Universal Language Model Fine-tuning for Text Classification
汎用性が高く性能の良いNLP向けの転移学習手法の提案
Wikipediaのような入手しやすい言語資源を利用することで、少量のラベル付きデータで良い性能を出せることを示している
- 論文
- 特設ページ
- Q&A
- コード(Pytorchベース)
-
Fast.aiのCourse
(本内容が扱われている)
ハイライト
- 汎用性の高いNLP向けの転移学習手法を提案
- 従来の転移学習の際に生じる情報消失を防ぐ学習法の提案
- 6つの分類タスクでSOTAに比べて18-24%のerror rateの低減を達成
- サンプル効率が高い(少ないサンプルで性能を出せる)
- モデルとコードを提供
学習方法の提案で、新しいネットワークアーキテクチャの提案ではない。
数式はほぼ出てこない。
背景
- CVは転移学習の恩恵に浴していて羨ましい
- NLPではDNNによってSOTAの成果を得られてはいるが、多くはスクラッチからの学習が必要
- 既存手法のLanguage Model は、膨大なin-domain documentが必要
- → in-domain document集めるの大変だし、転移学習とかでなんとかなれば...
現在のNLPにおける転移学習事情
- NLPでは、Transductive transfer 1 が主な研究対象とのこと
- Inductive transfer2の例としては、事前学習したembedding layerをinputにおいて全体を学習するパターンが流行
- モデリングしなければいけない上層の範囲が大きい
- しかし、CVでの転移学習と比べると、お手軽さが低い
- より便利なNLP用の転移学習モデルが欲しい
方針
- NLPのモデルとして汎用性のあるものを使って転移学習できるようにする
- モデルではなく学習の方法を工夫する
- fine-tuningする際に事前学習した情報が失われてしまうのが問題
- NLPはCVに比べて浅いネットワークなので、CVとは違ったアプローチが必要となるはず
Universal Language Model Fine-tuning (ULMFiT)
-
Language Model(LM; ngramのニューラルネット版)を source taskとする
- 多くの応用の重要な要素である
- 様々な言語的な特徴を捉えることができる
- MT等と比べて、無限に近いデータがある
- etc.. と、理想的なsource taskに見える
-
実用的なメリット
- 様々なドキュメントサイズについてworkする
- single architecture/training process
- 追加のfeature engineering不要
- in-domain documents/labelsが不要
-
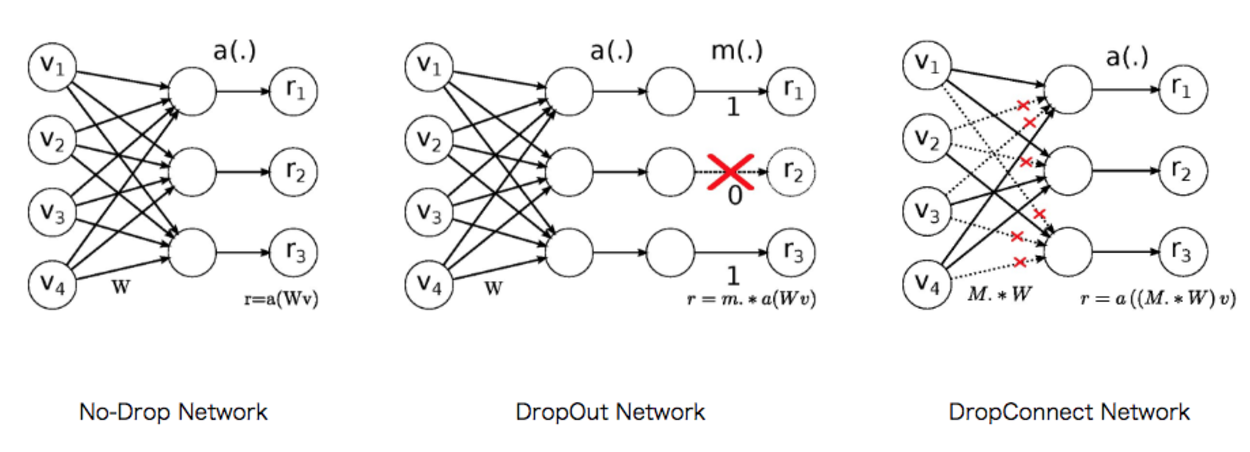
今回ベースとするモデルはAWD-LSTM
- → 3層LSTM+DropConnect3+SGDの変形で頑張った手法)
-
また、クラス分類をtarget taskとする
学習の流れ
- General-domain LM pretraining
- 大規模なGeneral-domain corpusでLMを事前学習
- Target task LM fine-tuning
-
- のLMをTarget taskのコーパスを用いてfine-tuning
-
- Target task classifier fine-tuning
-
- のLMをベースとしてTarget taskのclassifierを構成し、fine-tuning
-

