はじめに
前回投稿した OpenVINO で Face re-identification (顔再識別) をもとに、「リアルタイムの顔識別」、「似ている人検索」のデモUIを作成しました。顔検出するとともにそれが「誰か」を識別します。
- リアルタイム顔識別 (YouTube Link になってます)
- 似ている人検索
コードは Github: face_reidentification_demo に上げました。
環境
- Windows 10 (CPU: Core i5-7200U , RAM: 16GB)
- OpenVINO 2018 R51
- Python 3.6
- Flask 1.0.2
リアルタイム顔識別
顔の識別には Intel OpenVINO の Face re-identification モデルを使っています。
このモデルでは入力した顔画像の特徴ベクトルを出力します。比較対象とする顔との コサイン類似度 を求めることで「似てる度」を数値化することができます。
学習なしに汎用的な使い方ができるのがこのモデルの素晴らしいところだと思います。
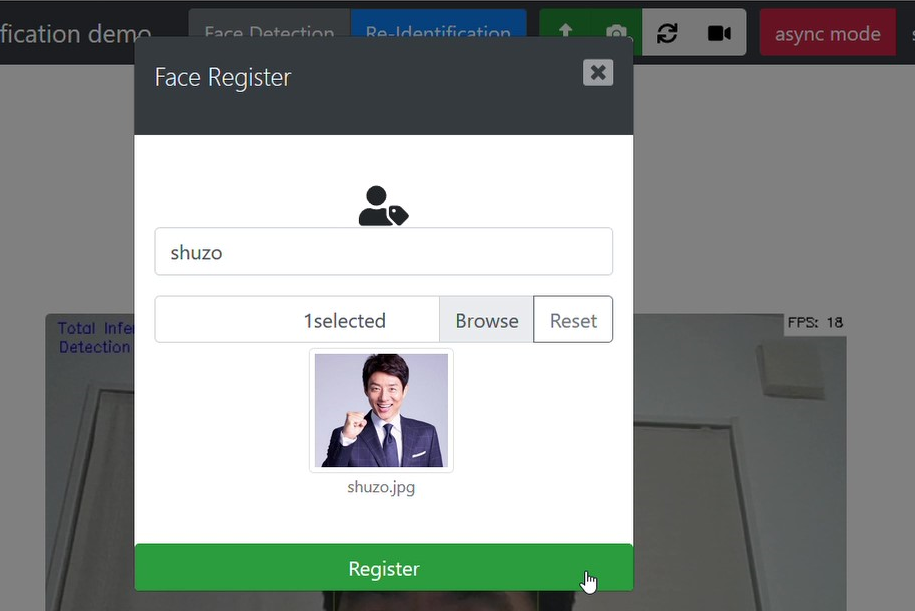
顔の登録
まずは顔を登録します。
- カメラストリーミングからのキャプチャ、または画像をアップロードして顔を登録します。
- 1枚の画像に複数の顔がある場合は一度に顔登録ができます。
- 登録した顔はラベルの編集・削除ができます。
顔の識別
