目次
はじめに
こんにちは。データブリックスの新井です。
皆様は、Databricksデータエンジニアアソシエイト試験の公式練習問題(リンク)があることをご存知でしょうか。
自社なので当たり前だろと言われそうですが、自分はDatabricks認定データエンジニアアソシエイト試験に合格しています。ただ、勉強する際に公式練習問題の解説が乏しく、また日本語訳が存在しないことで勉強が大変でした。
受験者も増加しており過去の自分の方々もいるのではないかと思い、今回はDatabricksデータエンジニアアソシエイト試験の公式練習問題の全45問のうちQ1-15を翻訳、解説してみようと思います。
需要があれば(10いいね以上で25問目まで追加、25いいね以上で35問目まで追加、40いいね以上で45問目まで追加)、以降の質問についても翻訳・解説しようと思いますので、「いいね」や記事を保存いただけると嬉しいです。よろしくお願いいたします!

留意点として翻訳並びに解説は、全て私(新井)個人で行った翻訳や解説でございますので、至らない点がございましたらご指摘いただけましたら幸いです。
練習問題
質問1. 次のうち、従来のデータウェアハウスにはないデータレイクハウスの利点を説明するものはどれですか。
- A. データレイクハウスは、リレーショナルシステムによるデータ管理を行う
- B. データレイクハウスは、バージョン管理のためにデータのスナップショットを取得する
- C. データレイクハウスは、完全な制御を実現するためにストレージとコンピュートを密結合する
- D. データレイクハウスは、データ蓄積のために占有技術であるストレージフォーマットを利用する
- E. データレイクハウスは、バッチ解析とストリーミング解析の両方を可能する
答えを見る
正解は「E. データレイクハウスは、バッチ解析とストリーミング解析の両方を可能する」です。Databricksのレイクハウスプラットフォームでは従来のDWHのようなバッチ処理に加えてストリーミングも一つのプラットフォーム上で処理できます。他の選択肢は下記の理由から不正解です。
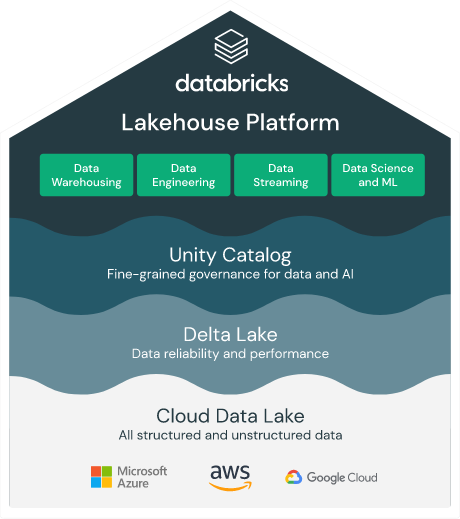
- A. 従来のリレーショナルシステム(RDBMS)ではなく、カラム志向のDeltaフォーマットでデータを格納・管理します。
- B. スナップショットは取得せず、Time Travel という機能でデータのバージョンを管理して信頼性を担保しています。
- C. レイクハウスにおいては、ストレージとコンピュートは完全に分離されています。
- D. Delta Lakeというオープンソースのフォーマットでデータを蓄積します。
質問2. Databricksが管理するクラスタのドライバノードとワーカーノードをホストする場所は、次のうちどれですか?
- A. データプレーン
- B. コントロールプレーン
- C. Databricks ファイルシステム
- D. JDBC データソース
- E. Databricks ウェブアプリケーション
答えを見る
正解は「A. データプレーン」です。データブリックスのアーキテクチャは下記のようになっており、コンピューティングリソースであるSparkクラスタのドライバーノードとワーカーノードはそれぞれデータプレーン(各クラウドプロバイダー内)に存在します。
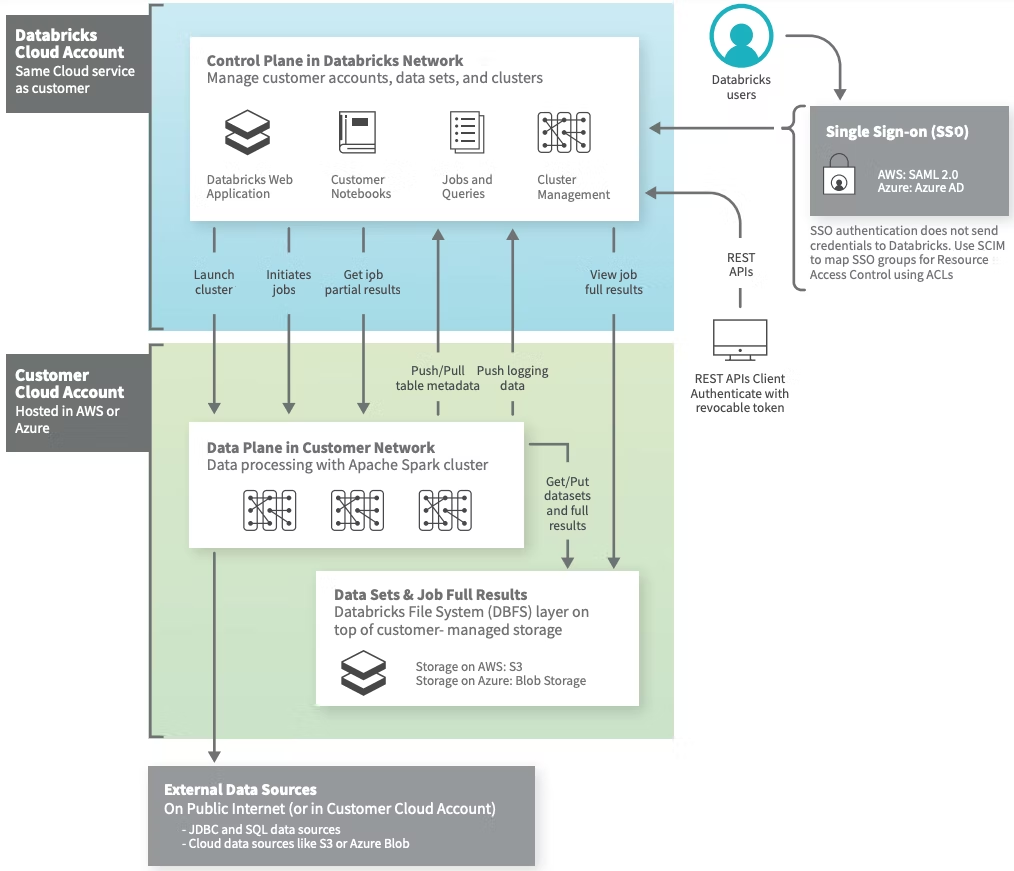
他の選択肢は下記の理由から不正解です。
- B. コントロールプレーンにはノートブックやクラスタマネージャが存在しますが、コンピューティングリソースは存在しません。