1. General-domain LM pretraining
はじめに、General-domain corpusにより、LMを一から学習する。
- CVにおけるImageNetのように、大規模で言語の一般的な特徴を捉えることのできるコーパスを対象としてpretrainするのが良い
- 論文中ではWikitext-103を選択
- 28,595 preprocessed Wikipedia articles
- 103 million words.
この計算コストは高いけど、結果は使いまわせるから気にならないよね。
2. Target task LM fine-tuning
次に、1. の学習済みモデルに対し、Target taskのコーパスを使い、fine-tuningを行う。
ここでは学習に際し、Discriminative fine-tuning と Slanted triangular learning rate という2つのテクニックを用いる。
Discriminative fine-tuning
- 階層化した各レイヤはそれぞれ違った抽象度/情報を捉える
- → 各々に適した"程度"でfine-tuningするのがよさそう
- → それぞれのレイヤ毎で別のlearning-rateをとる
- → レイヤごとのパラメータ $\theta^l$に、それぞれ異なる学習率$\eta^l$を用意する
これを
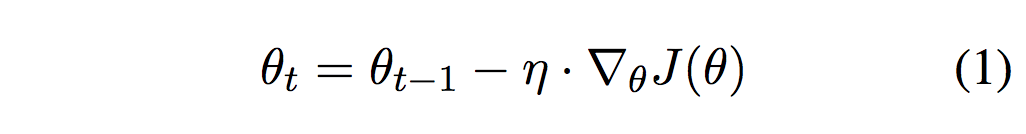
こうする。
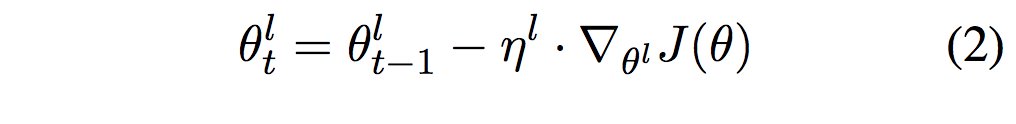
もちろんSGDである必要はない。
- ηl-1 = ηl / 2.6 が経験的にうまくいくとのこと
- (実装を見る限り、fine-tuningの時は違うパラメータ使っていように見えるが...)
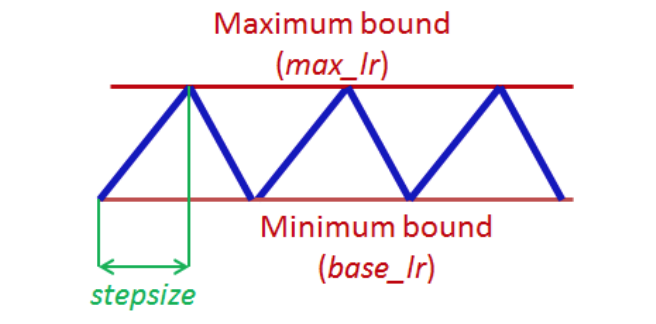
Slanted triangular learning rates
- Learning rateをiterationが進むごとにどのように変化させていくか
-
Cyclical learning rates(Triangular learning rates)4の派生形
- 短期間でlearning rateが増加
- その後徐々にlearning rateが減少
- ピークが$\eta^l$となり、それに対する比率で増減させる