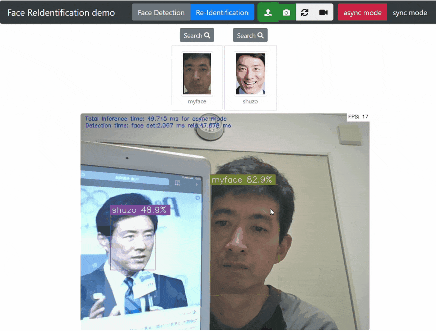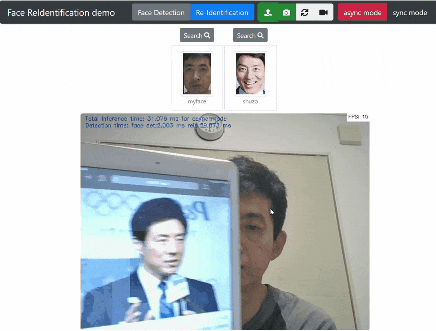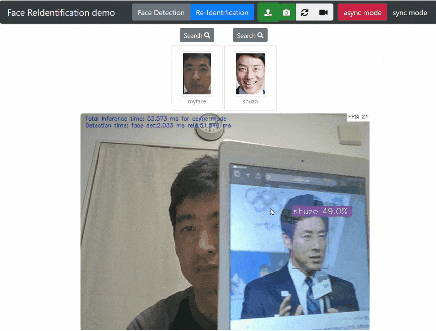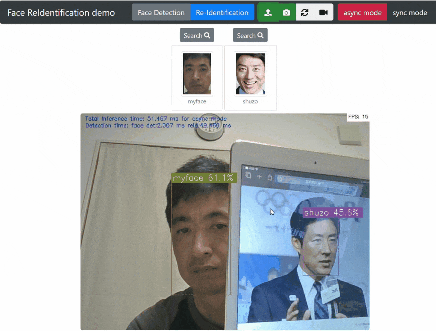
Re-Identification ボタンをクリックすると 登録した顔 と カメラストリーミングの顔 をリアルタイムで識別します。
試行錯誤の結果、類似度 が 40% を超える場合に描画するようにしました。(目をつぶっていたり、髭があっても47% の類似度を示しています。)
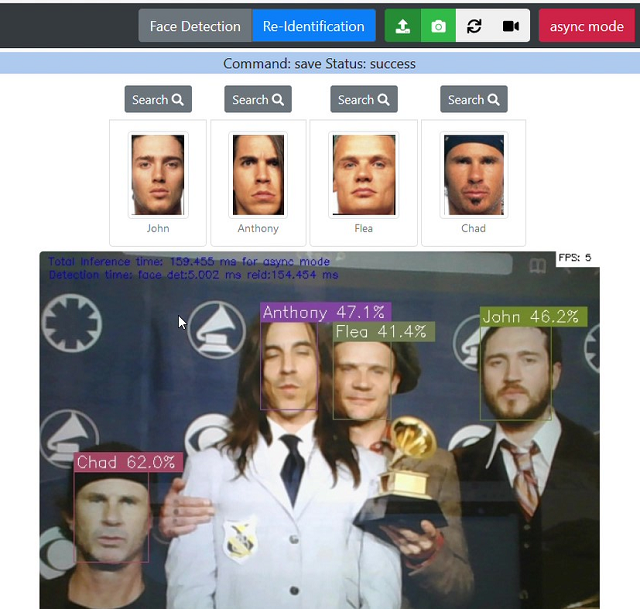
リアルタイムで処理する顔の数(ストリーミングの顔)が多いと処理が重くなる2ので 4つに制限しました。
# Threshold of similarity to draw result on faces
sim_threshold = 0.4
# Limit count to infer face reidentification
fi_limit = 4
...
# ----------- Face re-identification ---------- #
if is_fi and face_vecs.any():
inf_start = timer()
# select 'fi_limit' faces. Too many faces effect performance.
feature_vecs, aligned_faces = self.preprocess(
face_frames[:fi_limit])
inf_end = timer()
...
