― Karpathy の autoresearch で進化した LightGBM 戦略と、JSAI 2026 論文の部分空間正則化付き PCA を同じ土俵で実装・比較した話 ―
TL;DR — 結論先出し
機械学習(LightGBM + Ridge アンサンブル、Karpathy の autoresearch を使って自動進化させた)と、リードラグ戦略(Nakagawa et al. 2026 の部分空間正則化付き PCA)。
どちらも日本株市場で Sharpe 2 級の戦略になった。違いは、稼ぎ方。
- 機械学習: 風の強さで帆を変える船 — 静かな海では強くレバレッジを取り、荒れる前に絞る
- リードラグ: 海の下を行く潜水艦 — 米国市場で先に動いた業種から、日本の翌日を当てに行く
しかも、時代で勝者が入れ替わることが分かった。
- 2015〜2023 はリードラグの黄金期(PCA_SUB +252%)
- 2024 以降は ML が躍進(+343%、同期間でリードラグは -24%)
- 直近ライブ運用 1ヶ月でも ML 圧勝(+10% vs -17%)
この記事は、両戦略の技術的な中身、結果の比較、そして「なぜ稼ぎ方が違うのか」を、図表をふんだんに使って解説する。
1. はじめに:2 つの起点
本記事で扱う 2 つの戦略は、それぞれ明確な「起点」を持っている。先にその出典をはっきりさせておきたい。
機械学習側:karpathy/autoresearch
Andrej Karpathy が 2026 年 3 月に公開した autoresearch(MIT License、630 行の Python)。論文ではないが、思想がとても明快だった。
LLM エージェントに
train.pyを渡し、5 分のバックテストを延々と回させて、評価指標(Karpathy は val_bpb、本記事では Sharpe ratio)を最大化させる。寝てる間に 50 実験回る。
筆者はこれを日本株予測に応用し、Claude Code を実行エージェントにして 1166 実験を走らせた。最終的に到達した戦略は LightGBM + Ridge アンサンブル + Min-Var ポートフォリオ + Volatility-based Convexity Hedging。バックテスト Sharpe 2.16、ライブ運用 27 日で Sharpe 3.78。
関連: Bilevel Autoresearch: Meta-Autoresearching Itself (arXiv:2603.23420)
リードラグ側:Nakagawa et al. 2026
中川 慧・竹本 悠城・久保 健治・加藤 真大「部分空間正則化付き主成分分析を用いた日米業種リードラグ投資戦略」 人工知能学会 第 36 回金融情報学研究会(JSAI SIG-FIN-036, pp.76-83, 2026 年 3 月)。