- C. Databricks ファイルシステムはワークスペースを作成した時に作られるオブジェクトストレージ(S3やAzure Blob Storage)を抽象化したものです。
- D. JDBC データソースはJDBC接続で取得できるデータソースであり、コンピューティングリソースとは関係ありません。
- E. Databricks ウェブアプリケーションはコントロールプレーンに存在し、ユーザが操作するGUIです。
質問3. あるデータアーキテクトは、動画を使った機械学習と監査に対応したバッチETL/ELTの両方に対応するアーキテクチャを設計しています。次のうち、データレイクハウスが両方のワークロードのニーズを満たす理由について説明しているものはどれですか?
- A. データレイクハウスは、データモデリングをほとんど必要としない。
- B. データレイクハウスは、シンプルなガバナンスのためにコンピュートとストレージを組み合わせている。
- C. データレイクハウスは、コンピュートクラスタのオートスケーリングを提供する。
- D. データレイクハウスは、非構造化データを格納し、ACIDに準拠しています。
- E. データレイクハウスは、完全にクラウドに存在します。
答えを見る
正解は「D. データレイクハウスは、非構造化データを格納し、ACIDに準拠しています。」です。レイクハウスの基盤になっているDelta Lake は構造化データに加えて動画や画像などの非構造化データにも対応しており、また信頼性を高めるためにACID準拠しています。詳細はこちらのブログ記事「Delta Lakeとは」もご参照ください。
他の選択肢は下記の理由から不正解です。
- A. データモデリングはパフォーマンスや運用面において重要です。こちらのベストプラクティスもご参照ください。
- B. ストレージとコンピュートは分離しています。
- C. こちらは提供していますが、問題文の条件を満たす理由ではありません。
- E. 問題文の条件を満たす理由ではありません。
質問4. 次のうち、データエンジニアが汎用クラスタではなくジョブクラスタを使用したいと思うシナリオはどれですか?
- A. 計算コストを最小限に抑えながら、アドホック分析レポートを作成する必要がある。
- B. データチームが共同で機械学習モデルを開発する必要がある。
- C. 自動化されたワークフローを30分ごとに実行する必要がある。
- D. 上長への報告のためにDatabricksのSQLクエリをスケジュール実行する必要がある。
- E. データエンジニアは、手動で本番エラーを調査する必要があります。
答えを見る
正解は「C. 自動化されたワークフローを30分ごとに実行する必要がある。」です。
データブリックスのクラスタは①ジョブクラスタと②汎用クラスタが存在し、それぞれの用途は下記の通りです。
ジョブクラスタ:自動化されたジョブを高速・セキュアに実行する
汎用クラスタ:ノートブックを使って協力してデータ分析を行う
他の選択肢は下記の理由から不正解です。
- A. アドホックな分析を行う際には汎用クラスタを使用します。
- B. ジョブクラスタは共同作業には使えません。汎用クラスタを使用します。
- D. SQLクエリはDatabricks SQLエンドポイントを使ってスケジュール実行します。
- E. ジョブクラスタでは本番エラーは自動で検知されます。
質問5. データエンジニアは、データパイプラインの一部としてDeltaテーブルを作成しました。そのテーブルを利用するデータアナリストはDelta テーブルの SELECT 権限を必要とします。データエンジニアがDeltaテーブルの所有者であると仮定した場合、どの部分を使用すれば適切なアクセス権を付与することができますか?
