はじめに
今回は生成AIがやり取りを仲介するランダムチャットアプリのプロトタイプを作ったので、それを題材にLangChain、Gemini、ベクトル検索の使い方を学んでいきます。
下記が実際に作ったものです。
https://kawarini-tsutaerune.vercel.app/
この記事の対象者
- LangChain, ベクトル検索を使った開発に入門したい人
- 個人開発で生成AIを使ってみたい人
※ AIやエンベディングに絡んだ部分のみが解説の対象となります。
目標成果物
- マッチングボタンで、興味が似ている人とマッチします
- @マークで相手を指定してメッセージを送ると、AIがメッセージの要約や返信のサジェストに書き換えたうえで、相手に送信します
- 安心してランダムチャットを楽しめるように、ネガティブな表現は自動で変換します
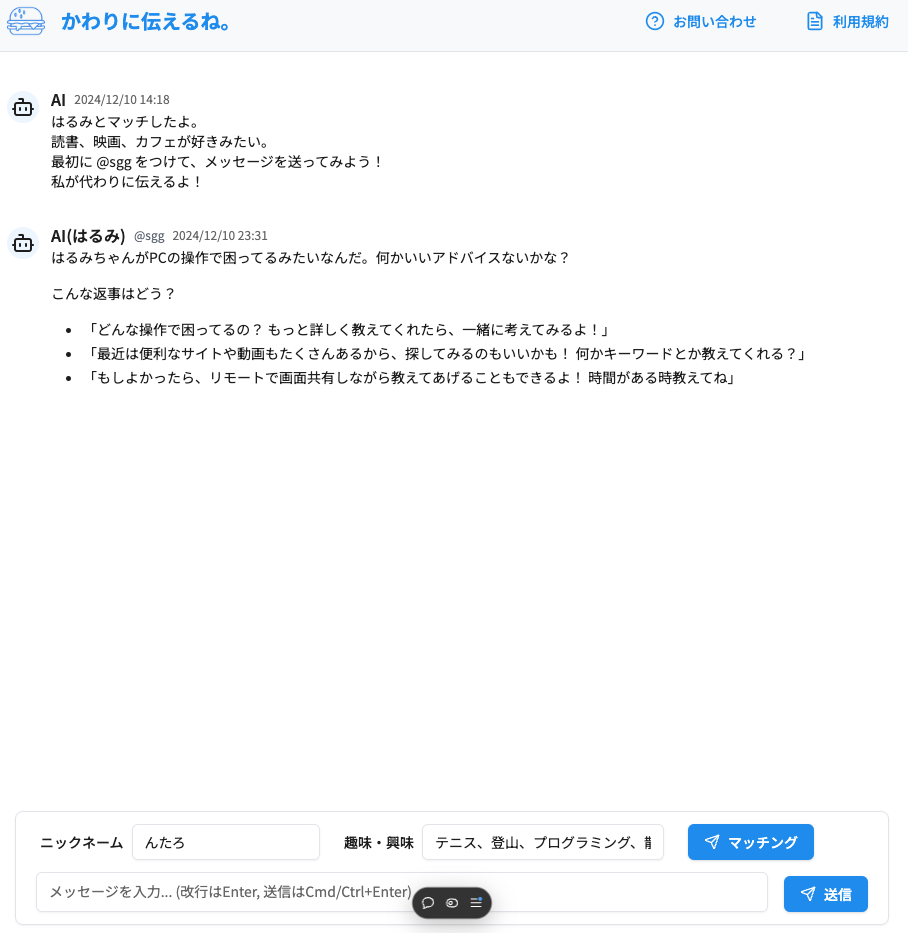
マッチング機能(ベクトル検索)
まず、マッチング機能から実装していきます。
ユーザーが入力した興味関心と近いユーザーをDBから検索して、マッチングします。
今回はベクトル検索によって、興味が近い人を抽出します。
Supabaseについて
ここでSupabaseについて軽く触れておきます。
Supabaseは、Firebaseを代替するBaaSとして生まれました。特徴としては、なんといってもPostgresが使えます。しかも、DBとのリアルタイム通信もあるので、FirestoreのようにDBが更新されたら、フロントも更新するということが簡単にできます。
ユーザー認証、ストレージ、エッジファンクションなどFirebaseにある機能はたいていあります。ただし、Host機能はないので、今回はVercelを使いました。
従量課金制で無料から始められます。
ユーザテーブルを作成する
下記のようなSQLでSupabaseにテーブルを作成します。
interests_embeddingカラムが興味をベクトル形式で保存するカラムとなっています。
vector拡張を入れると、ベクトル型が扱えるようなります。
-- Enable required extensions
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
CREATE EXTENSION IF NOT EXISTS vector;
-- Users table
CREATE TABLE public.users (
id UUID PRIMARY KEY REFERENCES auth.users(id),
interests_text text,
interests_embedding vector(768),
created_at timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
);
興味をベクトル化
Geminiを埋め込みベクトル作成に使う場合には落とし穴にあります。
結論から言うと、Generative Language APIのエンベディングモデルは英語専用のため日本語のエンディングには使えません。
よって、Vertex AI APIの多言語エンベディングモデル「textembedding-gecko-multilingual@001」を使う必要があります。
下記のコードでエンベディングができます
※ 多言語モデルは、東京リージョンでは使えないので、locationにご注意ください。
const embeddings = new VertexAIEmbeddings({
model: 'textembedding-gecko-multilingual@001',
location: 'us-central1',
});
const embedding = await embeddings.embedQuery(text);
