tl;dr
-
自然言語処理のトップ会議であるEMNLP 2018のbest paperの1つ (4つ中)
-
メインタスクのSemantic Role Labeling (SRL) と3つの関連タスク
- SRL: 誰が、誰に対して、何をしたかと言った情報を抽出
- Predicate detection: 述語の特定
- 係り受け解析: 各語の係り受け関係を明らかにするタスク
- POS tagging: 品詞の特定
-
End-to-endで前述した4つタスクを学習/予測するマルチタスク深層学習を提案
- Transformerによる特徴量抽出
- POS taggingとPredicate detectionを、それらのラベルを組み合わせたラベルの分類問題として定式化することで1タスクとして学習
- 係り受け木を表現するattention headを設けたTransformerによる係り受け解析
- 係り受け木の学習・推論に加え、attention headの値を外部係り受け木で置換した上で推論ができる
- POS tagging+predate detectionモジュールと係り受け解析モジュールからの出力をもとに、SRL
-
POS taggingとpredicadte detectionを加えた時点でCoNLL-2005でSotA。係り受け解析モジュールを入れることでさらなる精度向上。
@InProceedings{strubell-EtAl:2018:EMNLP,
author = {Strubell, Emma and Verga, Patrick and Andor, Daniel and Weiss, David and McCallum, Andrew},
title = {Linguistically-Informed Self-Attention for Semantic Role Labeling},
booktitle = {Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing},
month = {October-November},
year = {2018},