3. Target task classifier fine-tuning
最後に、2. のモデルを使いTarget taskのclassifierを構成し、学習する。
- classifierの構成に際し、3.2のモデルに以下の2層を追加
- batch normalization/dropout/ReLU
- batch normalization/dropout/Softmax → output
- ここでも学習に際し、いくつかの工夫を入れる。
Concat pooling
- 分類タスクにおける重要な語は、文書中に点在するごく少数の語彙になる
- → 最後のtime stepのhidden state(${\bf{h}}_T$)のみの考慮ではうまくいかない。
- → 前方のtimestepsのhidden statesも考慮するようにする
- (ただしメモリの許す限り)

Gradual unfreezing
- 事前学習で得られた有益な情報がfine-tuningで消えてしまうのを避けるための工夫
- 最初にlast layerをunfreezeする(パラメータのupdateが効くようにする)
- epochごとにunfreezeするレイヤを増やしていく
(実装では3ステージに分けて、最終層のみ, 最終層+一つ前, 全部の順でunfreezeしてtrainingを回している様子)
BPTT for Text Classification (BPT3C)
- documentを固定長のバッチ に分割
- モデルは前のバッチの最後の状態で初期化
Bidirectional language model
- 順方向と逆方向のコーパスを作って独立に学習して、classifierの予測結果を平均する
Experiments
実験タスクと利用するデータセット
- Sentiment Analysis
- IMDb
- Yelp
- Question Classification
- TREC-6
- Topic classification
- large-scale AG news
- DBPedia ontology datasets

結果
IMDb / Trec-6

- CoVe(転移学習のSOTA)に対して43.9/22% error rateの低減
- CoVeのような転移学習以外の手法と比較してもより良い結果
- 複雑なアーキテクチャを採用しなくても、LSTMにdropoutを加えただけのモデルでSOTAを上回る性能
- IMDbは現実的なデータに近いからpromissing
- TREC-6は大幅な改善とはなっていない
- テストセットが500と小さいため
- 1文からなる小さいデータから、比較的大きなデータも扱えるのは有益
- CoVeみたいに膨大な量(7 million sentences)のデータも必要としない
AG / DBPedia / Yelp

- これらについても軒並みうまくいっている
- error rateの逓減率
- AG: 23.7%
- DBpedia 4.8%
- Yelp-bi 18.2%,
- Yelp-full 2.0%
Analysis
Low-shot learning
- ラベル付きデータが少ない場合の振る舞いを調べる
- 転移学習のメリットを確認
- supervisedとsemi-supervisedでの実験

- ラベル付きデータ100サンプル+転移学習の時の数字が、10〜20倍のラベル付きデータを用いてスクラッチで学習した時の数字と同等
- さらに50k〜100kのラベルなしのデータを利用することで、50〜100倍のラベル付きデータを用いてスクラッチで学習した時の数字と同等
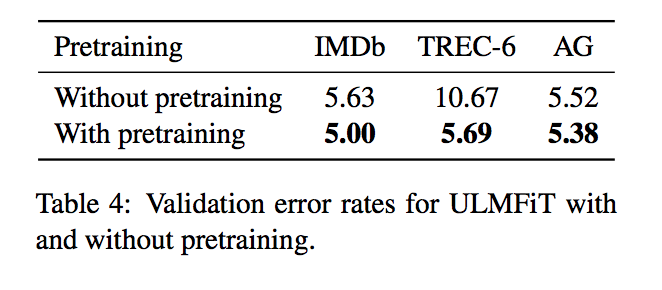
Impact of pretraining
- WikiText-103でのpretraining有無での比較
- データセットが小さい(TREC-6)場合、大きな改善がある
- データセットが大きい(IMDb/AG)場合でも、数字の改善に寄与
Impact of LM quality
- ベースとなるモデルがシンプルなものである場合の性能
- Vanilla LM (AWD-LSTMからDropoutを外したもの)
- モデルがシンプルであるにも関わらず、良い数字が出ている

