概要
Keras+GoogleColabで顔識別を試してみた。 ハーフ系タレントを見事見分けられるか??
目的
- 顔認識システムを作りたい。
- 過去に試した時の備忘録が消えてしまったので、再度やってみた。今回はメモを残す。
関連記事
やったこと
スクレイピングでデータ収集、データ前処理、モデル定義、Tensorboadで学習過程の可視化、Prediction、GradCamなど。試行錯誤なので無駄なこともやってるかも。
データ準備
画像はスクレイピングで収集。(顔認識のテストのためにスクレイピングでハーフタレントの画像収集してみた)
今回はハーフタレント(ハリー杉山、Joy、ウエンツ、ユージ、+ ラウール)で試してみた。

データを1:5の割合でtrain,testに分類。
#2割をテストデータに移行
import shutil
import random
import glob
import os
print('Making train data & test data...')
datadir ="Orgdata/"
traindir ="data/train/"
testdir ="data/test/"
SearchName = os.listdir(datadir)
test_num = 0.2 # 20%をテスト画像とする
if not os.path.exists(traindir):
os.makedirs(os.path.join(traindir))
if not os.path.exists(testdir):
os.makedirs(os.path.join(testdir))
for name in SearchName:
print(name)
in_dir = datadir+ name
in_png = glob.glob(in_dir+"/*")
img_file_name_list=os.listdir(in_dir)
# img_file_name_listをシャッフル、そのうち2割をtest_imageディテクトリに入れる
random.shuffle(in_png)
if not os.path.exists(testdir+name):
os.makedirs(testdir+name,exist_ok=True)
if not os.path.exists(traindir+name):
os.makedirs(traindir+name,exist_ok=True)
for i_fl in range(len(in_png)):
if i_fl < int(len(in_png)*test_num):
shutil.copy(str(in_png[i_fl]),testdir+name)
else:
shutil.copy(str(in_png[i_fl]),traindir+name)
print('done!')
Data Augmentation
KerasのImageDataGeneratorを使ってみる。(このクラスの存在を知らなかったのでnumpyで関数を作っていた…。) 顔画像には[閾値処理、ぼかし処理、回転処理]が有効らしい。ただ、ぼかし処理はImageDataGeneratorにはないので、自作する必要がある。まずはImageDataGeneratorをつかった水増しを行う。
参考:自前のDeep Learning用のデータセットを拡張して水増しする
import os
import glob
import numpy as np
from keras.preprocessing.image import ImageDataGenerator,load_img,img_to_array,array_to_img
def draw_images(generator,x,img_name,dir_name,index):
save_name = img_name+'_ext'
g = generator.flow(x,batch_size=1,save_to_dir=output_dir,save_prefix=save_name,save_format='png')
# 1つの入力画像から何枚拡張するかを指定
n_aug = 10
for i in range(n_aug):
bach = g.next()
print('Data Augmentation...')
train_dir ="data/train"
SearchName=os.listdir(train_dir)
for i in range(len(SearchName)):
name = SearchName[i]
print(str(i+1)+'/'+str(len(SearchName))+':'+name)
# InputDir
input_dir = train_dir+"/"+name
# Orginalimage
images = glob.glob(os.path.join(input_dir+"/*.png"))
image_file = os.listdir(input_dir)
# OutputDir
output_dir = input_dir
if not (os.path.exists(output_dir)):
os.makedirs(output_dir)
# SettingImageDataGenerator
generator=ImageDataGenerator(
rotation_range = 30, # [deg]まで回転
width_shift_range = 0.1, # 水平方向にランダムでシフト
height_shift_range = 0.1, # 垂直方向にランダムでシフト
channel_shift_range = 50.0,# 色調をランダム変更
shear_range = 0.39,# 斜め方向(pi/8まで)に引っ張る
horizontal_flip = True,# 水平方向にランダムで反転
vertical_flip = False# 垂直方向にランダムで反転
)
# 読み込んだ画像を順に拡張
for i in range(len(images)):
img = load_img(images[i])
img_name = image_file[i].split('.')[0] # 元ファイル名を保存する
# 画像を配列化して転置a
x = img_to_array(img)
x = np.expand_dims(x,axis=0)
# 画像の拡張
draw_images(generator,x,img_name,output_dir,i)
print('done!')