- A. リポジトリ
- B. ジョブ
- C. データエクスプローラー
- D. Databricks ファイルシステム(DBFS)
- E. ダッシュボード
答えを見る
正解は「C. データエクスプローラー」です。データエクスプローラーにはテーブルやスキーマの確認に加えて、権限を付与する機能が存在します。下記画像のようにGUI上で権限の付与などが可能です。
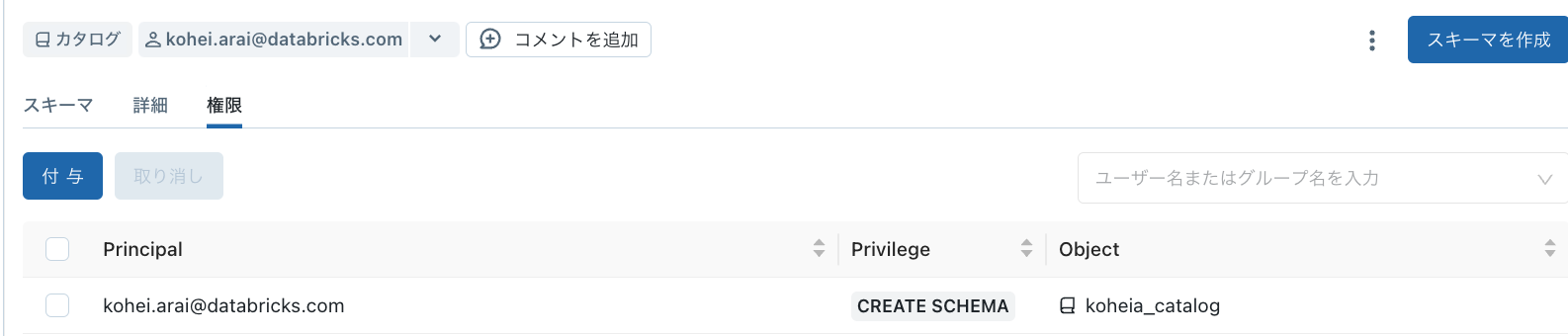
他の選択肢は下記の理由から不正解です。
- A. リポジトリはGit連携に使用するものであるため、誤りです。
- B. ジョブは定期的なジョブを高速かつセキュアに実行するために使用します。
- D. Databricks ファイルシステムはクラウドのオブジェクトストレージを抽象化したものであり、アクセス権を付与する機能はありません。
- E. ダッシュボードは複数のグラフなど可視化を組み合わせたもので、レポーティングなどに使用されます。
質問6. 若手データエンジニア二人が、データパイプラインに用いる一つのノートブックの別々の部分を編集しています。二人は別々の Git ブランチで作業しているので、同じノートブックで同時にペアプログラミングを行うことができます。Databricks の経験豊富なシニアデータエンジニアが、このようなコラボレーションには、より良い代替手段があることを示唆しています。次のうち、シニアデータエンジニアの主張をサポートするものはどれですか?
- A. Databricks Notebooksは、自動的な変更追跡とバージョン管理をサポートしています。
- B. Databricks Notebooksは、1つのノートブック上でリアルタイムの共同執筆をサポートします。
- C. Databricks Notebooks は、コメントと通知コメントをサポートしています。
- D. Databricks Notebooksは、同じノートブックでの複数言語の使用をサポートしています。
- E. Databricks Notebooks では、インタラクティブなデータ可視化の作成がサポートされています。
答えを見る
正解は「B. Databricks Notebooksは、1つのノートブック上でリアルタイムの共同執筆をサポートします。」です。URLを共有すると同じノートブック上でリアルタイムに編集可能です。他の選択肢は下記の理由から不正解です。
- A. 変更追跡・バージョン管理機能はありますが、問題文のコラボレーションには関係ありません。
- C. サポートしていますが、問題文のコラボレーションには関係ありません。
- D. ノートブック上でPython、R、SQL、Scalaを書けますが、問題文のコラボレーションには関係ありません。
- E. ノートブック上で可視化をサポートしておりますが、問題文のコラボレーションには関係ありません。
質問7. Databricks ReposがDatabricks Lakehouse Platform上でCI/CDワークフローを促進する方法について説明しているのは次のうちどれでしょうか?
- A. リポジトリは、プルリクエスト、レビュー、およびブランチのマージ前の承認プロセスを促進することができます。
- B. リポジトリは、セカンダリ Git ブランチの変更をメイン Git ブランチにマージすることができます。
- C. リポジトリを使って、Git の自動化パイプラインを設計、開発、起動することができます。
- D. リポジトリは、単一の真実である Git リポジトリを保存することができます。
- E. リポジトリは、CI/CD プロセスを起動するために、コードの変更をコミットまたはプッシュすることができます。
答えを見る
これは難しいのですが、正解は「E. Databricks Repos はCI/CD プロセスを起動するために、コードの変更をコミットまたはプッシュすることができます。」です。
 他の選択肢は下記の理由から不正解です。
他の選択肢は下記の理由から不正解です。
- A. CI/CDとは関係が薄い内容なので誤りです。
- B. CI/CDとは関係ない内容なので誤りです。
- C. 問題作成時はできなかったのかと思いますが、現在は可能です。こちらもご参照ください。
- D. 難しいですが、CI/CDとは関係が薄い内容なので誤りです。
質問8. デルタレイクを説明した文章は次のうちどれでしょう?
- A. Delta Lakeは、ビッグデータのワークロードに使用されるオープンソースの分析エンジンです。
- B. Delta Lakeは、信頼性、セキュリティ、パフォーマンスを提供するオープンフォーマットのストレージレイヤーです。
- C. Delta Lakeは、完全な機械学習のライフサイクルを管理するためのオープンソースプラットフォームです。
- D. Delta Lakeは、分散データのためのオープンソースのデータストレージフォーマットです。
- E. Delta Lakeは、データを処理するオープンフォーマットのストレージレイヤーです。
答えを見る
正解は「B. Delta Lakeは、信頼性、セキュリティ、パフォーマンスを提供するオープンフォーマットのストレージレイヤーです。」です。他の選択肢は下記の理由から不正解です。詳細はこちらのブログ記事「Delta Lakeとは」もご参照ください。
- A. 分析エンジンではなく、ストレージレイヤーのフォーマットです。
- C. MLFlowの説明です。
- D. 分散データが不明瞭ですが、データの種類(構造化・非構造化)やサイズ、分布を問わず格納可能なストレージフォーマットです。
- E. Delta Lake自体にはデータを処理する機能はありません。レイクハウスプラットフォーム上だとSparkを使ってデータを処理します。
質問9. あるデータアーキテクトは、次のような形式の表が必要であると判断した。

この名前のテーブルがすでに存在するかどうかにかかわらず、上記の形式で空のDelta テーブルを上記のフォーマットで作成するためには次のコードブロックのどれが適切か。
- A.
