この資料が生まれた理由
本題の前に話を1つ
AWSやMicrosoft Azure、GCP、Oracle Cloud、IBM Cloudのようにパブリッククラウドを使っていればデータ転送料課金は、わかっている人にとっては月々の利用料を考える際に考慮して算出するものですが、データ転送料を考慮せずに費用を考えることが非常に多いようで、出てきた費用に頭を抱える経営者や自治体担当者が増えている模様。
使う前に、SIerの営業が黙っている可能性があるので、SIerの言い分をそのまま信じずに自分で確認する習慣をつけてほしいものです。
生成AIのAPIのトークン数課金
トークンは生成AIで扱う文章の最小単位で、英語であれば1単語、日本語であれば文字や句読点1つ、日本語の場合はひらがなと漢字では数え方が異なるのですが、生成AIサービスのAPIもトークン数で課金することが多いため、入力内容と出力内容で課金が生じます。また使用モデルで課金も生じます。
従って、個人でも法人(専門学校や大学などの教育機関、自治体、企業)でも、トークン数の課金が生じます。生成AIを使う授業で、学生や教員がそれぞれ何文字使ったということを詳細に管理しなければ、正確な予算の見積もりが困難となります。会社も学校の予算、どちらも安く済む分には予定より外れてもなんとかなりますが、増えると面倒なことになります。
経緯
2022年から2023年にかけて、勤務先の教育機関の授業で生成AIについて取り入れてきたところ、当初は個人的に契約しているChatGPTのAPIを自分の研究や学生に使ってもらい、大した課金ではなかったので、あまり問題視していませんでした。
ところが、2023年度の下半期から、必修科目内で学生に生成AIのAPIを使ったシステム開発に取り組んでもらおうと考えた際に、トークン数課金が課題となり、ChatGPTやAzure OpenAIなどの生成AIサービスの活用は断念せざるを得ません。今後、教育機関向けに固定料金があれば別ですが、授業で使いやすい料金体系の生成AIサービスが必要でした。
同時に、学生がいつでも好きな時にお金をかけずに、インターネットに繋げなくても生成AIに触れることができる必要がありました。インターネットに接続する手段がスマートフォンのみという家庭の場合は通信制限が生じることがあるためです。
そこで、llama.cppを使い、トークン数課金に依らない生成AIとAPIサーバーを構築することで、生成AIを使いつつ、生成AI対応のアプリやサービス開発に繋げるようにしました。
VM上で生成AIを使用可能なOpenAI互換のAPIサーバーを用意する
VM(仮想マシン)は、家庭や学生が使うパソコンで利用することができます。Windows環境であればWSLがありますし、MacであればUTMなどがあります。
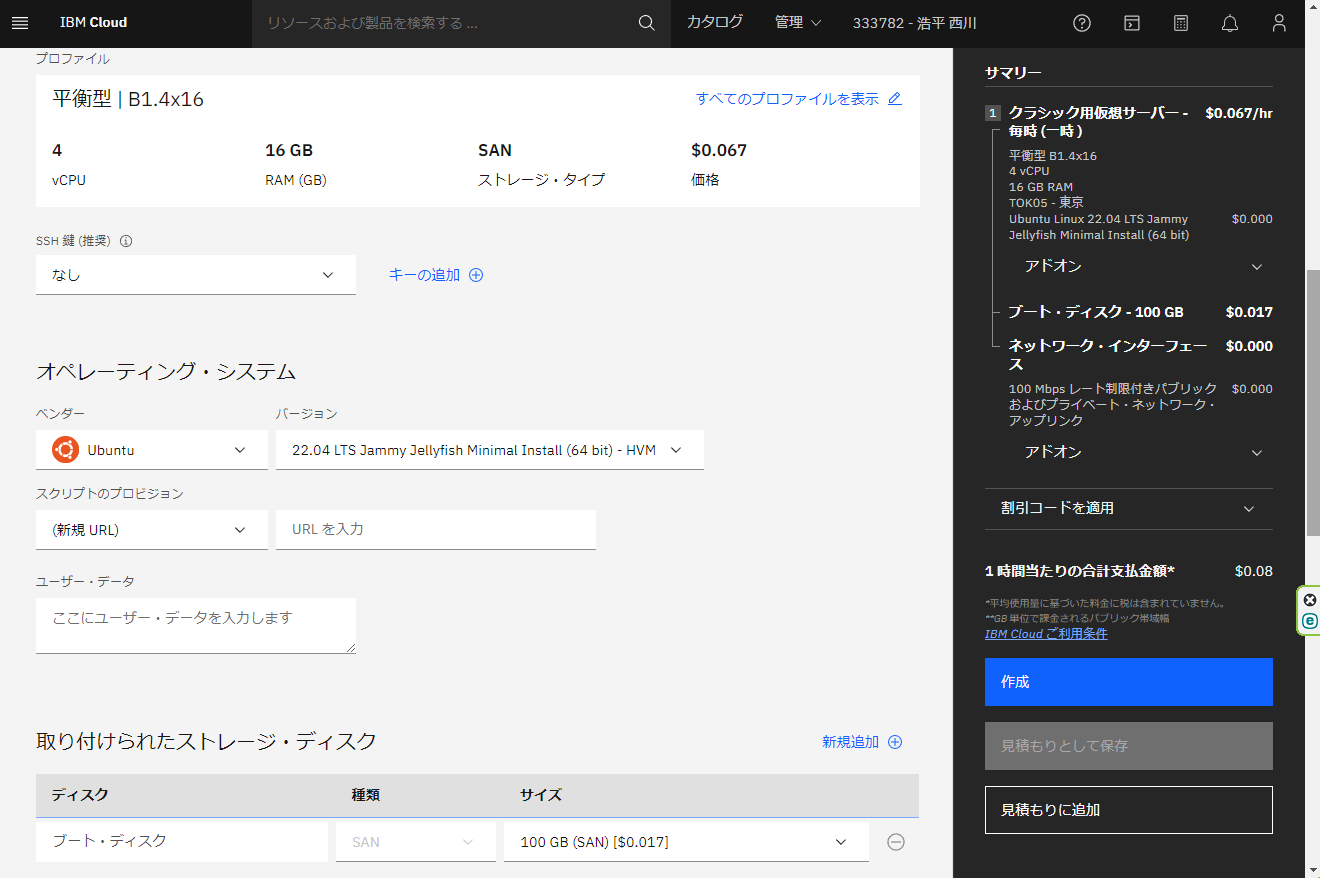