VertexAI APIについて
-
Generative Language APIがAIを簡易に使える軽量なAPIであるのに対して、VertexAI APIはエンタープライズ用の包括的なAIプラットフォームのAPIとなります
-
Generative Language APIは認証がAPI Keyだけで済むのに比べて、VertexAI APIはサービス アカウントが必要になるなど、ひと手間が必要です。詳しくは以下をご覧ください
https://qiita.com/sho_hei_0990/items/9688d1be80b079660573 -
VertexAI APIはGenerative Language APIと併用する場合は注意が必要です。環境変数にGOOGLE_API_KEYがある場合にVertexAI APIがエラーを吐くためです。詳しくは以下をご覧ください
https://github.com/langchain-ai/langchainjs/issues/5000
ベクトル検索用のSQLファンクションを作成する
下記のSQLファンクションを外部から呼び出すことで、interests_embeddingカラムが近いユーザ同士を抽出します。
引数の query_embedding は対象ベクトル、match_threshold はどの程度ベクトルが近い場合に検出するのかの閾値、match_count はマッチするユーザの最大数です。
ベクトルの近さはコサイン類似度で測ります。
CREATE OR REPLACE FUNCTION match_users (
query_embedding VECTOR(768),
match_threshold FLOAT,
match_count INT,
)
RETURNS TABLE (
id UUID,
similarity FLOAT
)
LANGUAGE plpgsql
AS $$
BEGIN
RETURN query
SELECT
users.id,
(users.interests_embedding <#> query_embedding) * -1 AS similarity,
users.created_at,
FROM users
WHERE
users.interests_embedding IS NOT NULL
AND (users.interests_embedding <#> query_embedding) * -1 > match_threshold
ORDER BY users.interests_embedding <#> query_embedding
LIMIT match_count;
END;
$$;
チャット機能(生成AI)
次にAIが仲介するチャット機能を実装します。
ユーザーから受け取ったチャットを要約し、返信のサジェスト候補を加えた上で、送信先のユーザーに届けます。
LangChainについて
ここで今回使用した LangChain について触れます。
LangChain は、LLMアプリケーションを開発するためのフレームワークです。
メリットとしては機能が豊富だったり、モデルを抽象化してくれるので切り替えが楽だったりと、色々あります。
LangChain以外にも、ステートフルでマルチアクターなLLMアプリケーション(いわゆるAIエージェント)を開発するためのフレームワークである LangGraph や、LLMアプリケーションの評価やモニターをするためのプラットフォームである LangSmithがあります。
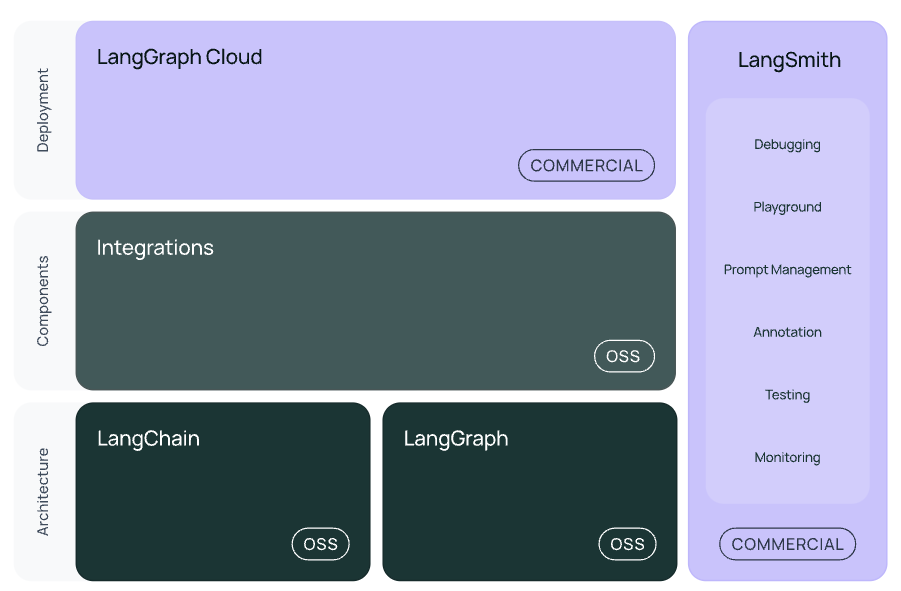
生成AIによる要約や返信サジェスト
「LCEL」(LangChain Expression Language) を使用して実装していきます。