CREATE OR REPLACE TABLE table_name AS SELECT id STRING, birthDate
DATE, avgRating FLOAT USING DELTA
- B.
CREATE OR REPLACE TABLE table_name (id STRING, birthDate DATE, avgRating FLOAT)
- C.
CREATE TABLE IF NOT EXISTS table_name (id STRING, birthDate DATE, avgRating FLOAT)
- D.
CREATE TABLE table_name AS SELECT id STRING, birthDate DATE, avgRating FLOAT
- E.
CREATE OR REPLACE TABLE table_name WITH COLUMNS ( id STRING, birthDate DATE, avgRating FLOAT) USING DELTA
答えを見る
正解は「B」です。Databricksでテーブルを作成する方法はこちらも参照ください。
他の選択肢は下記の理由から不正解です。
- A. CREATE TABLE AS文はすでに存在するテーブルから新しいテーブルを作成する際に使用します。
- C. CREATE TABLE IF NOT EXISTS を使うと既にテーブルが存在する場合には新しいテーブルが作成されません。
- D. Aと同様の理由で誤りです。
- E. CREATE TABLE table_name WITH COLUMNSという文法はDatabricksは対応しておりません。
質問10. 次のSQLキーワードのうち、既存のDeltaテーブルに新しい行を追加するために使用できるのはどれですか?
- A. UPDATE
- B. COPY
- C. INSERT INTO
- D. DELETE
- E. UNION
答えを見る
正解は「C. INSERT INTO」です。
他の選択肢は下記の理由から不正解です。
質問11. データエンジニアリングチームはDelta テーブルから同じ条件を満たす行を抽出する必要があります。しかし、クエリの実行速度が遅いことに気づき、データファイルのサイズを調整しました。調査した結果、条件を満たす行は各ファイルにまばらに配置されていることがわかりました。次の最適化手法のうち、どれがクエリを高速化できるでしょうか。
- A. データスキッピング
- B. Z-Order
- C. ビンパッキング
- D. パーケット形式で書き込み
- E. ファイルサイズの調整
答えを見る
正解は「B. Z-Order」です。まず小さいファイルが大量にある場合にはIOが大量に発生して、パフォーマンスが低下してしまいます。
そのため、OPTIMIZEコマンドを実行します。その際にカラム内で同じデータを物理的にまとめて配置することでより効率的なデータスキッピングで更にI/O効率を向上させることをデータスキッピングといい、Z-Orderコマンドを使用します。
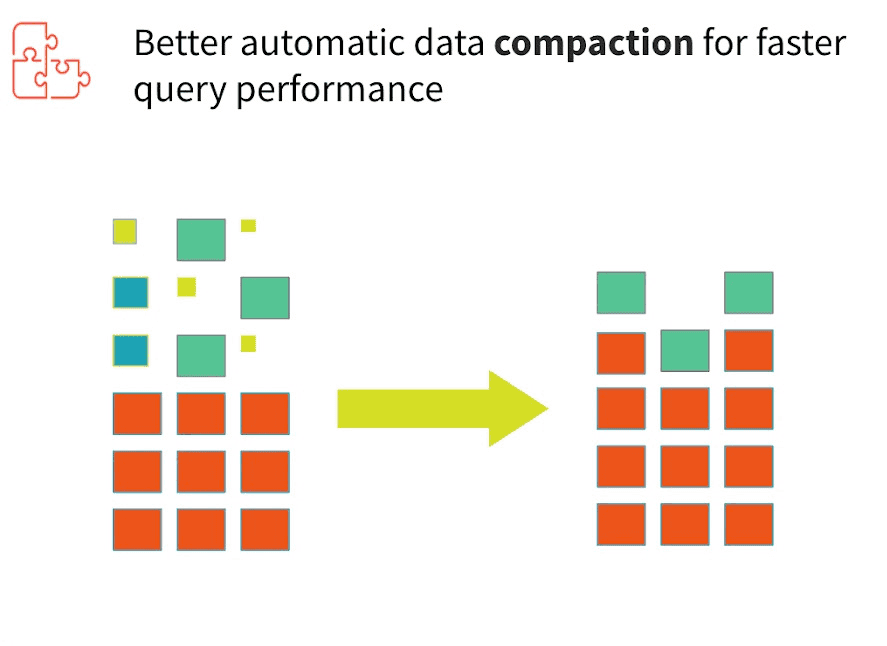
他の選択肢は下記の理由から不正解です。
- A. こちらややこしいですが、データスキッピングは目的であって手段はZ-Orderです。
- C. ビンパッキングのみだとまだ条件を満たす行が各ファイルにまばらになっている可能性があるため、特定のカラムを使ってZ-Orderを実行する必要があります。
- D. Deltaフォーマットはパーケット形式で書き込みを行っています。
- E. ファイルサイズは調整済みです。
質問12. データエンジニアが customer360 というデータベースを /customer/customer360 という場所に作成する必要があります。データエンジニアは、同僚の1人がすでにデータベースを作成しているかどうかわからない。データエンジニアは、このタスクを完了するために次のどのコマンドを実行する必要がありますか?
- A.
CREATE DATABASE customer360 LOCATION '/customer/customer360';
- B.
CREATE DATABASE IF NOT EXISTS customer360;
- C.
CREATE DATABASE IF NOT EXISTS customer360 LOCATION '/customer/customer360'
- D.
CREATE DATABASE IF NOT EXISTS customer360 DELTA LOCATION '/customer/customer360'
- E.
