はじめに
BigQueryクライアントライブラリのgoogle-cloud-bigquery
そのラッパーのpandas-gbqを使う方法を書きます。
※ Googleはgoogle-cloud-bigquery を使って欲しそう。
https://cloud.google.com/bigquery/docs/pandas-gbq-migration?hl=ja
環境
- MacOS X 10.14.5 (Mojave)
- Homebrew 2.2.5
- Google Cloud SDK 281.0.0
- bq 2.0.53
GCPアカウント登録
【画像で説明】Google Cloud Platform (GCP)の無料トライアルでアカウント登録
Google Cloud SDKのインストール
プロジェクト作成
サービスアカウント / サービスアカウントキーの作成
PythonからGCSにアクセスできるうようにするため、サービスアカウント / サービスアカウントキーを作成します。
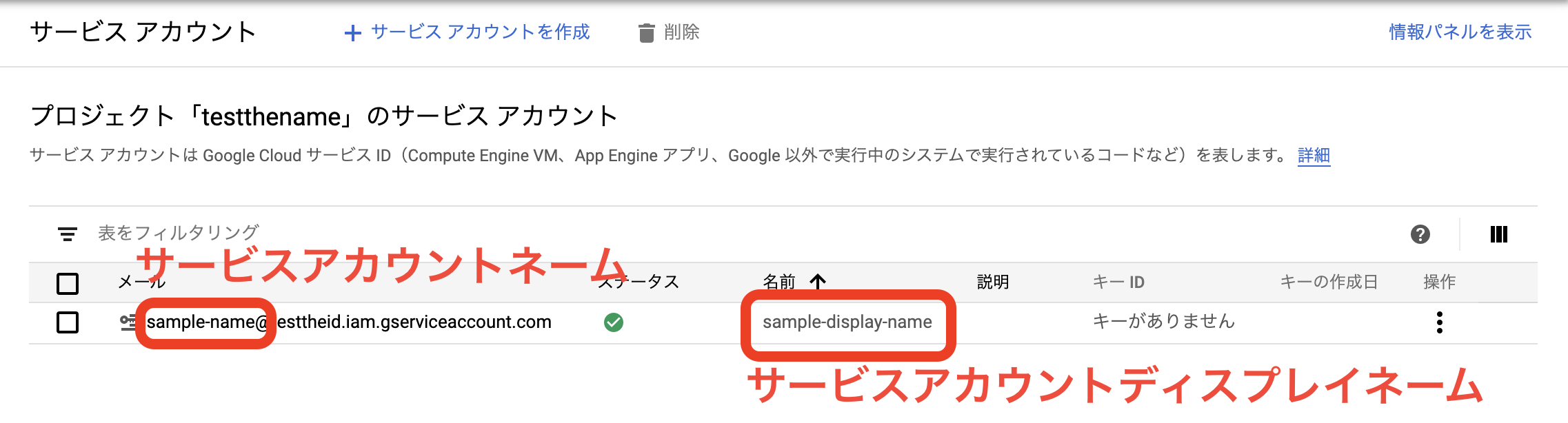
サービスアカウント作成
gcloud iam service-accounts create サービスアカウントネーム \
--display-name サービスアカウントディスプレイネーム \
今プロジェクトに紐付いている権限を確認
gcloud projects get-iam-policy mypj-id
# bindings:
# - members:
# - user:anata_no_address@gmail.com
# role: roles/owner
# etag: BwWeTrntoao=
# version: 1
サービスアカウントへ権限付与
BigQuery管理者の権限を付与
gcloud projects add-iam-policy-binding プロジェクトID \
--member serviceAccount:サービスアカウントネーム@プロジェクトID.iam.gserviceaccount.com \
--role roles/bigquery.admin

roleリスト
再度権限を確認
gcloud projects get-iam-policy mypj-id
# bindings:
# - members:
# - user:anata_no_address@gmail.com
# role: roles/owner
# - members:
# - serviceAccount:mysa-name@mypj-id.iam.gserviceaccount.com
# role: roles/bigquery.admin
# etag: BwWeTz6vIBY=
# version: 1
サービスアカウントキー作成
$ gcloud iam service-accounts keys create ./anata_no_key.json \
--iam-account サービスアカウントネーム@プロジェクトID.iam.gserviceaccount.com
ディレクトリ構成
.
├── anata_no_key.json
└── working/
└── main.py
google-cloud-bigqueryを使う場合
google-cloud-bigquery をpipでインストール
$ pip install google-cloud-bigquery
クエリ結果をDataFrameで読み込む
main.py
import os
from google.cloud import bigquery
from IPython.display import display
# 自ファイルのディレクトリを取得
cwd = os.path.dirname(os.path.abspath(__file__))
# 環境変数に設定
key_path = '{}/../credentials.json'.format(cwd)
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = key_path
project_id = 'project_id'
dataset_id = 'dataset_id'
table_id = 'table_id'
client = bigquery.Client(project=project_id)
sql = f"""
select col1, col2, col3
from {dataset_id}.{table_id}
limit 100
"""
df = client.query(sql).to_dataframe()
display(df)
pandas-gbqを使う場合
pandas-gbq をpipでインストール
$ pip install pandas-gbq
クエリ結果をDataFrameで読み込む
import pandas as pd
# BigQueryからDataFrame形式でロード
project_id = 'project_id'
dataset_id = 'dataset_id'
table_id = 'table_id'
query = f"""
SELECT *
FROM {dataset_id}.{table_id}
LIMIT 10
"""
# dialect='standard' で標準SQLを使用
df = pd.read_gbq(query, project_id, dialect='standard')
display(df)
DataFrameをBigQueryのテーブルへ書き込む
import pandas as pd
# DataFrameをBigQueryへインポート
df = pd.read_csv('path/to/dir/file.csv')
dataset_id = 'dataset_id'
table_id = 'table_id'
df.to_gbq(f'{dataset_id}.{table_id}')