
目次
はじめに
こんにちは。Databricks の新井です。Qiita 初投稿です。
2022年の7月よりソリューションアーキテクトとして働き始めました。
お客様に弊社製品を知っていただき、導入いただく際の技術サポートを行う役割です。
本記事では Databricks にご興味がある皆様に弊社プラットフォームを理解いただくために、新入社員の目線から便利だと感じた10個の機能をまとめました。
今後も記事執筆を継続するモチベーションに繋がりますので「いいね」や記事の保存、SNSで共有いただけると嬉しいです。宜しくお願いいたします!
背景と目的
皆様の中には Databricks という会社に馴染みがない方も多いと思います。
米国カリフォルニア州に本社が存在する企業であり主にB2Bの製品を開発しているため、一般的な認知度は高くない認識です。
一方で、データエンジニアリングやデータサイエンスに関わる方の中には MLFlow や Spark について見聞きしたことのある、または使ったことのある方もいらっしゃるのではないでしょうか。Apache Spark は弊社創設者が2009年にカリフォルニア大学バークレー校で開始したプロジェクトであり、MlFlow は2018年に発表したプロジェクトです。また今年(2022年)には Delta Lakeもオープンソース化しました。

自分も入社以前に MLFlow を使った機械学習パイプラインの開発や Spark を使った ETL パイプライン開発の経験はあったのですが、Databricks のプラットフォーム(Databricks Lakehouse Platform)として何ができるかは、日本語で纏められた記事が少ないこともあり、知識が限られていました。
