tl; dr
- Du, Czarnecki, Jayakumar, Pascanu and Lakshminarayanan (DeepMind). 2018. Adapting Auxiliary Losses Using Gradient Similarity. ArXiv.
- auxiliary tasksの学習から得た教師信号をもとに主タスクの性能を向上するマルチタスク学習において、auxiliary tasksが主タスクに益さなくなったときに、その信号を動的にブロックする方法を提案
- auxiliary tasksと主タスクの損失による勾配が同じような向きを向いていればauxiiliary tasksを使う、逆方向を向いているようであればauxiliary tasksからの教師信号をブロックする。
- ナイーブなマルチタスク学習のベースラインよりは良い傾向(局所最適なauxiliary taskを途中でブロックする)を示すことを確認
- 手法的にはシンプルで、着眼点も妥当に見えるのが、実験が少々不完全
本論文の状況について
本論文はICLR 2019の投稿論文としてOpen Reviewにて公開されましたが、査読結果としてはRejectとなっています。
("4: Ok but not good enough - rejection"が1人、"6: Marginally above acceptance threshold"が2人)
本記事は2018/12/23時点のOpen Review第二版のものをもとに記載しています。
はじめに
マルチタスク学習
近年、マルチタスク学習(Multi-task learning; MTL)が注目されています1。マルチタスク学習では、異なる性質2を持つタスクを1つの学習器でときます。
マルチタスク学習を使うことによって、補タスク(auxiliary tasks)の学習から得た教師信号をもとに興味がある主タスクの性能を向上することができます(e.g. 文から"誰が、誰に対して、何をしたか"と言った情報を抽出する問題を解くために、各単語の品詞を当てるタスクを同時に解く3)。あるいは、いくつかのタスク全てに興味がある場合に、それらのタスクの学習の相乗効果により、各タスクの性能向上を図ります。また、複数のタスクを1つの学習器で解くことによって、学習時間や総パラメータ数を減らせるというメリットもあります。
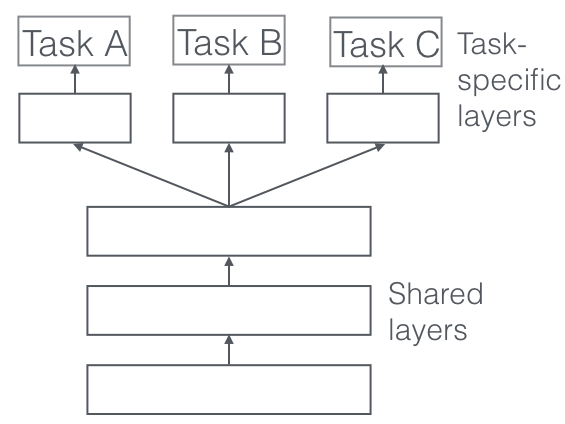
(Picture from http://ruder.io/multi-task/)
マルチタスク学習自体は古くからある概念なのですが、近年の深層学習の興隆により注目を集めています。深層学習では、確率的勾配方とチェインルールにより、様々な形状のニューラルネットワークを学習できるため、例えば上記の図のように1つのネットワークにタスクを複数つけることで、簡単にマルチタスク学習器を作ることができあmす。本研究は、そのような深層学習のパラダイムにおけるマルチタスク学習の学習方法について研究したものになります。
本研究の目的
本研究では、前述した2つのマルチタスク学習の目的のうちの前者、つまりauxiliary tasksの学習から得た教師信号をもとに興味がある主タスクの性能を向上する場合を対象にします。主タスクの性能向上を期待してauxiliary tasksを足したとしても、実はauxiliary taskが主タスクの性能に寄与せず、むしろ学習が阻害される場合があります。あるいは、auxiliary tasksに補助的効果があったとしても、ある程度学習器が各タスクに適合してくると、各タスクの目的が競合してくることがあります。さらに、強化学習のような設定においては、途中で評価関数が変わった場合などにauxiliary tasks一転して阻害要因になってしまうことが考えられます。
