我的想法是:让generator能够根据label来生成对应的图片,比如label为1,生成1的图片,而不是随机生成。
为了实现这个目标,我给discriminator的输入做了些手脚。
vanilla模型里,D的输入是单纯的图片向量,输出是图片为真的可能性,很简单。但是为了能强迫generator能够根据label生成图片,我给辨别器开了作弊,输入变成了(图片向量+对应label的embedding),用torch.cat做一个简单的连接。
这样一来如果生成器不根据label embedding生成对应图片向量,就会很轻松地被辨别器识破。
其实这样的结构——concat了一个辅助向量——给我一种感觉就是很像可控VAE,更深入的分析我现在还没有时间做,总之先将结果放上来吧,这是epoch1的结果:

这是epoch 200的结果:

我让电脑挂了一晚上,然后回去睡觉,心想明天就能坐享其成结果却是这副模样。总之分析一下出错的原因吧,先上结构图。
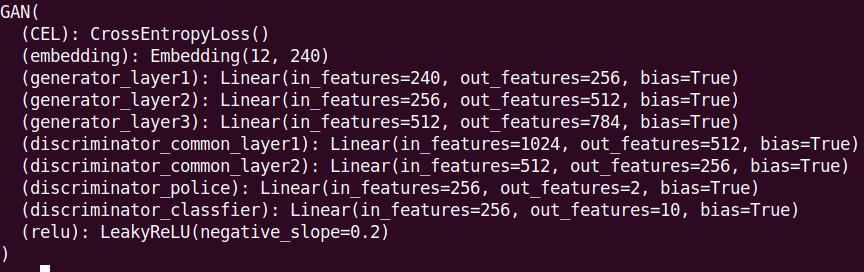
我之前设想的分工如下:
Generator: 提高discrimination loss
Discriminator: 降低(discrimination loss + classification loss)
问题点1: 冗余classifier
现在想想我实在不明白定义一个classification loss的意义何在。也许当时的我想让discriminator同时学习鉴别真假和辨别标签,所以定义了两个输出层,然而仔细想想,鉴别真假的时候鉴别器就能利用标签label,这样的操作像是画蛇添足。总而言之我会把classfier去掉再训练一次。
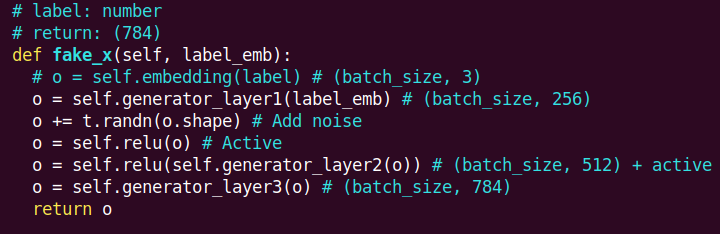
问题点2: 错误的noise添加方式
然后我又对照了一遍网络上的实现 GAN from scratch,发现他们引入noise的方式是直接作为generator的第一层输入。而之前我的实现是,让label embedding作为第一层输入,然后在中间层加上一个随机变量。
问题点3: loss定义方式
这是我不大愿意想象的,总之我会把它作为一个备考。
今天就继续修复实验吧。