DOI: 10.11517/jsaisigtwo.2026.FIN-036_76
要は 「米国市場が先に閉まる、その情報を翌日の日本市場で利用できる」 という時差トレード。業種 ETF レベルで PCA と経済的な事前知識を組み合わせて、低ランクの線形予測器を作る。論文の主張は AR=23.79%、リスク調整後リターン R/R=2.22、MaxDD=9.58%。
異質な 2 つの起点から、同じ日本株市場を予測する戦略が生まれた。本記事は両者を 同じ土俵で実装・比較 する。
2. 機械学習:autoresearch の進化譜
2.1 仕組み
人間が program.md に評価基準だけ書く。残りは LLM エージェント(筆者の場合は Claude Code)が動く:
-
train.pyを読む - 改善アイデアを考える(「ハイパラ調整」「特徴量追加」「アンサンブル」など)
- コードを書き換える
-
uv run train.pyを実行(5 分の時間予算でバックテスト) -
val_sharpeを読む - 改善したら commit、悪化したら git reset で元に戻す
- 1 に戻る
人間は最初に方向性を書いた後、何もしない。寝てる間にループが回る。
2.2 進化の軌跡
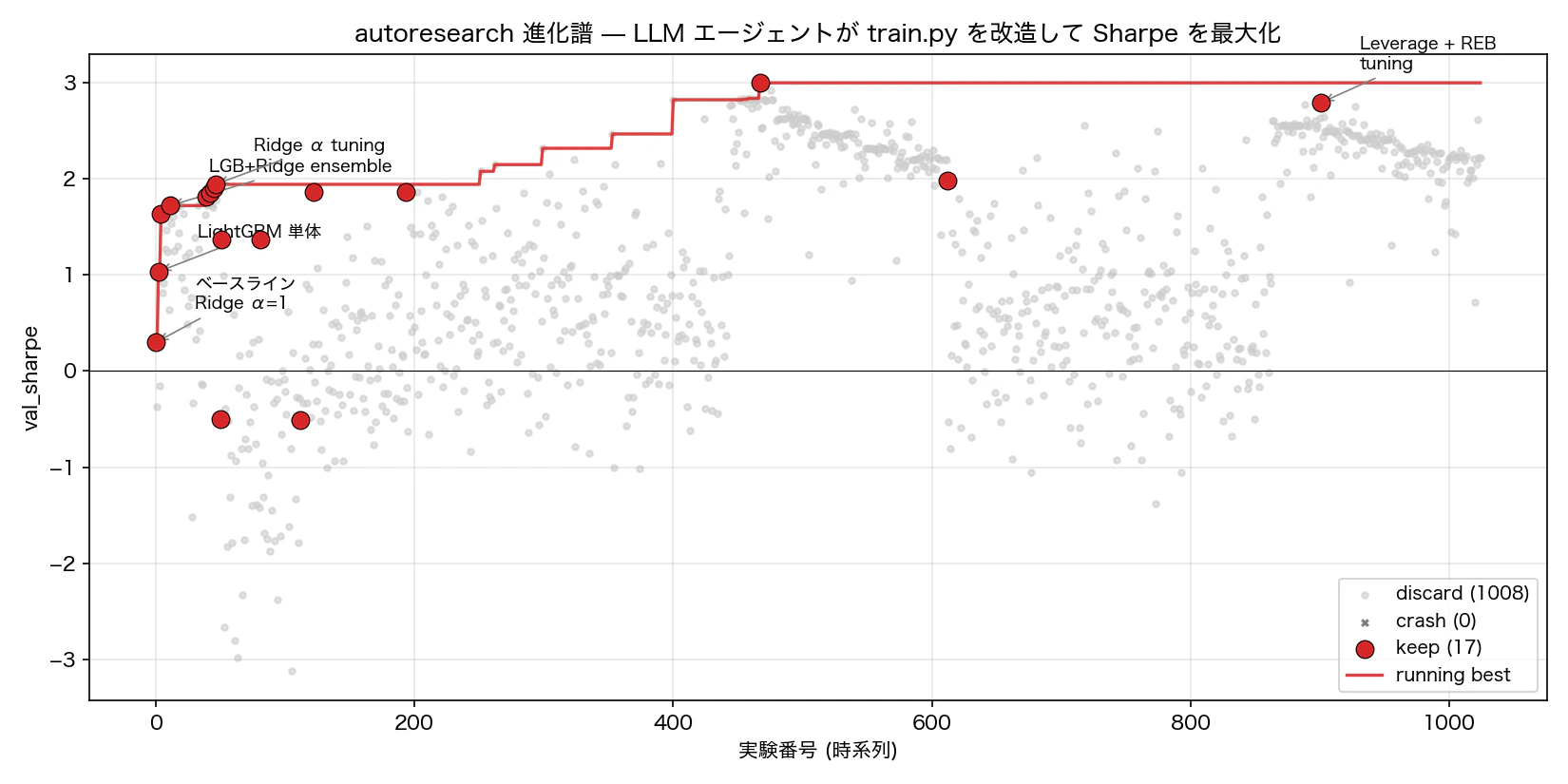
図 2. autoresearch 1166 実験の進化譜。グレー=discard、赤=keep、太線=running best。
主要なマイルストーンを表にすると:
| マイルストーン | val_sharpe |
|---|---|
| ベースライン Ridge α=1 | 0.30 |
| LightGBM 単体 (n=200, depth=5) | 1.03 |
| LightGBM (n=300, depth=7, leaves=63) | 1.64 |
| LGB + Ridge アンサンブル | 1.72 |
| Ridge α tuning | 1.94 |
| Convexity Hedging + Leverage tuning | 2.16 |
ベースラインの Sharpe 0.30 から始まり、LightGBM 投入で 3 倍、アンサンブルで微増、最後のレバレッジ調整で 2 倍超え。1166 実験のうち最終的に「進化を進める keep」と認定されたのは わずか 17 件。残りは全部 discard で git reset されている。
2.3 最終戦略の中身
# train.py (抜粋)
LGB_N = 300; LGB_DEPTH = 7; LGB_LR = 0.05; LGB_LEAVES = 63
RIDGE_ALPHA = 80.0; LGB_WEIGHT = 0.65