最終的には下記のようなデータ数となった。各150枚スクレイピングして、ごみを目視で取り除く作業をしたらこの位になった。大体同じくらいの数にそろえた方がいいかもしれない。
| original | test | train | |
|---|---|---|---|
| Other | 170 | 34 | 1495 |
| Joy | 74 | 14 | 660 |
| Harry | 70 | 14 | 615 |
| Uentsu | 131 | 26 | 1155 |
| Raul | 55 | 11 | 484 |
| Yuji | 63 | 12 | 559 |
正規化とラベリング
正規化してラベリングを行う。
from keras.utils.np_utils import to_categorical
import cv2
import os
import numpy as np
def normalized(rgb):
norm = np.zeros((rgb.shape[0],rgb.shape[1],3),np.float32)
b = rgb[:,:,0]
g = rgb[:,:,1]
r = rgb[:,:,2]
norm[:,:,0] = cv2.equalizeHist(b)
norm[:,:,1] = cv2.equalizeHist(g)
norm[:,:,2] = cv2.equalizeHist(r)
return norm
def make_label(datadir):
print('loading'+datadir+'...')
SearchName = os.listdir(datadir)
# 教師データのラベル付け
data = []
label = []
for i in range(len(SearchName)):
name = SearchName[i]
img_file_name_list = os.listdir(datadir+"/"+name)
print("{}:Number of data is {}.".format(name,len(img_file_name_list)))
for img_file in img_file_name_list:
img_path = os.path.join(datadir+"/"+name+"/",img_file)
img = np.uint8(normalized(cv2.imread(img_path)))
if(img is None or len(img)==0):
print('image'+img_file+':NoImage')
continue
else:
data.append(img)
label.append(np.uint8(i))
print('done!')
return(data,label)
print('Labeling...')
SaveDir ='data/'
if not os.path.exists(SaveDir):
os.mkdir(os.path.join(SaveDir))
# TrainData
X_train,y_train = make_label('data/train')
X_train = np.array(X_train)
y_train = to_categorical(y_train)
