2018/06/23に@shunarooさんが主催している勉強会で話した内容を加筆・修正したものです。
当日の発表資料 (SlideShare)
はじめに
皆さんはをどのように情報収集していますでしょうか?
私はfeedlyを試してみたものの、あまり開いていません。
そんな私ですが、arXivにアップロードされる論文はチェックしておきたいので、職場で使っているSlackに興味のあるものを通知してくれるBotが欲しいなと思っていました。
しかし、似たようなものばかりレコメンドしても良い気付きが得られないような気がしていたので、Botを作るまでには至りませんでした。
ところが、先日、ふと「自分のフォーカスしたい分野の中で、最も興味が無い論文からアハ体験1できないだろうか?」と、思ったので実装してみることにしました。
レコメンドについては、基本的なアルゴリズムは理解しているものの、実装するのは初めてです。
もっと良い方法がある、間違いがある等はコメントして頂けると嬉しいです。
作るもの
arXivのRSSのアップデート情報から自分の興味に近い論文と最も遠い論文を抽出してSlackに投稿するチャットBot
推薦アルゴリズム
TF-IDFとコサイン類似度によるコンテンツベース
使用言語と依存ライブラリ(標準ライブラリを除く)
Python 3.5以上
requests
scikit-learn
pandas
BeautifulSoup4
PyYAML
作成したプログラム一式はこちらです。
GitHub: Katsuya-Ishiyama/paper_recommend
実装手順
プログラムの全体像
これから作成するプログラムはいくつかのファイルに分けて実装していきますが、最終的にはmain.pyで統合して、
$ python main.py --fields cs stat
と実行します。
main.pyは次のようになっています。
# -*- coding: utf-8 -*-
import argparse
import pandas as pd
from recommend import recommend
from scraper import RSSScraper
from similarity import calculate_similarity_of_interest
def get_commandline_args():
parser = argparse.ArgumentParser()
parser.add_argument('--fields',
type=str,
required=True,
nargs='+',
help='Your interested fields.')
return parser.parse_args()
def main():
# TODO: revise to receive interest from a foreign source.
interest = ['I want to predict mascots\' popularity from its photo using machine learning methodologies.']
args = get_commandline_args()
scraper = RSSScraper()
_papers = []
descriptions = []
for field in args.fields:
scraper.fetch_rss(field=field)
for _abs in scraper.extract_paper_abstract():
_papers.append(_abs)
descriptions.append(_abs['description'])
papers = pd.DataFrame(data=_papers)
similarity = pd.Series(
data=calculate_similarity_of_interest(
interest=interest,
descriptions=descriptions
)
)
papers.loc[:, 'similarity'] = similarity