入社して実際に触ってみると、想像していたよりも多くのことができるプラットフォームであると感じております。入社前の自分のような方も多いのではないかと思い、本記事に自分が使ってみた機能を中心に簡単に紹介します。
弊社プラットフォームのことをより知りたい皆様、この記事を通して少しでも理解いただけますと幸いです。また少しでもご興味をお持ちいただけたら弊社までお問い合わせください。
Databricksとは何か
端的に言うと
「データの収集・蓄積から分析・機械学習モデル開発並びに運用を一気通貫・効率的かつ安価に行うことができる統合プラットフォーム」です。
突然ですが、データを取り扱う皆様は次のような状況に陥ったことはないでしょうか。
「他チームが使っているデータがどこにあるのかわからない」
「データレイク上のデータとデータウェアハウス上のデータが違う」
「データウェアハウスにSQLを投げたが、処理に時間がかかり過ぎている」
「データサイエンティストが存在せず、機械学習モデルが作れない」
「書いていたノートブックが残っていなくてモデルが再現できない」
「機械学習のモデルは作ったけども本番運用するための基盤がない」
「似た分析レポートが複数あるが値が異なっていて、どれが正しいか不明」
などデータ基盤にまつわる課題には枚挙に遑がありません。
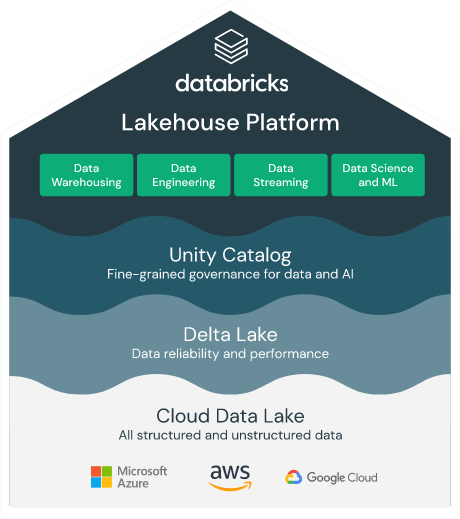
Databricks は上記の課題を解決するプラットフォームを提供しており、
プラットフォームは後述する3つの思想(Simple / Open / Multi Cloud)に基づいて設計されております。
Simple - シンプル
「複数のデータ基盤が社内に存在してどれを使ったら良いのかわからない...」