# TestData
X_test,y_test = make_label('data/test')
X_test = np.array(X_test)
y_test = to_categorical(y_test)
# 顔認識する対象のclass Name作成
def classes_name(datadir):
SearchName = os.listdir(datadir)
# ラベル付け
classes = []
for i in range(len(SearchName)):
name = SearchName[i]
classes.append(name)
return classes
classes = classes_name('data/train')
# classes = ['Other', 'Joy', 'Harry', 'Uentsu', 'Raul', 'Yuji']
print(classes)
print('Labeling done!')
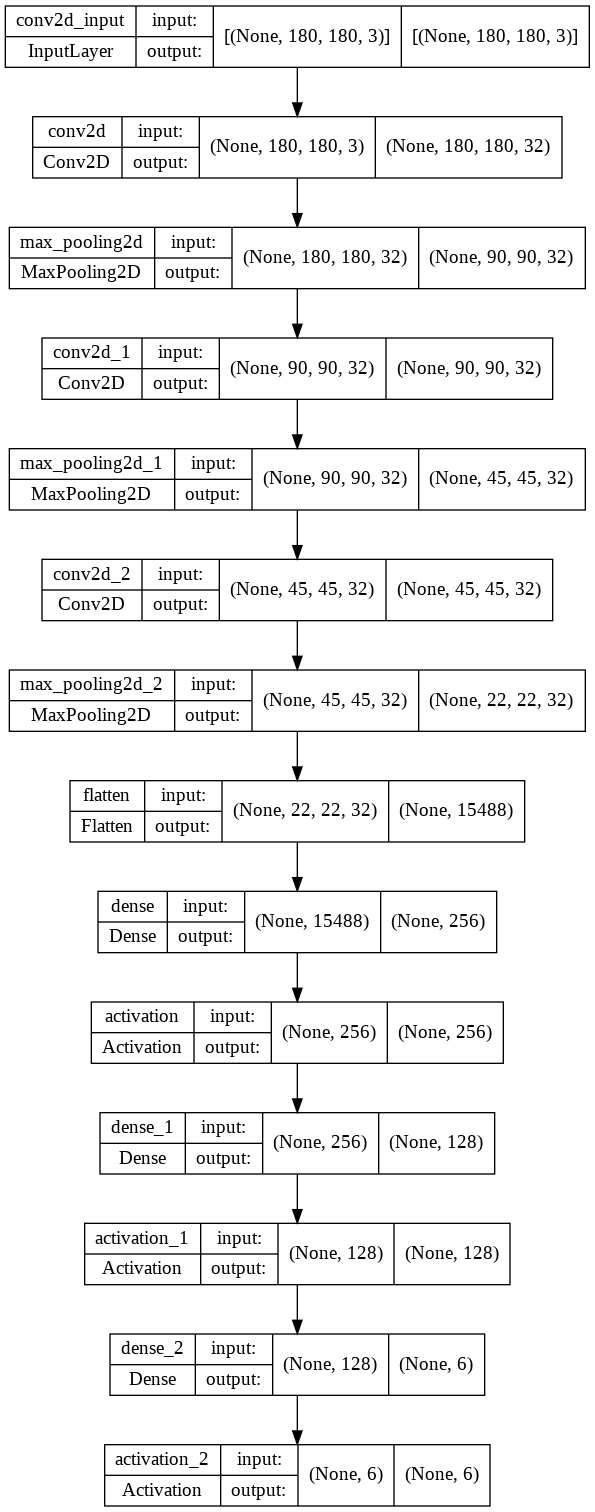
Model
(180x180x3)の画像を6クラス分。
from keras.layers import Activation,Conv2D,Dense,Flatten,MaxPooling2D
from keras.models import Sequential
# CNNで学習するときの画像のサイズを設定(サイズが大きいと学習に時間がかかる)
ImgSize = (180,180,3)
# モデルの定義
model = Sequential()
model.add(Conv2D(input_shape=ImgSize,filters=32,kernel_size=(3,3),strides=(1,1),padding="same"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=32,kernel_size=(3,3),strides=(1,1),padding="same"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=32,kernel_size=(3,3),strides=(1,1),padding="same"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation("sigmoid"))
model.add(Dense(128))
model.add(Activation('sigmoid'))
# 分類したい人数を入れる
model.add(Dense(len(classes)))
model.add(Activation('softmax'))
# コンパイル
print("Compilingmodel...")
model.compile(optimizer='sgd',loss = 'categorical_crossentropy',metrics = ['accuracy'])
print("done")
model.summary()
モデルを可視化すると下記のようになる。
from tensorflow.keras.utils import plot_model
# グラフで可視化。
plot_model(model, show_shapes=True)