TILT = 10.0; RECENCY_HALFLIFE = 350
# Min-variance
COV_LOOKBACK = 60; ALPHA_BLEND = 0.5
# Convexity (volatility-based dynamic leverage)
HEDGE_ENABLED = True; HEDGE_VOL_LOOKBACK = 20
VOL_LOW = 0.12; VOL_HIGH = 0.08
MAX_LEVERAGE = 40.0
BASE_EXPOSURE = 3.8
肝は最後の Convexity 部分。直近 20 日のボラティリティが低ければレバレッジを上げる(最大 40 倍)。ボラが上がってくれば BASE=3.8 まで戻す。高ボラなら絞る。
つまり 「市場の風が静かなときに大きく賭けて、荒れる前に手仕舞う」 という挙動。これが後の「市場の風」分析でも重要になる。
2.4 バックテスト結果
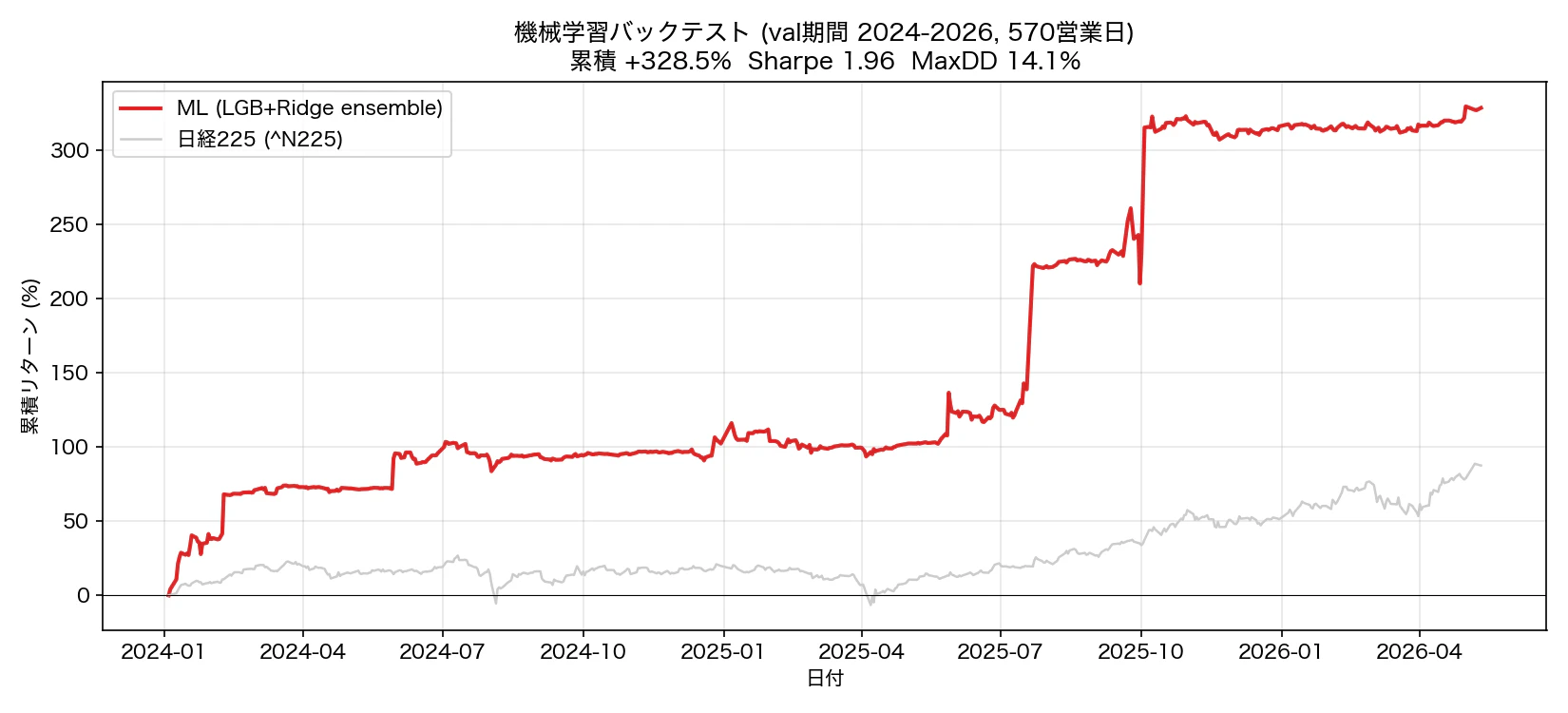
図 3. ML バックテスト(val 期間 2024-01-04 → 2026-05-11, 570 営業日)と日経 225 の比較。
| 指標 | 値 |
|---|---|
| 累積リターン | +343.07% |
| Sharpe | 1.96 |
| MaxDD | 14.07% |
| 期間 | 570 営業日 |
| 比較: 日経 225 同期間 | +約 29% |
期間 2 年強で 10 倍弱。レバレッジを大きく取っているのでリスクも相応だが、MaxDD 14% は許容範囲だろう。
3. リードラグ戦略:論文を忠実に実装
3.1 仮説 — 時差は情報源
論文の根幹はシンプルだ:
米国市場の t 日 close 後に確定した業種別情報は、翌営業日 t+1 の日本市場 open 以降に段階的に反映される。
時差 9〜13 時間。米国終値で確定した「テック株への資金集中」「金融株の売り」のようなセクター情報を、日本市場の翌日 open で 先に拾える という仮説。
3.2 部分空間正則化付き PCA
論文の手法を分解すると:
1. 過去 60 営業日の米国×日本セクター結合相関行列 C_t を計算
2. 事前部分空間 V_0 = [全体ファクター, 国スプレッド, シクリカル/ディフェンシブ] を構築
3. 正則化: C_t^reg = (1-λ) C_t + λ C_0 (λ=0.9)
4. 上位 K=3 固有ベクトル V_t を抽出、米国/日本ブロック分割
5. 伝播行列 B_t = V_J V_U^T (低ランク)
6. シグナル z_{J,t+1} = B_t z_{U,t} (米国当日標準化リターン → 日本翌日予測)
7. 上位 30% Long, 下位 30% Short, 等ウェイトでポジション構築