CREATE DATABASE customer360 DELTA LOCATION '/customer/customer360';
答えを見る
正解は「C」です。LOCATIONを書くことでデータの格納場所を指定することができます。
他の選択肢は下記の理由から不正解です。
- A. 同僚が既にデータベースを作成している場合は「既にスキーマが存在する」旨のエラーが発生するため、誤りです。
- B. ロケーションを指定していないため、誤りです。
- D. DELTAは不要です。
- E. Aと同様に同僚が既にデータベースを作成している場合はエラーが発生するため、誤りです。
質問13. ジュニアデータエンジニアは、Sparkがデータとメタデータの両方を管理するSpark SQLテーブルmy_tableを作成する必要があります。メタデータとデータはDatabricks Filesystem (DBFS)に保存される必要があります。このタスクを完了するために、シニアデータエンジニアがジュニアデータエンジニアと共有すべきコマンドは次のうちどれですか?
- A.
CREATE TABLE my_table (id STRING, value STRING) USING org.apache.spark.sql.parquet OPTIONS (PATH "storage-path")
- B.
CREATE MANAGED TABLE my_table (id STRING, value STRING)
USING org.apache.spark.sql.parquet
OPTIONS (PATH "storage-path")
- C.
CREATE MANAGED TABLE my_table (id STRING, value STRING) USING org.apache.spark.sql.parquet
- D.
CREATE TABLE my_table (id STRING, value STRING)
USING org.apache.spark.sql.parquet
OPTIONS (PATH "dbfs:///storage-path")
- E.
CREATE TABLE my_table (id STRING, value STRING)
USING org.apache.spark.sql.parquet
答えを見る
正解は「E」です。Databricks上で作られるデルタフォーマットのテーブルには①Managedと②Unmanagedの2種類が存在する。参照:What is a managed table?
Managed: データ並びにメタデータを管理、DROPする場合には全てのデータが削除される。データはデータベースで指定してLOCATION内に存在する。デフォルトではこちらが作られる。
Unmanaged: メタデータのみをデータブリックスが管理。テーブル名の変更や新規データベースの変更を行う際に、データを移動する必要がない点が利点。
Databricks のレイクハウスにおけるテーブルには managed テーブルと unmanaged (もしくは external) テーブルの2種類がある。managed テーブルでは Databricks がメタデータとデータそのものを両方管理するが、unmanaged テーブルではメタデータのみを管理する。そのため、managed テーブルをドロップすると裏側にあるデータも削除されるが、unmanaged テーブルではデータは削除されない。unmanaged テーブルではテーブル名を変更した際でもデータを移動せずにデータベースに再登録することができるという利点がある。CREATE TABLE するときのデフォルトの挙動では managed テーブルが作成される。unmanaged テーブルを作成したい場合は LOCATION '/path/to/existing/data' のようにデータのパスを指定する。今回はデータとメタデータの両方を管理するテーブル、つまり managed テーブルを作るので E が正解となる。
他の選択肢は下記の理由から不正解です。
- A. OPTIONS句の中身が絶対パスではないため、エラーが発生します。
- B. A.同様にエラーが発生します。
- C. MANAGEDは不要です。デフォルトでManagedテーブルを作成します。
- D. PATHを指定する必要はありません。
質問14. あるデータエンジニアが、2つのテーブルからデータを取り出してリレーショナルオブジェクトを作成したいと考えています。この リレーショナル・オブジェクトは、他のセッションで他のデータ・エンジニアが使用する必要があります。ストレージのコストを削減するために ストレージコストを節約するために、データエンジニアは物理データのコピーと保存を避けたいと考えています。データエンジニアは次のどのリレーショナルオブジェクトを作成する必要がありますか?
- A. ビュー
- B. テンポラリービュー
- C. デルタテーブル
- D. データベース
- E. SparkSQLテーブル
答えを見る
正解は「A」です。ビューは物理データを持ちませんが、該当のセッションが切れても削除されません。他の選択肢は下記の理由から不正解です。参照:CREATE VIEW
- B. テンポラリービューはセッションが消えたら削除されてしまうため、誤りです。
- C. デルタテーブルは物理データを持つので誤りです。
- D. データベースもCと同様に物理データを持つので不適切です。
- E. C、D同様に物理データを持つので不適切です。
質問15. あるデータエンジニアリングチームが、外部システムに保存されている Parquet データを使用して、一連のテーブルを作成しました。このチームは、外部システムのデータに新しい行を追加した後、Databricks のクエリで新しい行が返されないことに気づきました。彼らは、この問題の原因として、以前のデータのキャッシュを特定します。次のどのアプローチが、クエリによって返されるデータが常に最新であることを保証しますか?
- A. テーブルをDelta形式に変換する必要があります。
- B. テーブルをクラウドベースの外部システムに保存する必要があります。
- C. テーブルは、次のクエリを実行する前に、書き込みクラスタ内でリフレッシュされるべきです。
- D. テーブルは、キャッシュしないようにメタデータを含むように変更する必要があります。
- E. 次のクエリを実行する前にテーブルを更新する必要があります。
答えを見る
正解は「A」です。デルタ形式に変更することで、データソースに変更を施した際のACIDトランザクションが適用されます。
他の選択肢は下記の理由から不正解です。
- B. テーブルの所在ではキャッシュの更新について機能差はありません。
- C. 自動で更新されないので、最も良い答えではありません。
- D. キャッシュしないようにしても、デルタテーブルではない場合はデータソースの読み込み一貫性を保証しません。
- E. REFRESH TABLEを行えばDelta Cacheも更新されるが手間がかかるため、最も良い答えではありません。
質問16. customerLocations テーブルは以下のスキーマで存在します。
id STRING,
date STRING,
city STRING,
country STRING
シニアデータエンジニアは、このテーブルから次のコマンドを使用して新しいテーブルを作成することを望んでいます。
CREATE TABLE customersPerCountry AS
SELECT country,
COUNT(*) AS customers
FROM customerLocations
GROUP BY country;
ジュニアデータエンジニアが、新しいテーブルに対してスキーマを宣言しない理由を尋ねました。次の回答のうち、スキーマの宣言が必要ない理由を説明するものはどれですか?
