前置き
この投稿は画面の話だけです。画面のための設定の前、前提となるNode-REDやWatson Discoveryについて準備が必要です。
準備.Node-RED
Node-RED環境が必要です。もしあなたがクラウド環境や自宅内にサーバー、Raspberry Piなどをお持ちでない場合は、Node-RED環境を無料で手に入れる手段として、IBM Cloud ライト・アカウントが最も手軽です。
- IBM Cloud ライトアカウントでNode-REDを準備する場合 >> 2020年4月 Node-REDハンズオン (Node-RED環境の準備)
- その他の環境でNode-RED環境を用意する場合 >> Getting Started:Node-RED日本ユーザー会
- Node-REDの基本操作 >> ユーザーガイド:Node-RED日本ユーザー会。書籍が欲しい人は、Node‐REDユーザーグループジャパンが書いている本があります。
準備.Watson Discoveryについて
Watson Discoveryについてまだご存知ない方は下記をご覧ください。Watson Discoveryを知るための資料として有用です。
IBM Dojo: Watson Discovery を使ったAI検索体験の資料 << 「資料」をクリックすると移動します。Watson Discoveryを作成するロケーションは「ダラス」がオススメです。
準備.独自のデータコレクションの作成
上記の資料をもとに、Watson Discovery内に、あなた用のデータコレクションを作成してください。
データコレクションにアップロードするドキュメントは、下記を使ってください。AI検索画面らしく振る舞うために、URLなどの情報が入ったJSONデータを使用します。
sample-docs.json << sample-docs.jsonのデータ構造は次のようになっています。

「title」「url」「text」「date」の4項目からなるJSONデータです。
Watson Discovery内にデータコレクションを作成し、sample-docs.jsonをアップロードすると下図のように6つの文書が認識されます。

データコレクションに格納された文書が検索対象になります。
フローの解説
1.サンプルフローの場所
Node-REDでは、作成するプログラムのことを「フロー」と言います。フローはJSON形式で保存することができます。JSON形式のサンプルフローは、Github内のWatson Discovery AI検索 UIにあります。次の説明をご覧ください。
2.サンプルフローの読み込み手順
- flows-discoverysearch-ui.jsonに新規タブでアクセスし、「Raw」ボタンをクリック。
- 全選択(Windowsを利用の場合は、Ctrl+Aキー)を行い、その後コピーを実行。