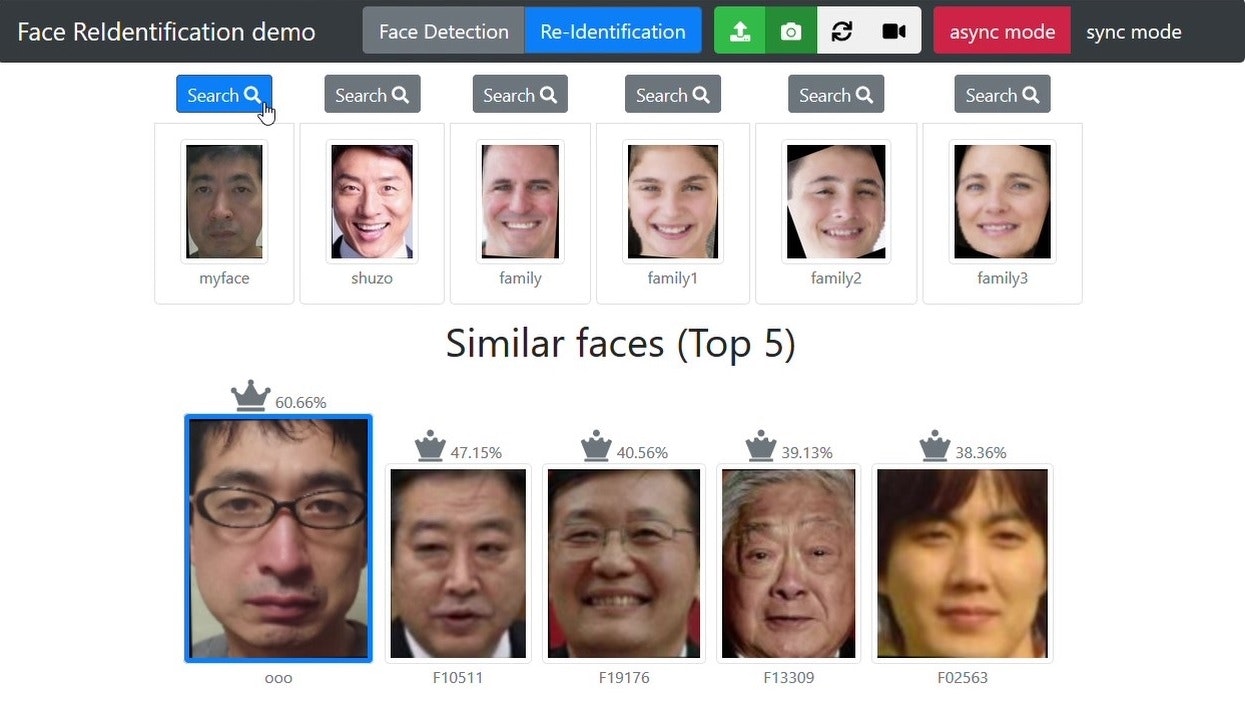
似ている人検索
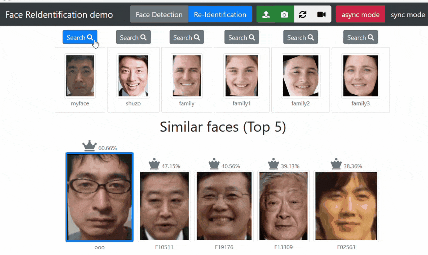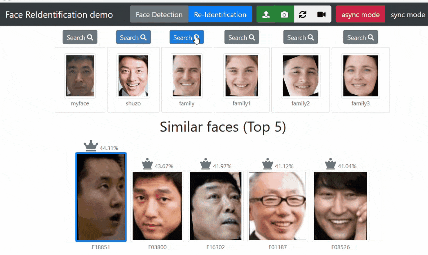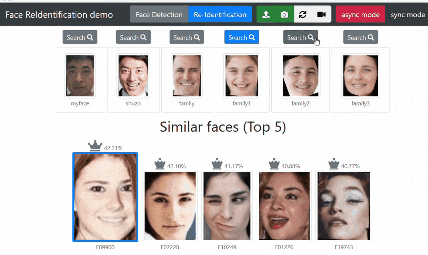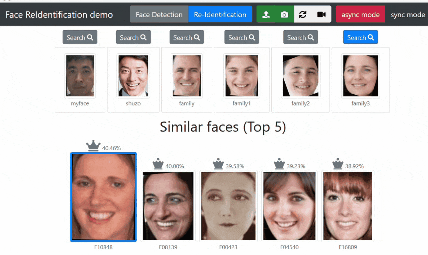
Search ボタンをクリックすると「対象の顔」と似ている顔をデータベースから検索します。
眼鏡をかけた自分の顔 を顔データベースに登録してテストしましたが無事に識別できました。
私の場合、結構な頻度で野田元首相に似ている(下の画像では 47 %)という結果になります。
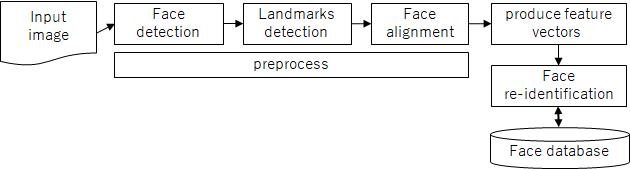
顔検索の処理フローです。入力画像 (Input image) を前処理 (preprocess) して顔の特徴ベクトルを生成し、顔データベースと照合して識別します。
前処理 (preprocess) では、顔検出 > ランドマーク検出 > 顔の回転 > 特徴ベクトルの生成を行います。
顔データベースの作成
上の例では、CelebA のデータセット (202,599 face images. Size 1.3 GB)のうち、2万人分の顔データベースを作成して検索しました。
- CelebAのページにある Google Drive リンクの CelebA > img > img_align_celba.zip
- 2万人の顔は単純にファイルの始めから 1 ~ 20000 枚の画像を選択
顔データベースは、スクリプトで簡単に作成できるようにしました。
python registrar.py
usage: registrar.py [-h] [-i INPUT] [-d {CPU,GPU,FPGA,MYRIAD}]
[--label LABEL [LABEL ...]] [--csv CSV] [--dbname TARGET]
[--batch_size BATCH_SIZE]
{create,update,change,list,show,remove,csv_register}
registrar.py: error: the following arguments are required: method
以下は、csvファイルから登録する例です。
csvフォーマット
imagepath,label
