はじめに
この記事は、基盤モデル×Roboticsのカレンダー13日目になります。
ほかにもすごい興味深い記事がたくさんあるので気になった方は↓から見ていってください!
(ちなみに僕も今回初めて基盤モデルというものを知りました。自分自身、機械学習が専門ではないので、何か間違いがあればご指摘ください。)
基盤モデルとは?という方は @MeRT さんの以下の記事が参考になるかと思います。(上記アドベントカレンダー1日目の記事ですね)
また、本論文はMicrosoftのプロジェクトページ、論文ともに公開されているので、本記事はラフな感じでいきたいと思います。
本記事 > プロジェクトページ > 論文という順で取っ付きやすくなればいいなーと思います。
LATTEとは?
論文タイトルは「LATTE: LAnguage Trajectory TransformEr」です。
ミュンヘン工科大学とMicrosoftの方々が発表した論文です。
とても簡単にまとめると、「ユーザーの自然な言語を解釈してロボットの経路を生成(調整)する」という感じですね。
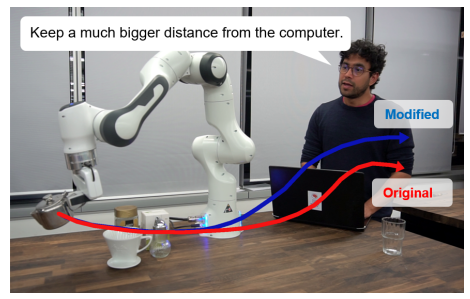
以下は、マニピュレータに対して、PCから遠ざけるような指示を与えている例です。
特徴
自然な言語の処理
ここでいう「自然な言語」とは、我々が普段使うような言葉ですね。「そこの飲み物とって」や、「危ないからそこには近づかないで」など。
これらの言葉(指示)をロボットの動作生成に適用するのはとても難しいでしょう。それを可能にしているのがLATTEです。
画像の処理
ロボット付近の画像から物体を検出し、指示の中に含まれる物体を割り出します。
上記の画像の例だと、"computer"がそれにあたりますね。
それらの統合
最終的にカメラ画像、人の自然な言語の処理結果から、ロボットの経路生成までを行うシステムを提案しています。
カメラ画像の処理にはCLIPを、言語処理にはCLIPとBERTを使用しています。
CLIPに関しては本アドベントカレンダーの2日目で紹介されていますね。
この論文の特徴
この論文のもととなった研究は以下のようです。
上記の論文からの拡張部分は以下になります。
- 次元の拡張
- 2次元から3次元を扱えるようになった。
- 動作の速度も扱えるようになった。
- 環境の画像の使用
- ネットワークのインプットにテキストの物体ラベルを使用していたが、実際の画像を使用している。
- マルチプラットフォームでの評価
- マニピュレータ、ドローン、多足ロボットで実証している。
- シミュレータはCoppeliasimとBulletを使用したと記載がありました。
LATTEのシステムアーキテクチャ
LATTEのシステムアーキテクチャを以下に示します。
