はじめに
iQONでは、アイテムのレコメンドといった大規模データの計算が必要な際には、Spark の MLlib という機械学習のライブラリを使っていますが、その際に Google Cloud Platform (GCP) のマネージド Hadoop & Spark サービスである Dataproc で計算を行っています。
本記事では、実際に業務で使ってみた上で、Dataproc にどのような特徴があり、他の類似サービスと比べてどのようなメリットがあるか、また利用する際にどのような点に気をつけるべきか、といった点について説明したいと思います。
Dataproc とは?
Dataprocは、Hadoop & Saprk のマネージド サービスです。類似サービスとしては、AWS の Elastic MapReduce (EMR) や Azure の HD Insight がありますが、それらのサービスと比較すると、個人的には下記の点が Dataproc の特徴的な点だと思っています。
- 分単位課金のため短時間利用の料金が安い
- クラスタへの SSH 接続なしにジョブを実行可能
- クラスタの立ち上げが早い
- データのやり取りが簡単
- BigQuery のデータを読み書き可能
まだベータ版なため、不安定な部分がありますが、他のサービスと比べてクラスタの立ち上げも早いため、日次バッチ処理等で一時的に多くの台数のクラスタを立ち上げて計算させたり、一時的にクラスタを立ち上げて計算するといった用途では、かなり便利かつ安価に利用できるなという印象です。
参考:https://cloud.google.com/dataproc/?hl=ja
Dataproc の特徴
上記で説明した特徴を具体的に説明していきたいと思います。
分単位課金のため短時間利用の料金が安い
まず、Dataprocを利用するメリットとして、分単位の課金のため、特に短時間利用時の料金が安いことが挙げられます。
Spark で大規模データを計算する場合、いくつもクラスタを立ててバッチで並列計算をさせる場合が多いと思いますが、短時間で終わる場合は、EMR のように1時間単位でなく、分単位の課金1というのは大きなメリットです。
例えば、Dataproc で n1-standard-16 という vCPU 16コア、メモリ60G のマシンを6インスタンス立てて、15分計算をした場合、
GCE 料金
$0.80/1時間 × 6インスタンス x 15/60 = $1.20
Dataproc 料金
$0.01/1時間 × 16 core x 6インスタンス x 15/60 = $0.24
となるので、もし1時間単位の課金であれば $5.76 のところ、15分であれば $1.44 で計算できてしまいます。この計算を同様に EMR のc3.4xlarge インスタンスで行うとすると、
EC2 料金(オンデマンド)
$0.84/1時間 × 6インスタンス = $5.04
EMR 料金
$0.21/1時間 × 6インスタンス = $1.26
となり、$6.30 となるので3倍ほど料金が異なってきます。もちろん、EC2 に関してはスポットインスタンス等を使えば、もっと安く利用することができると思いますが、それでも短時間利用や多くのクラスタを立ち上げるといった用途では、分単位での課金は大きなメリットだと思います。
クラスタへの SSH 接続なしにジョブを実行可能
Dataproc は、基本的に SSH でノードクラスタにログインしてコマンド操作を行うことはせず、下記の様に、クラスタ外のコンピューターから gcloud というコマンドラインでジョブを投げるといった使い方をします。
具体的には、下記のように gcloud コマンドを実行することで、Spark のジョブを実行することができます。
$ gcloud beta dataproc jobs submit pyspark --cluster <my-dataproc-cluster> hello-world.py
また、ジョブの実行状況は、Spark UI から確認できる他、GCPコンソールの Web UI からも確認することができます。
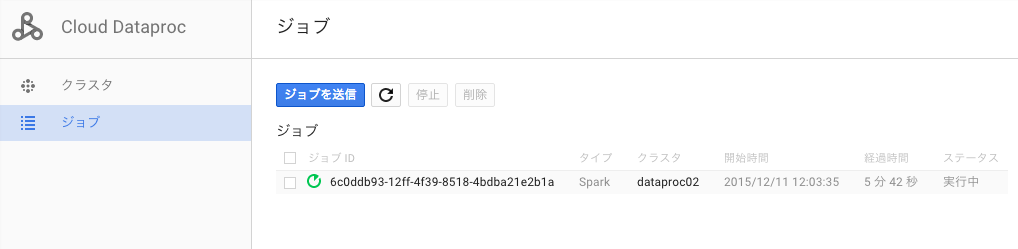
もちろん、ジョブの実行だけでなく、クラスタの作成や削除もコマンドから実行できるため、計算したいときだけクラスタを立ち上げて、ジョブを投げ、クラスタを削除するという一連のバッチ処理を簡単に作成することが可能です。
クラスタの立ち上げが早い