今回は、クラウドサービスからIBM CloudのIBM Cloud Virtual Server for VPC または、IBM Cloud Virtual Server for Classic のどちらでも良いので選びます。短期間の利用で安く済ませたいのであれば、IBM Cloud Virtual Server for Classicの方が良いでしょう。
IBM Cloudの選定理由
IBM Cloudでは、Virtual ServerのようなIaaSには、データ転送のうち、外部から入るインバウンドは無料で、出ていくアウトバウンドには課金されますが無償枠があるので、無償枠で済む範囲に収まるのであれば課金されることなく、費用が予測しやすいというメリットがあります。
VMの構成
VMのスペックは、クラウドサービスではvCPU数やメモリは予算の許す範囲で多い方が望ましいです。パソコンの場合は、CPUコア数やメモリは多ければ多いほど良いです。CPUコア数やメモリが少なくても動くには動きますが、結果が出るまで時間がかかります。
IBM Cloud Virtual Server for Classicの場合
最低限、下記の環境であれば動きます。
- OSは、Ubuntu Server 22.04(2023年12月現在)
- vCPUは、4つ以上。
- メモリは、16GB以上。
2万円未満で買える中古のノートパソコンの場合
多少時間がかかっても良い場合は、特にパソコンの場合は2017年くらいのパソコンでも下記のスペックで動くことは確認済みです。2023年10月頃に2万円未満で購入でいたPanasonic製のLet's note CF-SZ6で確認済みです。
- Windows環境でWSL2を使い、VMとして、Ubuntu 22.04を選ぶ。
- CPUは、2コア以上の第7世代Intel Core i5 以降。推奨は第8世代以降。
- メモリは、8GB以上。
VMにインストール
起動直後は、rootユーザーで、VMにSSH接続して作業します。
作業用ユーザーの作成
rootユーザーで作業することはセキュリティ上や運用上望ましくないので、作業用ユーザーを作成します。
ユーザーの追加
workuser1というユーザーを追加するため、次のコマンドを実行します。
adduser workuser1
sudo権限の追加
管理者としてふるまえるように、sudoのグループに割り当てます。
usermod -aG sudo workuser1
作成した作業用ユーザーで接続し直し
exitコマンドを実行し、ログアウトします。
exit
今度は、作成した作業用ユーザーで、SSH接続して作業を再開します。
タイムゾーンを日本時間に合わせる
Ubuntu環境を整えるため、次のコマンドを実行し、タイムゾーンを日本時間に合わせることを含めて実行します。
sudo timedatectl set-timezone Asia/Tokyo
sudo apt update -y
sudo apt upgrade -y
llama-cpp-python の導入
