Oracleからデータを取得する方法
PythonからOracleにSELECT文を実行して、Pythonでデータ取得する方法は、
以下のチューニングパラメータと3つのデータ取得方法があります。
※本投稿では、各データ取得方法の説明、処理時間、メモリ使用量について検証を行い纏めました。
- チューニングパラメータ(cursor.arraysize)
データをフェッチする行数を指定します。
- データ取得方法 その1
Cursor.fetchall
全部のレコードの結果をもってくる
- データ取得方法 その2
Cursor.fetchmany
指定された行数のデータをもってくる。
- データ取得方法 その3
Cursor.fetchone
1件ずつデータをもってくる
・参考
http://www.oracle.com/technetwork/articles/dsl/python-091105.html
https://cx-oracle.readthedocs.io/en/latest/cursor.html
チューニングパラメータ (cursor.arraysize)
データをフェッチする行数を指定します。
デフォルトは、100です。
⇒1度に100行をフェッチします
cursor.arraysizeで指定したデータ件数単位でOracleからデータを取得します。
データ件数が多い場合、
クライアントとOracleの間のデータ取得のやり取りが多くなり、
データ取得のパフォーマンスに影響を与えます。
※cursor.arraysizeはチューニングパラメータになります
たとえば、
10000件のデータを取得する場合で考えますと、
cursor.arraysizeが100件の場合、100回データを取得します。
cursor.arraysizeが1000件の場合、10回でデータを取得するので
クライアント<==>DBサーバ間のデータのやりとりが減ります。
◆設定方法
import time
import cx_Oracle
Svr="xxx.xxx.xxx.xxx"
Port=1521
Svs="orcl"
USR="scott"
PWD="tiger"
tns = cx_Oracle.makedsn(Svr, Port, Svs)
con = cx_Oracle.connect(USR, PWD, tns)
cur = con.cursor()
### カーソルオブジェクトを作成後、arraysizeを設定します
cur.arraysize = 1000
※python から Oracleへの接続する詳細は
Windows環境のPythonからOracleに接続してみる を参照ください
データ取得方法 その1 (cursor.fetchall)
簡単に言うと
いちどに全部の結果をもってくる。 (cursor.arraysizeで設定された行数単位で取得)
大量データ取得の場合、python実行端末では、たくさんのメモリを使用します。
問合せ結果のすべての行を取り出し、それらをタプルのリストとして戻します。
また、データがない場合は空のリストが戻されます。
Oracleからデータを読込む単位はcursor.arraysizeで設定した値(データ件数)となります。
クライアントとOracleの間のデータ取得のやり取りが多い場合、データ取得のパフォーマンスに影響を与えるますので、パフォーマンスが遅い場合、cursor.arraysizeを調整します。
import time
import cx_Oracle
# DBサーバ接続情報
Svr="xxx.xxx.xxx.xxx"
Port=1521
Svs="orcl"
USR="scott"
PWD="tiger"
tns = cx_Oracle.makedsn(Svr, Port, Svs)
con = cx_Oracle.connect(USR, PWD, tns)
cur = con.cursor()
# cur.arraysize 設定 デフォルトは100。サンプルでは1000に設定
cur.arraysize = 1000
cur.execute('select * from bigtab')
# フェッチ開始前の時間取得
start = time.time()
# fetchallでデータを取得
res = cur.fetchall()
# 件数確認カウンタ
dcnt = 0
# データをフェッチ
for r in res:
col1 = r[0]
dcnt = dcnt + 1
# フェッチ完了後の時間を取得して、差分をもとめして実行時間を算出
elapsed = (time.time() - start)
print ("fetchall:" + str(elapsed) + " seconds")
print("datacount:" + str(dcnt))
# 10秒スリープ
print("**************************")
print("check process memory")
print("**************************")