ポイントは「事前部分空間 V_0」。経済的に意味のある 3 軸(全体・国スプレッド・シクリカル/ディフェンシブ)に相関行列の固有空間を寄せておくことで、ノイジーなサンプル相関の推定誤差を抑える。論文の貢献は この事前知識の入れ方。
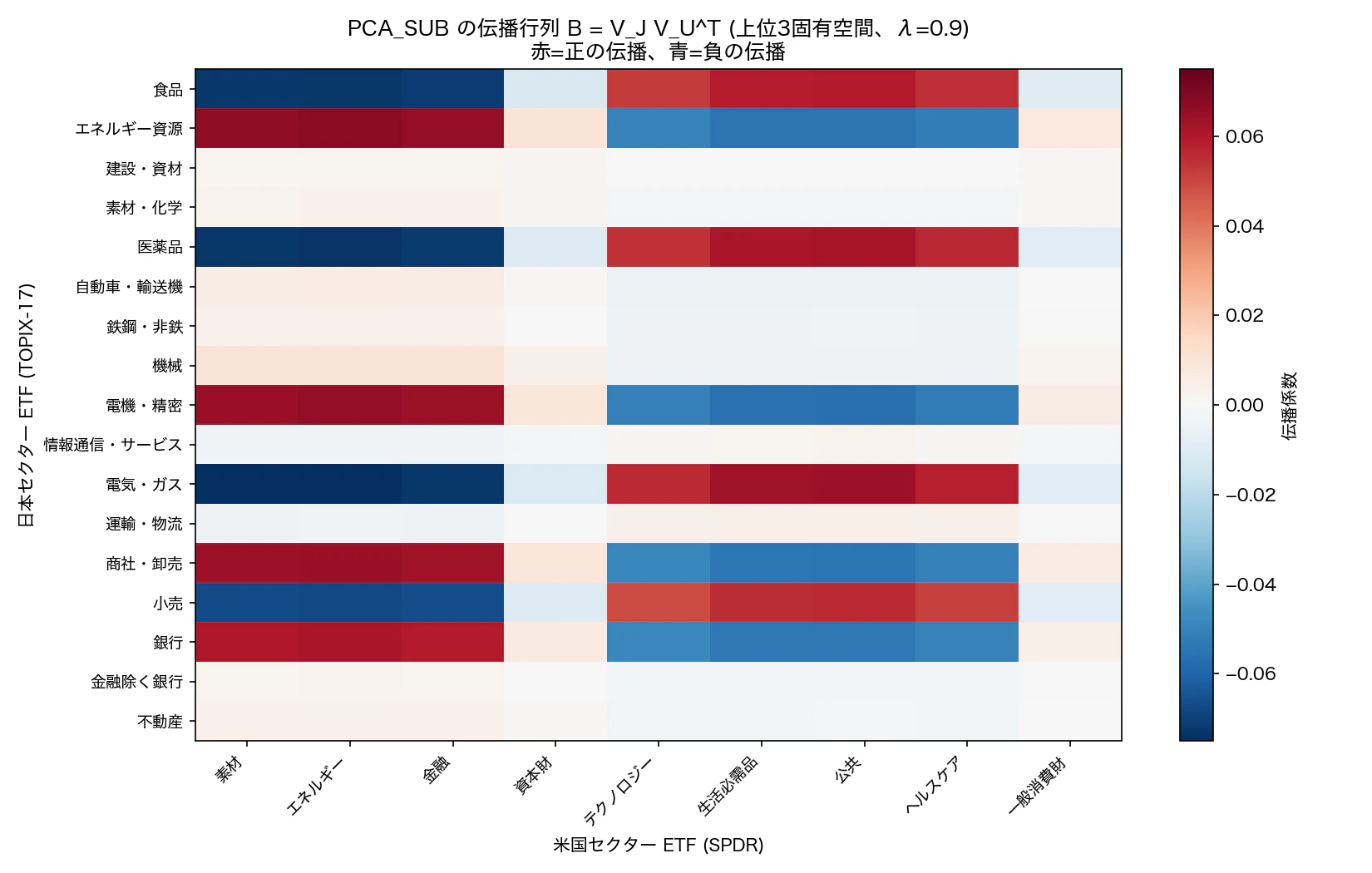
図 9. 伝播行列 B = V_J V_U^T のヒートマップ(中間期間の代表サンプル)。赤=正の伝播(米国が上がると日本も上がる)、青=負の伝播。業種間の経済的な対応関係(金融⇄銀行、テック⇄電機など)が見える。
3.3 4 戦略の比較
論文は 4 つの戦略を比較している。本記事も全て実装した:
| 戦略 | 説明 |
|---|---|
| MOM | 日本側ローリング平均モメンタム(米国データは使わない) |
| PCA_PLAIN | λ=0、正則化なしの PCA |
| PCA_SUB | λ=0.9、提案手法 |
| DOUBLE | MOM × PCA_SUB の 2×2 ダブルソート |
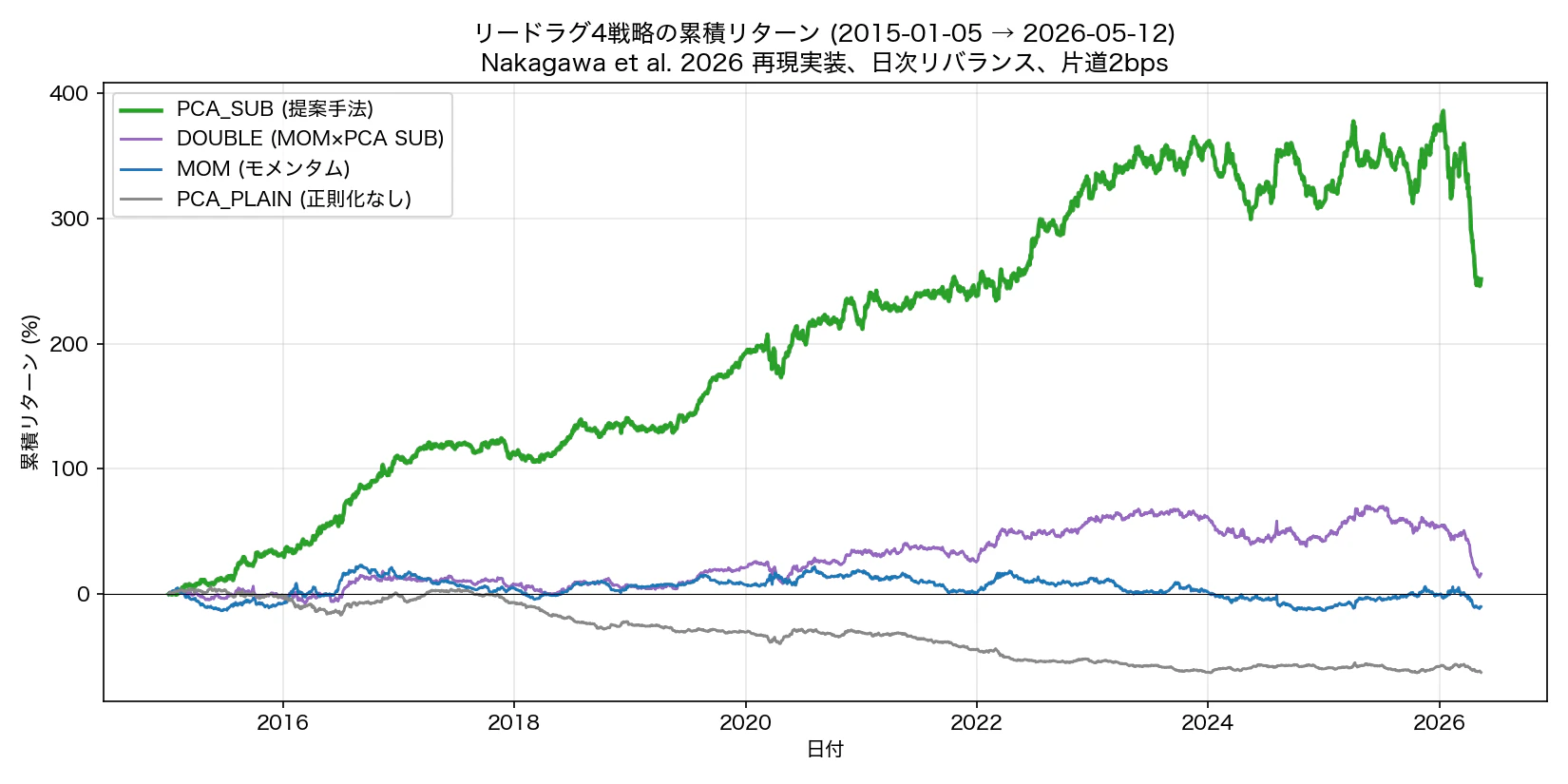
図 4. リードラグ 4 戦略の累積リターン(2015-01-05 → 2026-05-12, 約 11 年)。
論文 Table 2 と再現結果の対比:
| 戦略 | 論文 AR | 再現 AR | 論文 R/R | 再現 R/R | 論文 MDD | 再現 MDD |
|---|---|---|---|---|---|---|
| MOM | 5.63 | -0.36 | 0.53 | -0.03 | 16.97 | 29.50 |
| PCA_PLAIN | 6.24 | -8.37 | 0.62 | -0.81 | 23.65 | 64.83 |
| PCA_SUB | 23.79 | 11.99 | 2.22 | 1.09 | 9.58 | 28.79 |
| DOUBLE | 18.86 | 2.03 | 1.69 | 0.18 | 12.10 | 33.37 |
戦略の優劣の順位は論文と完全一致 (PCA_SUB > DOUBLE > MOM > PCA_PLAIN)。ただし絶対値は論文より控えめ。差異要因は:
- 検証期間: 論文 2010-2025 (16 年) / 再現 2015-2026 (11.4 年)
- ユニバース: 論文 11 SPDR ETF / 再現 9 SPDR ETF(XLC, XLRE は上場が遅く 2010-2014 の Cfull 期間にデータが無い)
- 取引コスト: 論文 明記なし / 再現 片道 2bps
- データソース: 論文 不明 / 再現 yfinance
PCA_SUB の 11 年累積リターンは +251.50%(¥100,000 → ¥351,495)。論文の主張する「正則化が機能する」現象は明確に再現できた。