Dataproc を利用してみた感じたのは、クラスタの立ち上げの早さです。gcloud コマンドからクラスタの立ち上げを行っても、90秒ほどで立ち上がるので、立ち上げっぱなしにしておく必要がありません。
データのやり取りが簡単
また、データのやり取りが簡単である点も見逃せません。通常、Spark でデータを扱う際は、HDFS へデータを格納する必要があると思いますが、Dataproc では GCS のデータを直接読み書きすることができます2。
例えば、Scala でファイルを読み込む際は、データファイルを GCS へ用意し、下記の様に GCS のファイルパスを指定するだけで、簡単にデータを読み込めます。
val sc = new SparkContext()
val data = sc.textFile("gs://iqon-hoge/data.csv")
また、計算結果を書き出す際にも、下記のように GCS のパスを指定するだけで、簡単に結果をファイルに書き出すことができます。
resultRDD.savaAsTextFile("gs://iqon-hoge/result")
BigQuery のデータを読み書き可能
Dataproc では、ファイルでデータをやり取りするだけでなく、BigQuery のデータを読み込んだり、計算結果をテーブルに書き込んだりすることもできます。iQON では機械学習に読み込むデータの前処理に BigQuery を利用することが多いため、この機能はとても便利です。
参考:Using the BigQuery Connector with Spark
利用時の注意点
ただし、マネージドサービスといっても、やはり本格的に使うためには各種パラメータの調整は必要になってきます。ここでは、Dataproc で Spark を利用するにあたり、嵌った設定項目について説明します。
Dynamic Resource Allocation の無効化
Dataproc の Spark はクラスタマネージャーとして YARN を使っていますが、その際に Dynamic Resource Allocation という機能を有効にしてあると、Executor がきちんと指定した数だけ立ち上がらないといったことがあったので、無効にしておくことをおすすめします。
実際には、ジョブを投げる際に、オプション引数として "--propaties spark.dynamicAllocation.enabled=false" とすることで無効にすることができます。
gcloud beta dataproc jobs submit pyspark \
--properties spark.dynamicAllocation.enabled=false \
--cluster <my-dataproc-cluster> \
hello-world.py
参考:[DataProc master does not see the correct numbers of Spark executors]
(https://groups.google.com/forum/#!msg/cloud-dataproc-discuss/e8LVlEdJePA/7WpGrqQ6EAAJ)
Executor の設定
また、Spark を実行する際には、Executor のパラメータを適切に設定する必要があります。特に、下記の3つに関しては、デフォルトではなく明示的に設定しないとリソースをうまく使い切れませんでした。
spark.executor.cores
spark.executor.memory
spark.executor.instances
設定値をどう設定したらよいかは、Cloudera の下記のブログがとても参考になりました。
How-to: Tune Your Apache Spark Jobs (Part 2)
これらのパラメータは、Dynamic Resource Allocation の設定と同様に、--propaties オプションの引数として設定することができます。
gcloud beta dataproc jobs submit pyspark \
--properties spark.dynamicAllocation.enabled=false,spark.executor.cores=\
5,spark.executor.memory=8g,spark.executor.instances=15 \
--cluster <my-dataproc-cluster> \
hello-world.py