OpenAI互換のAPIサーバーを利用可能にするために、次のコマンドを実行します。
sudo apt install -y python3-pip python3-venv python3-dev
pip install llama-cpp-python[server]
「python3-venv」は、Pythonの仮想環境を使いたい人向けです。この資料では使いませんが、パソコン上で「llama-cpp-python」を使う場合は、「python3-venv」が合った方が良いでしょう。
実行結果
2023年12月現在は、下記のように出力されます。
Successfully installed annotated-types-0.6.0 anyio-3.7.1 diskcache-5.6.3 exceptiongroup-1.2.0 fastapi-0.105.0 h11-0.14.0 llama-cpp-python-0.2.23 numpy-1.26.2 pydantic-2.5.2 pydantic-core-2.14.5 pydantic-settings-2.1.0 python-dotenv-1.0.0 sniffio-1.3.0 sse-starlette-1.8.2 starlette-0.27.0 starlette-context-0.3.6 typing-extensions-4.9.0 uvicorn-0.24.0.post1
LLMのダウンロード
生成AIの心臓部とも言えば、LLM(大規模言語モデル)です。LLMがないと生成AIとして機能しないので、ここでは日本語LLMを取得します。
今回はダウンロードが短時間で済むように2ビット量子化の「ELYZA-japanese-Llama-2-7b-fast-instruct-q2_K.gguf」を使っていますが、よりまともな文章を生成したい場合は8ビット量子化の「ELYZA-japanese-Llama-2-7b-fast-instruct-q8_0.gguf」の方が良いでしょう。
2ビット量子化の「ELYZA-japanese-Llama-2-7b-fast-instruct-q2_K.gguf」をダウンロードするために、次のコマンドを実行します。
wget https://huggingface.co/mmnga/ELYZA-japanese-Llama-2-7b-fast-instruct-gguf/resolve/main/ELYZA-japanese-Llama-2-7b-fast-instruct-q2_K.gguf
APIサーバーの起動
次のコマンドを実行し、ダウンロードした日本語LLMを使って、OpenAI互換のAPIサーバーを起動します。
python3 -m llama_cpp.server --host 0.0.0.0 --model ELYZA-japanese-Llama-2-7b-fast-instruct-q2_K.gguf