学習
コールバックの作成
from keras.callbacks import ModelCheckpoint
# CheckPoint
print("Deifining callbacks...")
filepath = "weights/weights.best.hdf5"
checkpoint = ModelCheckpoint(filepath,monitor='val_accuracy',verbose=1,save_best_only=True,mode='max')
callbacks_list = [checkpoint]
os.makedirs('weights',exist_ok=True)
print("done.")
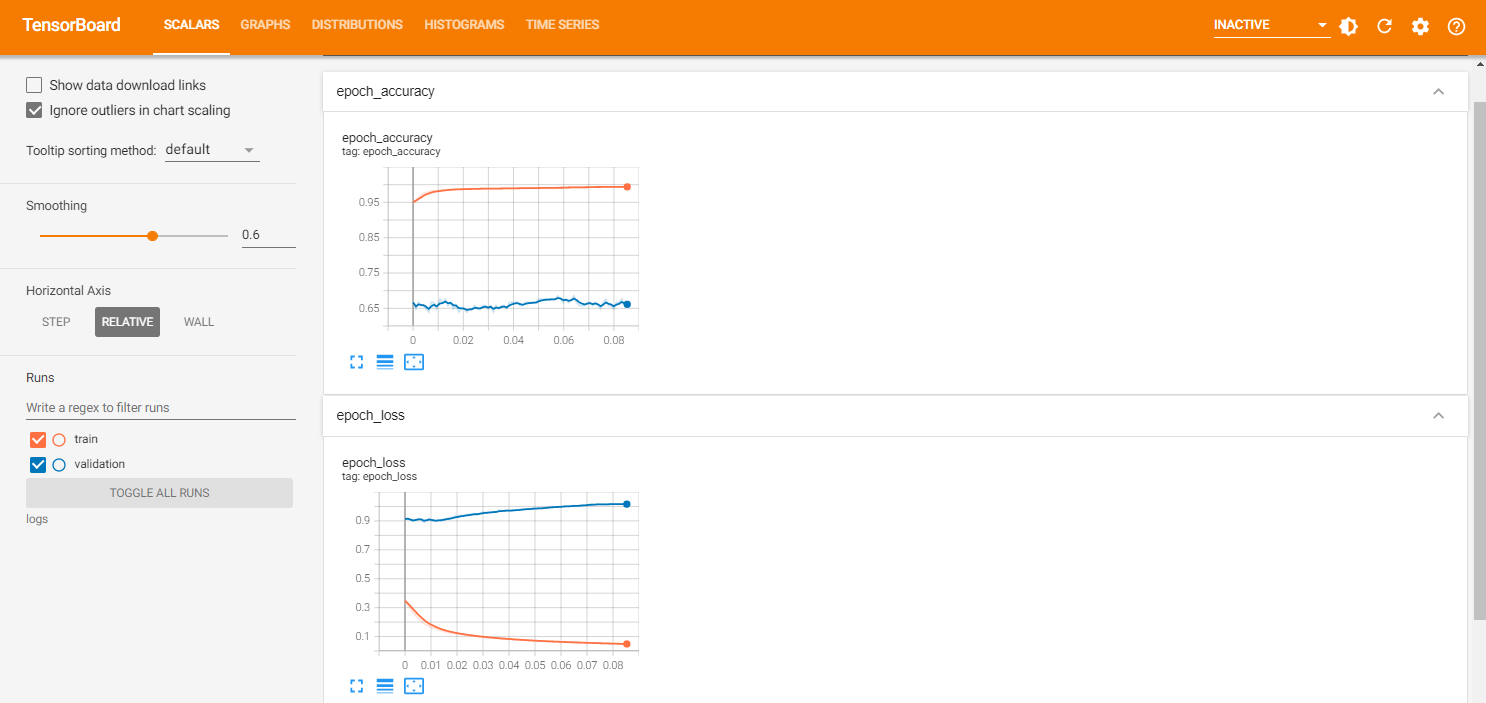
Tensorboad
学習の進捗をリアルタイムでVisualizeするためにTensorboadを使用してみた。必須ではない。
# Load the Tensor Board notebook extension
%load_ext tensorboard
from keras.callbacks import TensorBoard
logdir = "logs"
os.makedirs(logdir,exist_ok=True)
tf_callback = TensorBoard(log_dir=logdir,histogram_freq=1)
callbacks_list = [checkpoint,tf_callback]
# Visualize
%tensorboard --logdir logs
Model fitting
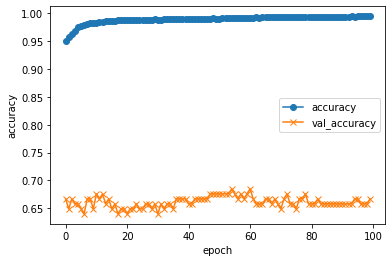
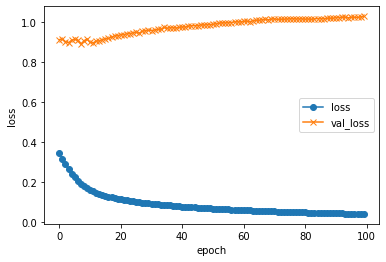
約5000枚のデータをバッチサイズ64、100エポック学習させる。Google Colab上で1エポック4sec程度。学習元のデータが不十分なのか、70エポック程度で過学習気味?accも0.5程度で頭打ち。 データクレンジングしたら改善した。
batch_size = 64
nb_epoch = 100
print("Fitting model...")
history = model.fit(X_train, y_train, batch_size=batch_size, epochs = nb_epoch, verbose = 1, callbacks = callbacks_list, validation_data=(X_test,y_test))
print("done.")
# This save the trained model weights to this file with number of epochs
print("Saving model and weights...")
os.makedirs('models',exist_ok=True)
model.save('models/vgg16_model.hdf5')
model.save_weights('weights/model_weight_{}.hdf5'.format(nb_epoch))
print("done.")