本研究では、マルチタスク学習においてauxiliary tasksが主タスクに益さなくなったときに、その信号をうまくブロックする方法を提案します。
方法
提案手法はすこぶるシンプルです。auxiliary tasksと主タスクの損失による勾配が同じような向きを向いていればauxiiliary tasksを使う、逆方向を向いているようであればauxiliary tasksからの教師信号をブロックする、というものです。
まず、auxiliary tasksを伴うマルチタスク学習の損失は一般に下記のように書き表されます。

主タスクの損失に、auxiliary taskの損失を適当な値で重みつけて使おうということです。本研究ではこの$\lambda$ を学習中に動的に変更することを行います。つまり、このような式です。
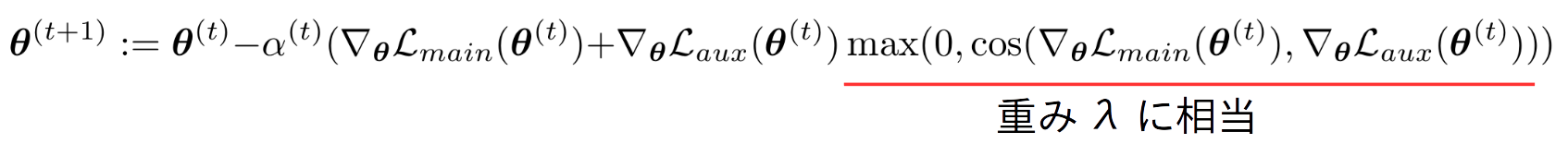
ここで、赤線部が$\lambda$の値に相当します。前述した"同じ向き"というのを表現するために、勾配のコサイン距離を使っています。また、$\max(0, \cdot)$となっているのは、コサイン距離がマイナス(つまり競合する要素がある場合)、その信号をブロックすることを示します。なお、この重みは毎イテレーション(ミニバッチ)ごとに決定します。
著者らはこれをもう少し改変し、次のような重み$\lambda$を使う亜種を提案しています。
\lambda = \text{sign}\left(cos(\nabla_{\mathbf{\theta}}\mathcal{L}_{main}(\theta^{(t)}), \nabla_{\mathbf{\theta}}\mathcal{L}_{aux}(\theta^{(t)})\right)
符号関数signというのは、0以上だったら1、0未満だったら0を返す関数です。つまり、主タスクとauxiliary taskが同じ向きを向いていればauxiliary taskを使う、そうでなければブロックする、ということになります。
証明
提案した更新ルールは必ず$\mathcal{L}_{main}$の局所解に収束することを著者らは証明しています。提案手法によるパラメータの更新量を$\Delta\theta$とおいたときに、
\Delta\theta = \nabla_{\mathbf{\theta}}\mathcal{L}_{main} + \nabla_{\mathbf{\theta}}\mathcal{L}_{aux} cos(\nabla_{\mathbf{\theta}}\mathcal{L}_{main}, \nabla_{\mathbf{\theta}}\mathcal{L}_{aux}) \\
\left<\nabla_{\mathbf{\theta}}\mathcal{L}_{main},\Delta\theta\right> \geq 0
かつ、上の式が0ならば、iffで$\nabla_{\mathbf{\theta}}\mathcal{L}_{main} = 0$、となることが簡単な式変換からわかるためです。局所解に落ち着くまでは必ず勾配が同じ方向を向いている、かつ、局所解でのみ更新量が0になる、ということなので、あとは一般的な確率的勾配法と同じロジックで必ず局所解に収束することが示せます。
なお、証明からわかるように「必ず収束する」というと語弊があり(嘘ではないのですが)、"いつかは収束する(発散はしない)だろうし、収束するときはそれが局所解だよ"程度のものと理解ください。
実験
本研究の実験は微妙です。査読者にもそこを指摘されてRejectされていました。
画像分類