パソコンで同様の仕組みを構築している場合は、この段階まで進めば、インターネットに接続していなくても、生成AIと生成AIをAPI経由で呼び出すAPIサーバーを利用することができます。
実行結果
2023年12月現在は、下記のように出力されます。
llama_new_context_with_model: n_ctx = 2048
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 1
llama_new_context_with_model: KV self size = 1024.00 MiB, K (f16): 512.00 MiB, V (f16): 512.00 MiB
llama_build_graph: non-view tensors processed: 676/676
llama_new_context_with_model: compute buffer total size = 159.32 MiB
AVX = 1 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 |
INFO: Started server process [18353]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
上記が表示されれば起動確認は終了です。「Ctrl+C」キーを押して停止します。
llama.cpp server のsystemd 対応
OpenAI互換のAPIサーバーであるllama.cpp serverを、systemctlで制御できるようにします。systemctlで制御できるようにすることで、自動起動、開始、停止、再起動を容易に制御できるようになります。
unit定義ファイルの作成
次のコマンドを実行します。
sudo nano /etc/systemd/system/llamacppserver.service
下記の内容を記述します。記述後、「Ctrl+x」キーを押し、yキーを押して保存します。
[Unit]
Description=llama cpp server
After=network.target
[Service]
Type=simple
User=workuser1
Group=workuser1
WorkingDirectory=/home/workuser1
ExecStart=python3 -m llama_cpp.server --host 0.0.0.0 --model /home/workuser1/ELYZA-japanese-Llama-2-7b-fast-instruct-q2_K.gguf
Restart=on-abort
[Install]
WantedBy=multi-user.target
systemctlコマンドによるAPIサーバーの起動と自動起動の有効化
