogPostingに含まれる情報を表しています。 -
articleBodyとdateCreated2つのsemanticがあります。それらの意味はdocのテキストで表されてるのではなく、それらの意味が定義されたボキャブラリサイトの該当ページをdefで指し示されています。 -
ID
collectionで示されたのはsafeつまり安全な遷移3でその遷移を辿るとBlogという(ブログ記事一覧)の状態になるという事がrtから分かります。HTTPでいうところのGETリクエストを表しています。docやdefでその意味が表されていませんが、それはIANAで用意された標準リレーション名だからです。
collection: The target IRI points to a resource which represents the collection resource for the context IRI. [RFC6573]
RFC6578ではitemとcollectionのより詳しい説明があります。4
- IANAで用意された標準リレーション名を使用するときには説明が不要です。(逆にいうとその他の語は全て説明するか説明されたサイトをリンクして明らかにしなければなりません)
つまりこのJSONからBlogPostingとは何で(オントロジー)、それが何を含み(タクソノミー)、またその情報に関係する物は何か(コレオグラフィー)が明らかになります。
それぞれの値の型やそれが必須なものかオプションなものかなどの実装の詳細は表されません。ここは問題空間で、RESTアプリケーションに登場する情報や遷移に全て"セマンティックディスクリプタ(意味的記述子)"としてIDを与えてそれぞれを説明するものです。
上記のJSONは図にするとこのような図になります。
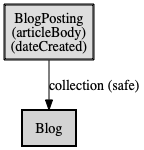
ブログ記事(BlogPosting)は記事(articleBody)と、作成日(dateCreatred)という2つのプロパティを持ちブログ一覧(Blog)にcollenctionという遷移名で安全に遷移3できるする事ができる - という事が分かります。これをアプリケーションステートダイアグラムと言い次のセクションで説明します。
ALPSプロファイル例)
https://github.com/koriym/app-state-diagram/blob/master/demo/profile.example.json
アプリケーションステートダイアグラム作成
ツールを使い、プロファイルからアプリケーションステートダイアグラムの図とボキャブリリストを作成します。
app-state-diagram
https://github.com/koriym/app-state-diagram
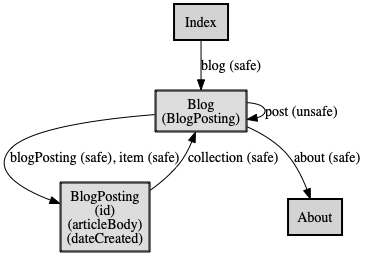
アプリケーション状態はボックスで表され、クライアントが見ているものを示します。URIと対応するものと考えて構いません。URIの代わりにIDが振られ、それぞれの状態で何のデータが含まれるかが示されています。(BlogPostingにはarticleBodyとdateCreateが含まれてる)遷移にも全て名前がついていて、その遷移の属性も示されています。
- safe (安全、GET)
- unsafe (非安全、非冪等、POST)
- idempotent (非安全、冪等、PUT, DELETE)
状態や遷移には設計者が自由に名前をつける事ができますが、それよりもschema.orgやIANA、activity streamなどボキャブラリサイトで定義されている名前を使った方がいいでしょう。説明するのにリンクするだけですみ、共通用語として自分で作った用語よりパワフルです。
設計のポイントはリソースをグラフにする事です。リソースにリソースを含めたリソースグラフを作成します。記述もテストも作成もキャッシュ有効性にも全てにおいてプラスに働きます。
ボキャブラリ
ステート図を理解するためには用語の理解が必要ですが、ボキャブラリリストも出力されます。
新しく入ったメンバーが理解できない用語があったとすると、伝えるだけでなくプロファイルを更新します。次の新しいメンバーに同じ説明を繰り返さなくてすみます。
JSONスキーマ作成
次にプロファイルに示されたそれぞれのアプリケーション状態の情報に基づいてJSONスキーマを記述します。
必ずスキーマに基づいて補完をしてくれるPHPStormなどのエディタを使いましょう。JSONを素で書くのは大変です。
スキーマはデータを構造化して作成しましょう。例えばnameが givenNameとfamilyNameで構成されているならそれを定義したname.jsonを作り再利用します。単なる省力化という意味だけではなくデータに構造を与えます。
プロファイルでセマンティックディスクリプタが説明されてるため、スキーマでそれぞれの用語を説明する必要はありません。
FakeJSON作成
php-json-schema-fakerツールを使ってスキーマからFake JSON(Fakeデータ)を作成します。
php-json-schema-faker
https://packagist.org/packages/koriym/json-schema-faker
このプロセスはスキーマの質を高めるのに重要です。質の高いスキーマからは質の高いFakeJSONが作成され、質の低いスキーマからは質の低いFakeJSONが作成されます。
このFakeJSONでフロントエンドの開発者は開発に入る事ができます。またこのFakeJSONはフロントエンドとバックエンドのコミュニケーションにも用いる事ができます。
Fakeサーバー作成
BEAR.Sundayプロジェクトを作成して、リソースクラスのメソッドにスキーマをアノテートします。
/**
* @JsonSchema(schema="Blog.json", params="rel.blog.json")
*/
public function onGet()
{
fakeコンテキストを作成して、FakeJsonModuleをインストールします。
use BEAR\Resource\Module\FakeJsonModule;
class FakeModule extends AbstractAppModule
{
protected function configure()
{
$this->install(new FakeJsonModule);
// ..
