はじめに
機械学習初心者がscikit-learnの学習をアウトプットするために実際のデータを使って予測モデルを構築します。
今回は一番シンプルな線形回帰モデルについて取り組んでいこうと思います。
実行環境
Python3
MacBook Air(端末)
Jupyter Lab(Chrome)
本記事の概要
1.背景、目的
2.データの取得、前処理
3.モデル構築
4.モデル評価
5.結論
本編
1.背景、目的
前回の記事でSQLの実践を兼ねてbigqueryの一般公開データセットにあるChicago Taxi Tripsというデータから、SQLを記述してデータを取得してみるということを行いました。
アメリカ・シカゴ市のタクシー利用に関するデータがまとめられています。
前回ではデータからアメリカのチップ文化を知るというのが大きな目的でした。
前回の記事
最後の分析のところで、乗車距離が長いほど支払うチップの金額が大きくなっていることがわかりました。
そこで、今度は最近勉強したscikit-learnの実践も兼ねて乗車距離に対するチップの支払い金額を予測するモデルを構築してみようと思います。
2.データの取得、前処理
データの取得
Jupyter Lab上でbigqueryにアクセスし、Chicago Taxi Tripsにある乗車距離とチップの金額のデータを取り出します。
取り出したデータをデータフレームに格納します。
bigqueryでデータを取り出す段階で欠損値を避けています。
from google.cloud import bigquery
import pandas as pd
client = bigquery.Client()
query = """
SELECT
trip_miles, tips
FROM
bigquery-public-data.chicago_taxi_trips.taxi_trips
WHERE
trip_miles IS NOT NULL AND tips IS NOT NULL
"""
query_job = client.query(query)
df = query_job.to_dataframe()
どのようなデータが入っているか確認してみます。
df.head()
[出力結果]
| trip_miles | tips | |
|---|---|---|
| 0 | 4.70 | 2.0 |
| 1 | 22.50 | 0.0 |
| 2 | 9.90 | 0.0 |
| 3 | 3.51 | 0.0 |
| 4 | 0.33 | 0.0 |
データの前処理
外れ値がないかを確認します。箱ひげ図を用いてみます。
import matplotlib.pyplot as plt
%matplotlib inline
# trip_milesの箱ひげ図を描画
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.boxplot(df['trip_miles'])
plt.title('Boxplot of trip_miles')
# tipsの箱ひげ図を描画
plt.subplot(1, 2, 2)
plt.boxplot(df['tips'])
plt.title('Boxplot of tips')
[出力結果]
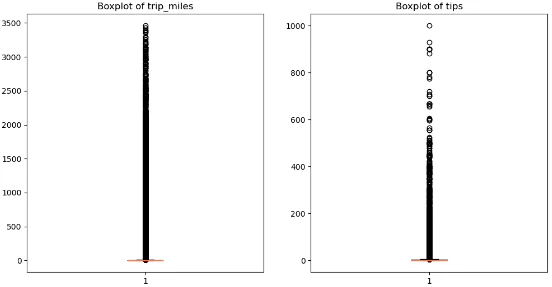
大きく飛び出ているデータは見当たらないため、外れ値の除外は行わずに行きたいと思います。
3.モデル構築
ここでは線形回帰モデルを使用します。特徴量は乗車距離のみで、乗車距離とチップの金額は比例関係にあるかもしれないと前回の記事で判断したため線形回帰モデルを選択しました。
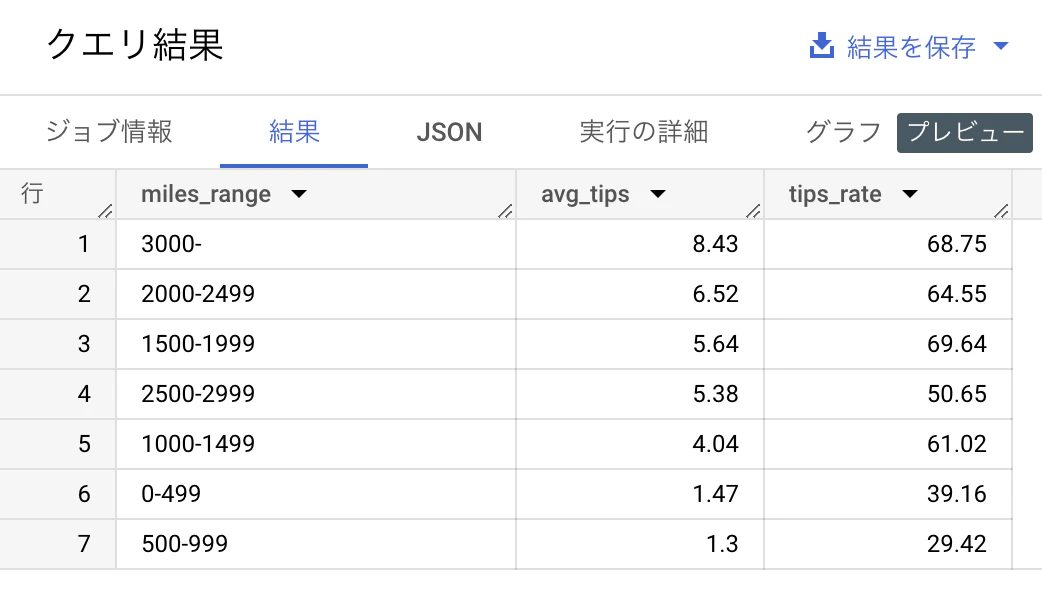
乗車距離が長いほど、チップの支払い金額の平均が大きくなっていることがわかります。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# データの分割