address = {Brussels, Belgium},
publisher = {Association for Computational Linguistics},
pages = {5027--5038},
url = {http://www.aclweb.org/anthology/D18-1548}
}
Disclaimer
私は自然言語処理に遅参なので、正直SRLあたりの理解は微妙です1。間違った解釈がありましたら是非ご指摘いただけますと幸いです。
はじめに
SRL、そしてPredicate detection, 係り受け解析、POS tagging
自然言語処理のコアタスクの1つにSemantic Role Labeling (SRL) という問題があります。SRLは、文を入力に、誰が、誰に対して、何をしたかと言った情報を抽出する問題です。もう少し具体的には、文を入力に、述語 (predicate)を特定し、そのpredicateに関係がある語を特定するという問題です。SRLが実現できると、それで抽出した情報をもとに質疑応答を行ったりすることができるようになります。
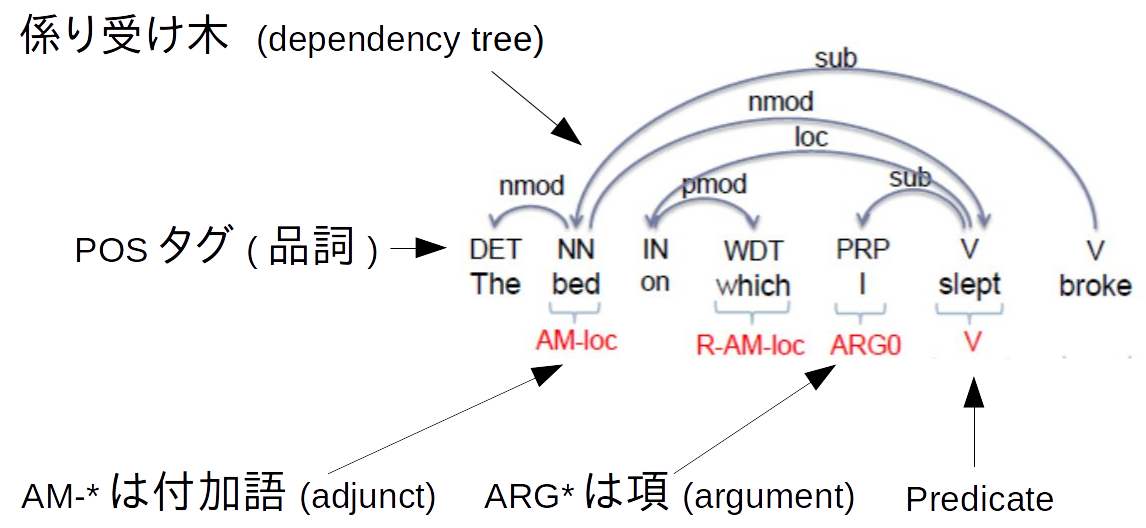
例えば上記の文ではsleepという述語に対し、Iという主語を特定しています。この場合は場所に関する付加語なども特定しています。
SRLに関係が深いタスクにPredicate detection, 係り受け解析、POS taggingがあります。
- Predicate detection: 述語を特定することです。
- 係り受け解析 (Dependency parsing): 各語の係り受け関係を明らかにするタスクです。検索をすればわかりやすい説明がでてきます。
- POS tagging: 品詞を特定することです。
述語がわからなければSRLはできないですし、述語に係る語を特定するために係り受け解析が重要であるのは明らかです。加えてPOS tagは係り受け解析を行うために大きなヒントになります。
SRLの動向
近年は深層学習が非常に流行っていますが、SRLにもその波は当然きています。
- 昔はPOSなどの構文情報をもとにSRLを行っていた。