手前味噌でしかないですが弊社プラットフォーム( Databricks Lakehouse Platform )はシンプルで、簡単に利用可能です。従来データを扱うチームで発生していたデータレイクやデータウェアハウスの課題や問題点を解決する「データレイクハウス」の思想に基づいて設計されております。具体的には、データレイクに不要なファイルが増加してデータスワンプ化してしまう点やパフォーマンス面での課題に加えて、チームや組織間で乱立するデータウェアハウスの不整合や排他性(データサイロ)を排除できるデータ基盤を実現します。
Open - オープン
「一回導入してしまうとベンダーロックインされないか不安...」
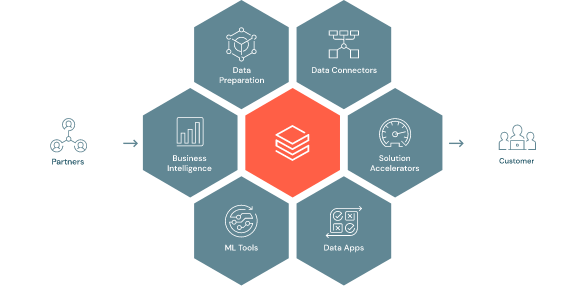
ベンダーロックされません。プラットフォームの基盤となっていて信頼性・セキュリティ・パフォーマンスを担保している Delta Lake はオープンソースプロジェクトであり、特定のベンダーやプロバイダーしか保守・運用できない状況には陥りません。不要であればオープンソースを使って内製化することが可能です。また Python や SQL に慣れ親しんだ方であれば誰でも使用可能です。加えて、450を超えるパートナーが存在しており、プラットフォーム上で Connector を使うことで各社のツールと連携が可能になっています。
Multi Cloud - マルチクラウド
「今使っているクラウドとは違うクラウドを使いたくなったらどうしよう..」
Databricks を中心として、すべてのクラウドで一貫した管理・セキュリティ・およびガバナンス体制(Unity Catalog)を提供しており、クラウドプロバイダーを変更しても同様の機能を提供できます。他のクラウドを使用する際に新しい管理・ガバナンス体制を再発明する必要はありません。

機能紹介
本章では自分が触ってみてイケてると感じた機能10選を紹介します。
今回は簡単にそれぞれの機能をご紹介させていただきますが、今後の記事ではそれぞれの機能の詳細に焦点を当てられればと思います。
