前書き
最近AWSの勉強をしていてLambda Layerの存在を知りました。
スクレイピングもLambdaで楽にできるのでは?と思いチュートリアル的な記事を色々やってみましたがハマったので備忘録を残します。
チュートリアル?はこちらを参考にしました。
最終的にIaCにしたかったのでServerlessFrameworkも使ってみました。
作成したコードは→touka9029/selenium-lambda-layer
DockerやAWS Cloud9、AWS CloudFormationなど周辺機能については解説しません。
環境やライブラリバージョン
- AWS Cloud9, AMI: ami-081330c4becd75920
- adieuadieu/serverless-chrome, v1.0.0-55, chromium 69.0.3497.81 (stable channel) for amazonlinux:2017.03
- ChromeDriver 2.41
- Lambda Runtime: python3.7
- selenium: 3.141.0
ハマったポイント
その1: Cloud9のpythonバージョンとpipバージョンが異なる
Cloud9のPreferencesからpythonのバージョンはpython3に変更できるのですが、pipのバージョンは2のままでした。
AWS Cloud9 でPython3を使うための設定を参考に、pipのバージョンもpython3を向くようにしました。
その2: serverless-chromeとChromeDriverのバージョン
https://sites.google.com/a/chromium.org/chromedriver/downloads で確認しましょう。
chromium 69.0なのでSupports Chrome versionが69を含むバージョンにします。
いろいろ試した結果、ChromeDriver 2.41に落ち着きました。
メジャーバージョンなら2.44まで動くはずなのですが、タイムアウトしてしまいました。
Chromeとchromiumって違うのでしょうか?(しっかり把握していない)
その3: chrome_optionsが足りていなかった
これが一番大きいハマりポイント。
チュートリアルのオプションだけでは(1年以上前ですが)最新バージョンでは動かず、最終的にはIssueで動いたと報告のあったオプションと見比べて解決しました。
# このオプションが必要だった
options.add_argument('--disable-dev-shm-usage')
その4: Cloud9のEBS容量
ServerlessFrameworkでIaC化している最中にEBSの容量が足りなくなりました。
10GBしかない上、デフォルトでlambci/lambdaのDockerイメージが入っていたり(合計で2~3GBぐらい?)、seleniumのライブラリを作るために使ったlambci/lambda:build-python3.7イメージもそこそこ容量を食うのでほとんど消しました(使う際に再取得すればいいと思います)。
Lambdaのローカルデバッグに使うらしいですがLayerは現時点(2020/01/20)では対応していないみたいです。残念。
dockerhubのドキュメントを見たらを確認したらlayerをマウントできるみたいです。
※後から確認したらCloud9とlambci/lambda:build-python3.7のOSは同じみたいなので直接pip installでも良かったかも。とはいえCloud9以外でも使えるようにするならDockerでしょうか。
実装
- IaC化にあたり、AWS Lambdaで動的サイトのwebスクレイピングをしてtwitterに投稿するbotを作った(続) の実装を参考にさせていただきました。
chrome driverを取得
- まずはheadless-chromiumとChromeDriverを取得します。
- 最後に容量節約のためDockerイメージを削除しています。
# !/bin/bash -x
SERVERLESS_CHROME_URL=https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-55/stable-headless-chromium-amazonlinux-2017-03.zip
CHROME_DRIVER_URL=https://chromedriver.storage.googleapis.com/2.41/chromedriver_linux64.zip
# get headless_chrome
rm -r ./headless_chrome
mkdir -p ./headless_chrome
wget $SERVERLESS_CHROME_URL
unzip stable-headless-chromium-amazonlinux-2017-03.zip -d ./headless_chrome/bin/
rm stable-headless-chromium-amazonlinux-2017-03.zip
wget $CHROME_DRIVER_URL
unzip chromedriver_linux64.zip -d ./headless_chrome/bin/
rm chromedriver_linux64.zip
# get selenium
# /opt/python, または /opt/python/lib/python3.7/site-packages に展開されるように配置する
PYTHON_LIB=python/lib/python3.7/site-packages
rm -r ./selenium
mkdir -p ./selenium/${PYTHON_LIB}
docker run --rm \
-u=`id -u ${USER}`:`id -g ${USER}` \
-v ${PWD}/selenium/${PYTHON_LIB}:/site-packages \
lambci/lambda:build-python3.7 \
pip install selenium -t /site-packages
docker image rm lambci/lambda:build-python3.7
Serverless FrameworkでLambda Layerを作成
-
npm install -g serverlessで Serverless Framework をインストール、以下のYAMLを作成してsls deployします。 - 何度かAWS CloudFormationを触っていたのでとっつきやすかったです。裏でzipに固めてS3にアップロード、CloudFromationのjsonを自動生成してスタック作成しているようでした。
# template docs: https://serverless.com/framework/docs/providers/aws/guide/layers/
service: selenium-lambda-layer
provider:
name: aws
stage: dev
region: ap-northeast-1
layers:
selenium:
path: selenium
description: selenium layer, Runtime python3.7
compatibleRuntimes:
- python3.7
headlessChrome:
path: headless_chrome
description: serverless-chrome v1.0.0-55, ChromeDriver2.41
compatibleRuntimes:
- python3.6
- python3.7
- python3.8
# docs: The name of your layer in the CloudFormation template will be your layer name TitleCased (without spaces) and have LambdaLayer appended to the end.