精度の評価・表示
import matplotlib.pyplot as plt
# 汎化精度の評価・表示
score = model.evaluate(X_test, y_test, batch_size=32, verbose=0)
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score))
# acc, val_accのプロット
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
# loss, val_loss
plt.plot(history.history["loss"], label="loss", ls="-", marker="o")
plt.plot(history.history["val_loss"], label="val_loss", ls="-", marker="x")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
Prediction
modelとweightを読み込む。これらのファイルをダウンロードして置けば、別のPC環境でも実行可能。
from keras.models import load_model
model = load_model('models/vgg16_model.hdf5')
model.load_weights("weights/weights.best.hdf5")
testデータの中から適当なデータを突っ込んでみる。
1つの画像をPredictするのに0.15秒弱@Let's Note
# テスト用のコード
from keras.preprocessing import image
import numpy as np
import matplotlib.pyplot as plt
import cv2
from google.colab.patches import cv2_imshow
def normalized(rgb):
# print(rgb)
# returnrgb/255.0
norm = np.zeros((rgb.shape[0],rgb.shape[1],3),np.float32)
b = rgb[:,:,0]
g = rgb[:,:,1]
r = rgb[:,:,2]
norm[:,:,0] = cv2.equalizeHist(b)
norm[:,:,1] = cv2.equalizeHist(g)
norm[:,:,2] = cv2.equalizeHist(r)
return norm
# 画像を読み込んで予測する
def img_predict(filename):
print(filename)
# 画像を読み込んで4次元テンソルへ変換
# 学習時に cv2.equalizeHist で normalized したので、同様に正規化を行う。
img = cv2.imread(filename)
x = np.uint8(normalized(img))
x = np.expand_dims(x, axis=0)
# 表示
cv2_imshow(img)
# 指数表記を禁止にする
np.set_printoptions(suppress=True)
# 画像の人物を予測
pred = model.predict(x)[0]
# 結果を表示する
print(classes[np.argmax(pred)] + ':{:.2f}'.format(pred[np.argmax(pred)]*100) + '%' )
print(classes)
print(pred*100)
import glob
tests = glob.glob('./data/test/*')
for human in tests:
# テスト用の画像が入っているディレクトリのpathを()に入れてください
test = glob.glob(human + '/*')
# 数字は各自入力
i = np.random.randint(len(test))
img_predict(test[i])
print('\n')
-
Other

Other:99.82%
['Other', 'Joy', 'Harry', 'Uentsu', 'Raul', 'Yuji']
[99.82031 0.04009435 0.00082934 0.03350555 0.01194384 0.09332196] -
Joy

Joy:38.14%
['Other', 'Joy', 'Harry', 'Uentsu', 'Raul', 'Yuji']
[37.25051 38.13593 0.01143323 1.0881307 13.000186 10.513814 ] -
Harry

Harry:98.07%
['Other', 'Joy', 'Harry', 'Uentsu', 'Raul', 'Yuji']
[ 0.08365683 0.69369125 98.06667 0.6573652 0.49559665 0.0030142 ] -
Uentsu

Uentsu:64.66%
['Other', 'Joy', 'Harry', 'Uentsu', 'Raul', 'Yuji']
[14.70626 5.4450717 0.35880703 64.6608 4.9400964 9.888976 ] -
Raul

Uentsu:78.08%
['Other', 'Joy', 'Harry', 'Uentsu', 'Raul', 'Yuji']
[ 8.502379 1.1384983 0.36339712 78.08337 11.412714 0.4996482 ] -
Yuji

Yuji:94.60%
['Other', 'Joy', 'Harry', 'Uentsu', 'Raul', 'Yuji']
[ 0.11124698 1.4917603 0.00512221 3.3407028 0.44914895 94.60202 ]
そこそこPredictionできている?