共通
① ノートブックの同時編集やコメントを使った共同作業ができる
「ファイルを受け渡してレビューするのではなく、同時編集したい...」
皆様も他の方が書いているコードをファイルとして共有いただいたことがあるのではないでしょうか。Databricks上では許可されたユーザは直接ノートブック上でコードにコメントしたり、同時に編集することができます。自分は過去にファイルの受け渡しや Github / Gitlab を通じてコメントのやりとりやレビューをしていたのですが、こちらの機能を使うことで生産性が向上しています。

② ノートブックのバージョン管理・復元ができる
「ノートブックに不要な編集を加えてしまって、過去の断面に戻せない...」
ノートブックに不要な変更を加えてしまった場合に過去のバージョンを復元したい場合もあると思います。Databricks 上では過去のバージョンを選択して復元する機能が存在して、特定の断面に戻すことができます。自分は必要だったコードを削除してしまって再度作業をしないといけない経験が多々あるのですが、本機能を使うことで課題が解決されています。

③ ノートブック単位でスケジュール実行ができる
「ジョブをスケジュール実行したいけどCRONやスケジューラの設定が面倒臭い...」
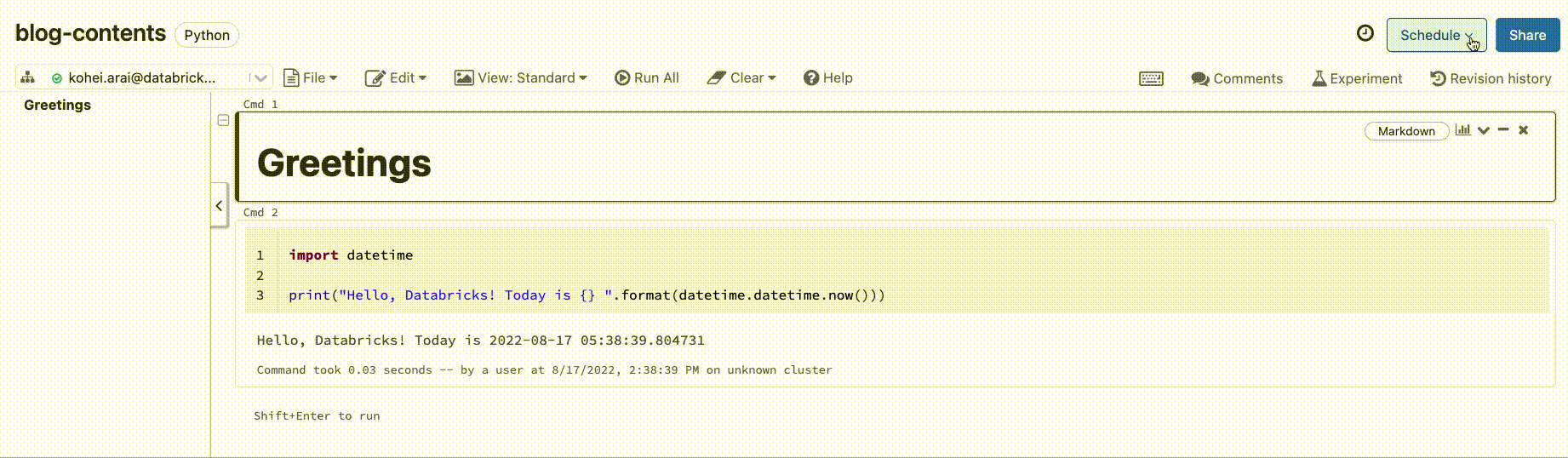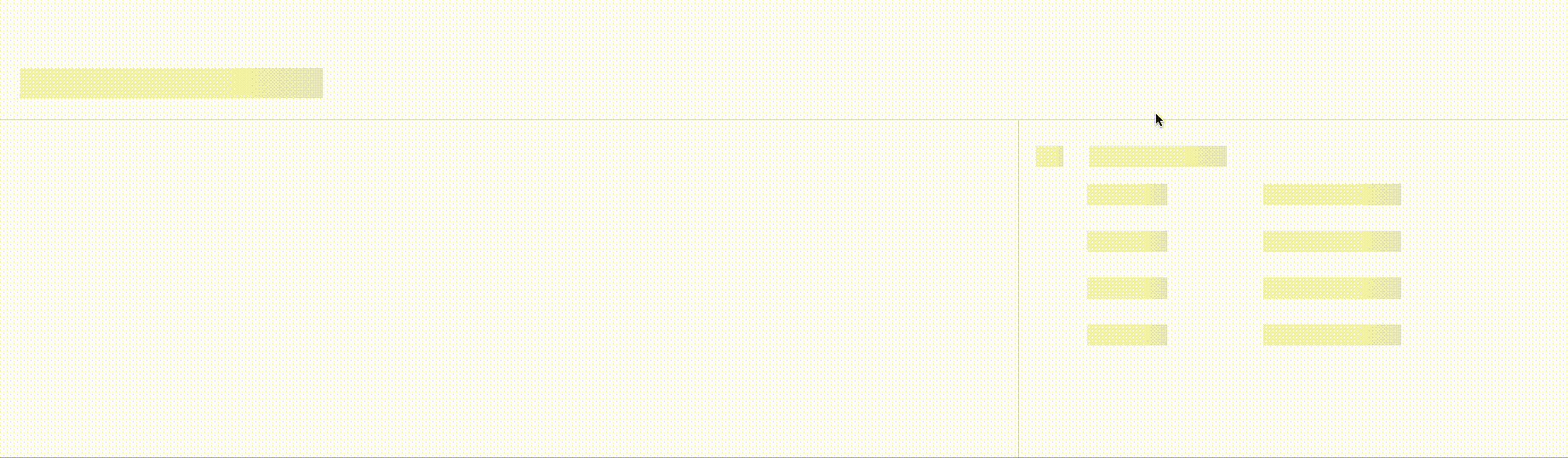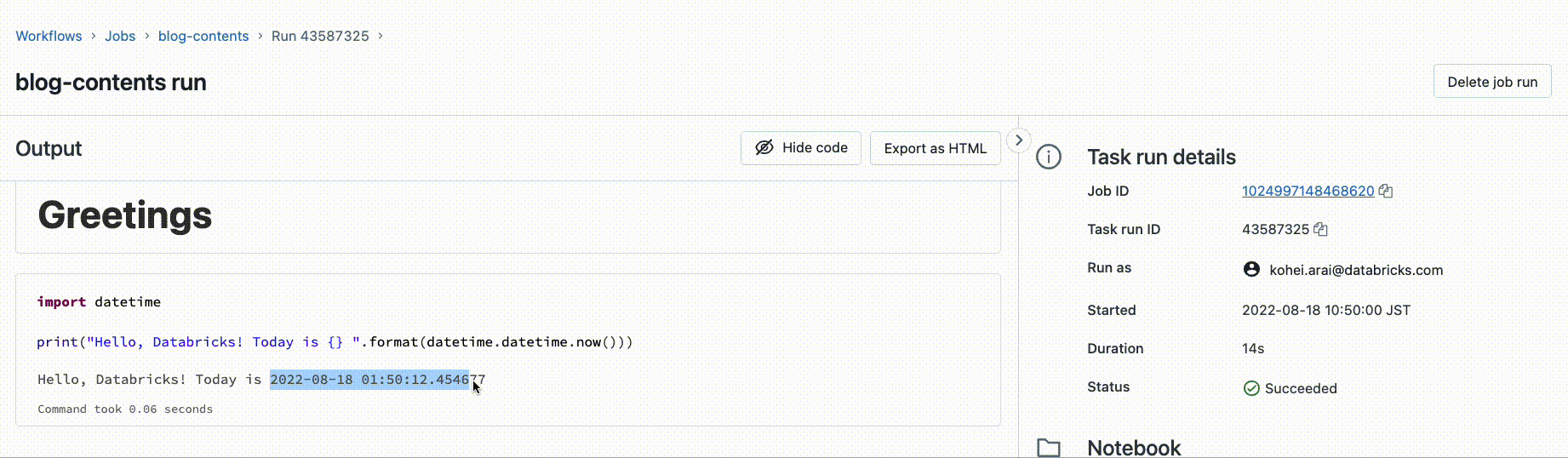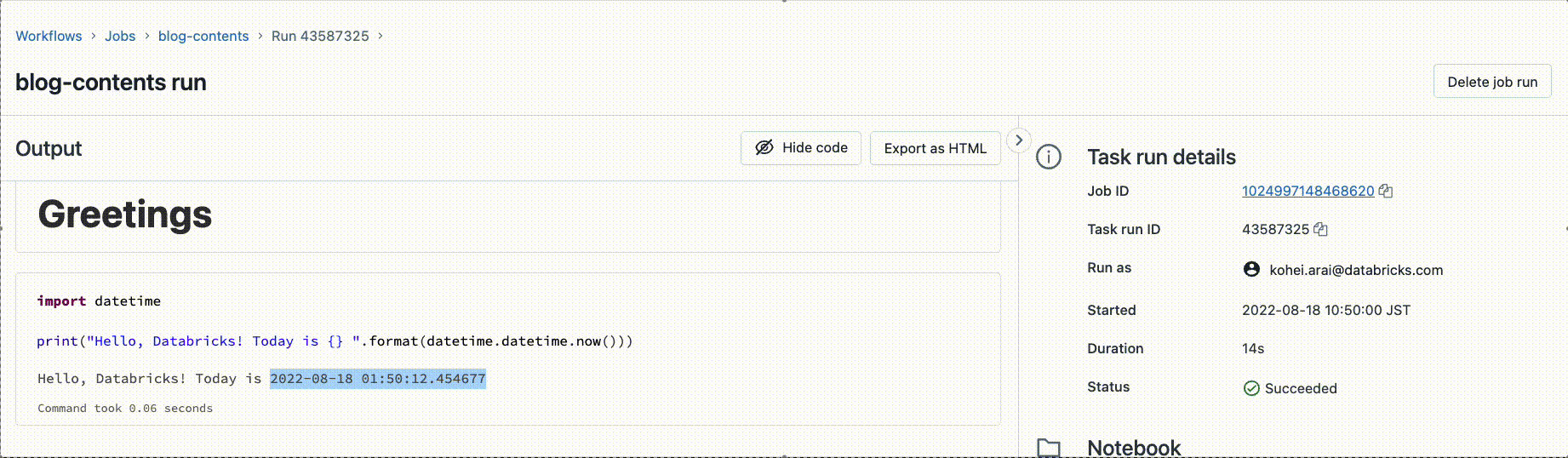