次のコマンドを実行し、APIサーバーを起動します。先ほどと違って、systemctl を使っています。
sudo systemctl start llamacppserver.service
次に自動起動を有効化します。自動起動により、VMを再起動した場合にAPIサーバーを起動するようになります。次のコマンドを実行します。
sudo systemctl enable llamacppserver.service
起動の有無を確認したい時は、次のコマンドを実行します。確認後「q」キーを押せば、次のコマンドを実行できるようになります。
sudo systemctl status llamacppserver.service
生成AIおよびAPIサーバーの動作確認
Webブラウザで、http://IPアドレス:8000/docs にアクセスします。IPアドレスの部分は、VMに割り当てられているパブリックIPアドレスに読み替えてください。
ドメインを割り当て済みの場合は、IPアドレスの部分を独自ドメインに置き換え、かつNginx等のリバースプロキシを使い、https接続にしても良いでしょう。
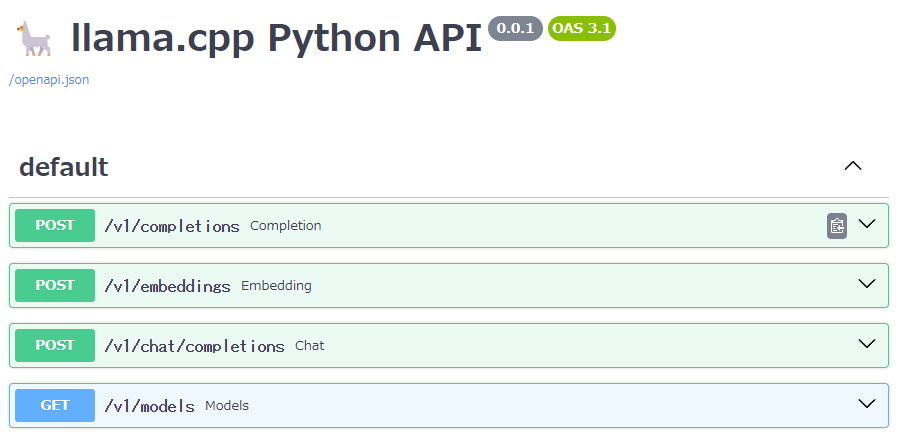
「chat」と表示されている部分をクリックします。

「Try It out」をクリックします。
「Request」の実施
下図のように、「Request body」にJSON形式で質問文を入力します。
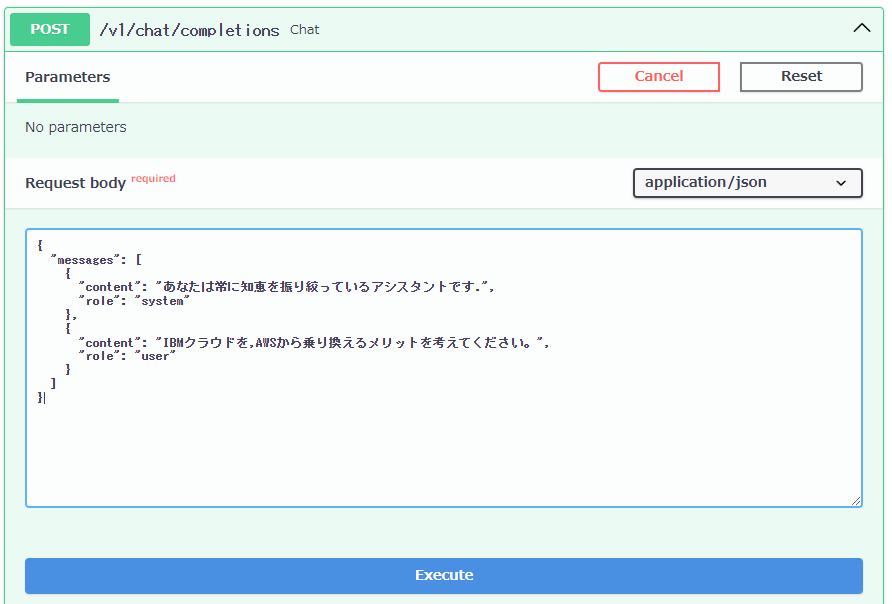
質問文の例文はこちらです。
{
"messages": [
{
"content": "あなたは常に知恵を振り絞っているアシスタントです.",
"role": "system"
},
{
"content": "IBMクラウドに,AWSから乗り換えるメリットを考えてください。",
"role": "user"
}
]
}
入力後、「Execute」をクリックします。この作業を「Request(リクエスト)」と言います。
「Response」の取得・表示
数分後、結果が返ってきます。APIから届く結果を、「Response(レスポンス)」と言います。
「Responses」の表示では、「Curl」の欄に「Request」を「Curl」コマンドで行う場合についての作法が表示されます。「Curl」コマンドを使えば、WebブラウザでアクセスしなくてもLLMを用いたAIに文章を作らせ、結果を取得できます。
curl -X 'POST' \
'http://IPアドレス:8000/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"messages": [
{
"content": "あなたは常に知恵を振り絞っているアシスタントです.",
"role": "system"
},
{
"content": "IBMクラウドに,AWSから乗り換えるメリットを考えてください。",