Confusion Matrix
Confusion Matrixをプロットしてみた。
import numpy as np
from sklearn.metrics import confusion_matrix
import pandas as pd
import seaborn as sn
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
def label_class(y_test):
classes = np.zeros((len(y_test),))
for i in range(len(y_test)):
cls = np.nonzero(y_test[i,:])[0][0]
classes[i] = np.uint8(cls)
return classes
def print_cmx(y_true,y_pred,xlabels,normalize=False):
labels = sorted(list(set(y_true)))
cmx_data = confusion_matrix(y_true,y_pred,labels=labels)
if normalize:
cmx_data = cmx_data.astype('float')/cmx_data.sum(axis=1)[:,np.newaxis]
df_cmx = pd.DataFrame(cmx_data,index=labels,columns=labels)
fig = plt.figure(figsize=(12,7))
ax = fig.add_subplot(1,1,1)
fmt = '.2f' if normalize else 'd'
sn.heatmap(df_cmx,annot=True,fmt=fmt,square=True)
ax.set_xticklabels(xlabels)
fig.autofmt_xdate(rotation=45)
ax.set_yticklabels(xlabels)
# fig.autofmt_ydate(rotation=90)
plt.ylabel("actual")
plt.xlabel("predict")
plt.show()
predict_prob = model.predict(X_test)
predict_classes = np.argmax(predict_prob,axis=1)
true_classes = np.argmax(y_test,axis=1)
xlabels = classes
print_cmx(true_classes, predict_classes, xlabels)
print_cmx(true_classes, predict_classes, xlabels,normalize=True)
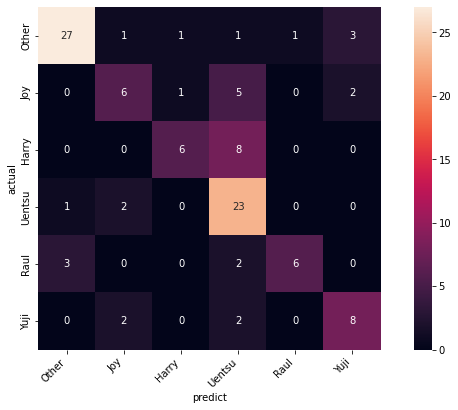
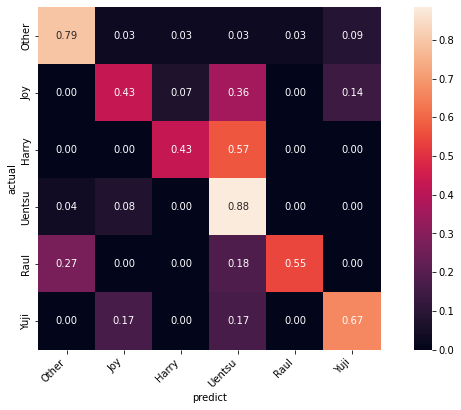
全体的にUentsuに間違えがち。特に、Harry を Uentsuに間違えがち。Uentsuの元データが多く、芸歴も長いのでいろんな画像があるからだろうか?
試しに、オリジナルデータ全て識別させた結果を見てみる。学習に使ったデータが含まれるので、識別率は良くなるはず。
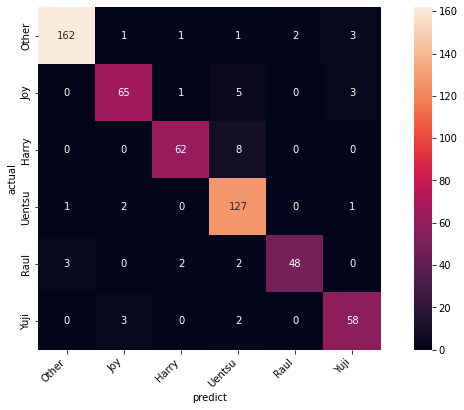
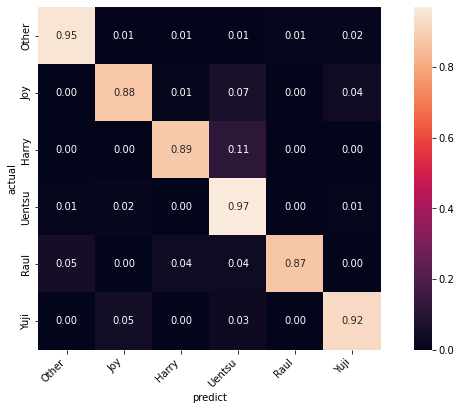
GradCAM
重みの可視化する。Pooling直前の最後のConv層の重みを見るらしい。ここでは"conv2d_2"を指定。
下記エラーが出て困っていたところ、非常に参考になるQiita記事を見つけたので、参考にさせていただきました。
RuntimeError: tf.gradients is not supported when eager execution is enabled. Use tf.GradientTape instead.