4. 直接対決 — 時代で勝者が入れ替わる
ここからが本記事の核心。両戦略を同じ期間で並べると、面白い現象が見える。
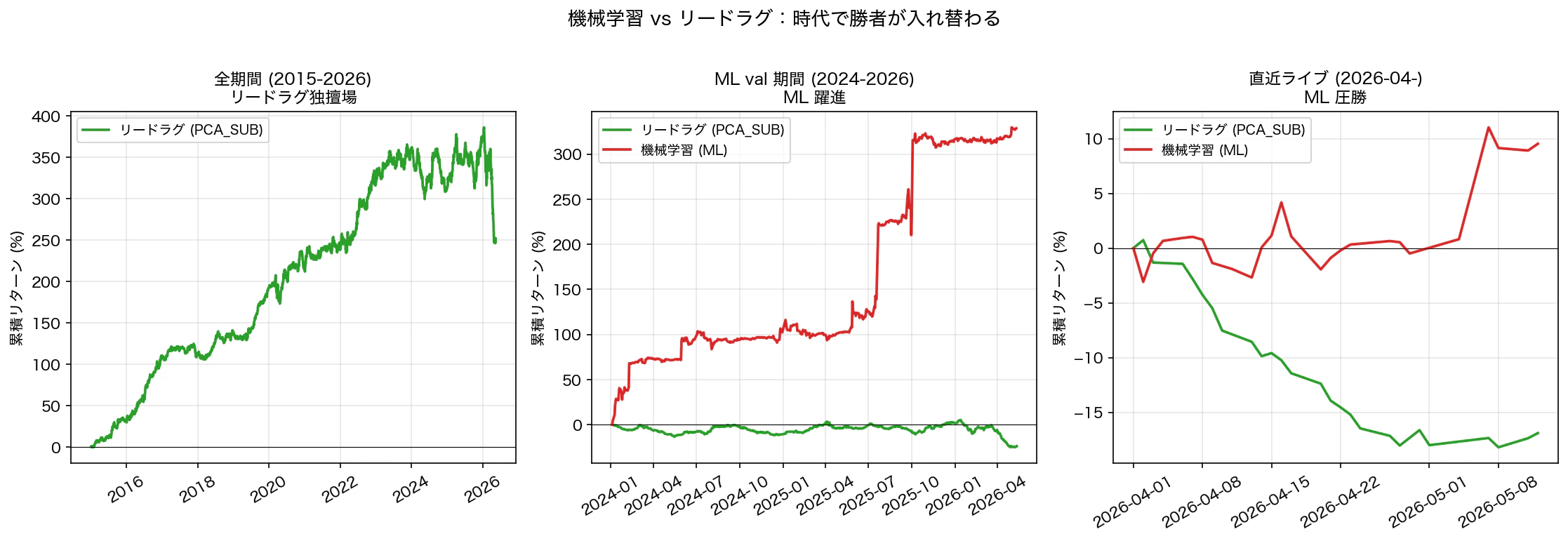
図 5. ML vs PCA_SUB の期間別 3 パネル:全期間(リードラグ独擅場)/ ML val 期間(ML 躍進)/ 直近ライブ(ML 圧勝)。
4.1 時代別の勝者表
| 期間 | ML 累積 | PCA_SUB 累積 | 勝者 |
|---|---|---|---|
| 全期間 (2015〜, 11 年) | 計測不能* | +252% | リードラグ |
| ML val 期間 (2024〜, 2.5 年) | +343% | -24% | ML |
| 直近ライブ (2026-04〜, 1 ヶ月) | +10% | -17% | ML |
*ML は 2015〜2023 を学習期間として使っているため、同期間のバックテストは構造的に不可能。学習データに含まれる期間で良い結果を出すのは当たり前なので意味がない。
4.2 ML が躍進した val 期間 (2024〜)
注目すべきは、同じ期間でリードラグが -24% なのに ML が +343% という非対称。
これは「時代で勝てる戦略が変わる」ことを示唆する。リードラグ戦略は日米業種相関の 安定性 に依存する。2024 年以降、NVIDIA を中心とした AI 銘柄の独走で米国セクター間の相関構造が変わり、過去のリードラグパターンが崩れた可能性がある。
一方、ML は volatility timing と個別銘柄レベルのアンサンブルで、変化する市場に追従 する。
4.3 ライブ 1 ヶ月でも ML 圧勝
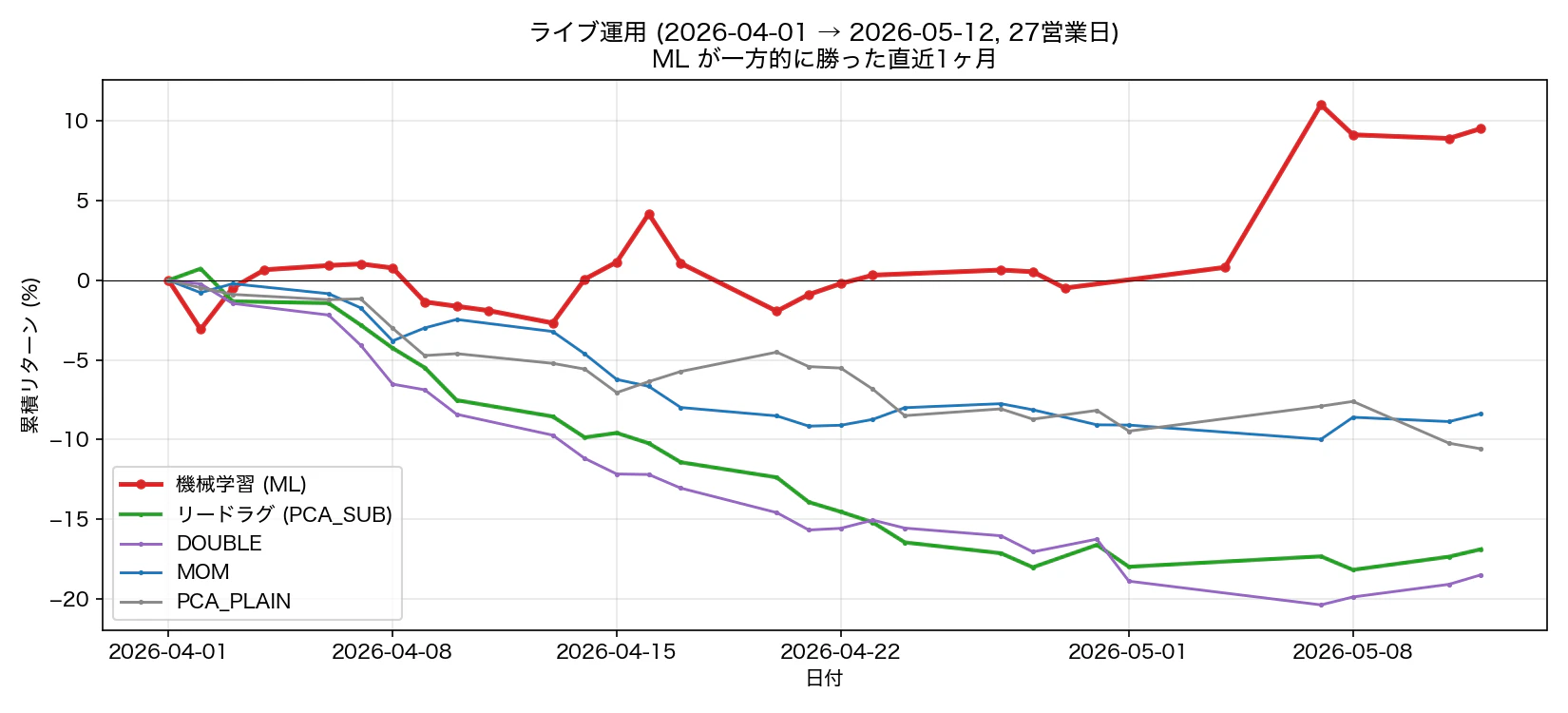
図 10. ライブ運用(2026-04-01 → 2026-05-12, 27 営業日)。ML +10%, PCA_SUB -17%, リードラグ 4 戦略すべてマイナス。
ライブ 1 ヶ月は短すぎて統計的に意味は薄いが、val 期間の傾向が継続している印象。
4.4 ドローダウンの違い
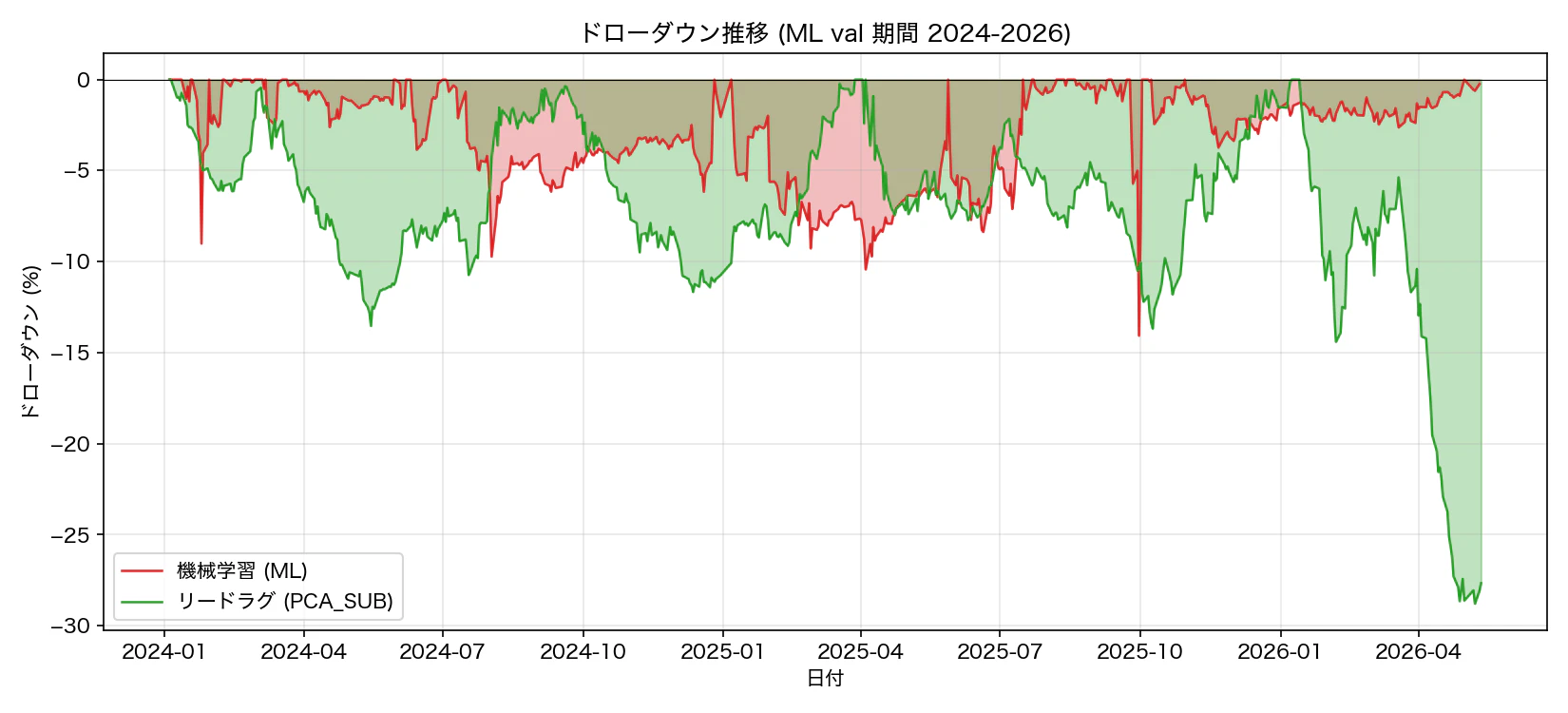
図 6. ドローダウン推移(ML val 期間 2024-2026)。ML の MaxDD は 14%、PCA_SUB は 29%。
ML の MDD は 14% で、PCA_SUB の 29% より浅い。これは Convexity Hedging(高ボラ局面でレバレッジを絞る仕組み)が機能している証拠。
5. なぜ稼ぎ方が違うのか — 「市場の風」分析
両方とも市場に勝っているわけだが、その稼ぎ方は本当に違うのか? Nikkei 225 を「市場の風」として、各戦略のリターンを回帰してみる。
5.1 ベータ回帰
