モチベーション
とある家族見学会のイベントで、子供も楽しめるゲームを作ろうと思い立ちました。
子供も楽しめるものといえばじゃんけん…という安易な発想から、カメラ1台でじゃんけんの出し手を認識して勝ったらお菓子を進呈する装置を作ってみました。
今回は、物体検出アルゴリズムとしてYolov3を、動作させる環境としてJetsonNano+ROSの組み合わせで実装しました。
(じゃんけん画像認識自体はすでに色々な方が試行されていますが、ここではYolo・Jetson・ROSという色々と応用が効きそうな方法のお試しも兼ねてやっています。)
この記事の中で触れること
- データセットの作成
- Yolov3の学習
- JetsonNanoへの実装
すべての手順について詳細に触れられるわけではありませんが、ポイントになりそうなところを掻い摘んで説明できればと思います。誰かのお役に立てれば。
データセットの作成
一般的にはDeeplearningベースの物体認識では数千枚オーダーのデータセットが必要になってきます。
精度の良い物体検出モデルを作るためには、いろいろな姿勢・背景の手を含む写真を集めてアノテーション(どこにどのポーズの手が写っているかマークする作業)を行う必要があります。
画像収集やアノテーションの作業をゼロからやるのはとても大変です。
なんとか手抜きをする方法がないかWebを探して見たところ、じゃんけんを画像認識で実装しているドンピシャな記事を見つけました。
こちらの記事では、画像に写っている手のポーズを推定する(Classification)タスクを扱っていますが、今回は手のポーズに加えてその位置も推定する(Detection)タスクで実装します。
上でご紹介した記事では、トルコの高校生の方々が作ったデータセットを使っていますが、ここでもそのデータセットを活用します。
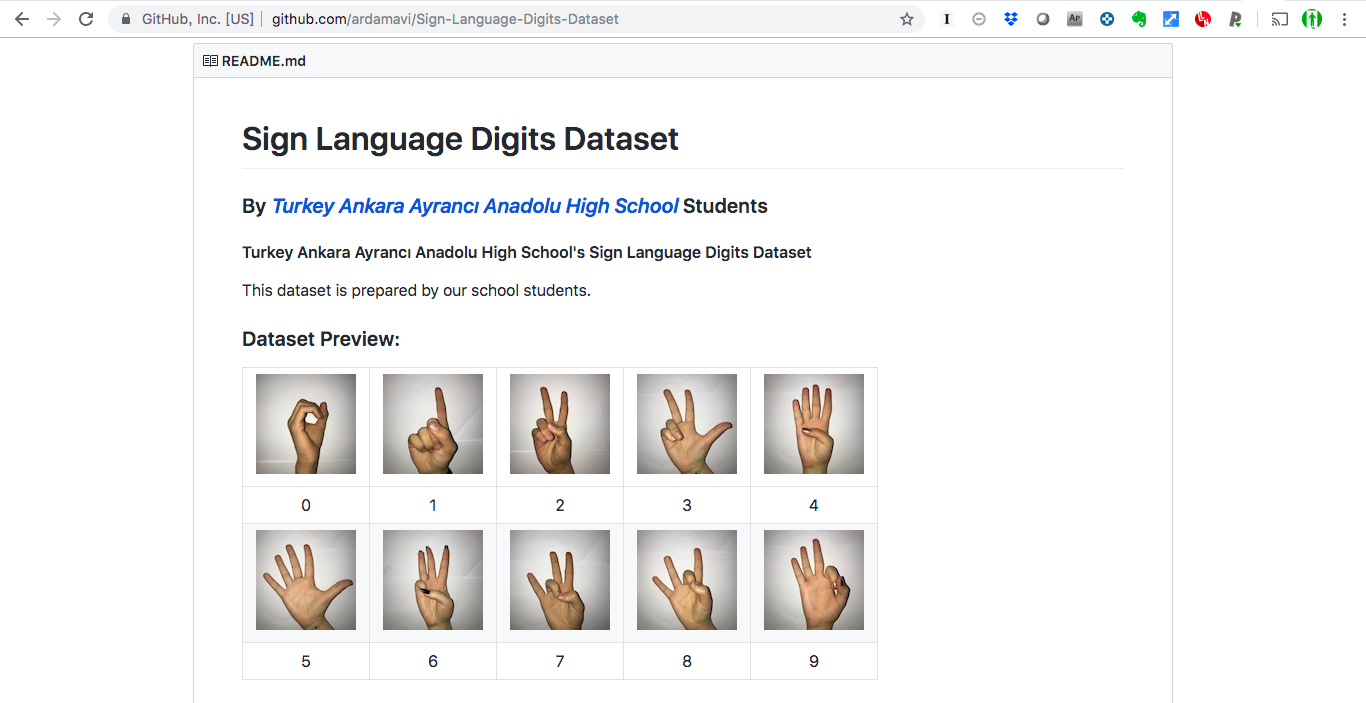
Sign-Language-Digits-Datasetは、0〜9を表す手のポーズをそれぞれおよそ200枚ずつ保持しています。今回は、グー・チョキ・パーがわかればよいので0・2・5の三クラス分のデータを利用します。
このデータセットはそれぞれの写真とそのクラス番号の情報しかありませんが、物体検出の学習を行えるようにするために、どうにかして手の領域をアノテーションしてあげる必要があります。また、白背景だけではなく色々な種類の背景を生成して、よりロバストなモデルを作りたいと思います。
今回のデータセット生成の流れは下記の通りです。
- 手の領域を切り抜いた画像を生成する
- データオーグメンテーション
- 結合された画像に対応するアノテーションデータを自動生成する
手の領域切り抜き
手の領域の切り抜き方法として、安易ではありますがOpenCVの色域抽出機能を使いました。
Sign-Language-Digits-Datasetでは背景が白であるため、下記のように切り抜き自体は比較的うまくいきました。左から元画像、色域抽出によるマスク領域、元画像からマスク領域のみを切り抜いた画像です。元画像には、マスク領域をもとに外接矩形を描画しています。

色域抽出に使ったコードはこちら。
def colorRange(hsvImg):
HSV_MIN = np.array([0, 20, 40])
HSV_MAX = np.array([20, 220, 255])
hsv_mask = cv2.inRange(hsvImg, HSV_MIN, HSV_MAX)