- A. CREATE TABLE AS SELECTステートメントは、ソーステーブルからスキーマの詳細を採用する
- B. CREATE TABLE AS SELECT文は、データをスキャンすることによってスキーマを推測します。
- C. CREATE TABLE AS SELECT ステートメントは、スキーマがオプションであるテーブルを生成します。
- D. CREATE TABLE AS SELECT文は、すべての列にSTRING型を割り当てます。
- E. CREATE TABLE AS SELECT ステートメントは、スキーマをサポートしないテーブルをもたらします。
答えを見る
正解は「A」です。CREATE TABLE AS SELECT(CTAS)ステートメントはソーステーブルのスキーマ情報を採用してテーブルを作成します。
他の選択肢は下記の理由から不正解です。
- B. CTASステートメントはスキーマを推測しません。
- C. スキーマは任意ではなく必須ですが、ソーステーブルのスキーマを踏襲します。
- D. 誤りです。
- E. スキーマはサポートされます。
質問17. あるデータエンジニアは、テーブルを削除し、テーブルを再作成することによって、テーブルのデータを上書きしています。別のデータエンジニアは、これは非効率的であり、テーブルを単純に上書きするべきだと提案します。テーブルを削除して再作成する代わりに、テーブルを上書きする次の理由のうちどれが正しくないですか?
- A. テーブルの上書きは、ファイルを削除する必要がないため、効率的です。
- B. テーブルを上書きすると、ロギングと監査用にテーブルの履歴がきれいになる。
- C. テーブルの上書きは、タイムトラベルのために古いバージョンのテーブルを維持します。
- D. テーブルの上書きはアトミックな操作であり、テーブルを未完成の状態にすることはない。
- E. テーブルの上書きを実施している際に、同時進行のクエリが完了させることができます。
答えを見る
正解は「B」です。Delta Formatのテーブルを上書きしてもテーブルのトランザクション履歴は削除されずに保持されます。一方でDROPしてから再作成する場合は履歴が削除されます。
他の選択肢は下記の理由から不正解です。
- A. 正しいです。
- C. 正しいです。デフォルトで30日のデータを保持しています。
- D. 正しいです。Delta FormatのテーブルはACIDサポートしています。
- E. 正しいです。
質問18. 次のコマンドのどれが、既存のDeltaテーブルmy_tableから重複削除されたレコードを返すか?
- A.
DROP DUPLICATES FROM my_table;
- B.
SELECT * FROM my_table WHERE duplicate = False;
- C.
SELECT DISTINCT * FROM my_table;
- D.
MERGE INTO my_table a USING new_records b ON a.id = b.id WHEN
NOT MATCHED THEN INSERT *;
- E.
MERGE INTO my_table a USING new_records b;
答えを見る
正解は「C」です。SELECT DISTINCT句を使うと重複レコードが削除されます。
他の選択肢は下記の理由から不正解です。
- A. DROP DUPLICATESという文法は存在しません。
- B. WHERE duplicate = Falseという文法は存在しません。
- D. こちらはUPSERTと呼ばれる処理で、MERGE句を使用します。
- E. MERGE句はON条件が必要です。
質問19. あるデータエンジニアが、クエリの一部として2つのテーブルを水平に結合させたいと考えている。彼らは共有カラムをキーカラムとして使用し、キーカラムの値が両方のテーブルに存在する行だけをクエリ結果に含めたいと考えています。このタスクを達成するために、次のSQLコマンドのうちどれを使用することができますか?
- A. INNER JOIN
- B. OUTER JOIN
- C. LEFT JOIN
- D. MERGE
- E. UNION
答えを見る
正解は「A」です。水平方向の結合、共有のカラムをキーとして使用するという条件からINNER JOINを使うことがわかります。他の選択肢は不正解です。こちらのリンクSQLでテーブル間を結合する方法まとめがわかりやすいのでご参照ください。
- B. OUTER JOIN
- C. LEFT JOIN
- D. MERGE
- E. UNION
質問20. ジュニアデータエンジニアは、JSONファイルを以下のスキーマを持つテーブルraw_tableにインジェストしました。
cart_id STRING,
items ARRAY [item_id:STRING]
ジュニア・データ・エンジニアは、raw_table の items カラムをアンネストして、以下のスキーマを持つ新しいテーブルを作成したいと考えています。
cart_id STRING,
item_id STRING
このタスクを完了するために、ジュニアデータエンジニアは次のどのコマンドを実行する必要がありますか?
- A.
SELECT cart_id, filter(items) AS item_id FROM raw_table;
- B.
SELECT cart_id, flatten(items) AS item_id FROM raw_table;
- C.
SELECT cart_id, reduce(items) AS item_id FROM raw_table;
- D.
SELECT cart_id, explode(items) AS item_id FROM raw_table;
- E.