作成したノートブックやコードを時間を決めてスケジュール実行したいこともあります。Databricks上では下記のようにGUI上でノートブック単位でスケジュール実行が詳細に設定できます。従来まで CRON ジョブや Airflow のスケジュール機能を使っていたのですがこちらの機能で代替可能と感じています。
(設定画面)

(実行結果)
データエンジニアリング
④ オブジェクトストレージ(S3やAzure Blob、Google Cloud Storage)をマウントしてそのままSQL / Python / R で処理できる
「S3に置いてあるファイルを直接読んでいるけどパフォーマンスが悪い...」
「ローカル環境にS3からいちいちファイルをダウンロードするのは面倒臭い...」
データエンジニア・データサイエンティストの方々は日常的にAWS / Azure / GCP 上のデータを利用しているのではないでしょうか。環境によってはパフォーマンスに課題があったり、生産性が低かったりするかと思います。オブジェクトストレージをマウントしておけばデータを移行せずに変換・利用できます。ストレージから逐一ファイルをダウンロードする手間や直接読み書きする際のパフォーマンス低下に悩まされることがなくなります。

⑤ ノートブック上でストリーミングデータや非構造化データに対応できる
「1日1回のバッチ処理ではなく、リアルタイムで随時データを簡単に更新したい...」
ストリーミングデータもノートブック上で対応できます。
対象のパスに新しくデータが保存されてくると、勝手にテーブルにレコードを追加してくれます。下図においては青い部分がイベントを表しており、対象のテーブルにレコードが随時追加されていることがわかります。今まで日次/週次/月次など都度連携されてくるデータを手動でデータウェアハウスにデータを取り込んでいた経験があるのですが、こちらの機能を使えば工数が削減できます。

機械学習
⑥ AutoMLを使って簡単に機械学習モデル / AIを作れる