- 深層学習により、構文情報を使わず、単語列から直接SRLを行うのが流行った(2015~2018)。
- 単語列に加えて構文情報をうまく使うことでさらなる精度向上が図れることがわかってきた(2016〜)。
特に、過去の研究では人手で特定した構文情報と深層学習を(入力データとして)併用すると、性能が大幅に改善することがわかっていました。しかし、構文情報を学習に使った先行研究や、学習済みのパーサーを使った研究では、ごく微量の性能向上にとどまっていたという問題がありました。
そこで、本研究では、End-to-endで前述した4つタスクを学習/予測するマルチタスク学習法を提案します。マルチタスク学習とは、1つのニューラルネットワークで複数のタスクを学習することにより、相乗効果で各タスクの性能を向上するような学習法です。著者らは本手法をlinguistically-informed self attention (LISA)と呼んでいます。
提案手法
全体像
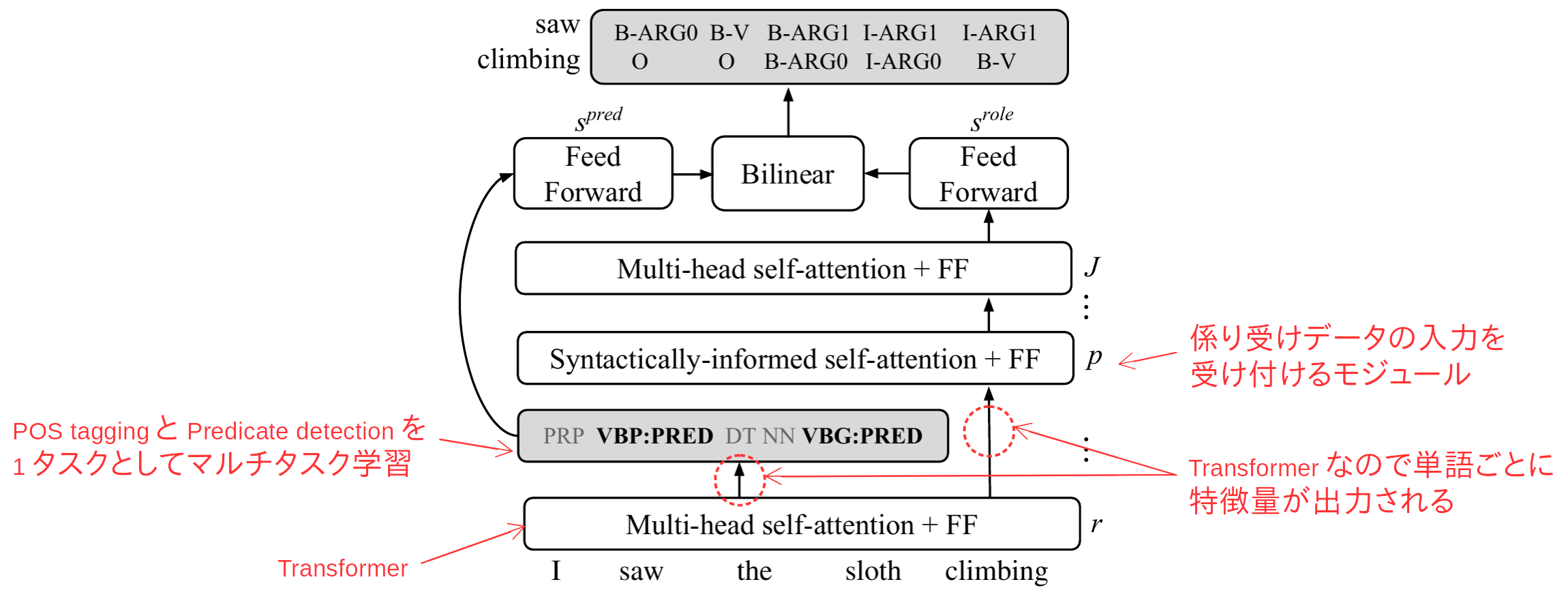
- まず、Transformer (a.k.a. Attention is all you need)で単語列から特徴量を抽出します。
- Transformerの説明は割愛します。本論文の根幹部分もTransformerを前提としているので、これを期に元論文やRyobotさんの解説などをもとに理解しておくと良いと思います。
- 先行研究とは異なり、4タスクの特徴量を共通のモジュールで抽出します。
- Transformerの出力からPOS taggingとPredicate detectionを学習します(後述)。本モジュールの出力はSRLに使われる他、2タスクの学習を特徴量抽出器に伝播させることで間接的に係り受け解析を支援します。
- Transformerの出力から係り受け解析を行います (Syntactically-informed self-attention)。本モジュールが提案手法の肝です。(後述)
- POS tagging+predate detectionモジュールと係り受け解析モジュールからの出力をもとに、SRLを行います。SRLは一般的なBIO分類2を使います。