- Node-REDにアクセスし、画面右上の「三」→「読み込む」をクリック。
- 「フローをクリップボードから読み込み」に、コピーしておいた、「flows-discoverysearch-ui.json」の中身を貼り付け。
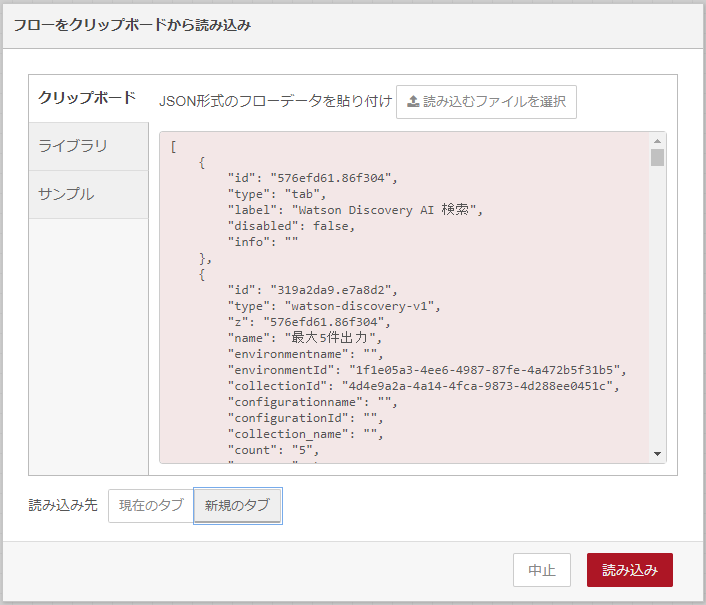
- 「読み込み先」に「新規タブ」を選択。
- 「読み込み」をクリック。
- 「Watson Discovery AI検索」タブが表示される。
読み込み後のNode-RED上のフロー
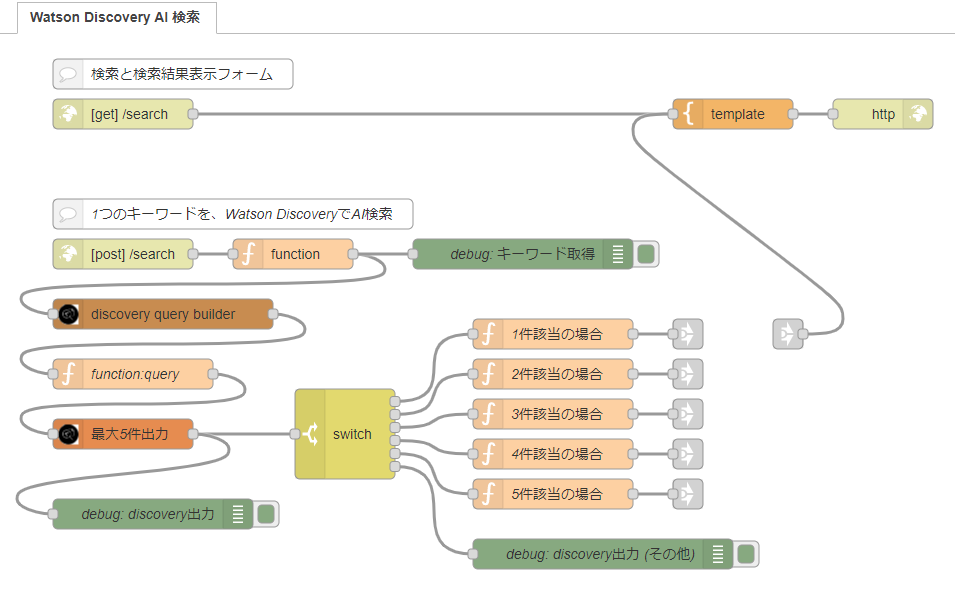
3.サンプルフロー内のノード解説
discovery query builder
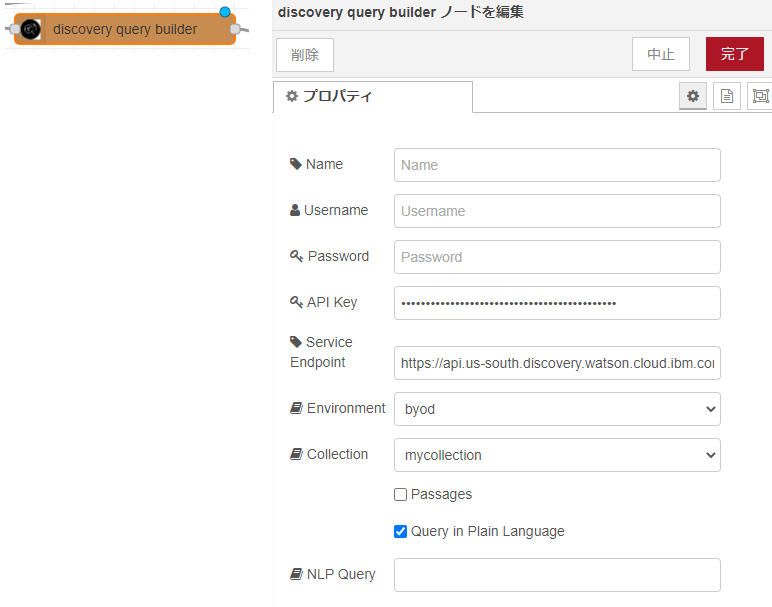
discovery query builderノードを使用しています。
API KeyとService Endpointを入力します。Environmentは「byod」、Collectionには作成したデータコレクションを選びます。
ここで言うAPI KeyとService Endpointは、Watson Discoveryを有効化すると表示される「管理」の「資格情報」のAPI鍵とURLのことです。値は人それぞれ異なります。「完了」をクリックします。
function:query
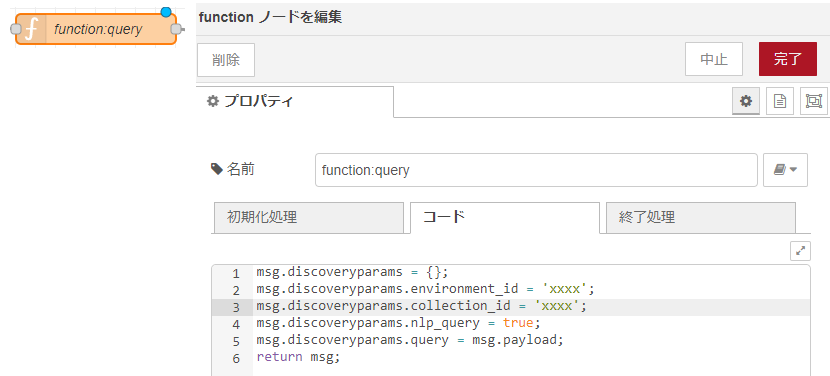
functionノードを使用しています。
Watson Discovery内に作成したあなたのデータコレクションにアクセスし、画面右上の「api」と表示されているアイコンをクリックします。

「Environment ID」と「Collection ID」をそれぞれコピー、ノード内に貼りつけます。図のxxxxの部分が各自の「Environment ID」と「Collection ID」に読みかえてください。値は人それぞれ異なります。貼り付け後、「完了」をクリックします。
最大5件出力
discoveryノードを使用しています。Watson Discoveryに検索キーワードを渡して、結果を出力する際の件数も指定しています。サンプルでは5件としているだけで、10件にすることも可能です。但し、「Number of documents」の数値を変えることと、switchノードとその出力先のノードを変更する必要があります。
API KeyとService Endpoint、Environment IDとCollection IDの4つの値を入力します。「完了」をクリックします。図に入っているAPI KeyとService Endpoint、Environment IDとCollection IDの4つは各自の値に置き換えてください。人それぞれ異なります。