「機械学習をやってみたいけど複雑なコードは書けない...」
「簡単に最初のベースラインとなるモデルを開発したい...」
「データサイエンティストが存在せず、機械学習モデルが作れない...」
Databricks 上では訓練データを用意して1行だけコードを書くとAutoMLがXGboost / LightGBM / RandomForest などのモデルを作ってくれます。プラットフォーム上では勿論手動でモデルを開発することもできますが、データサイエンティストや機械学習エンジニアは人手不足なことが多く、作業はできるだけ効率化することが望まれます。この機能を使うことでデータサイエンティストの工数を削減できる上、機械学習に明るくない方でもモデル/AIを開発することが出来ます。

⑦ モデル開発時に MLFlow に評価指標や特徴量を記録できる
「ハイパーパラメータや評価指標、使ったモデルの管理が面倒臭い...」
「書いていたノートブックが残っていなくてモデルが再現できない」
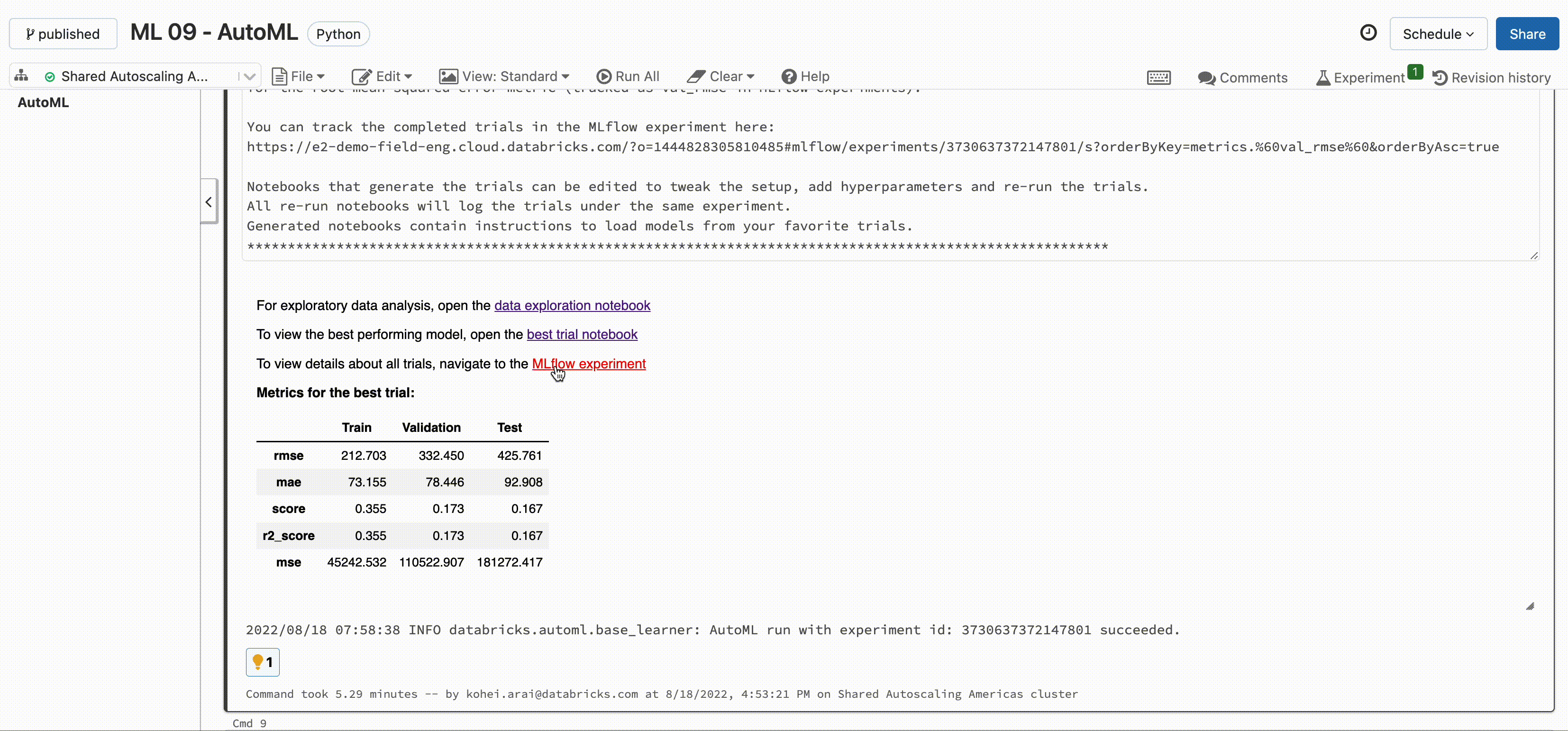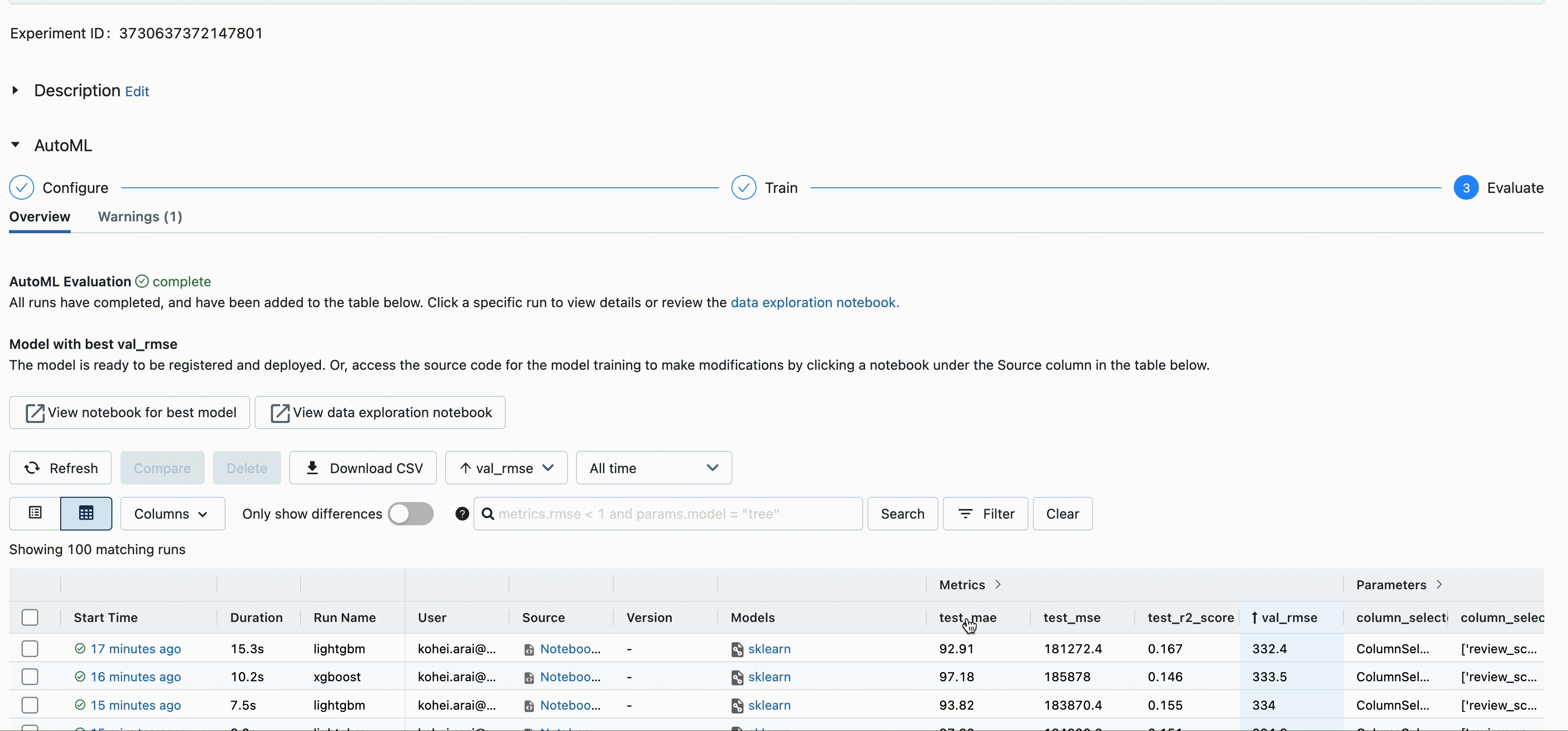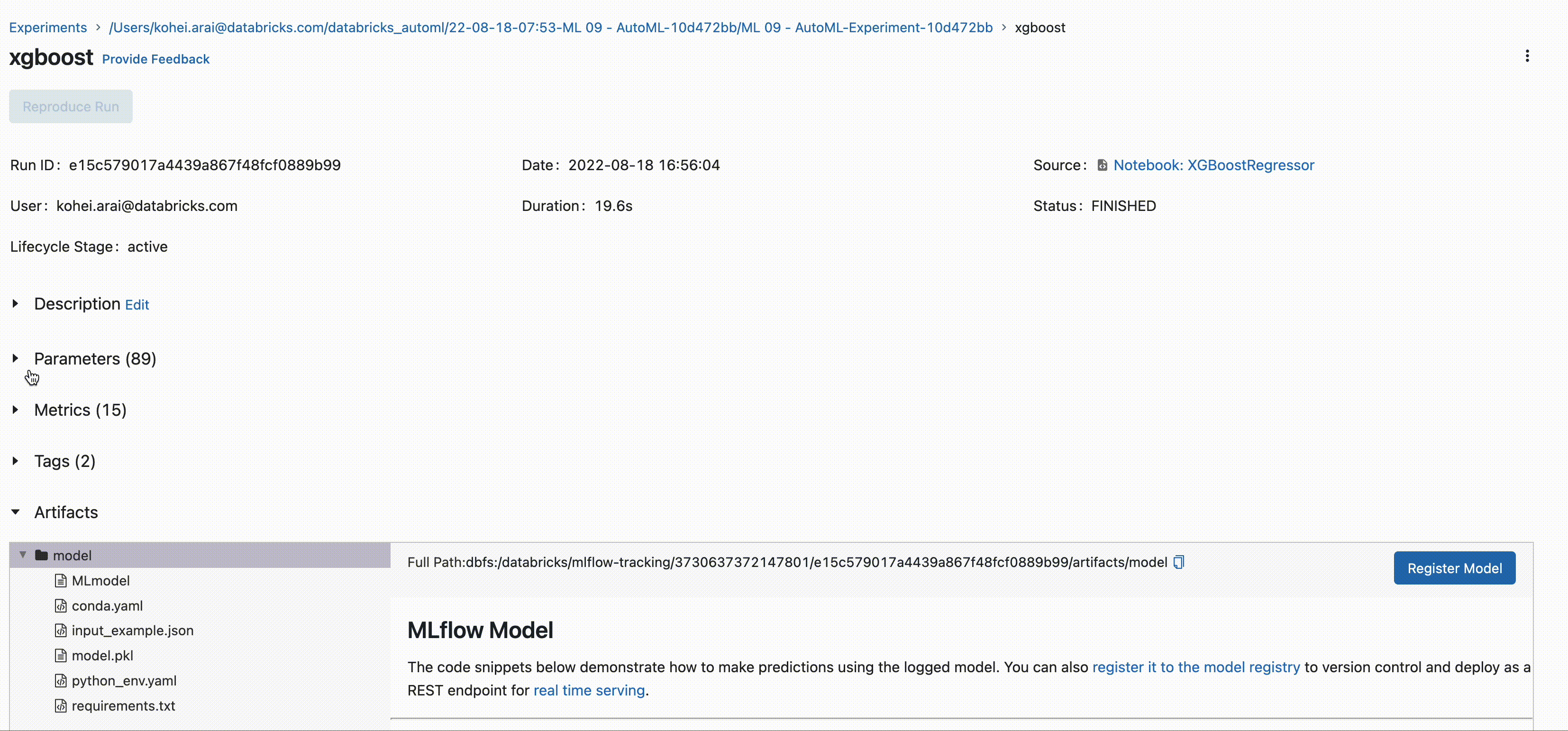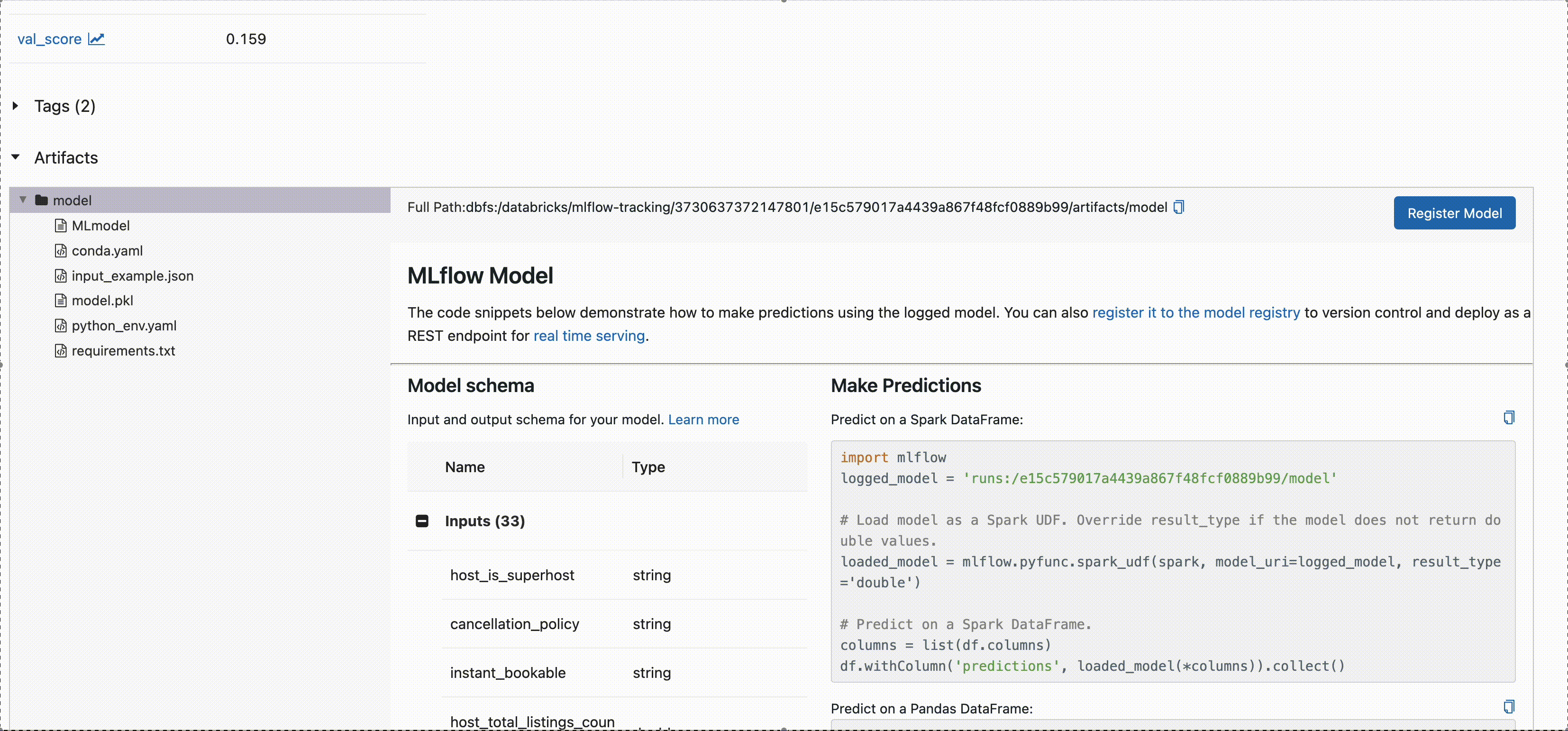
機械学習/モデリングを行う際には記録する情報(ハイパーパラメータや評価指標、モデルファイルなど)が多いです。プラットフォーム上では学習結果は MLFlow Expriments で確認でき、使用したモデルやハイパーパラメータ・評価指標を確認することができます。こちらは AutoML を使った結果ですが、マニュアルでモデルを開発する際にもログ出力やモデル格納を設定することで同様の出力が可能です。