recommend(papers, interest)
if __name__ == '__main__':
main()
RSSから必要なデータを抽出する
arXivのRSSは http://arXiv.org/rss/{your interested field} から取得できます。
ここでは統計学 (Statistics) の場合を例にして実際にブラウザでデータを取得してみます。
{your interested field} は stat なので実際のURLはhttp://arXiv.org/rss/stat 2となります。
ブラウザに上記のURLを入力すると
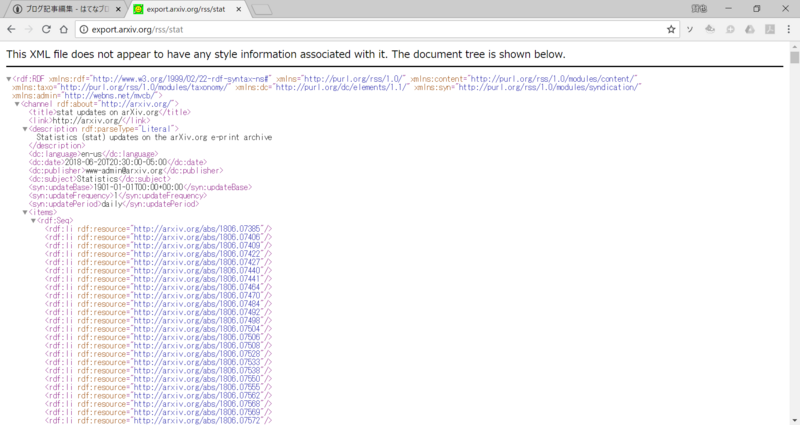
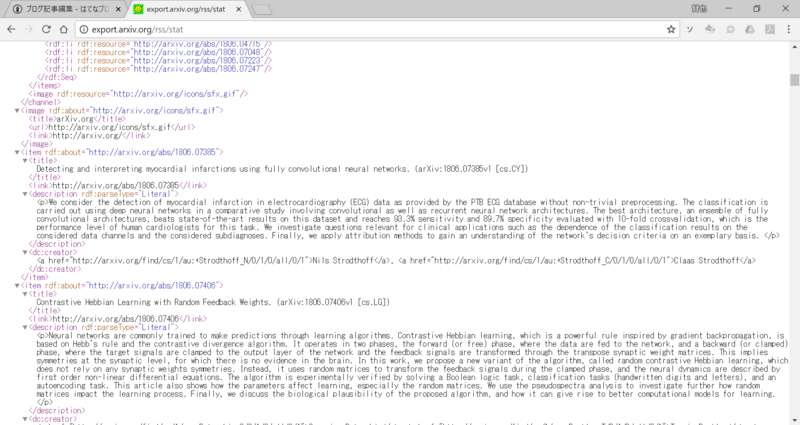
上のようにXMLで結果が返ってくるのでHTMLパーサーが必要です。
今回はrequestsとBeautifulSoup3を使ってスクレーパーを作成します。
ファイル名はscraper.pyとします。
# -*- coding: utf-8 -*-
import logging
import re
import requests
from bs4 import BeautifulSoup
from bs4.element import Tag
logger = logging.getLogger('RSSScraper')
class RSSScraper(object):
def __init__(self):
self.base_url = 'http://arxiv.org/rss/{field}'
self.field = None
self.response = None
self.parsed_html = None
@property
def url(self):
"""
getter of url
Returns
-------
url of arXiv's rss
"""
return self.base_url.format(field=self.field)
def fetch_rss(self, field: str):
""" fetch rss from arXiv
Arguments
---------
field : str
field of your expertise. (eg. stat, cs)
Returns
-------
html parsed by BeautifulSoup
"""
self.field = field
_url = self.url
_response = requests.get(_url)
_status_code = _response.status_code
if _status_code != 200:
logging.warning('{} status code: {}'.format(_url, _status_code))
raise requests.HTTPError(_status_code)
else:
self.response = _response
self.parsed_html = BeautifulSoup(self.response.text, 'lxml')
self._metadata_src = self.parsed_html.findAll('channel')[0]
self._abstract_src = self.parsed_html.find_all('item')
def _extract_metadata_internal(self, category: str) -> str:
"""
Extract metadata from fetched html.
Arguments
---------
category: str
category of metadata. eg: date, publisher etc.
Returns
-------
extracted metadata. all data types are str.