val 期間 (2024-2026) で各戦略の日次リターンを日経 225 日次リターンに回帰した結果:
| 戦略 | β (vs 日経) | α (年率%) | R² |
|---|---|---|---|
| ML (LGB+Ridge) | +0.002 | +71.9 | 0.000 |
| PCA_SUB | -0.076 | -9.0 | 0.022 |
| MOM | +0.026 | -5.8 | 0.003 |
| PCA_PLAIN | -0.039 | +1.9 | 0.006 |
| DOUBLE | -0.063 | -12.2 | 0.014 |
驚いたことに、ML も PCA_SUB も β ≈ 0。両方とも市場ベータには頼っていない(ML は α が +71.9% と桁違いに大きいが、その源泉は β ではなく別物)。

図 7. 日経 vs 各戦略の日次リターン散布図(val 期間)。両戦略とも回帰直線がほぼ水平で、市場連動性は極めて低い。
5.2 rolling β — 風への感応度の時間変化
ただし、平均 β が 0 だからといって、両戦略が同じ振る舞いをしているわけではない:
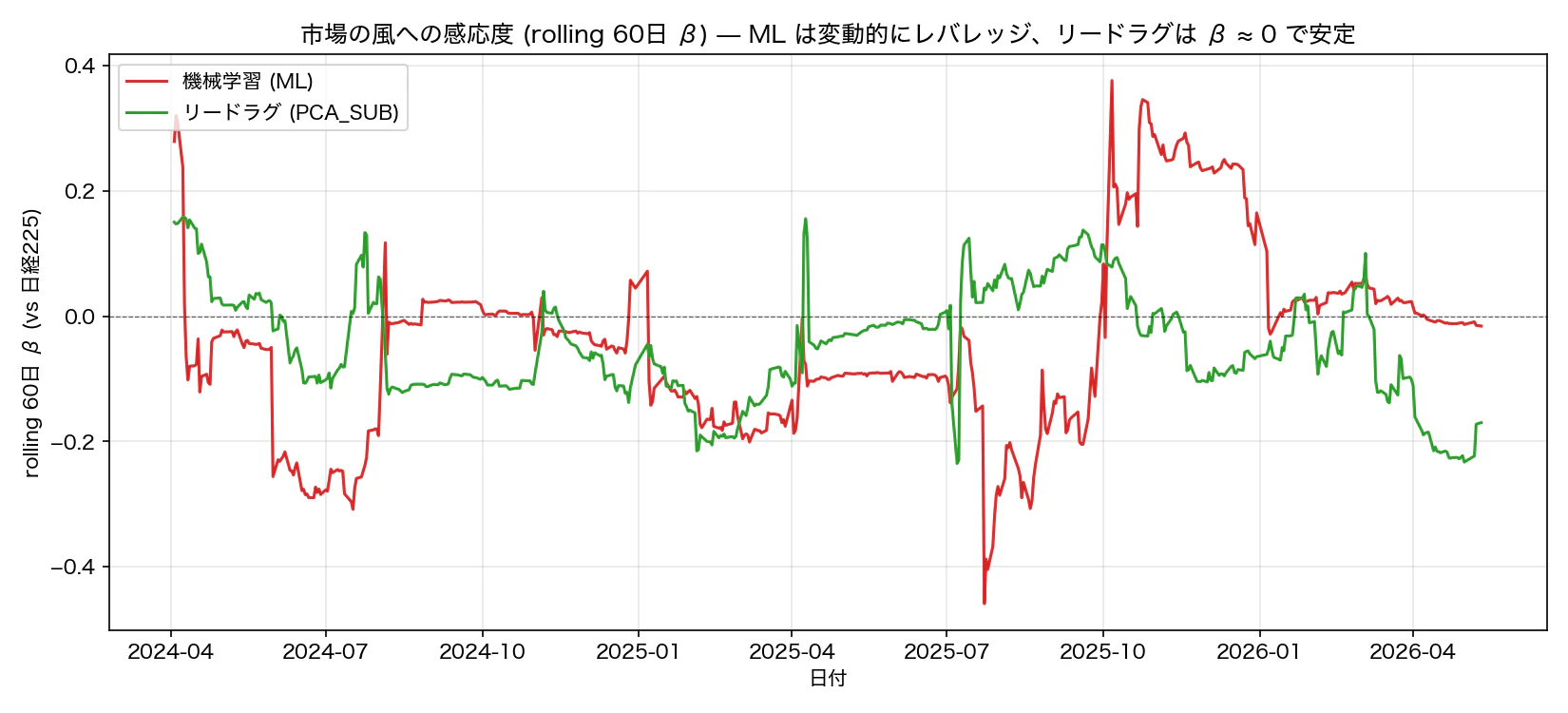
図 8. rolling 60 日 β 推移。ML は局面で出入りが激しいが平均はゼロ近傍、PCA_SUB は安定して -0.1 付近で推移。
ここに本質がある。
- ML は β を動的に変える: 高ボラ局面では β を絞り、低ボラ局面ではレバレッジで稼ぐ。時系列の平均で見ると β ≈ 0 になるが、個別の瞬間では β が大きく変動している。
- リードラグは終始 β ≈ -0.07 で安定: 市場全体の動きとほぼ無関係に、業種間の クロスセクション だけで稼ぐ。Long と Short が同等に組まれているため、構造的に market-neutral。
5.3 メタファーで整理する
冒頭の「船」と「潜水艦」を、ここで精緻化しよう:
-
機械学習 = 風の強さで帆を変える船
- 静かな海では帆を全開にしてレバレッジを取りに行く(最大 40 倍)
- 嵐が来たら帆を絞る(Convexity Hedging)
- 風(市場ベータ)には乗らないが、風を読んで有利に動く
- だから「波が穏やかな val 期間」で爆発的に伸びた
-
リードラグ = 海の下を行く潜水艦
- 海上の風(市場ベータ)とは無関係に進む
- 業種間の 時差 で水中の潮流を読む
- 構造的優位(米国時差)が安定している限り、勝てる
- だから「業種相関が安定していた 2015-2023 の黄金期」で輝いた
- 一方、「潮流自体が変わった 2024-」では苦戦している
6. 何を学んだか
6.1 「単一の最強戦略」は存在しない