/path/to/celeba/img_align_celeba\000001.jpg,F00001
/path/to/celeba/img_align_celeba\000002.jpg,F00002
..
/path/to/celeba/img_align_celeba\020000.jpg,F20000
csvから登録するコマンド (途中で エラーになることがあるので、batch_size で指定した数毎に保存。途中の エラーは無視。)
python registrar.py csv_register --csv celeba.csv --dbname celeba --batch_size 500
--dbname で指定した文字列で celeba_vecs.gz , celeca_pics.gz の2つのファイルが作成されます。
celeba_vecs.gz には {'label':'顔ベクトル(ndarray)'}, celeba_pics.gz には {'label':'image_path'} のような辞書形式でデータを joblib でシリアライズして 保存します。
>dir
..
2019/06/26 22:06 159,470 celeba_pics.gz
2019/06/26 22:06 23,168,652 celeba_vecs.gz
登録後の特徴ベクトルのファイルは、2 万人分のデータで 約 22 MB でした。
検索結果の表示
結果表示について 他にどんな人に似ているのか知りたかったので Top 5 表示にしました。
Top 5 を表示する処理の流れは以下のようになっています。
(1) Post リクエスト
Search ボタン(上の画像 青い虫眼鏡ボタン)クリックして /search へ Post リクエストします。
コードを表示
$('#face-list').on('click', '.btn', function () {
let label = $(this).find('input').data('label');
let command = JSON.stringify({ "command": "search", "label": label });
post('/search', command);
});
(2) AP サーバ (Flask) の処理
リクエストを受け取った Flask では、similarity = cos_similarity(target_vec, search_vecs) で類似度を取得します。
コードを表示
..
