Ubuntu 20.04 LTS のサポートが終了しつつあり、Gymnasium (https://gymnasium.farama.org) の実行環境を更新したので、結果をメモ。ポイントは3つ。
- PyTorch の Conda サポートが終了したので、Pip を使う
- Ubuntu 24.04 から Pip の際に仮想環境が必要になったので venv を使う
- swig が動作しないのでソースからコンパイル
(1) venv の導入
venv を導入する。
$ sudo apt install python3-venv python3-pip
.bashrc の末尾に
alias mkvenv='python3 -m venv --upgrade-deps --prompt . .venv'
alias activate='source .venv/bin/activate'
の2行を追加する。エディタを使わずに、コマンドラインから作業するなら
$ echo "alias mkvenv='python3 -m venv --upgrade-deps --prompt . .venv'" >> ~/.bashrc
$ echo "alias activate='source .venv/bin/activate'" >> ~/.bashrc
とする。
一度端末を閉じて開き直すか、$ source ~/.bashrc を実行して変更を反映させる。
以降、$ mkvenv で現在のフォルダに仮想環境を作成でき、$ activate で
現在のフォルダに作成済みの仮想環境を有効化できる。以上は次の記事を参考にした。
(2) Gymnasium のチュートリアル
導入
https://gymnasium.farama.org/introduction/basic_usage/
https://gymnasium.farama.org/introduction/train_agent/
にあるチュートリアルを試す。まず、作業用のフォルダ(ここでは gym)に仮想環境を作成し、有効化する。
$ mkdir gym
$ cd gym
$ mkvenv
$ activate
続けて以下を試すと(試さなくて良い)、なぜか box2d のインストール中に swig の実行に失敗する。
(gym) $ pip install swig
(gym) $ pip install "gymnasium[box2d]"
以下では swig をソースからコンパイルする。上記を実行してエラーが出た場合には以下を実行する。
(gym) $ pip uninstall swig
(gym) $ rm .venv/bin/swig*
仮想環境を終了してから、コンパイルに必要なライブラリをインストールする。
(gym) $ deactivate
$ cd ~
$ sudo apt install git build-essential automake bison libpcre2-dev
適当な作業用フォルダ(~/dev など)で
$ git clone https://github.com/swig/swig.git
$ cd swig
$ ./autogen.sh
$ ./configure --prefix=$HOME/.local/swig
$ make
$ make install
とし、出来上がった実行ファイルに PATH を通す。
$ echo 'export PATH=~/.local/swig/bin:$PATH' >> ~/.bashrc
一度端末を閉じて開き直すか、$ source ~/.bashrc を実行して変更を反映させる。
参照: https://swig.org/svn.html の To build the latest version
$ swig --version
SWIG Version 4.3.0
Compiled with /opt/rh/devtoolset-2/root/usr/bin/g++ [Linux]
Configured options: +pcre
Please see https://www.swig.org for reporting bugs and further information
とバージョンが表示されるのを確認したら、改めて環境を構築する。
$ cd gym
$ activate
(gym) $ pip install "gymnasium[box2d]"
(gym) $ pip install matplotlib tqdm
学習
'gym' フォルダに blackjack_train.py というファイルを用意して、https://gymnasium.farama.org/introduction/train_agent/ にあるすべての Python コードを順番にコピーペーストする。
学習結果を保存するために、末尾に次の3行を追加する。
import pickle
with open("q_values.pkl", "wb") as f:
pickle.dump(dict(agent.q_values), f)
blackjack_train.py を保存して
(gym) $ python blackjack_train.py
で実行を確認。
WSL の場合には、ウィンドウを表示させるために次も必要。
$ sudo apt install python3-tk
学習結果によるゲームプレイ
'gym' フォルダに以下の内容で blackjack_play.py を作成。
未学習の状態に対する Q 値は、学習済みの全状態における平均値で置き換えている。
from collections import defaultdict
import gymnasium as gym
import numpy as np
import pickle
import time
env = gym.make("Blackjack-v1", sab=False, render_mode="human")
with open('q_values.pkl', 'rb') as f:
q_values = pickle.load(f)
q_ave = sum(q_values.values()) / len(q_values)
q_values = defaultdict(lambda: q_ave) | q_values
def get_action(obs: tuple[int, int, bool]) -> int:
return int(np.argmax(q_values[obs]))
obs, info = env.reset()
done = False
# play one game
while not done:
time.sleep(0.5)
action = get_action(obs)
next_obs, reward, terminated, truncated, info = env.step(action)
print(f'{obs[0]} : ', end='')
print('Stand' if action==0 else 'Hit')
# update if the environment is done and the current obs
done = terminated or truncated
obs = next_obs
print ('Player ', end='')
print ('won.' if reward > 0 else 'lost.' if reward < 0 else 'drew.')
# Wait for the game window to close.
from pygame.locals import QUIT
import pygame
import sys
while True:
for event in pygame.event.get():
if event.type == QUIT:
pygame.quit()
sys.exit()
(gym) $ python blackjack_play.py
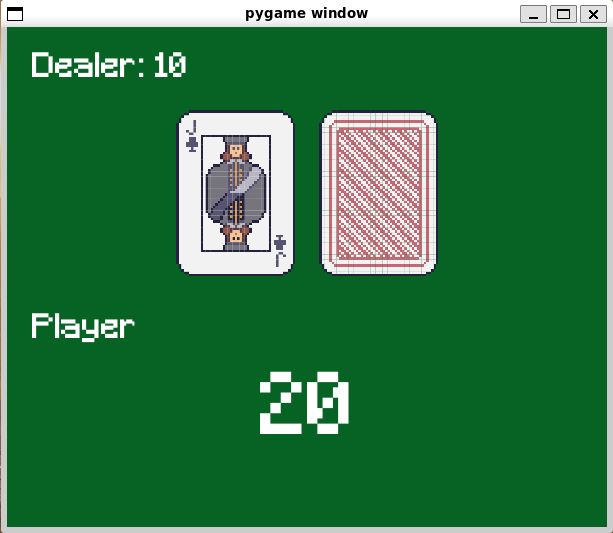
10 : Hit
20 : Stand
Player won.