POS taggingとPredicate detectionのマルチタスク学習
TransformerはN個を入力に、N個の特徴量を出力します。これら特徴量をもとにマルチクラス分類でPOS taggingとPredicate detectionを行います。
本来ならば2つのタスクを学習する必要があるのですが、著者らはちょっとした工夫でこれを1つのタスクに簡略化します。各単語ごとに品詞 (e.g. PRP, VBP, ...)を予測するかわりに、Predicateかどうか×品詞を予測する (e.g. PRP, PRP:PRED, VBP, VBP:PRED, ...)3よう学習します。
なお、学習中は、品詞×Predicateかどうかを学習するとともに、SRLには人手で付与した(真の)値を入力しているとのことです。これはSRLが構文情報を利用することを奨励するためのようです(構文情報の予測の質が低いとSRLの学習で無視される可能性があるためでしょう)。
Syntactically-informed self-attention
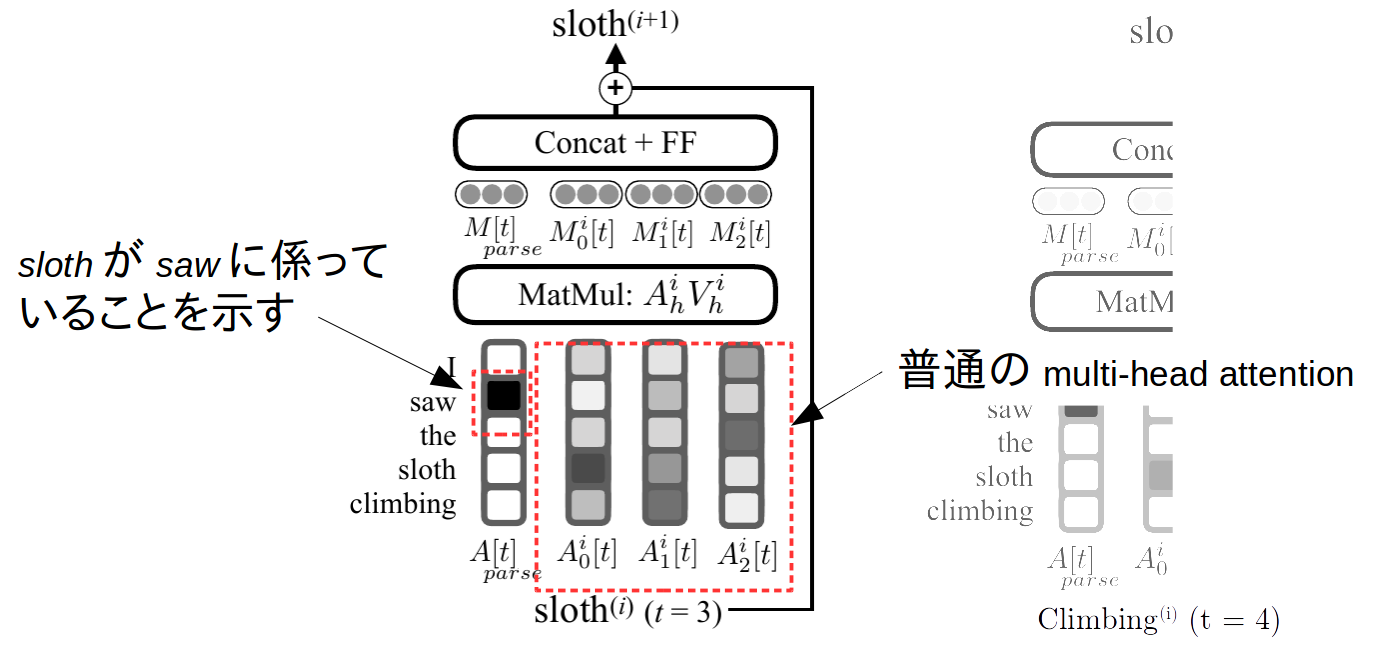
前述したとおり本モジュールが提案手法の肝です。
このモジュールは基本的にはTransformerのmulti-head (self-)attentionです。self-attentionでは全ての単語対単語のattentionを計算しますが、上記の図では、わかりやすさのために、1つの単語に対する他の全単語のattentionを図示しています。本モジュールの右側$A^i_k[t]$ ($k = 0, 1, \cdots$)は普通のMulti-head attentionです。$A^i_{parse}[t]$は係り受け解析に相当する部分です。$A^i_{parse}[t]$の値は係り受け先を示しており、例えば上図では、slothがsawに係っていることを示しています。$A^i_{parse}[t]$には3つの使い方があります。
- 学習時には、人手で付与した(真の)$A^i_{parse}[t]$に値が近くなるように学習する。