@app.route('/search', methods=['POST'])
def search():
global search_result
command = request.json['command']
target_label = request.json['label']
# get face vectors of target face
face_vecs_dict, face_pics_dict = face_register.load()
target_vec = face_vecs_dict[target_label]
# similarity by descending order
similarity = cos_similarity(target_vec, search_vecs)
search_result = {}
top_similarity = similarity.argsort()[::-1]
# Return top 5 search result
top_similarity = top_similarity[:5]
for i, face_id in enumerate(top_similarity):
score = "{:.2f}%".format(similarity[face_id] * 100)
search_result[search_labels[face_id]] = score
..
return jsonify(ResultSet=json.dumps(result))
得られる結果 similarity は、20,000 人分の類似度です。
similarity:[-0.0773913 0.01573132 -0.12464652 ... -0.07216378 0.08963019
0.57921212]
ここで similarity.argsort()[::-1] で類似度を降順ソートして、top_similarity[:5] で Top 5 の類似度(のIndex) を取得します。
検索結果は search_result として global スコープ で更新します。(Flask で global を使わないで 変数を更新する方法が分からない。。)
index(/) に 検索結果search_resultを渡します。
コードを表示
def index():
logger.info("face_labels:{}".format(face_labels))
return render_template('index.html', is_async=is_async, flip_code=flip_code,
face_labels=face_labels, search_result=search_result,
dbname=dbname, enumerate=enumerate)
(3) 結果表示
ブラウザのリロードで全体を更新するのは動きとして嫌なので jQuery の load() で顔検索結果の部分のみ更新します。以下のコードは (1) でPost リクエストした結果を受け取った後の javascript の処理です。
$('#search-list').load('/ #search-list'); で index(/) の #search-list のみを更新します。
コードを表示
// ajax post
function post(url, command) {
$.ajax({
type: 'POST',
url: url,
data: command,
contentType: 'application/json',
timeout: 10000
}).done(function (data, textStatus) {
..
if (JSON.parse(command).command == 'search') {
$('#video_feed').slideUp(200);
$('#search-list').load('/ #search-list');
$('#search-list').slideDown(200);
}
..
}
顔検索結果 #search-list の表示部分は、Jinja2 で連携します。
コードを表示
<div class=" col-xs-12" id="search-list">
<h2 class="mt-1 mb-2">Similar faces (Top 5)</h2>
{% for i, (label, score) in enumerate(search_result.items()) %}
{% set filename = 'images/' ~ dbname ~ '/' ~ label ~ '.png' %}
<div class="d-inline-block mr-1 mt-1">
{% if i == 0 %}
<div class="small text-muted text-center"><i class="fas fa-crown fa-2x"></i> {{ score }} </div>
<img class="img-thumbnail" src=" {{ url_for('static', filename=filename) }}" alt="{{ label }}"
style="height: 200px; background: #007bff;">
{% else %}
<div class="small text-muted text-center"><i class="fas fa-chess-queen fa-2x"></i> {{ score }}
</div>
<img class="img-thumbnail" src=" {{ url_for('static', filename=filename) }}" alt="{{ label }}"
style="height: 160px;">
{% endif %}
<div class="small text-muted text-center"> {{ label }} </div>
</div>
{% endfor %}
</div>
まとめ/感想
「顔識別」の実装を通して自分にとって大きな収穫となったのは、技術的な部分だけでなく「モデルは組み合わせて使う」という発想でした。
例えば顔識別をするには、検出した顔の特徴をそのまま抽出するのではなく、ランドマークモデルで目の位置を取得し、顔の傾きから画像を回転・整列させる前処理を行うことで、安定した結果を出すことができます。
これまで 顔検出・分析(年齢/性別・表情・ランドマーク・顔向き推定)と試して 「個々のモデルは何に使えるのか」と考えていましたが、納得のいく答えがでていませんでした。
「モデルの組み合わせ」という方法により そのことが何となく繋がったように感じます。
参考サイト・書籍
-
類似度を出力する実装全般
[ゼロから作るDeep Learning ❷ ―自然言語処理編] の第2章「自然言語と単語の分散表現」(https://www.amazon.co.jp/dp/4873118360) -
[Python3] 画像をBase64にエンコード、Base64をNumPy配列へ読み込みOpenCVで処理、NumPy配列をBase64に変換
-
ファイルアップロードとサムネイル表示
https://www.w3schools.com/bootstrap4/bootstrap_forms_custom.asp
https://cccabinet.jpn.org/bootstrap4/javascript/forms/file-b