Databricks SQL
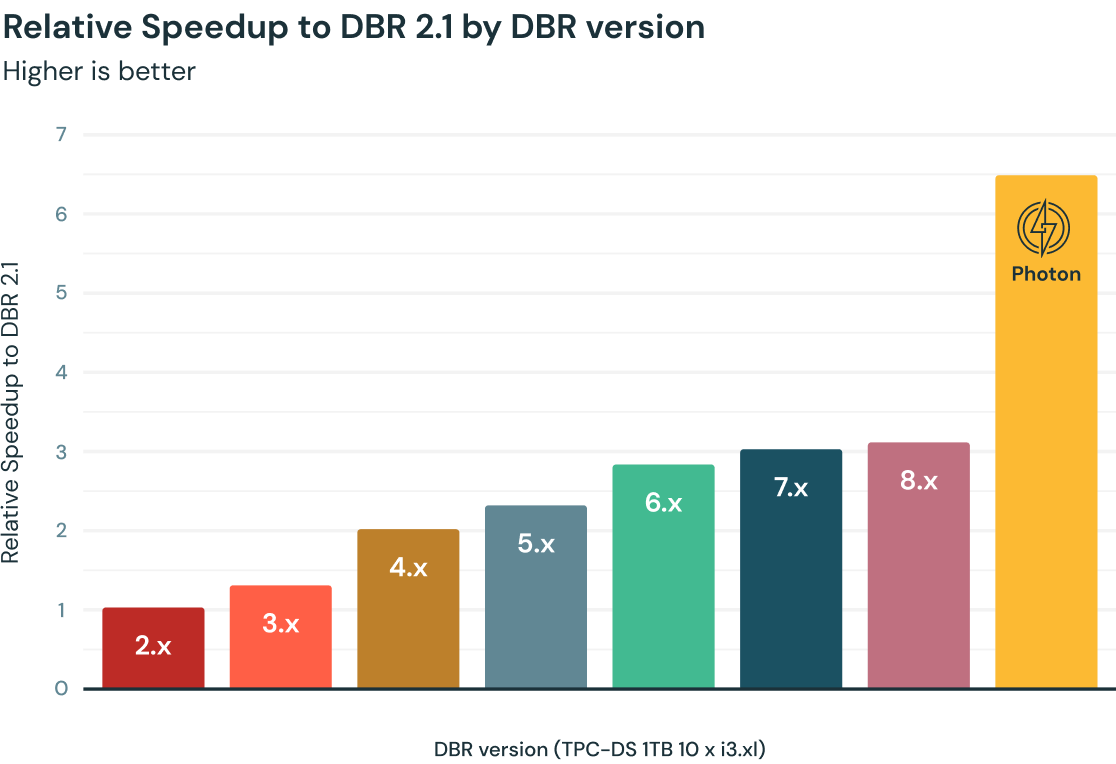
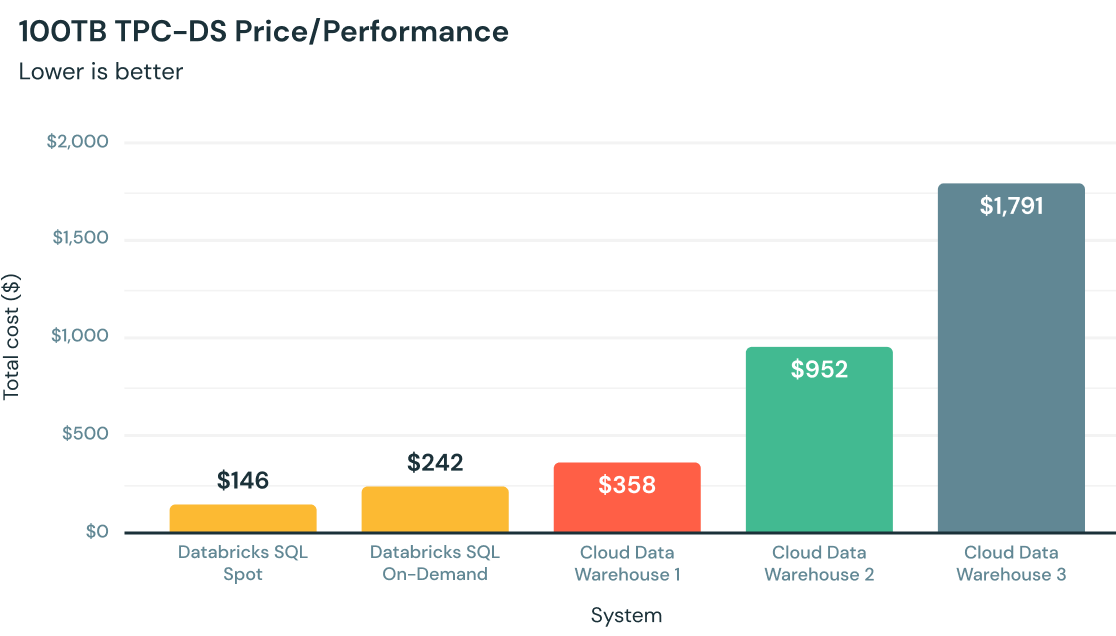
⑧ 高速 Spark エンジン Photon を使って処理できる
「データウェアハウスにSQLを投げたが、処理に時間がかかり過ぎている...」
Spark / MLFlowの会社というイメージが強く、データウェアハウス領域では知られていないかもしれないですが、Databricks SQL は Photon という Spark よりも高速なエンジンが裏側で支えています。第三者機関である TPC council によってパフォーマンスが計測されており、他のデータウェアハウス製品と比べてコストパフォーマンスの優位性が証明されています。高速で安価なデータウェアハウスを実現しており、インフラコスト削減・作業効率向上に貢献します。
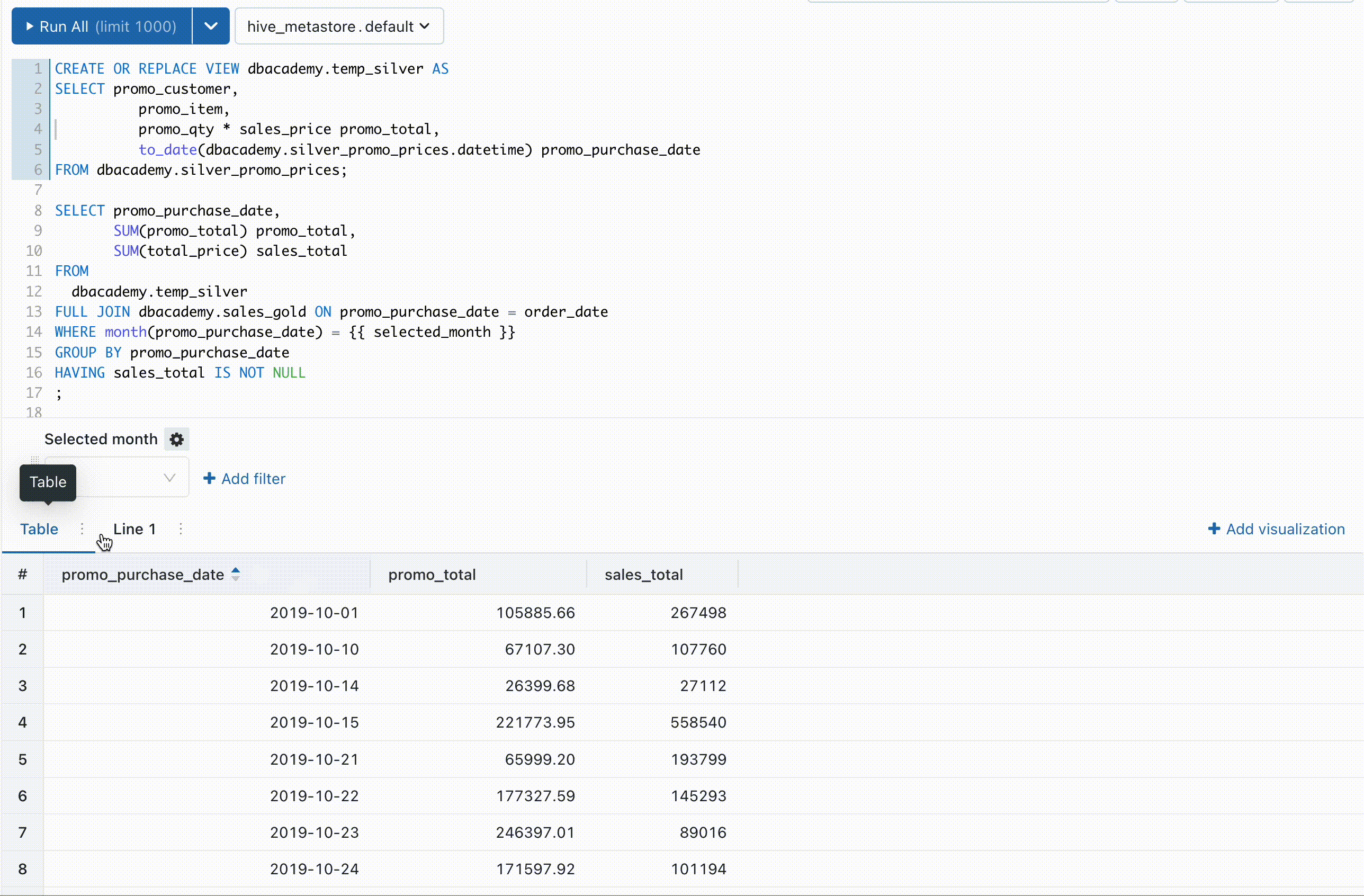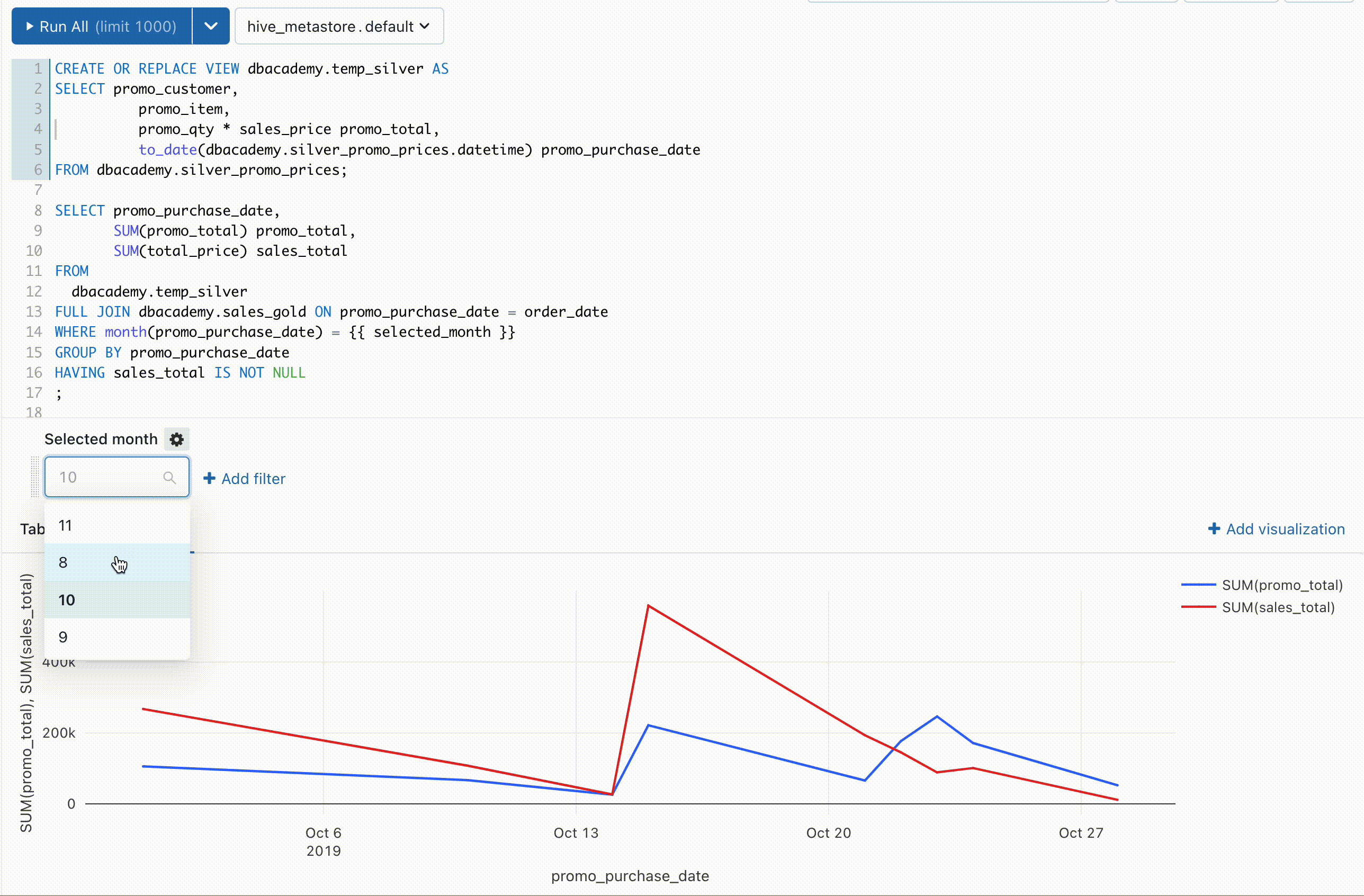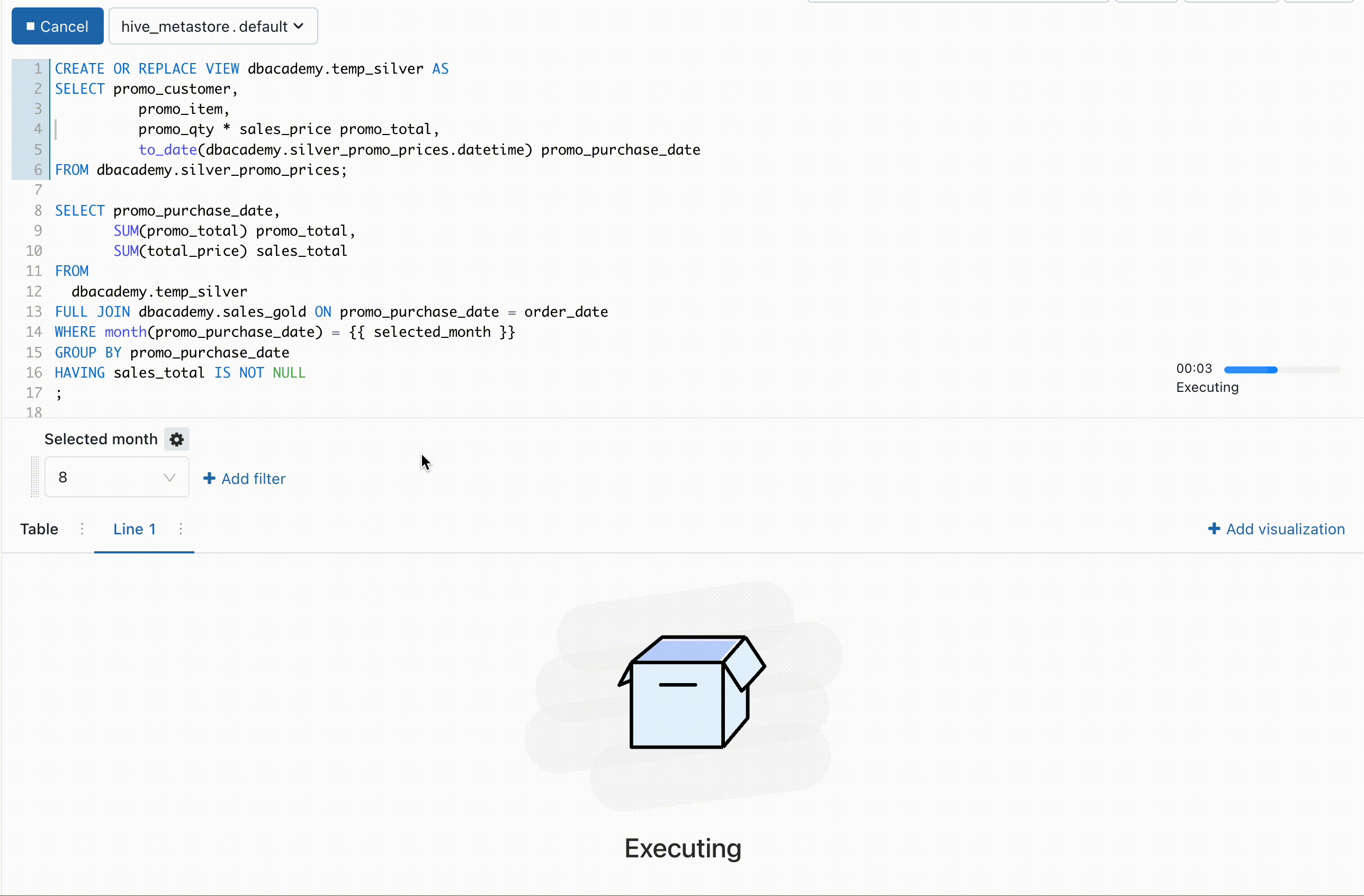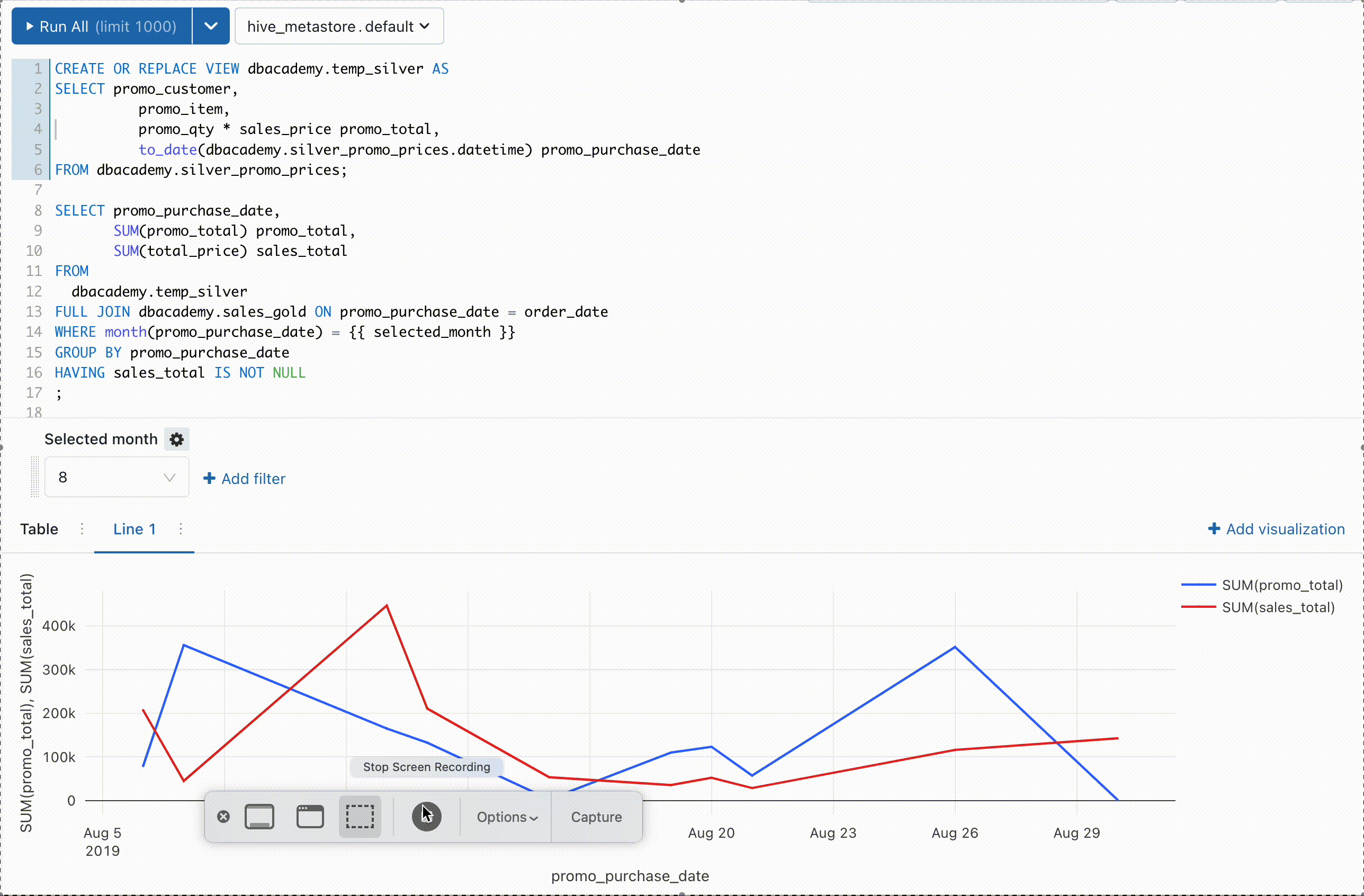
⑨ クエリ結果をGUI上で簡単に可視化できる
「分析結果を簡単に可視化したいけどツールの使い方が難しい..」
Databricks 上で SQL を実行する環境も用意されており、クエリ実行並びに裏側の Redash によって簡単な可視化をすることができます。また SQL の一部をパラメータにして動的に変更することでフィルタをかけて可視化することもできます。以前は自分もクエリ結果をCSVで出力してBIツールに連携、可視化していたのですがこちらの機能を使うことでそちらの工程が不要になります。