- 推定時には、自身で推定した$A^i_{parse}[t]$をもとにSRLを行う。
- 推定時に、仮に真の(あるいは別のパーサーで処理した)係り受け木がある場合、その値で$A^i_{parse}[t]$を置換することで、再学習などなく外部係り受け木を活用できる。
実験
著者らは手法をCoNLL-2005とCoNLL-12で実験していますが、ここではCoNLL-2005の結果だけ紹介します。
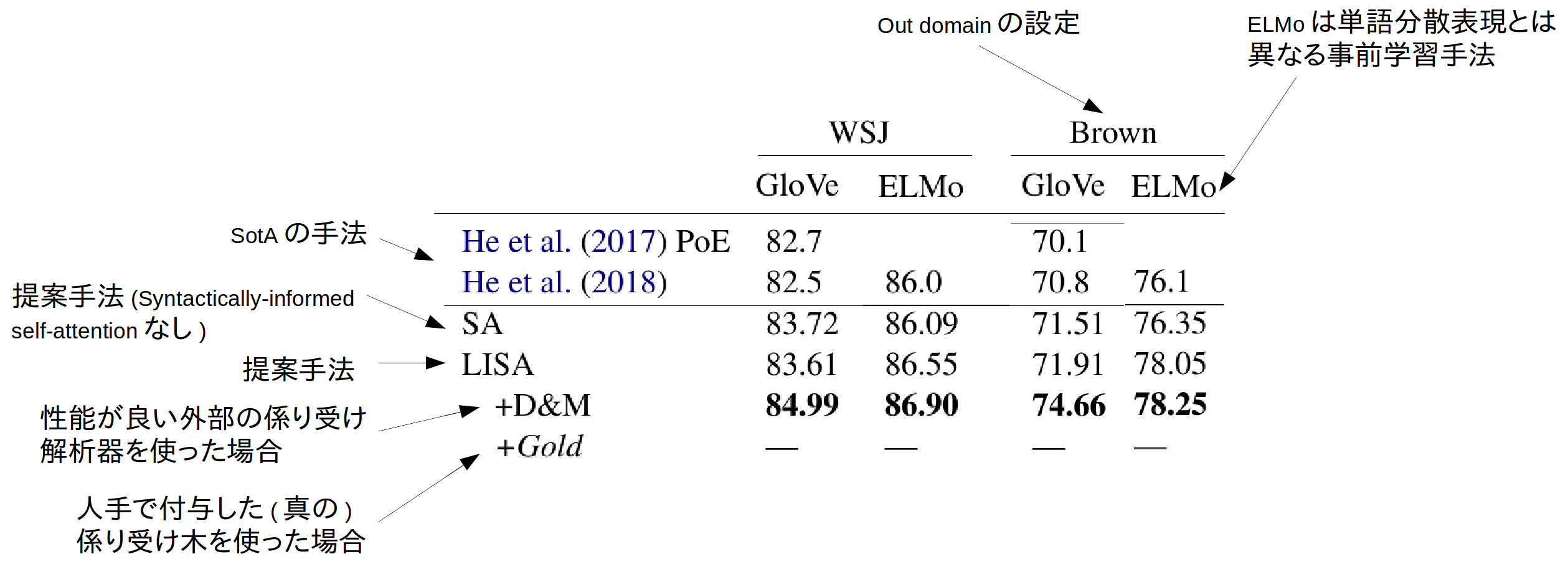
まず、提案手法の肝であるSyntactically-informed self-attentionがない条件 (SA)の時点でSotAとなっています。Syntactically-informed self-attentionを加えたLISAはSAより若干の改善が見られる程度ですが、より性能が高い外部の係り受け解析器を使うことで、SAから更に大幅な精度向上が得られています。
また、本タスクではありませんが、POS taggingと係り受け解析の性能についても記載があります。
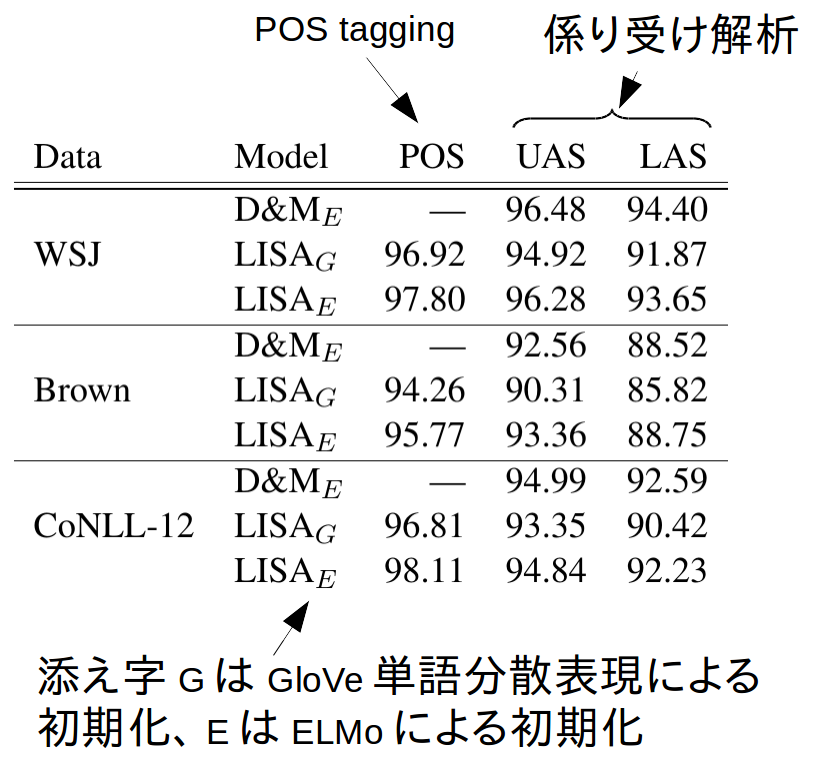
まず、普通に単語分散表現を使った$LISA_{G}$では、係り受け解析に特化したD&Mよりも性能が劣っています。それに対して$LISA_{E}$では性能がD&Mに肉薄しており、上記のSRLの結果でもELMoを導入したことでLISA+D&MにSRLの性能が肉薄したことと符合しています。
コメント
本研究は深層学習の柔軟性 (マルチタスク化しやすい、事前学習などを組み込みやすい) がよく機能した論文と思います。主張も筋が通っており、論文も明快で、さすがはEMNLPのbest paperといったところです。
画像界隈ではベースとなるモデル (VGGとか、Inceptionとか)が広く使われていますが、本研究のようなマルチタスク学習、あるいは最近発表されたBERTのような手法が汎用特徴量抽出器として活用されていく世界がまっているのやもしれません。
本記事の画像は論文より抜粋の上、本記事の著者が編集を加えています。本文ならびに図の編集部分についてはCC0にて公開します。
編集可能な図はこちら。