kernel = np.ones((2,2),np.uint8)
ksize=5
hsv_mask = cv2.medianBlur(hsv_mask,ksize)
hsv_mask = cv2.morphologyEx(hsv_mask, cv2.MORPH_CLOSE, kernel)
hsv_mask = cv2.dilate(hsv_mask,kernel,iterations = 1)
return hsv_mask
データオーグメンテーション
前項で切り抜かれた手の画像に、色々と手を加えてデータオーグメンテーションをしていきます。
目的は、色々な条件下の画像に反応できるようにするためです。
今回は色々な背景に対応できるようなモデルを作る必要があるため、データセットにも色々な背景を含めてあげる必要があります。
とはいえ、背景の画像を収集するのが面倒だったのでまずはガウシアンノイズを使って背景を埋めてみることにしました。ついでに、元画像を3方向に回転させて合成します。禍々しいね。

ガウシアンノイズを加えるために使ったコードはこちら。
def addGaussianNoise(src):
row,col,ch= src.shape
mean = 0
var = 0.5
sigma = 50
gauss = np.random.normal(mean,sigma,(row,col,ch))
gauss = gauss.reshape(row,col,ch)
a=1
noisy = a*src + (4-a)*gauss
return noisy
ちなみに、画像は下記のようにして回転させて合成しています。
def augmentedImage(img):
orgH, orgW = img.shape[:2]
aImg = np.zeros((orgH*2, orgW*2, 3), np.uint8)
aImg[0:orgH,0:orgW] = img
#90度
transpose_img = img.transpose(1,0,2)
clockwise = transpose_img[:,::-1]
aImg[orgH:orgH*2,0:orgW] = clockwise
#-90度
counter_clockwise = transpose_img[::-1]
aImg[0:orgH,orgW:orgW*2] = counter_clockwise
#180度
xAxis = cv2.flip(img, 0)
yAxis = cv2.flip(img, 1)
xyAxis = cv2.flip(img, -1)
aImg[orgH:orgH*2,orgW:orgW*2] = xyAxis
return aImg
結論から言うと、ガウシアンノイズだけでは背景のオーグメンテーションとして不十分だったので下記のようにWeb上の画像を追加で合成しています。禍々しいね(2回目)。

背景の画像は、こちらのサイトのものをお借りしました。
処理を抜粋するとこんな感じです。backgroundDirの中に背景画像を入れておいて、ランダムに選択・切り抜きした上で100×100のサイズにリサイズしています。
backgroundFiles = [r for r in glob.glob(backgroundDir)]
bgImg = cv2.imread(random.choice(backgroundFiles))
n = int(random.randint(-10, 10)*15)
bgImg = bgImg[300+n:500+n, 200+n:400+n]