"role": "user"
}
]
}'
「Request URL」には、「Request」のJSON形式の質問文の送付先となるエンドポイントが表示されています。
http://IPアドレス:8000/v1/chat/completions
「Server response」には生成された結果が表示されています。今回の質問文に対する生成結果は下記の通りです。
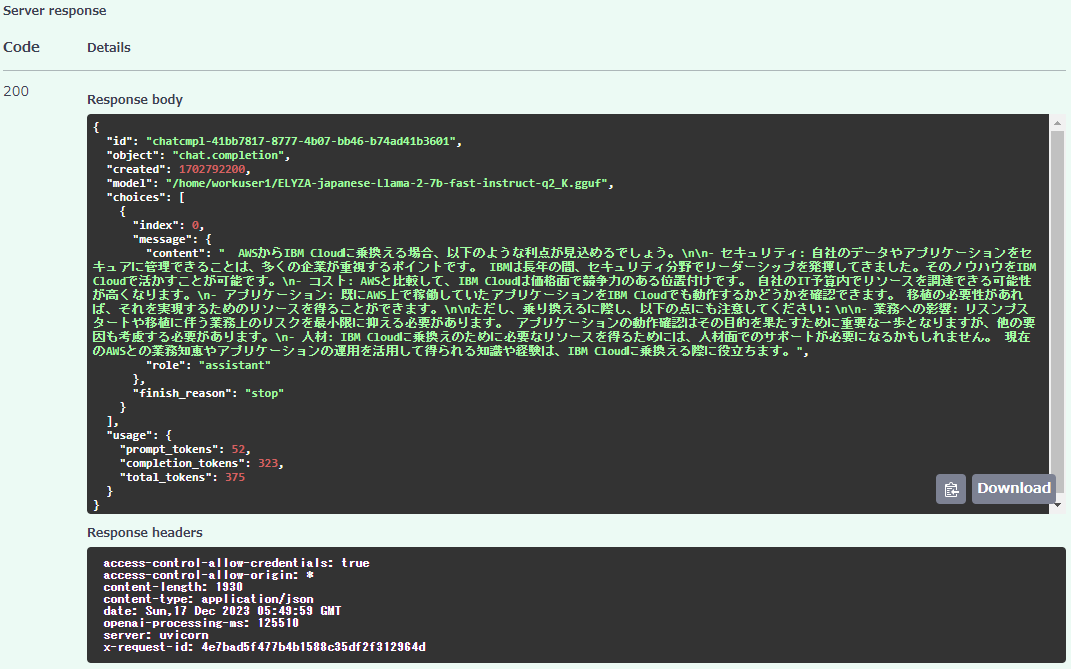
まとめ
ここまで実施したことで、API経由で生成AIを制御できることを体験することができたはずです。この先は、APIを使って生成AIアプリを作ることになります。では、どんなツールを使えば作れるのかですが、一例としては、AIやIoT、あるいはデータサイエンス等でおなじみの「Node-RED」を使うことで、短時間で作ることができます。
「Node-RED」を使って、単純なチャットUIを作っても良いですし、「Slack」や「Mattermost」のようなコミュニケーションシステムであれば、「Webhook」を使うことで、「Node-RED」経由で生成AIとAPIサーバーを使った仕組みを構築することも可能です。
この資料では、タイトルのとおり低予算で生成AIとAPIサーバーを構築することに注力しました。
また、ほぼ同じ仕組みを家庭用のパソコンにお金をかけずに構築することもできるので、生成AIに使ったアプリ開発にチャレンジしたい人には良いでしょう。
参考資料
- llama-cpp-pythonのオンラインマニュアル
- REST APIとは << REST API をご存知ない方は読んでおきましょう。
- Node-REDとローカル生成AIの連携 << Node-REDと使って今回と同様の仕組みを連携する方法について解説しています。
最後に
2022年度に高校までの情報教育必修化が行われましたので、高校卒業時点で必修科目の「情報1」の範囲である、情報技術を使った問題解決、コンピュータやネットワークの仕組み理解、情報デザイン、基礎レベルのデータ分析やプログラミングなどを学習済みということになります。
日本の情報技術やデジタル技術を活用する人は、昔から大学では人文系学部だった人、高校卒業後に就職して働きながら技術力を身に付けた人も多くおり、情報技術やデジタル技術の習得や活用に、学歴は無くても構いませんし、文系理系も関係ありません。
一昔前の状況とは異なり、ここ数年は事務職であってもノーコードツールで在庫管理システムを開発したり、営業職でもデータ分析やAIを使うことを要求されることは珍しくありません。つまり、誰もが自然と技術者になっています。
社会人は、特に企業に属していれば本人の向いている向いていない、やりたいやりたくないの意思は時には否定され無視されるものですから、働いて生活していく以上、生成AI含めてデジタル技術や情報技術には慣れ親しんでいた方が、社会を渡っていくには便利と言えます。