やったこと
- Pythonを利用して、Google Vision APIという、OCRの機械学習APIを利用して、以下の表形式のデータを読み取らせた
- 表形式の神エクセルとか絶対許せねぇ
- せめてPDFやろ!
- 画像にすんなボケ!
- さてとお役所は変わらない!
- なら技術でなんとかするしかねぇ!
- せや!Google Vision APIを使えば、画像からテキストデータに落とし込めるぞ!
結果
-
かなり高精度で読み取ってくれたものの、一部限界があり
- 表形式のフォーマットで取得することが非常に困難だった
- ただ、これらの値をエクセルにコピペする作業を行えば、普通に目視で一つ一つコピーするよりも5000兆倍くらい効率がよい
- まだ技術でお役所エクセルは倒せなさそう
-
出力結果はこちら
$python OCRproject.py
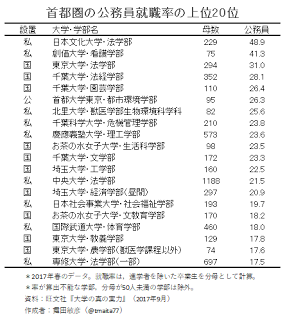
首都圏の公務員就職率の上位20位
設置
私
私
国
国
国
公
私
私
私
国
国
国
私
国
私
国
私
国
国
私
大学·学部名
日本文化大学·法学部
創価大学·看護学部
東京大学法学部
千葉大学法経学部
千葉大学·園芸学部
首都大学東京·都市環境学部
北里大学·獣医学部生物環境科学科
千葉科学大学危機管理学部
慶應義塾大学·理工学部
お茶の水女子大学·生活科学部
千葉大学·文学部
埼玉大学·工学部
中央大学·法学部
埼玉大学·経済学部(昼間)
日本社会事業大学·社会福祉学部
お茶の水女子大学文教育学部
国際武道大学·体育学部
東京大学·教養学部
東京大学·農学部(獣医学課程以外)
専修大学·法学部(一部)
母数
229
75
294
352
110
95
82
210
573
98
172
160
1188
297
193
170
460
129
74
697
48.9
41.3
31.0
28.1
26.4
26.3
25.6
23.8
23.6
23.5
23.3
22.5
21.5
20.9
19.7
18.2
18.0
17.8
17.6
17.5
ソースコード
- ソースコードの説明は、後述のリンクから見てください
- Google Vision APIの利用のための申請が必要でした
OCR.py
# !/usr/bin/python
# coding:utf-8
import base64
import json
from requests import Request, Session
from bs4 import BeautifulSoup
path = "image.JPG"
def recognize_captcha(str_image_path):
bin_captcha = open(str_image_path, 'rb').read()
#str_encode_file = base64.b64encode(bin_captcha)
str_encode_file = base64.b64encode(bin_captcha).decode("utf-8")
str_url = "https://vision.googleapis.com/v1/images:annotate?key="
str_api_key = "ここにAPI KEYをいれてね!"
str_headers = {'Content-Type': 'application/json'}
str_json_data = {
'requests': [
{
'image': {
'content': str_encode_file
},
'features': [
{
'type': "TEXT_DETECTION",
'maxResults': 10
}
]
}
]
}
print("begin request")
obj_session = Session()
obj_request = Request("POST",
str_url + str_api_key,
data=json.dumps(str_json_data),
headers=str_headers
)
obj_prepped = obj_session.prepare_request(obj_request)
obj_response = obj_session.send(obj_prepped,
verify=True,
timeout=60
)
print("end request")
if obj_response.status_code == 200:
#print (obj_response.text)
with open('data.json', 'w') as outfile:
json.dump(obj_response.text, outfile)
return obj_response.text
else:
return "error"
if __name__ == '__main__':
data = json.loads(recognize_captcha(path))
data = data["responses"]
print(data)
for i in data:
print(i["fullTextAnnotation"]["text"])
参考
- 実際のセットアップや実装方法、コードの説明は、下記記事をご覧ください
【Python】Google Vision APIで、スクショした表形式の画像データから文字を抽出してみたよん