bgImg = cv2.resize(bgImg, (100, 100))
更に、学習と推論を試して見ると子供の手にうまく反応できないことがわかってきました。
どうも、大人と子供の手の大きさや指長さが影響しているようです。
手前味噌ではありますが、アフィン変換で画像を圧縮(つぶして)画像生成しました。縦の長さの30%くらいを圧縮しています。禍(以下略)

処理は下記のような感じで。
def pressImage(img, ratio):
ratio = 1.0 - ratio
orgH, orgW = img.shape[:2]
src_pts = np.array([[0, 0], [int(orgW/2), 0], [orgW, orgH]], dtype=np.float32)
dst_pts = np.array([[0, int(orgH*ratio)], [int(orgW/2),int(orgH*ratio)], [orgW, orgH]], dtype=np.float32)
mat = cv2.getAffineTransform(src_pts, dst_pts)
#print(mat)
affine_img = cv2.warpAffine(img, mat, (orgW, orgH))
return affine_img
アノテーションデータの生成
前の章で説明したマスク画像を生成した時点で手の領域の座標がわかるので、その情報を使ってアノテーションデータを生成します。下記のようにマスク画像(maskImg)をもとに、外接矩形を検索します。
ここでは、元画像に手が一つしか写っていない前提で最も大きな矩形を選び出しています。
dst, contours, hierarchy = cv2.findContours(maskImg, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
for i, contour in enumerate(contours):
area = cv2.contourArea(contour)
if area < size_min:
continue
if image_size * 0.99 < area:
continue
x,y,w,h = cv2.boundingRect(contour)
if w*h > size_max:
size_max = w*h
maxX,maxY,maxW,maxH = x,y,w,h
各画像ごとにグー、チョキ、パーが写っている座標をアノテーションファイルとして出力すれば学習の準備は完了。
YOLOv3の学習
ここまでで作成したデータセットをもとに、YOLOv3(darknet)を使って学習を進めます。
詳細な手順は各所で紹介されていますので省略しますが、今回は推論速度を優先してtiny-yoloを使っています。
学習時、標準出力にログが表示されます。
バッチサイズを128で設定しているため、128枚の画像を学習するごとにlossやlearning rateなどの情報が出力されます。
Region 23 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.538939, .5R: -nan, .75R: -nan, count: 0
Region 16 Avg IOU: 0.276084, Class: 0.366372, Obj: 0.541348, No Obj: 0.476522, .5R: 0.218750, .75R: 0.000000, count: 32