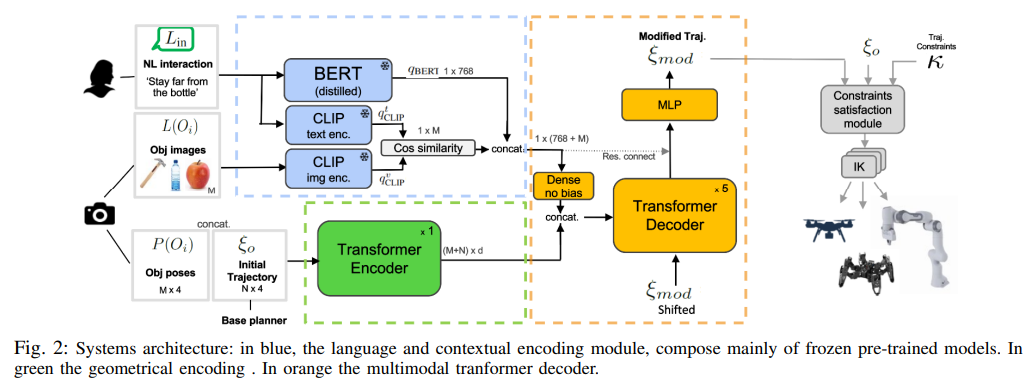
青と緑と黄色の四角がそれぞれ主要モジュールとなっています。
- 言語と画像のエンコーダ(青)
- 自然言語入力の埋め込み表現を生成し、テキストで言及される可能性のあるオブジェクトを識別するために、個別の事前学習済み特徴エンコーダ(BERTとCLIP)を利用します。
- ジオメトリエンコーダ(緑)
- オブジェクトの位置姿勢と軌道のウェイポイントを入力として使用し、変換器を使用して元の軌道、速度プロファイル、シーン内のオブジェクトの間の幾何学的関係を学習します。
- マルチモーダル変換器デコーダ(黄)
- 2つの先行モジュールの埋め込み出力を組み合わせて、修正された軌道を回帰的に生成する。
最終的に画像上の白色のIKという箇所でロボットの起動を生成します。プラグイン形式でどのようなロボットでも対応可能という記述がありました。
実験結果
シミュレータでの実験
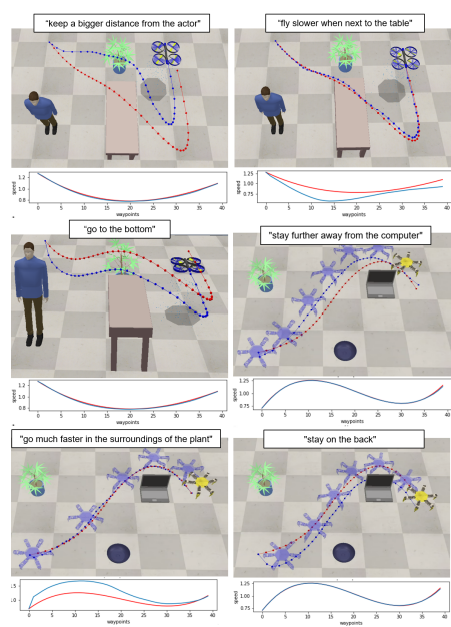
以下はドローンと多足歩行ロボットにそれぞれの指示を与えて経路を生成させた結果です。
赤色の経路(速度)がオリジナルの経路(速度)、青色の経路(速度)がLATTEを使用して生成した経路(速度)です。
経路と速度が操作できているのがわかります。
例として、
中段左:"go to the bottom"で青の方が下に移動している
下段左:"go much faster in the surroudings of the plant"で青の方が植物近くで速く移動している。
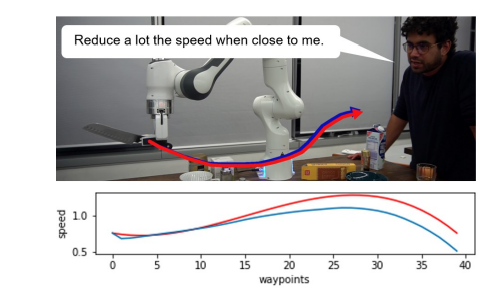
実機での実験
以下の例は実機のマニピュレータの動作を生成したものです。赤色の経路(速度)がオリジナルの経路(速度)、青色の経路(速度)がLATTEを使用して生成した経路(速度)です。
この例では、"Reduce a lot the speed when close to me"と言って、速度を操作していますね。
それ以外の動作の様子は以下のページ内の動画から見ることができます。
まとめ
LATTEは、事前に学習された大規模言語モデルと画像モデル(BERTとCLIP)を活用し、自然言語と環境画像からユーザの意図とターゲットの物体を取得することによって軌道を出力する手法です。
本モデルは、3次元空間と速度空間におけるロボットの軌跡を操作することができ、マニピュレーション、航空車両、脚式ロボットなど、様々な異なるプラットフォームに適用することができます。
将来的には、力入力のような追加の指示方法を探求するとともに、より長い時間軸と複数の指示入力に渡ってユーザーと対話するモデルの能力を探求していくそうです!