X = df[['trip_miles']] # 2次元のデータフレームとして抽出
y = df['tips']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# モデルの学習
model = LinearRegression() #線形回帰モデル
model.fit(X_train, y_train)
これでモデルの学習が完了しました。
4.モデル評価
予測
モデルを構築したことで、乗車距離がわかれば大体のチップの金額を予測することができるようになります。
試しにテストデータに対する予測を行ってみます。
# 予測
import numpy as np
X_new = np.array(100).reshape(-1, 1)
model.predict(X_new)
[出力結果]
array([6.53816979])
乗車距離が100マイルの時のチップの支払い金額はおよそ6.5ドルだと予測してくれました。
評価
回帰モデルで使われる評価指標はMSE、RMSE、MAE、R-Squaredなどいくつかあります。今回はRMSEを用います。
RMSEはMSEに平方根をつけたものです。
RMSE = \sqrt{\frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y}i)^2}
MSEは残差の二乗の平均を表します。MSEのままだと単位が二乗になるので指標の解釈がしづらいという問題点があります。
RMSEは指標の単位が目的変数の単位と一致するので解釈しやすくなります。
from sklearn.metrics import mean_squared_error
# 学習データでの予測と評価
train_preds = model.predict(X_train)
train_rmse = mean_squared_error(y_train, train_preds, squared=False)
# テストデータでの評価と予測
test_preds = model.predict(X_test)
test_rmse = mean_squared_error(y_test, test_preds, squared=False)
print(f'Training RMSE: {train_rmse}')
print(f'Test RMSE: {test_rmse}')
[出力結果]
Training RMSE: 2.7169623466582067
Test RMSE: 2.7211446819405705
学習データでのRMSEとテストデータでのRMSEの値が近いことからモデルは過学習していないことがわかります。また、このモデルは新しいデータに対しても十分な予測を行う性能を持っていることがわかります。
RMSEがおよそ2.7ということは、チップの支払い金額の平均的な誤差が2.7ドルであると言えます。
3.モデル構築の乗車距離と乗車距離に対するチップの支払い金額の平均の表を確認すると、およそ1.3ドルから8.43ドルの間で推移していることから、誤差が2.7というのはかなり大きいということがわかります。
5.結論
タクシーの乗車距離からチップの支払い金額を予測するモデルを線形回帰モデルを使って構築しました。
乗車距離からチップの支払い金額を予測するモデルを完成させることはできましたが、残念ながらRMSEの結果からモデルの精度は高いとは言えない結果になりました。
乗車距離だけでなく、乗車時間や乗車日など他の特徴量を考慮したり不均衡データになっていないかの確認など特徴量エンジニアリングに関しても積極的に取り組んでいく必要があることがわかりました。
まとめ
scikit-learnの実践ということで、シンプルな線形回帰モデルの構築に取り組みました。
機械学習の手法をインプットしているときはなかなか内容を理解することが難しかったですが、実際にモデルを作ってみることで特徴量エンジニアリングの必要性や評価指標の数字感覚を実感することができました。
今度は特徴量を増やすなどして精度の高いモデルを作れるように頑張ります。