Region 23 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.539579, .5R: -nan, .75R: -nan, count: 0
1: 485.622101, 485.622101 avg, 0.000000 rate, 3.699675 seconds, 128 images
avgで表示されているloss、rateで表示されている学習率を縦軸に、イテレーション数を横軸にグラフを書くと下のような感じになります。学習率はデフォルトで0.001を目指すように設定されていますが、今回は1000イテレーション付近ですでにサチっています。
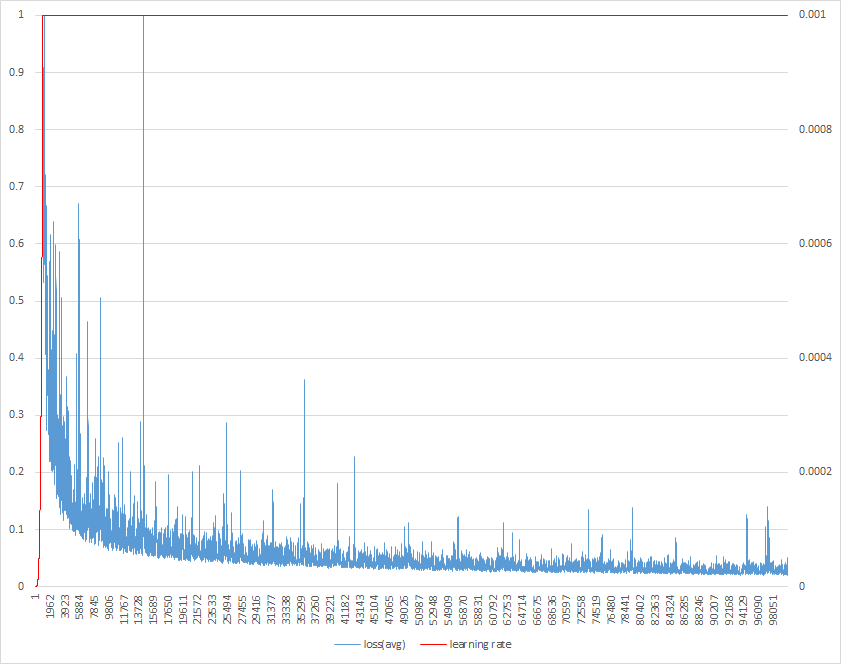
出来上がったモデルとしては、100000イテレーション付近のものがうまく手に反応できていたのでそれを使いましたが、各種ハイパーパラメータはチューニングの余地ありかと思います。
Jetson Nanoへの実装
出来上がったモデルを動作させる環境として、流行りのJetson Nanoを使って見ました。
1万円ちょっと出して強力かつ小型のGPUマシンが手に入るとは、良い時代になりましたね。

ケースには、Thingiverseで配布されているものを出力して利用しました。
セットアップについてはからあげさんの記事で詳細に説明されておりますので、そちらを参考にしています。
構成はこちらの通り。
- Jetson Nano(Jetpack4.2.1)
- Logicool C270(USB-Webカメラ)
- IODATA WN-G300UA(USB Wi-FIモジュール)
- ROS melodic
- darknet_ros(darknetのROS向けラッパー)
- usb_cam(UVCカメラドライバ)
ハードウェア類は、特にドライバインストールせずに動作しました。
またGPUをフルに活用するため、ここではPower Mode: MAXNで動作させます。
microUSBでは電力が不足するため、DCジャックから給電できるようにします。また、ファンも取り付けておきました。
ちなみに、現在のPower Modeは”nvpmodel -q”で確認できます。
darknet_rosは公式のGitから、usb_camについてはaptでインストールすることができます。
Jetpack4.2.1では、公式の手順から特に変えることなくインストールできました。
sudo apt install ros-melodic-usb-cam
続いて、darknet_rosを使った推論実行について説明します。
darknet_rosをオリジナルの学習済みモデルにて使う際に作成、変更が必要な設定ファイルは下記の通りです。(ROSのワークスペースを”~/catkin_ws”に作成していると仮定)
- ~/catkin_ws/src/darknet_ros/darknet_ros/config/ros.yaml
- Subscribeするカメラ画像トピックの名前などを指定
- ~/catkin_ws/src/darknet_ros/darknet_ros/config/janken-yolov3-tiny.yaml
- 学習済みモデルと設定ファイル(weights,cfg)や表示時の閾値、クラス名を定義