$this->install(new FakeAuthModule); // 例
$this->install(new NullMailModule); // 例
}
}
これで先ほどのonGetメソッドは中身がからでもFakeJSONデータをサーブするようになります。立ち上げたサーバーでフロントエンドの開発者は開発ができるようになります。
この時onGet内がきちんと実装されて正しいデータを返すようになるとそちらが使われます。
RESTテスト作成
まずはAPIのルート/にアクセスするてテストを記述します。200が返ってきたらOKです。ボディの値のテストはここでは必要ありません。JsonSchemaのバリデーションが通っているためです。
class UserSiteTest extends TestCase
{
/**
* @var ResourceInterface
*/
protected $resource;
protected function setUp() : void
{
$injector = (new AppInjector('MyVendor\Api', 'test-hal-api-app'));
$this->resource = $injector->getInstance(ResourceInterface::class);
}
public function testIndex()
{
$index = $this->resource->get('/index');
$this->assertSame(200, $index->code);
return $index;
}
RESTアプリケーションでは状態遷移のテストがテストの中心になり、基本的にクライアント側でURIを組み立てる事はありません。HALでは1度レスポンスを受け取れば次のアプリケーションステートの遷移が_linkで示されてるはずです。
前回で得られたレスポンスと遷移図で示されたリンクを辿って次のステートに遷移します。@depends testIndexで前回のリスポンスを利用してる事に注目してください。
注) ResourceObjectオブジェクトはHALレンダラーがインジェクトされているので(string)でJSONになります。
/**
* @depends testIndex
*/
public function testBlog(ResourceObject $response)
{
$json = (string) $response;
$href = json_decode($json)->_links->{'blog'}->href;
$ro = $this->resource->get($href, []);
$this->assertSame(200, $ro->code);
return $ro;
}
さらに遷移します。
/**
* @depends testBlog
*/
public function testBlogPosting(ResourceObject $response)
{
$json = (string) $response;
$href = json_decode($json)->_links->{'blogPosting'}->href;
$ro = $this->resource->get($href, ['id' => 1]);
$this->assertSame(200, $ro->code);
return $ro;
}
こうやって遷移を次々に進めていきます。テストは遷移図同様、アプリケーションの使い方を示すものとなります。記述は非常に容易です。
このPHP主体のワークフローテストは、実際のHTTPサーバーを使ったテストにそのまま利用する事ができます。
違うのはsetUpのHTTPサーバーを立ち上げる箇所と、PHPのクライントの生成の箇所だけです。ルートからの他の遷移は同じなのでテストクラスをextendsで拡張して再利用しています。
use MyVendor\Api\Workflow\UserSiteTest as Workflow;
class UserSiteWebTest extends Workflow
{
use HttpServiceTrait;
protected function setUp() : void
{
parent::setUp();
$logFile = dirname(__DIR__, 2) . '/docs/log/UserSiteWebTest.log';
$this->resource = new LoggerResource($this->injector, $logFile);
}
public function testIndex()
{
$index = $this->resource->get('http://127.0.0.1:8088/');
$this->assertSame(200, $index->code);
return $index;
}
}