kerasとtensorflowでGrad-CAMを実装してみた
バージョン依存によるエラーのようです。2019年に動いたコードが動かなくなって一番はまったのはここでした。他にも以下の記事も参考にしました。
現バージョンは以下。
import tensorflow as tf
import keras
print('tensorflow version: ', tf.__version__)
print('keras version: ', keras.__version__)
tensorflow version: 2.8.2
keras version: 2.8.0
GradCamの関数を定義して、適当な画像で試してみる。
import numpy as np
import cv2
# 画像用
from keras.preprocessing.image import array_to_img, img_to_array, load_img
# モデル読み込み用
from keras.models import load_model
# Grad−CAM計算用
from tensorflow.keras import models
import tensorflow as tf
IMAGE_SIZE=(180,180)
target_layer = 'conv2d_2'
def grad_cam(input_model, x, layer_name=target_layer):
"""
Args:
input_model(object): モデルオブジェクト
x(ndarray): 画像
layer_name(string): 畳み込み層の名前
Returns:
output_image(ndarray): 元の画像に色付けした画像
"""
# 画像の前処理
# 読み込む画像が1枚なため、次元を増やしておかないとmode.predictが出来ない
X = np.expand_dims(x, axis=0)
preprocessed_input = X.astype('float32') / 255.0
grad_model = models.Model([input_model.inputs], [input_model.get_layer(layer_name).output, input_model.output])
with tf.GradientTape() as tape:
conv_outputs, predictions = grad_model(preprocessed_input)
class_idx = np.argmax(predictions[0])
loss = predictions[:, class_idx]
# 勾配を計算
output = conv_outputs[0]
grads = tape.gradient(loss, conv_outputs)[0]
gate_f = tf.cast(output > 0, 'float32')
gate_r = tf.cast(grads > 0, 'float32')
guided_grads = gate_f * gate_r * grads
# 重みを平均化して、レイヤーの出力に乗じる
weights = np.mean(guided_grads, axis=(0, 1))
cam = np.dot(output, weights)
# 画像を元画像と同じ大きさにスケーリング
cam = cv2.resize(cam, IMAGE_SIZE, cv2.INTER_LINEAR)
# ReLUの代わり
cam = np.maximum(cam, 0)
# ヒートマップを計算
heatmap = cam / cam.max()
# モノクロ画像に疑似的に色をつける
jet_cam = cv2.applyColorMap(np.uint8(255.0*heatmap), cv2.COLORMAP_JET)
# RGBに変換
rgb_cam = cv2.cvtColor(jet_cam, cv2.COLOR_BGR2RGB)
# もとの画像に合成
output_image = (np.float32(rgb_cam) + x / 2)
return output_image
# Modeland Weight Setting
model=load_model('models/vgg16_model.hdf5') # load
model.load_weights("weights/weights.best.hdf5")
# 画像を読み込む
test = glob.glob('Orgdata/Uentsu/*')
i = np.random.randint(len(test))
filename = test[i]
# Predictioin
img_predict(filename)
# GradCam
img = cv2.imread(filename)
x = np.uint8(normalized(img)) # 正規化する
gradimg = grad_cam(model, x, target_layer)
gradimg = array_to_img(gradimg)
# 表示
plt.imshow(gradimg)
plt.show()
Orgdata/Uentsu/

Uentsu:99.83%
['Other', 'Joy', 'Harry', 'Uentsu', 'Raul', 'Yuji']
[ 0.01584092 0.02424594 0.02174441 99.82527 0.03469932 0.07820116]

目と口のあたりで判断しているのだろうか…。
結論
学習、識別まで一通り試すことができた。(Google Colaboratoryのノート全体)
データを増やす、正確にラベリングする、怪しいデータ(JOYか誰かわからないような画像)を省くことで識別率が上がったが、testデータでの識別率がいまいち。元データが大事。
モデルさえ作成できればGPUのないPCでも識別処理可能なので、会議中にWEBカメラに映る顔をリアルタイムで識別し続け、会議中に映して遊ぶこともできた。
同じ要領で自分の画像をGoogle Photoから抽出して、OpenCVで切り取り、学習させることもできたので、顔認識を用いるアプリに応用してみたい。