SELECT cart_id, slice(items) AS item_id FROM raw_table;
答えを見る
正解は「D」です。explodeはARRAY/MAPのような入れ子構造のデータを展開して値を列にする際に使用します。他の選択肢は不正解です。
質問21. ジュニアデータエンジニアは、JSONファイルを以下のスキーマを持つテーブルraw_tableにインジェストしました。
transaction_id STRING,
payload ARRAY [customer_id:STRING, date:TIMESTAMP, store_id:STRING]
データエンジニアは、各トランザクションの日付を以下のスキーマのテーブルに効率的に抽出したいと考えています。このタスクを完了するために、データエンジニアは次のどのコマンドを実行する必要がありますか?
transaction_id STRING,
date TIMESTAMP
- A. SELECT transaction_id, explode(payload) FROM raw_table;
- B. SELECT transaction_id, payload.date FROM raw_table;
- C. SELECT transaction_id, date FROM raw_table;
- D. SELECT transaction_id, payload[date] FROM raw_table;
- E. SELECT transaction_id, date from payload FROM raw_table;
答えを見る
正解は「B」です。Arrayの値を取得するためにはArray.Elementで取得します。
質問22. あるデータアナリストが、データエンジニアリングチームに以下のSpark SQLクエリを提供しました。
SELECT district,
avg(sales)
FROM store_sales_20220101
GROUP BY district;
データアナリストは、データエンジニアリングチームが毎日このクエリを実行することを希望しています。テーブル名の末尾にある日付(20220101)は、クエリを実行するたびに、自動的に現在の日付に置き換えられる必要があります。このプロセスを効率的に自動化するために、データエンジニアリングチームが使用できるアプローチはどれか?
- A. PySpark を使ってクエリをラップし、Python の文字列変数システムを使って、テーブル名を自動的に更新することができます。自動的にテーブル名を更新します。
- B. テーブル名の中の日付を、手動で現在の日付に置き換えることができる。日付に置き換える。
- C. データアナリストに、クエリの実行頻度を減らすように書き換えるよう依頼することができる。
- D. テーブルの文字列形式の日付をタイムスタンプ形式の日付に置き換えることができる。
- E. PySpark にテーブルを渡して、既存のクエリに対して堅牢にテストされたモジュールを開発することができます。
答えを見る
正解は「A」です。Pythonの変数を使うことでテーブル名を自動で変換することができます。
- B. 手動で置換することは非効率です。
- C. 実行頻度を減らしても手動の箇所は変わらないので非効率です。
- D. タイムスタンプに変更しても手動の箇所は変わらないので非効率です。
- E. 「PySparkにテーブルを渡す」が不明です。
質問23. あるデータエンジニアが、外部ソースからPySpark DataFrame raw_dfにデータを取り込みました。彼らは、データアナリストがデータの品質保証チェックを行うために、このデータをSQLで簡単に利用できるようにする必要があります。データの品質保証チェックを行うために、このデータをSQLで簡単に利用できるようにする必要があります。データエンジニアは、Sparkセッションの残りの時間だけこのデータをSQLで利用できるようにするために、次のどのコマンドを実行する必要がありますか?
- A. raw_df.createOrReplaceTempView("raw_df")を実行します。
- B. raw_df.createTable("raw_df")を実行します。
- C. raw_df.write.save("raw_df")を実行します。
- D. raw_df.saveAsTable("raw_df")。
- E. PySpark と SQL の間でデータを共有する方法はありません。
答えを見る
正解は「A」です。Temp ViewはSparkセッションの間のみ有効です。
- B. テーブルはセッションが切断されても永続的に残るため、不正解です。
- C. .saveは特定のパスにファイルとして出力するためのコマンドです。
- D. B同様にテーブルが作成されるため不正解です。
- E. Aを含めて方法は存在するので、誤りです。
質問24. データエンジニアは、3つのPython変数:region、store、yearを使用して、動的にテーブル名文字列を作成する必要があります。 region = "nyc"、store = "100"、year = "2021"の場合のテーブル名の例はnyc100_sales_2021です。データエンジニアがPythonでテーブル名を構築するために使用すべきコマンドは次のうちどれですか?
- A.
"{region}+{store}+_sales_+{year}"
- B.
f"{region}+{store}+_sales_+{year}"
- C.
"{region}{store}_sales_{year}"
- D.
f"{region}{store}_sales_{year}"
- E.
python{region}+{store}+"_sales_"+{year}
答えを見る
正解は「D」です。Pythonではf文字列を使うと変数を文字列に組み込むことができます。
質問25. データエンジニアは、データソース上のストリーミング読み取りを実行するためのコードブロックを開発しました。 コードブロックは以下のとおりです。
(spark
.read
.schema(schema)
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load(dataSource)
)
コードブロックはエラーを返しています。ストリーミング読み取りを正常に実行するようにブロックを構成するために、以下のうちどの変更を行う必要がありますか?
- A. .read行を .readStreamに置き換える必要がある。
- B. .read行の後に新しい .stream 行を追加する必要がある。
- C. .format("cloudFiles") 行を .format("stream") に置き換える必要がある。
- D. sparkの後に新しい .stream 行を追加する必要がある。
- E. .load(dataSource) 行の後に新しい .stream 行を追加する必要がある。
答えを見る
正解は「A」です。ストリーミング処理を行う際は、readStreamを使用します。
- B. こちらの文法はありません。
- C. format("cloudFiles")は
- D. read.streamという文法はないので誤りです。
- E. こちらの文法はありません。
質問26. データエンジニアは、構造化ストリーミングジョブを構成して、テーブルから読み取り、データを操作し、新しいテーブルにストリーミング書き込みを実行するようにしました。を行い、その後新しいテーブルにストリーミング書き込みを行う。データエンジニアが使用するコード ブロックは次のとおりです:
(
spark.table("sales")
.withColumn("avg_price", col("sales") / col("units"))
.writeStream
.option("checkpointLocation", checkpointPath)
.outputMode("complete")
._____
.table("new_sales")
)
データエンジニアが、クエリに1つのマイクロバッチを実行させて、利用可能なすべてのデータを処理させたいだけであれば、次のコードのうちどれを実行すればよいでしょうか。空白を埋めるために使用するコードはどれですか?