Webドライバを使ったテストのほとんどをカバーする事ができます。CURLを使ったHTTPアクセスのログも記録されます。実際のHTTPリクエストのログはフロントエンドとバックエンドのコミニケーションに使う事ができます。
実装
ResourceObjectを実装します。プロファイルでグラフにしたリソースは@Embedで埋め込みグラフにします。
正しいデータを返すだけではなく@Cacheableと@HttpCacheを使い、リソースの有効期限や公開範囲(public or private)を意識しましょう。
例)
SQL(checkin_by_id.sql)を実行してその結果を返すだけのAPIは以下のようなPHPコードです。checkin_by_id.sqlに$idがバインドされ実行された結果が返ります。SELECTの結果がない時は404が返ります。入出力バリデーションは@JsonSchemaで指定され@Linkでリソースを繋いでいます。
class CheckIn extends ResourceObject
{
/**
* @Query("checkin_by_id?id={Id}", type="row")
* @JsonSchema(schema="checkin.json", params="rel.checkin.json")
* @Link(rel="cc:confirm", href="/checkin-confirm")
*/
public function onGet(string $id) : ResourceObject
{
return $this;
}
用意したのは1つのSQLと2つのスキーマJSONで、単純にSQLを実行して返すだけのこのメソッドにはPHPコードはほとんどありません。
結論
いかがだったでしょうか。ここで紹介する多くのプロセスやツールはBEAR.Sunday以外のフレームワークにも適用できます。
概要の説明なので、これを実戦導入するためには1のプロファイルの詳細やそもそものハイパーメディアAPIの理解は必要です。
しかしこれらの手順は単に理想を並べただけでなく、実際に今年私がチームで数ヶ月取り組んで結果を出したワークフローでもあります。新しい試みは、メンバーへの学習コストやHypemediaAPIの実際の運用で最初多少の不安はあったのですが全くの杞憂でした。メンバーの大部分がこのやり方を気に入り、驚くほどの成果を上げました。
理解共有に重きをおき、設計を中心においた開発は高品質なソフトウエア開発に寄与しましたが、生産性も高くRailsに慣れたエンジニアがざっくり普段の倍以上のスピードで開発できたとコメントしていました。その根拠についてこうコメントしてくれました。
- ローカルサーバーを使わなくても開発できた事 (dockerを使わずローカルサーバーで動かすことことも無しにリリースまでいけました。クラウド環境をモックしたりする必要がないのは利点でした)
- ダイアグラムとボキャブラリによってコミュニケーションコストが激減した事 (複数のチームがやり取りする場合40%程度がコミュニケーションコストになると言われているなか、同じ物を見て同じ用語で開発できたことでそのコストはほとんどゼロでした)
誰のためのものか?
REST(Hypermedia) APIはAPIを単なるリモートデータストレージ操作と考えません。継続的な進化を前提とした、ソリッドなAPI開発をしたいチームにむいていると思います。ボキャブリや遷移、内包関係をしっかり定義したプロファイルをコアに置いたAPI開発はAPIをビジネスの中心に置き、じっくりと育てていく事が可能だと思います。。
2020年にむけて
2015年にv1.0をリリースして以来、BEAR.Sundayはリソース指向フレームワークを名乗ってきました。(Because Everything is A Resource)。これはかなりの程度実現できたと思います。プロダクションで月間数億のアクセスを数年に渡って捌いてきた実績や、一度も後方互換性を失う変更をしていないという実績もあります。以前にもましてAPI駆動開発は開発の中心になりつつもあります。いくつかの大規模なサイトでも使われるようになりました。
今年はHypermedia APIのツールをいくつか作り、こうやって実践でも投入しました。そのBEAR.Sundayをリソース指向を超え、本当の意味でのRESTフレームワークにしたいと思っています。ソフトウェアエンジニアリングの進化は通常、層を成して起こるものです。5 ハイパーメディア/RESTは過去から続く遺産であり、また未来でもあると考えます。
今年も残り後わずかです。21世紀の2回目の10年がもうすぐ終わります。
次の10年が皆様にとって素晴らしい10年になりますように。
Merry Christmas and happy new BEAR!
-
typeはsemanticの他にはアプリケーション状態遷移を表すsafe,unsafe,idemporentの4種類があります。 ↩ -
ちなみにこのRFCの提案者はRESTful Web APIのMike Amundsen氏です。 ↩
-
https://www.infoq.com/jp/articles/overcoming-restlessness/ ↩