- ~/catkin_ws/src/darknet_ros/darknet_ros/yolo_network_config/cfg/janken-yolov3-tiny-train-3classes.cfg
- 学習済みモデルに対応する設定ファイル。入力画像サイズもここで変えることができる
- そのほか、学習済みモデルは~/catkin_ws/src/darknet_ros/darknet_ros/yolo_network_config/weightsに格納する
ros.yamlについて、usb_camからの出力トピックを受けられるようにするため、subscriberを下記のように記載します。
subscribers:
camera_reading:
topic: /usb_cam/image_raw
queue_size: 1
janken-yolov3-tiny.yamlはこんな感じ。
yolo_model:
config_file:
name: janken-yolov3-tiny-train-3classes.cfg
weight_file:
name: janken-yolov3-tiny-train-3classes_100000.weights
threshold:
value: 0.3
detection_classes:
names:
- gu
- tyoki
- pa
janken-yolov3-tiny-train-3classes.cfgについては、画像の入力サイズを下げて処理速度を向上させます。width,height部分の設定によって、ネットワークへの入力画像サイズを変更できます。最初だけ抜粋するとこんな感じ。
[net]
# Testing
batch=1
subdivisions=1
# Training
#batch=64
#subdivisions=16
width=288
height=288
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
推論用にbatch,subdivisionsを1にするのを忘れずに。
usb_camノードとdarknet_rosを同時に起動させるためのlaunchファイル(janken-yolov3-tiny.launch)を用意しました。
<?xml version="1.0" encoding="utf-8"?>
<launch>
<node name="usb_cam" pkg="usb_cam" type="usb_cam_node" output="screen" >
<param name="video_device" value="/dev/video0" />
<param name="image_width" value="640" />
<param name="image_height" value="480" />
<param name="pixel_format" value="yuyv" />
<param name="camera_frame_id" value="usb_cam" />
<param name="io_method" value="mmap"/>
</node>
<node name="image_view" pkg="image_view" type="image_view" respawn="false" output="screen">
<remap from="image" to="/usb_cam/image_raw"/>
<param name="autosize" value="true" />