⑩ クエリ結果を使ってダッシュボード・レポートが作れる
「複数のSQLの結果を纏めてダッシュボードを作りたい...」
作ったクエリの結果をまとめてダッシュボードを作ることもできます。
こちらは動的に更新させることもでき、最新断面のデータを確認することが出来ます。こちらのダッシュボードはチームメンバーや他組織のメンバーに共有することができます。
おわりに
この記事では Databricks Lakehouse Platform のイケてる機能10選を新入社員の目線から簡単にご紹介いたしましたが、いかがでしたでしょうか。皆さんが使ってみたくなる機能がありましたら幸いです。
また「こういう機能についてもう少し詳細に知りたい」「自分は Databricks のもっと素晴らしい点を知っている」などあればコメント欄を含めてご連絡いただければと思います。
今後の記事ではそれぞれの機能をより深掘りしてご紹介できればと思います。初めての Qiita の記事で力を入れて書いたこともあり、記事を読んで少しでもためになったと思われた方は「いいね」や記事の保存、SNSでシェアいただけると嬉しいです!
参照
- Photon: https://www.databricks.com/product/photon
- Databricks Technology Partners: https://www.databricks.com/company/partners/technology
- Databricks Lakehouse Platform: https://www.databricks.com/product/data-lakehouse#:~:text=Open.,learning%20support%20of%20data%20lakes.