# 別のCloudFormationスタックから参照させるためにエクスポートする。
resources:
Outputs:
SeleniumLambdaLayerArn:
Description: The ARN for the SeleniumLambdaLayer
Value:
Ref: SeleniumLambdaLayer
Export:
Name: SeleniumLambdaLayer
HeadlessChromeLambdaLayerArn:
Description: The ARN for the HeadlessChromeLambdaLayer
Value:
Ref: HeadlessChromeLambdaLayer
Export:
Name: HeadlessChromeLambdaLayer
マネジメントコンソールで試す
- ここからは結果だけ。
from selenium import webdriver
class Chrome:
def headless_lambda(self):
options = webdriver.ChromeOptions()
options.binary_location = "/opt/bin/headless-chromium"
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--single-process")
options.add_argument("--disable-gpu")
options.add_argument("--window-size=1280x1696")
options.add_argument("--disable-application-cache")
options.add_argument("--disable-infobars")
options.add_argument("--hide-scrollbars")
options.add_argument("--enable-logging")
options.add_argument("--log-level=0")
options.add_argument("--ignore-certificate-errors")
options.add_argument("--homedir=/tmp")
# 参考に無かった以下のオプションが必要だった
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome(
executable_path="/opt/bin/chromedriver",
chrome_options=options
)
return driver
def lambda_handler(event, context):
chrome=Chrome()
driver=chrome.headless_lambda()
driver.get('https://www.google.com')
return driver.title
driver.quit()
- ロール(適当)とメモリ(320MB)、タイムアウト(30秒)を設定してCloudWatchテンプレートでテストしました。
- これだけでも12秒かかるんですね。
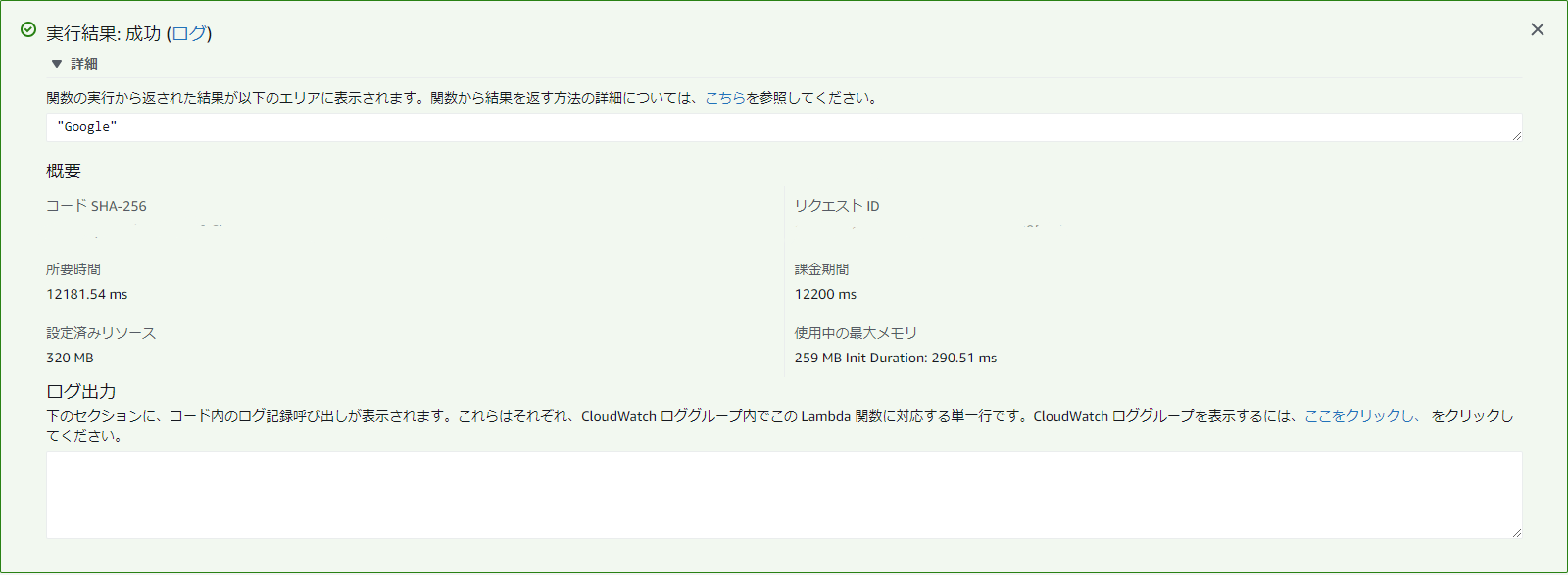
- これだけでも12秒かかるんですね。
終わりに
ハマりポイントが誰かのためになれば幸いです。
完成してみれば Lambda Layer も Serverless Framework も便利ですね。
CloudWatchEventsで定期処理させたり通知飛ばしたりAPI Gatewayと連携させたり色々できそうです。