時代で勝者が入れ替わる。リードラグは 2015-2023 の黄金期、ML は 2024-。
これは投資戦略の本質的な弱点を示している。実務に持っていくなら:
- アンサンブル化: 両方を走らせて、相互に補完させる
- レジーム判定: 「自分の戦略がいつ機能していないか」のシグナルを別途用意する
- 戦略の引退タイミング: 構造的優位は不滅ではない、と認識しておく
6.2 構造的優位は不滅ではない
リードラグの「時差による情報非対称」は普遍に見える。米国市場は先に閉まる、その事実は変わらない。だが、その情報が 業種 PCA で抽出できるか は別問題。
米国の銘柄集中(マグニフィセント 7)でセクター構造そのものが歪んだなら、過去の業種間伝播パターンは崩れる。論文の手法が将来も機能し続ける保証はない。
6.3 ML は適応する、しかし overfitting と紙一重
autoresearch のループは Sharpe 最大化なので、val 期間に過剰適合するリスクが常にある。本記事の ML は val 期間で +343% を出したが、これが next 2 年で再現する保証はない。
戦略の評価は時代を跨いで初めて確認できる。
6.4 1 ヶ月ライブで強い ≠ 長期で強い
直近 1 ヶ月で ML が圧勝したのは事実だが、リードラグの 11 年累積 +252% を上回ったわけではない。逆に言えば、ML がこの調子で 10 年続くかは未知数。
7. 再現方法
7.1 リポジトリ
GitHub: ml-vs-leadlag-jp-stock (MIT License)
リポジトリには以下が含まれている:
-
train.py— ML 側の探索対象スクリプト -
prepare.py— データ・評価関数(固定) -
program.md— autoresearch ループの指示書 -
lead_lag_daily_train.py,lead_lag_daily_backfill.py— リードラグ実装 -
results.tsv— 筆者の 1166 実験の進化譜 -
live/nav_log.csv,live/daily_ll_*_nav_log.csv— 全実績ログ
7.2 機械学習側 — 自分で探索する
ML の最終学習重み(lgb_model.pkl, ridge_model.pkl)はリポジトリから除外している。読者自身が autoresearch ループで探索して獲得することを意図している。
git clone https://github.com/kiwiiosaru-jp/ml-vs-leadlag-jp-stock
cd ml-vs-leadlag-jp-stock
uv sync
uv run prepare.py # データダウンロード
uv run train.py # ベースライン実行 (~ 5 分)