Impact of LM fine-tuning
- LM fine-tuningでの各種のテクニックのablation
- 小さいデータセット(TREC-6)の場合、Full+discr+stlrでないと効果が無い
- 大きいデータセット(IMDb/AG)では、fine-tuningの効果を得やすい

Impact of classifier fine-tuning
-
classifier fine-tuningでの各種のテクニックのablation、および別手法との比較
- スクラッチから学習するよりfine-tuningした方がうまくいく
- 特にデータセットが小さい時に有効
- 最終層だけのFine-tuningは、小さいデータセットの時に特にunderfitしがち
- chain-sawはかなり良い結果だが、AGの結果は少し弱い
- cosは小さいデータに弱い
-
ボード上、どれにも良い結果を出しているのはULMFiTだけ
- (論文中には、だからuniversalなんだと書いてある)

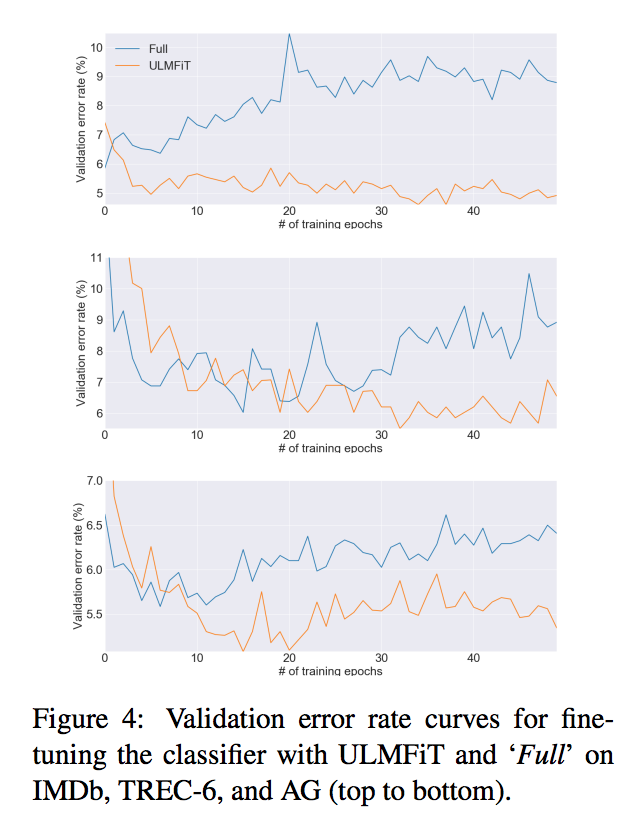
Classifier fine-tuning behavior
- classifierのfine-tuningの「やり方」の違いで学習がどのように進むか
- 各種テクニックを利用したものと、それらなしでfine-tuningしたものとの比較
- validation error rateの推移
Impact of bidirectionality
- 順方向、逆方向のコーパスそれぞれで個別に学習したモデルのアンサンブルの性能差
- Unidirectionalなモデルに比べて、error rateが0.5-0.7くらいさらに改善する
- IMDBでは、error rateが5.30 -> 4.58と改善
感想
- 触れ込みの通り、LMをベースにしているため、色々なNLPタスクに使えそうに思える
- 英語と比較すると、日本語のアノテーション済みコーパスは少ないため、本当に使いものになるなら恩恵が大きい
- また、実応用ではラベル付きデータが少ないことはよくあるので、うまくいくなら嬉しい
- アーキテクチャはシンプルだしコードも公開されているので理解はしやすい