- A. trigger(once=True)
- B. trigger(continuous="once")
- C. processingTime("once")
- D. trigger(processingTime="once")
- E. processingTime(1)
答えを見る
正解は「A」です。利用可能な全てのデータを処理する際にはtrigger(once=True)を使います。DBR11.3以上ではtrigger.AvailableNowを使用することが推奨されます。triggers
- B. こちらの文法はありません。
- C. format("cloudFiles")は
- D. read.streamという文法はないので誤りです。
- E. こちらの文法はありません。
質問27. データエンジニアがデータパイプラインを設計しています。ソースシステムは共有ディレクトリにファイルを生成し、他のプロセスも同じディレクトリを使用しています。その結果、ファイルはそのままに保持され、ディレクトリに蓄積されます。データエンジニアは、前回のパイプライン実行以降に新しく生成されたファイルを特定し、各実行でそれらの新しいファイルのみを取り込むようにパイプラインを設定する必要があります。
この問題を解決するためにデータエンジニアが使用できるツールは次のうちどれでしょうか?
- A. Databricks SQL
- B. Delta Lake
- C. Unity Catalog
- D. Data Explorer
- E. Auto Loader
答えを見る
正解は「E」です。AutoLoaderを設定すると、新しいデータファイルがクラウドストレージに到着した際に、追加設定なしで処理することができます。
- A. Databricks SQLはDatabricks上で使用できるデータウェアハウスです。
- B. Delta Lakeはストレージレイヤーのフォーマットであり、それ自体に自動でファイルを取り込む機能はありません。
- C. Unity CatalogはDatabricksにおけるデータ・AIのガバナンスモデルであり、本問とは関係ありません。
- D. Data Explorerはデータやメタデータを参照するための機能であり、本問とは関係ありません。
質問28. データエンジニアリングチームは、既存のデータパイプラインを変換して、JSONファイルの取り込みにAuto Loaderを利用するプロセスにあります。あるデータエンジニアは、Auto Loaderのドキュメントで以下のコードブロックを見つけました:
(streaming_df = spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.schemaLocation", schemaLocation)
.load(sourcePath))
- A. データエンジニアは、format("cloudFiles")の行をformat("autoLoader")に変更する必要があります。
- B. 変更は必要ありません。Databricksは自動的にストリーミング読み取りにAuto Loaderを使用します。
- C. 変更は必要ありません。format("cloudFiles")の含まれていることにより、Auto Loaderが使用可能になります。
- D. データエンジニアは、.autoLoader行を.load(sourcePath)の前に追加する必要があります。
- E. 変更は必要ありません。データエンジニアは、Auto Loaderを有効にするように管理者に依頼する必要があります。
答えを見る
正解は「C」です。AutoLoaderの設定にはformat("cloudFiles")を指定するだけです。
- A. こちらの指定は不要です。
- B. Databricksが自動的にAutoLoaderを使うわけではなく、format("cloudFiles")が指定された場合にAutoLoaderを使用します。
- D. こちらの設定は不要です。
- E. AutoLoaderを使用するために必要な設定は上記のみで、管理者に依頼する必要はありません。
質問29. 次のデータワークロードのうち、Bronzeテーブルをそのソースとして使用するものはどれですか?
- A. クリーンデータを集計して標準のサマリー統計を作成するジョブ
- B. 集計されたデータをクエリしてダッシュボードに主要な洞察を公開するジョブ
- C. ストリーミングソースから生データをLakehouseに取り込むジョブ
- D. 機械学習アプリケーションのための特徴セットを開発するジョブ
- E. タイムスタンプを人間が読み取り可能な形式に解析してデータを豊かにするジョブ
答えを見る
正解は「E」です。BronzeテーブルをソースとするSilverテーブルの記載です。
- A. クリーンデータから結果集計するGold Tableの記載です。
- B. Gold Tableに対してクエリを実行する記載です。
- C. Bronzeテーブルを作成する記載です。
- D. Gold Tableを使用して機械学習モデルを開発する記載です。
質問30. 次のデータワークロードのうち、Silverテーブルをそのソースとして使用するものはどれですか?
- A. タイムスタンプを人間が読み取り可能な形式に解析してデータを豊かにするジョブ
- B. 既にダッシュボードにフィードされている集計データをクエリするジョブ
- C. ストリーミングソースから生データをLakehouseに取り込むジョブ
- D. クリーンデータを集計して標準のサマリー統計を作成するジョブ
- E. 異常な形式のレコードを削除することでデータをクリーンにするジョブ
答えを見る
正解は「D」です。SilverテーブルをソースとするGoldテーブルの記載です。
おわりに
この記事ではDatabricksデータエンジニアアソシエイト試験の公式練習問題(リンク)のQ1-15を翻訳・解説してみましたが、いかがでしたでしょうか。
皆さんが今後試験を受ける際に少しでもお役に立てましたら幸いです。また、何かコメントなどあればご連絡ください。
最後に記事を読んで少しでもためになったと思われた方は「いいね」や記事の保存、SNSでシェアいただけると嬉しいです!
需要があれば(10いいね以上で25問目まで追加、25いいね以上で35問目まで追加、40いいね以上で45問目まで追加)、以降の質問についても翻訳・解説しようと思います。また今後読みたい記事などもコメントいただけると幸いです。
参照記事
Qiitaで良い記事を書く技術: https://qiita.com/t12u/items/8c28484100dfd3a6351b