switchノードとその出力先
1つ前の「discoveryノード」で、「Number of documents」の数値を5としていますので、swtichノードからの出力先となる「1件該当の場合」や「2件該当の場合」といったノードでは、5件分のノードを設定しています。
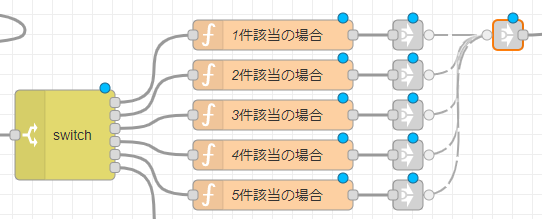
たとえば、「2件該当の場合」のノードは、funtcionノードを使っており、次のようになっています。Node-REDの画面で実際に確認してみてください。
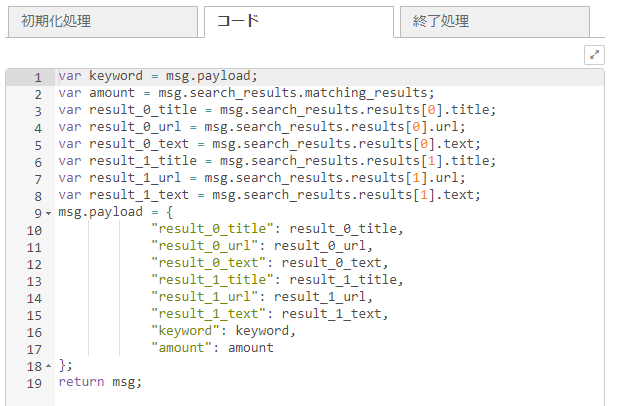
template
templateノードを使用しています。Webブラウザで使用する実際の検索画面のデザインがこちらになります。
動作確認
Node-REDの画面右上の「デプロイ」をクリックします。クリック後、Webブラウザで、検索画面にアクセスします。
検索画面にアクセス
Node-REDのURLが次のようになっている場合、Webブラウザで新しくタブを開き、Node-REDのURLをコピーして、/red を /search に変更してアクセスします。
https://node-red-xxxxx-xxxx-xx-xx.mybluemix.net/red
これが、検索画面のURLとして下記のようになります。
https://node-red-xxxxx-xxxx-xx-xx.mybluemix.net/search
キーワード検索を実行
検索画面にアクセスした直後は、次のように表示されます。
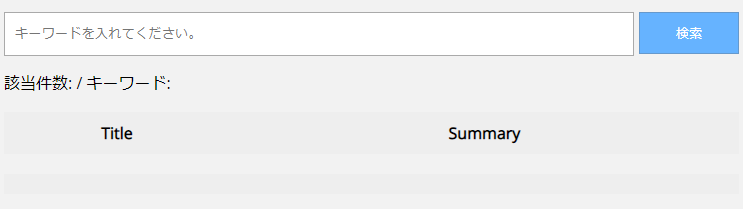
「キーワードを入れてください」の部分に、「クラウド」や「計装」といった、キーワードを入れます。検索可能なキーワードは、Watson Discoveryのデータコレクションにアップロードした文書データに記載のテキストデータと、Watson Discoveryによって、エンリッチメントとして付与されたメタデータが対象になります。たとえば、「計装」というキーワードは、今回使用したドキュメント(sample-docs.json)には書かれていないキーワードですが、Watson Discoveryが判断してエンリッチメントを行ったメタデータになります。

Titleをクリックすると、関連するWebサイトが表示されます。
カスタマイズ例
今回、データコレクションにアップロードしたJSONファイル内の項目で「date」が未使用なので、dateのデータを表示するようにカスタマイズすることができます。カスタマイズする場合は、「3.サンプルフロー内のノード解説」で扱った「switchノードとその出力先」と「template」の両方のノードを改修する必要があります。
備考
手軽にNode-REDだけで実施したものを記録として残しました。