ImageNetの2クラス(A、B)を抜き出してきて、Aとその他、Bとその他という2値分類のマルチタスクとして構成しました。提案手法の効果をみるために、相乗効果が期待される似たクラス(青線)、学習が相反することが期待されるクラス(赤線)を抽出し、実験しました。
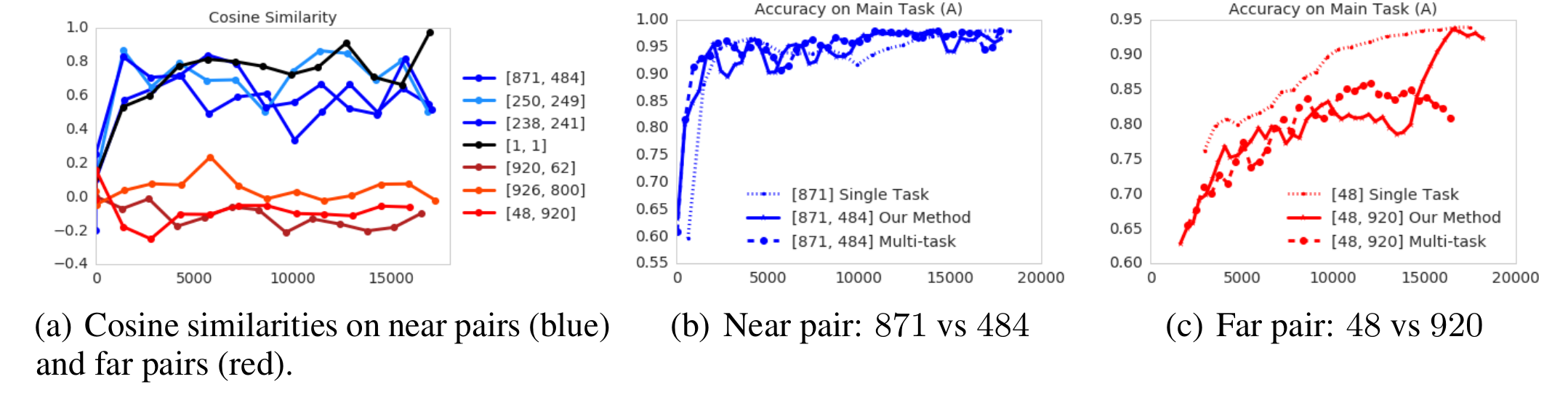
(a)は上記の$\lambda$に相当する量で、赤のクラスでは値がマイナス(相反している)、青のクラスでは値が正になっていました。(c)は相反されることが期待されるクラスで、実際に教師信号が相反していることから各タスクを別々に学習した破線に比べ、マルチタスク(◯付きの線)の性能は劣っています。提案手法も初期はマルチタスクと同様の傾向を示すのですが、あるタイミングで上記のブロッキングがトリガーされ、性能がsingle taskの場合と同程度になっています。
(ただ、いずれの場合もシングルタスクのほうが良いように見えます... これは査読者にも突っ込まれていました。)
強化学習 (toy task)
著者らが提案したtoy taskにて実験をしています。このタスクでは15×15のグリッドに2つのゴール (それぞれ+5、+10の報酬)が配置され、そこで教師エージェントの方策を学習します。次に、+10のゴールをなくした状態で、子エージェントを学習します。子エージェントは教師エージェントの真似 (distillation)4と、普通の方策学習を混ぜて学習します。つまり、不完全な教師エージェントの真似(auxiliary task)と、完全だけど学習に時間がかかる強化学習(主タスク)を混ぜて学習するマルチタスク学習になっています。
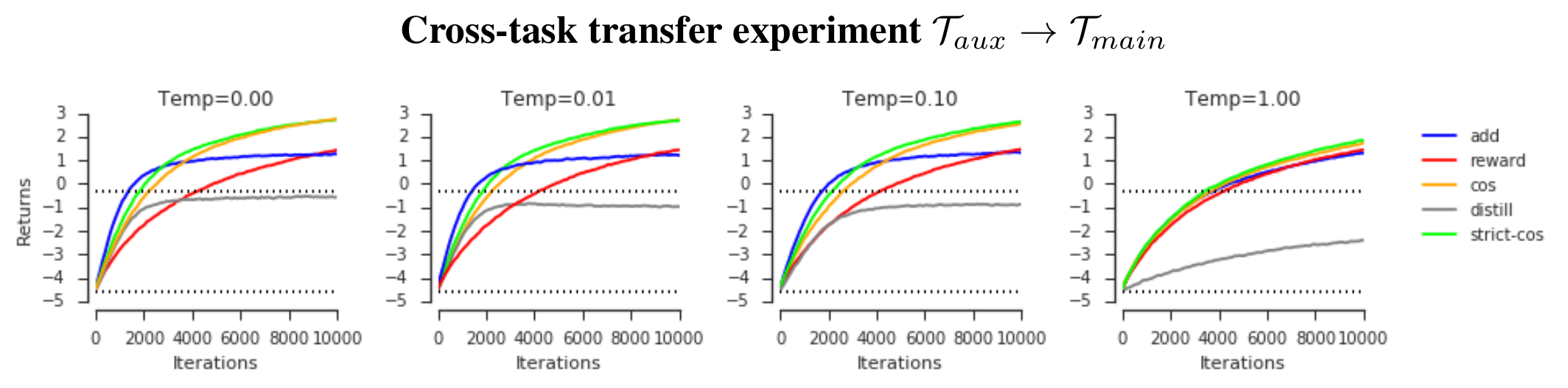
distillは教師エージェント真似だけ、rewardは教師信号だけです。addはナイーブに2つのタスクからの損失を足し合わせたマルチタスク学習のベースラインです。cosは前述したcosine関数で重みつけたもの、strict-cosは前述したsign関数によって重みつけた亜種です。さらに、異なるTempは教師エージェントに加えられた行動のノイズの大きさです(0の場合は完全な方策)。
提案手法は、最初はdistillと同程度の効率で学習できていいますが、どこかのタイミングで強化学習側にきりかえて学習ができていることがわかります。
強化学習
Atariゲームでも前述した強化学習のtoy dataと同様の設定で実験をしています。ナイーブなマルチタスク学習のベースラインよりは良い傾向(途中でauxiliary taskをブロックする)を示すことが確認できました。
コメント
- 実験が不完全なのが気になる。
- ベースラインが貧弱
- 設定が恣意的
- そのベースラインにすらちゃんと勝てているかが判断しにくい結果(もう少し学習時間を伸ばしたら、ベースラインも同程度の性能になっていそう)
- 手法的にはシンプルで、着眼点も妥当に見えるので、今後それらが補完された論文がでることに期待。
図表は論文からの抜粋です。本文に関してはCC0にて公開します。
-
近年のマルチタスク学習の動向については、Ruderさんによる素晴らしいまとめ記事(英語)をご覧ください。 ↩
-
業界レベルでコンセンサスが取れているかは不明ですが、通常、出力の形式が異なる問題をマルチタスク学習と呼び、分類タスクを複数同時に行うマルチラベル学習とは区別します。本論文ではマルチラベル学習もマルチタスク学習の一部として実験をしています。 ↩
-
先週紹介した、Strubell et al. 2018. Linguistically-Informed Self-Attention for Semantic Role Labeling. EMNLP. ↩
-
具体的には各時刻に教師の各行動に対する確率にアクセスできるとして、その確率と自身の行動の確率の交差エントロピーを最小化するように学習します。 ↩