で1試合の実行を表示。端末で Ctrl-C を入力するか、ゲーム画面を閉じると終了。
Blackjack-v1 ではディーラーの点数は非公開なので、勝敗のみを表示している。
(3) PyTorch のチュートリアル
導入
$ nvidia-smi で NVIDIA driver が動作していることを確認する。
PyTorch に対応したバージョンの CUDA ToolKit をインストールしておく。(記事作成時の対応バージョンは 11.8/12.4/12.6)
最新版以外の CUDA ToolKit は https://developer.nvidia.com/cuda-toolkit-archive にある。
PyTorchを https://pytorch.org/ に従ってインストールする。Stable, Linux, Pip, Python, CUDA のバージョン(例:12.6)を選択し、表示されたコマンドを仮想環境内で実行する。
$ cd gym
$ activate
(gym) $ pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
端末で以下を実行し、True が出力されたら成功
(gym) $ python
>>> import torch
>>> torch.cuda.is_available()
True
>>> quit()
他に必要なものをインストール
(gym) $ pip install "gymnasium[classic_control]"
(gym) $ pip install matplotlib
学習
'gym' フォルダに cartpole_train.py というファイルを用意して、
にあるすべての Python コードを順番にコピーペーストする。
学習結果を保存するために、末尾に次の1行を追加する。
torch.save(policy_net.state_dict(), 'policy.pth')
(参考) https://pytorch.org/docs/main/notes/serialization.html#saving-and-loading-torch-nn-modules
cartpole_train.py を保存して
(gym) $ python cartpole_train.py
で実行を確認。
緑線は棒が倒れるまでの時間(500で打ち切り)。赤線は直前100個の平均値(試行が100未満のときは0)
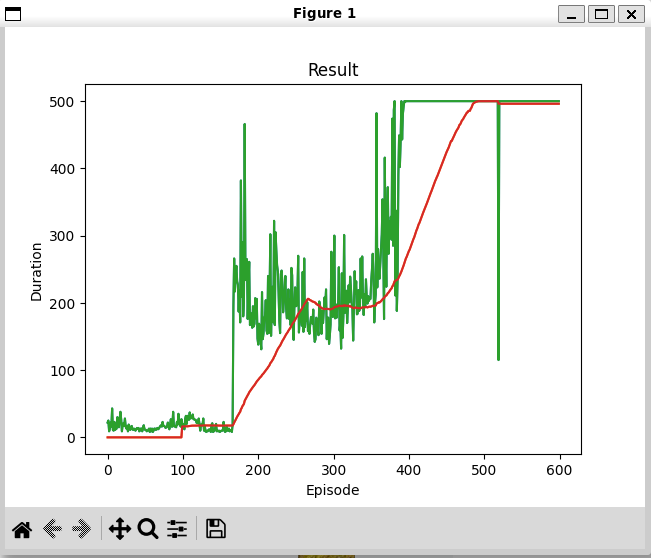
何回か学習を行い、うまくいった結果(最終部分が500で安定)をファイル名を変えて残す。
(gym) $ cp policy.pth policy1.pth
学習結果による制御シミュレーション
'gym' フォルダに以下の内容で cartpole_control.py を作成。
import gymnasium as gym
from itertools import count
import torch
import torch.nn as nn
import torch.nn.functional as F
from pygame.locals import QUIT
import pygame
import sys
path = 'policy.pth'
if __name__ == '__main__':
if len(sys.argv) == 2:
path = sys.argv[1]
env = gym.make("CartPole-v1", render_mode="human")
# if GPU is to be used
device = torch.device(
"cuda" if torch.cuda.is_available() else
"mps" if torch.backends.mps.is_available() else
"cpu"
)
class DQN(nn.Module):
def __init__(self, n_observations, n_actions):
super(DQN, self).__init__()
self.layer1 = nn.Linear(n_observations, 128)
self.layer2 = nn.Linear(128, 128)
self.layer3 = nn.Linear(128, n_actions)
def forward(self, x):
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
return self.layer3(x)
n_actions = env.action_space.n
state, info = env.reset()
n_observations = len(state)
policy_net = DQN(n_observations, n_actions).to(device)
policy_net.load_state_dict(torch.load(path))
def select_action(state):
with torch.no_grad():
return policy_net(state).max(1).indices.view(1, 1)
state, info = env.reset()
state = torch.tensor(state, dtype=torch.float32, device=device).unsqueeze(0)
for t in count():
action = select_action(state)
observation, reward, terminated, truncated, _ = env.step(action.item())
state = torch.tensor(observation, dtype=torch.float32, device=device).unsqueeze(0)
print(f'\r{t = }', end='')
if terminated:
print('')
break
for event in pygame.event.get():
if event.type == QUIT:
print('')
pygame.quit()
sys.exit()
学習時は500ステップで打ち切り(成功)だが、この制御シミュレーションは時間経過では終了しない。
(gym) $ python cartpole_control.py policy1.pth
初期状態は乱数によって設定されるので毎回挙動が変わる。学習が不十分だと、制御に失敗して終了する。
制御に失敗せず、いつまでも終わらない場合は、ゲーム画面を閉じるか端末で Ctrl-C を入力して終了する。