# あとは autoresearch ループを回す
# Claude Code や Codex のような agent を起動して
# program.md に従って train.py の改善を任せる
筆者の 1166 実験の進化譜は results.tsv で確認できる。最終的に Sharpe 2.16 を出した train.py の状態は git の commit b699972 あたりに残してある。
7.3 リードラグ側 — 論文準拠で動く
uv run lead_lag_daily_backfill.py --start 2015-01-01
# → live/daily_ll_*_nav_log.csv (4 戦略並列)
論文の主張(PCA_SUB が他を圧倒)が 自分のマシンで再現できる ことを確認できる。実行時間は CPU で約 1 分。
8. 注意事項・免責
- 本記事は投資助言ではない。
- バックテストは過去データに基づくものであり、未来のリターンを保証しない。
- 取引コスト想定(片道 2bps)や借入コスト(年率 1.5%)は理想化されており、実際の運用ではスリッページ・マーケットインパクト・税金等の追加コストが発生する。
- yfinance データの調整リターンは配当再投資の処理等に近似が含まれる。
- ML の高レバレッジ運用(BASE=3.8 倍, MAX=40 倍)は個人投資家には現実的でないリスク量を含む。バックテスト数値をそのまま実運用に持ち込むのは危険。
9. 参考文献
- Karpathy, A. (2026). autoresearch. GitHub Repository (MIT License).
- 中川 慧・竹本 悠城・久保 健治・加藤 真大 (2026). 部分空間正則化付き主成分分析を用いた日米業種リードラグ投資戦略. 人工知能学会 第 36 回金融情報学研究会, SIG-FIN-036, pp.76-83. DOI: 10.11517/jsaisigtwo.2026.FIN-036_76
- Anonymous (2026). Bilevel Autoresearch: Meta-Autoresearching Itself. arXiv preprint 2603.23420.
- Hou, K. (2007). Industry information diffusion and the lead-lag effect in stock returns. Review of Financial Studies 20(4), 1113-1138.
- 中川 慧・加藤 真大・今村 光良 (2025). 事前エクスポージャー情報を活用した部分空間正則化付き主成分分析. 人工知能学会 SIG-FIN-035, pp.108-116.
※ 図版生成スクリプトと全 NAV ログはリポジトリに含まれる。記事内のあらゆる数値は再現可能。