time.sleep(10)
# fetchallを使用したプロセスメモリ情報を取得(後述)
# 別コマンドプロンプトを立ち上げ
# tasklist /fi "imagename eq python.*" を実行
cur.close()
con.close()
データ取得方法 その2 (cursor.fetchmany(numRows))
簡単に言うと
numRows(numRows が指定されていない場合はcursor.arraysize)で指定された行数のデータをもってくる。
※numRowsの指定がない場合は、cursor.arraysize の値が使用されます
クエリで取得する件数 > numRows 場合、
cursor.fetchmany を コールして次データを取得する
※データ取得する単位は numRows で指定した分のみ取得するので
大量データ取得の場合、python実行端末では使用するメモリは一定量となり、
cursor.fetchallよりもメモリ使用量は少ない
問合せ結果をfetchmany(numRows)で指定された行数で取り出し、それらをタプルのリストとして戻します。
クライアントとOracleの間のデータ取得のやり取りが多い場合、データ取得のパフォーマンスに影響を与えるますので、パフォーマンスが遅い場合、numRows を調整します。
import time
import cx_Oracle
# DBサーバ接続情報
Svr="xxx.xxx.xxx.xxx"
Port=1521
Svs="orcl"
USR="scott"
PWD="tiger"
tns = cx_Oracle.makedsn(Svr, Port, Svs)
con = cx_Oracle.connect(USR, PWD, tns)
cur = con.cursor()
# cur.arraysize 設定 デフォルトは100。サンプルでは1000に設定
cur.arraysize = 1000
cur.execute('select * from bigtab')
# フェッチ開始前の時間取得
start = time.time()
# データ件数確認カウンタ
dcnt = 0
# データをDBに取得した回数の確認カウンタ
fcnt = 0
while True:
#numRows を 指定していないのでcur.arraysizeで設定した値が使用される
rows = cur.fetchmany()
if len(rows) == 0:
break
fcnt = fcnt +1
for r in rows:
s = r[0]
dcnt = dcnt + 1
# フェッチ完了後の時間を取得して、差分をもとめして実行時間を算出
elapsed = (time.time() - start)
print ("fetchmany:" + str(elapsed) + " seconds")
print("datacount:" + str(dcnt))
print("DB count:" + str(fcnt))
# 10秒スリープ
print("**************************")
print("check process memory")
print("**************************")
time.sleep(10)
# fetchmanyを使用したプロセスメモリ情報を取得(後述)
# 別コマンドプロンプトを立ち上げ
# tasklist /fi "imagename eq python.*" を実行
cur.close()
con.close()
データ取得方法 その3 (cursor.fetchone)
簡単に言うと
1行のみのデータをもってくる
問合せ結果の1行を取り出し、単一のタプルを返します。
※データがそれ以上利用できない場合は、Noneを返します。
import time
import cx_Oracle
# DBサーバ接続情報
Svr="xxx.xxx.xxx.xxx"
Port=1521
Svs="orcl"
USR="scott"
PWD="tiger"
tns = cx_Oracle.makedsn(Svr, Port, Svs)
con = cx_Oracle.connect(USR, PWD, tns)
cur = con.cursor()
cur.execute('select * from bigtab')
# フェッチ開始前の時間取得
start = time.time()
# データ件数確認カウンタ
dcnt = 0
while True:
res = cur.fetchone()
if res is None :
break
s=res[0]
dcnt = dcnt + 1
# フェッチ完了後の時間を取得して、差分をもとめして実行時間を算出
elapsed = (time.time() - start)
print ("fetchone:" + str(elapsed) + " seconds")
print("datacount:" + str(dcnt))