</node>
<!-- Console launch prefix -->
<arg name="launch_prefix" default=""/>
<!-- Config and weights folder. -->
<arg name="yolo_weights_path" default="$(find darknet_ros)/yolo_network_config/weights"/>
<arg name="yolo_config_path" default="$(find darknet_ros)/yolo_network_config/cfg"/>
<!-- ROS and network parameter files -->
<arg name="ros_param_file" default="$(find darknet_ros)/config/ros.yaml"/>
<arg name="network_param_file" default="$(find darknet_ros)/config/janken-yolov3-tiny.yaml"/>
<!-- Load parameters -->
<rosparam command="load" ns="darknet_ros" file="$(arg ros_param_file)"/>
<rosparam command="load" ns="darknet_ros" file="$(arg network_param_file)"/>
<!-- Start darknet and ros wrapper -->
<node pkg="darknet_ros" type="darknet_ros" name="darknet_ros" output="screen" launch-prefix="$(arg launch_prefix)">
<param name="weights_path" value="$(arg yolo_weights_path)" />
<param name="config_path" value="$(arg yolo_config_path)" />
</node>
</launch>
システムの起動は、下記の通り。シンプルですね。
roslaunch darknet_ros janken-yolov3-tiny.launch
起動すると、USBカメラの画像と推論結果を重畳されたものが表示されます。
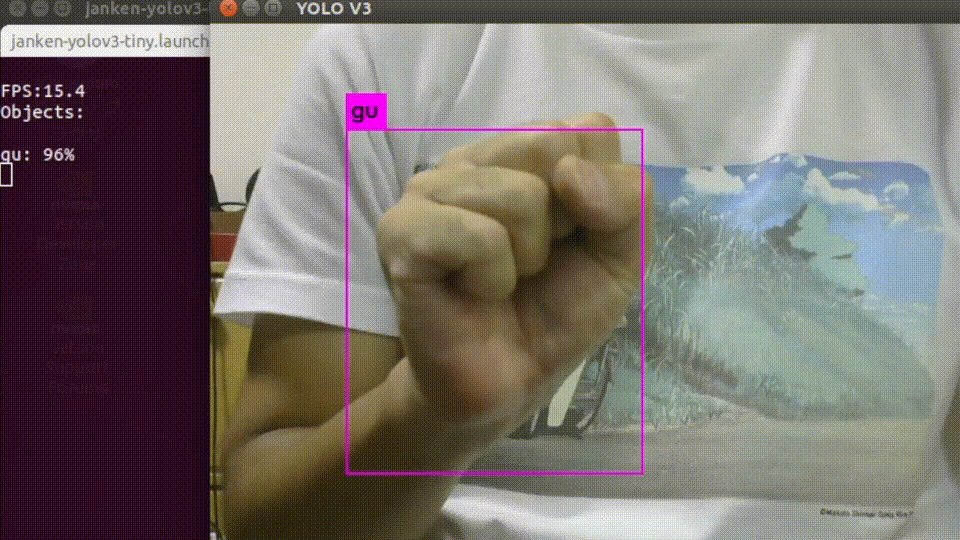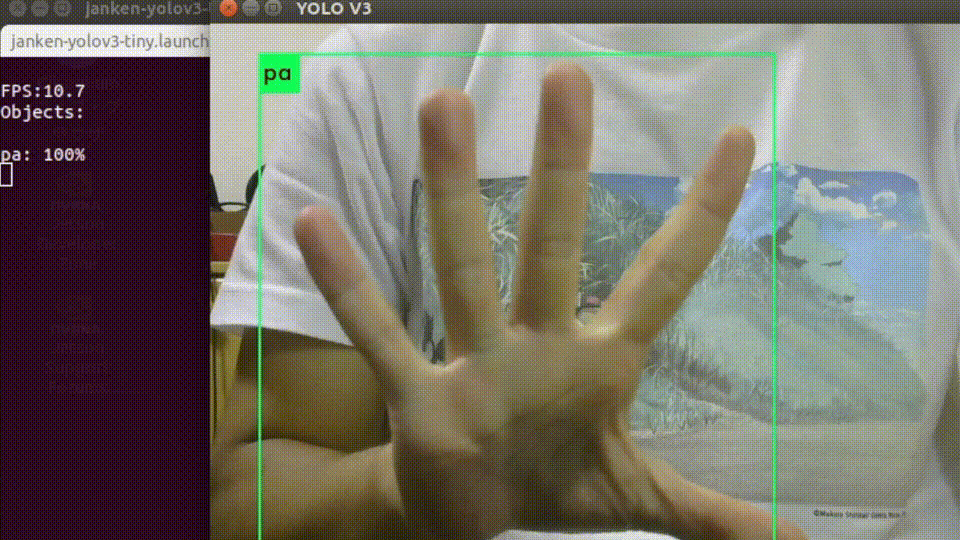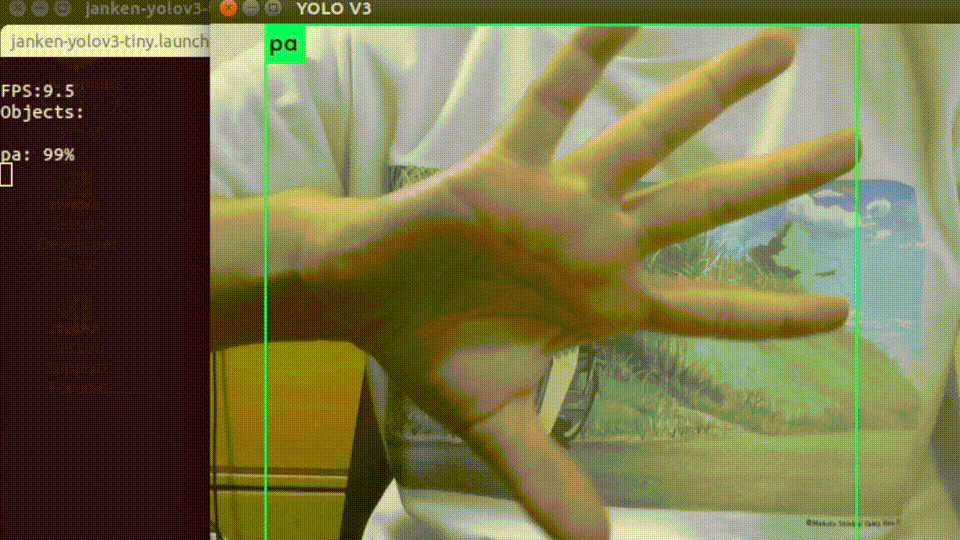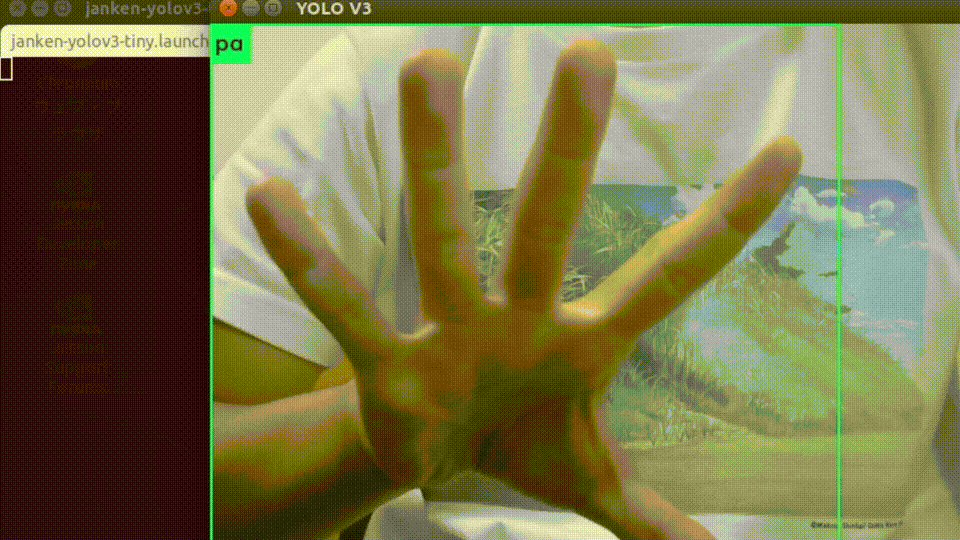
入力画像サイズを縮小していることもあって、平均して10-12fpsくらいの速度で処理できています。
オーギュメンテーションを頑張った甲斐もあり、背景や手の向きに強くなっています。
終わりに…
大変に長くなりましたが、ここまで読んでくださってありがとうございます。
単純な推論だけだったらdarknetを単体で使えばよいのですが、今回はじゃんけんの結果に応じてお菓子(うまい棒)が飛び出てくるマシーンを作ったため、ROSを使った実装にしました。
(rosserialを使ってArduinoを制御し、サーボモーターを動かしてうまい棒を飛ばす)
何か皆様の参考になる部分があれば幸いです。