LCELは、LLMによる操作を連結したカスタムチェーンを簡単に作成するためのLangChainの機能です。反復的な処理フローなど、より複雑なチェーンを実装したい場合は、LCELを拡張したLangGraphを使うと良いと思います。
(最初はLangGraphを使って、プロフィールも会話の中で設定できるようにしようと思いましたが、数日以内という期限に間に合わないので今回は見送りました。)
まず、Zodを用いて出力のスキーマを定義します。こうすることで、LLMの出力に型を適応することができます。
const OutputSchema = z.object({
content: z.string(),
});
type ProcessedOutput = z.infer<typeof OutputSchema>;
次にカスタムチェーンを作成します。今回はLLM入出力のみなので、単一の操作になります。
注意として、出力は二重中括弧を付けないと、エラーが発生します。
const template = `
プロンプト
入力:{input}
出力:{{"output": "出力"}}`
const model = new ChatGoogleGenerativeAI({
modelName: 'gemini-1.5-pro',
maxOutputTokens: 2048,});
const promptTemplate = PromptTemplate.fromTemplate(template);
const outputParser = new StringOutputParser();
const chain = RunnableSequence.from([
promptTemplate,
model,
outputParser,
]);
const result = await chain.invoke({
input: input,
});
const parsedResult = OutputSchema.parse(result);
当然ですが、大事なのはプロンプトです。必ずプロンプトジェネレーターなどを使って作成したものを自分でチューニングするように心がけましょう。
その他
直接トピックには関係がないですが、自分的に迷った部分について、備忘録を書いておきます。
なぜLangChainとGeminiを選んだのか?
LangChainに関しては、下記の理由から選定しました。
- 今後AIエージェント化してみたいので、直接APIを叩くのは避けたい
- LLMアプリ開発フレームワーク中で最もメジャーそう
Geminiに関しては、他に比べて圧倒的に安いので選択しました。無料枠もあり、GCPを登録すると最初にもらえるクレジットでも使用が可能です。
匿名ログインについて
Supabaseで匿名ログインを行う場合のSQLポリシーの書き方が独特だったので、そこだけ軽く触れたいと思います。以下のように書く必要がありました。
CREATE POLICY "sample policy"
ON public.samples FOR SELECT
TO authenticated
USING ((auth.jwt() ->> 'sub')::uuid = id);
ポイントは (auth.jwt() ->> 'sub')::uuid というところで、auth.uid()ではないようなので、注意が必要です。
まとめ
いかがだったでしょうか。自分的に落とし穴だったなというところを中心に解説しました。
生成AIやAIエージェントは今後どんどん発展していくと思うので、これからも発信していければと思います。良かったらフォローをお願いします。
Xも更新していますので、そちらも良かったらフォローをお願いします。
https://x.com/kojin_kaihatsu
お読みいただき、ありがとうございました。