# 10秒スリープ
print("**************************")
print("check process memory")
print("**************************")
time.sleep(10)
# fetchoneを使用したプロセスメモリ情報を取得(後述)
# 別コマンドプロンプトを立ち上げ
# tasklist /fi "imagename eq python.*" を実行
cur.close()
con.close()
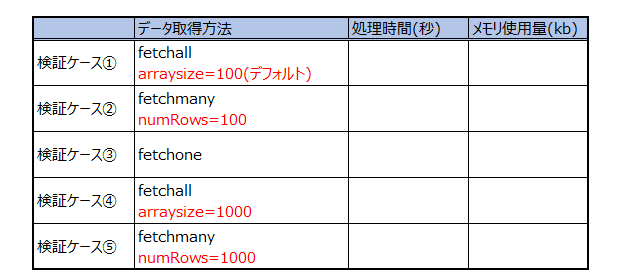
各データ取得方法毎のarraysizeによる処理時間とメモリ使用量を検証
データ件数 500,000万件を準備して、各ケースの検証を実施して
処理時間、メモリ使用量を確認する。
検証環境はVirtualBoxのDBを使用しての検証
検証方法
1.検証用テーブルとデータ作成
2.Oracle のBuffer_cacheをクリア
3.python使用メモリを計測の準備
4.python スクリプトを実行
5.python使用メモリを計測
上記検証①~⑤を行います
1.検証用テーブルとデータ作成
「bigtab」というテーブルを作成して、50万件データを登録
sqlplus scott/tiger で接続
--テーブル作成
create table bigtab (mycol char(200));
--データ作成
begin
for i in 1..500000
loop
insert into bigtab (mycol) values (lpad(i,'200',0));
end loop;
commit;
end;
/
2.Oracle のBuffer_cacheをクリア
データがメモリにのると検証によって、正確な時間が計測できないため
alter system flush buffer_cache でメモリをクリア
sqlplus / as sysdba で接続
alter system flush buffer_cache;
3.python使用メモリを計測の準備
コマンドプロンプトを起動
コマンドプロンプト画面が起動
4.python スクリプトを実行
arraysize を検証ケースごとに変更して実行
pythonスクリプトの実行方法は以下の記事を参照ください
・Windows環境でPythonスクリプト(.py)の実行方法
5.python使用メモリを計測
pythonスクリプト(fetchall.py、fetchmany.py、fetchone.py)の中でデータフェッチ後に、
10秒sleep するようにしています。
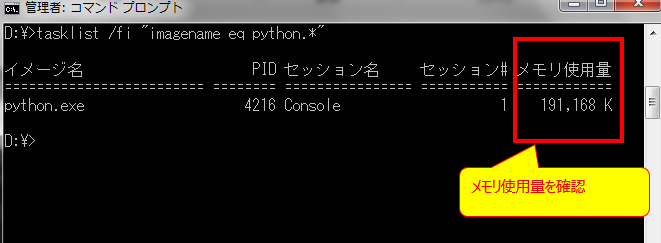
「check process memory」とメッセージがでたら
3.python使用メモリを計測の準備 で起動したコマンドプロンプトで以下のコマンドを実行します。
tasklist /fi "imagename eq python.*"
を実行してメモリ使用量 を確認します。
※pythonスクリプトから.batをコールする方法もありましたが、ここは手動で。。
実行サンプル
検証結果サマリ
データ件数 500,000万件を準備して、各ケースの検証を実施して
処理時間、メモリ使用量の計測結果
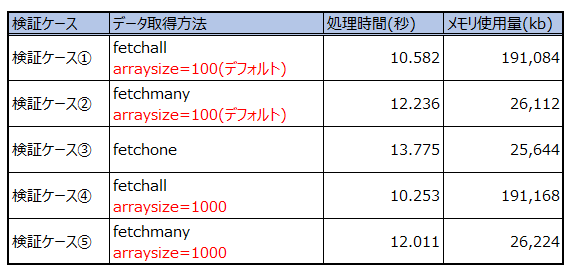
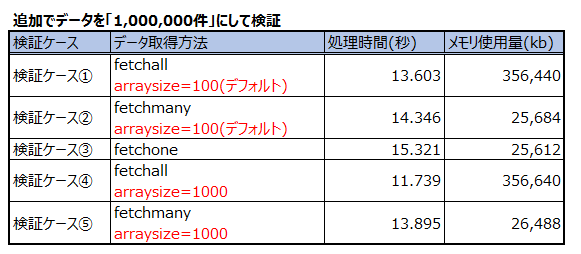
fetchall
・検証パターンで一番早い
・全てのデータをPython実行端末にもってくるので、取得データ分メモリを使用する
・pythonコードを書くとき、 fetchall() して ループするだけでいいのでコードは簡単
・arraysize によるチューニングする余地はある(どの値が適切かは環境依存)
fetchmany
・検証パターンは2番目に早い
・arrayseizeで指定した分のデータをPython実行端末にもってくるので、データ取得で使用するデータ量に依存せず、使用するメモリ量は一定。
・pythonコードを書くとき、 fetchall() よりも若干コードが増える
・arraysize によるチューニングする余地はある(どの値が適切かは環境依存)
fetchone
・検証パターンは3番目
・1件ずつデータをPython実行端末にもってくるので、データ取得で使用するメモリ量は少ない。
・pythonコードを書くとき、 fetchall() よりも若干コードが増える
**まとめ**
大量データを取得するときに、fetchall、fetchmany を使用する際、
arraysize をデフォルト値から大きく調整することで処理時間の短縮が期待できる。
(検証環境では若干の処理時間の短縮でしたが。。)
データ取得方法は、fetchallが一番早い結果になったが、
取得するデータ量によっては、Python実行端末のメモリを大量に使用する可能性があるので、
python実行端末でメモリ不足する傾向にある場合は、fetchmanyを使用することを検討。