はじめに
データ分析の勉強のために参戦したSIGNATEの第10回_Beginner限定コンペが先日終了したので、振り返るために初めて記事を書くことにしました。文章は拙いと思われますが、よろしければ読んでみてください。
分析環境
Google Colaboratory
結果
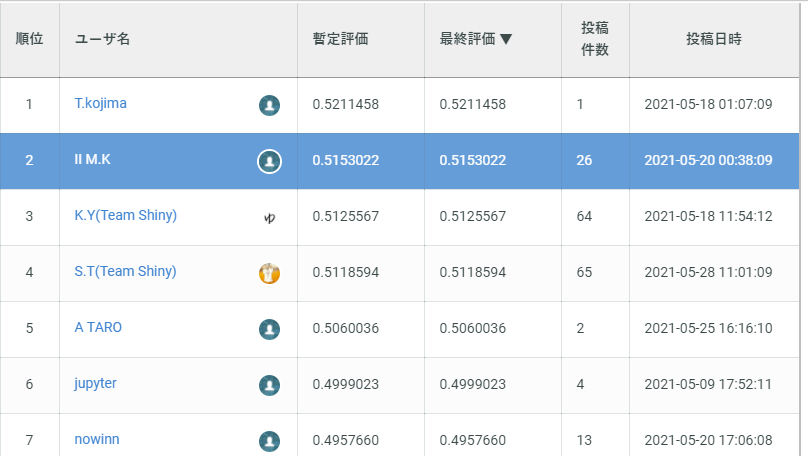
最終順位は2位(178人中)。使用モデルはLGBM(fold-out)。
コンペティション内容について
概要
- タスク
携帯電話のスペックから携帯電話価格帯を分類する多クラス分類
- データ
学習データ:1200、テストデータ:800のテーブルデータ
- 評価指標
F1macro
取り組みの大まかな流れ
- EDA
説明変数はすべて量的変数とされていたためカテゴリ変数になりうるものはカテゴリ変数化。
shape、info、describe、headで全体の把握。
ヒストグラム、散布図、箱ひげ図、バイオリンプロットで全体の分布の把握。
カテゴリ変数は全体、クラス毎に相対度数確認。
最後にtargetとの相関関係を確認。
- 特徴量作成
相関係数が極端に低い変数の削除。
カテゴリ変数を確認時、クラスごとに最頻の組み合わせがあったため「{}_{}_{}」という形でカテゴリ変数作成。
学習データ、テストデータを一度合わせて量的変数、カテゴリ変数でクラスターを作成。
カテゴリ変数をtarget encodingで数値化(https://towardsdatascience.com/target-encoding-for-multi-class-classification-c9a7bcb1a53(multilabel化)の方法と通常の方法)。
- 学習と予測
ロジスティック回帰、K近傍法、サポートベクターマシン、決定木、ランダムフォレスト、XGBoost、LightGBMでモデル構築(fold-out、crossvalidation)。
上記のモデルのアンサンブルの実施(バギング、スタッキング)
今回の反省点
- githubを使用しなかった上、ファイルも一つで作業を行っていたため、無駄な動作が多くなってしまった。
- CVでtarget encodingする方法で躓いてしまったため、fold-outで強引に進めてしまった。
- Pytorchを理解していなかったため、TabNetは試すことができなかった。
良かった点
- 上記に書いてないことも含めていろいろ試すことができた。
- TabNetは使用するまでの把握ができなかったが、論文やYoutubeの解説動画を見て学ぶことができた。
今後について
- 今回うまく行かなかったところを勉強し、使用できるようにする。
- Gitについて勉強する。
- kaggleのコンペに参加してみる。
最後に
最後まで読んでいただきありがとうございました。次回の投稿時にはもう少し読みやすいようにしたいです。思考の文章化もできればなと思っています
参考
- Kaggleで勝つデータ分析の技術(https://gihyo.jp/book/2019/978-4-297-10843-4)
- 前処理大全(https://gihyo.jp/book/2018/978-4-7741-9647-3)
- mechanisms-of-action-moa-tutorial(https://www.kaggle.com/sinamhd9/mechanisms-of-action-moa-tutorial)
- Target Encoding For Multi-Class Classification(https://towardsdatascience.com/target-encoding-for-multi-class-classification-c9a7bcb1a53)