"""
target_tag = '<dc:{category}>'.format(category=category)
_meta = None
for content in self._metadata_src.contents:
if target_tag in str(content):
_meta = content.text
break
return _meta
def extract_metadata(self):
""" extract metadata from fetched html. """
_meta = {
'date': self._extract_metadata_internal('date'),
'lang': self._extract_metadata_internal('language'),
'publisher': self._extract_metadata_internal('publisher'),
'subject': self._extract_metadata_internal('subject')
}
return _meta
def extract_paper_abstract(self):
_metadata = self.extract_metadata()
for tag in self._abstract_src:
abstract = {
'title': self._extract_title(tag),
'description': self._extract_description(tag),
'link': self._extract_link(tag),
'authors': self._extract_authors(tag)
}
abstract.update(_metadata)
yield abstract
def _extract_title(self, tag: Tag) -> str:
return tag.title.text
def _extract_description(self, tag: Tag) -> str:
desc = tag.description.text
soup = BeautifulSoup(desc.replace('\n', ' '), 'xml')
normalised = soup.text
return normalised
def _extract_link(self, tag: Tag) -> str:
link = re.findall(r'<link/>(.*)\n', str(tag))[0]
return link
def _extract_authors(self, tag: Tag) -> str:
creators = re.findall(r'<dc:creator>(.*)</dc:creator>', str(tag))[0]
creators_xml = creators.replace('<', '<')
creators_xml = creators_xml.replace('>', '>')
soup = BeautifulSoup(creators_xml, 'lxml')
tags = soup.findAll('a')
authors = [{'name': t.text, 'link': t.get('href')} for t in tags]
return authors
今回は試しにType Hintsを使っています。
引数にどの型のデータを入れたらいいのか分かりやすくなるので、気に入っています4が、python 3.5以上でないと使えないので注意が必要です。
類似度の計算を実装
自分の興味と論文の要約との類似度はそれぞれのTF-IDFからコサイン類似度を使って算出します。
ここでは理論的な部分に触れません5が、このあたりの事を学びたいならば、入門 ソーシャルデータ 第2版 の第4章に分かりやすく書かれているのでオススメです。
TF-IDFとコサイン類似度はscikit-learnを使っています。
TF-IDFを計算するTfidfVectoriserについてはscikit-learn.feature_extraction.textのTfidfVectorizerを検証するをご確認下さい。
calculate_similarity_of_interest関数は自分の興味を説明した文interestと論文の要約descriptionsを引数で受け取って、それらの間の類似度を計算します。
類似度を計算するプログラムsimilarity.pyは次の通りです。
# -*- coding: utf-8 -*-
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
def calculate_similarity_of_interest(interest, descriptions):
corpus = interest + descriptions
vectorizer = TfidfVectorizer(ngram_range=(1, 3),
stop_words='english')
tfidf_matrix = vectorizer.fit_transform(corpus).toarray()
interest_tfidf_matrix = tfidf_matrix[0, :]
descriptions_tfidf_matrix = tfidf_matrix[1:, :]
similarity = cosine_similarity(X=interest_tfidf_matrix.reshape(1, -1),
Y=descriptions_tfidf_matrix)
return similarity[0].tolist()
corpus = interest + descriptionsとする理由はコサイン類似度を求める際にTF-IDFの並びが同じになっている必要があるためです。
そのため、一度corpusを作成して、興味の説明文と論文の要旨を一緒にTfidfVectorizerに投げ込み、返ってきた行列をそれぞれに分解するという作業をしています。
レコメンドを実装
自分の興味を説明した文に最も近い論文と最も興味から遠い論文の2本を抽出して、Slackに投稿するまでを担っています。
# -*- coding: utf-8 -*-
import pandas as pd
from slack import Slack
def check_exists_similarity(data: pd.DataFrame) -> bool:
if data.columns.isin(['similarity']).any():
return True
else:
return False
def extract_most_similar_paper(data: pd.DataFrame) -> pd.DataFrame:
if not check_exists_similarity(data):
raise ValueError('data must contain "similarity" in its column.')
similarity = data.similarity
is_most_similar = similarity == similarity.max()
return data.loc[is_most_similar, :].copy()
def extract_most_dissimilar_paper(data: pd.DataFrame) -> pd.DataFrame:
if not check_exists_similarity(data):
raise ValueError('data must contain "similarity" in its column.')
data_exclude_zero = data.loc[data.similarity > 0, :]
similarity = data_exclude_zero.similarity
is_most_dissimilar = similarity == similarity.min()
return data_exclude_zero.loc[is_most_dissimilar, :].copy()
# TODO: implement displaying the authors
MESSAGE = """*Today's most {recommend_type} paper of your interest*
----------
Your Interest:
> {interest}
Title:
> {title}
URL:
> {link}
Descriptions:
> {description}
"""
def generate_recommend_message(data: pd.DataFrame, recommend_type: str, interest: str) -> str:
return MESSAGE.format(interest=interest,
recommend_type=recommend_type,
title=data.title.values[0],
link=data.link.values[0],
description=data.description.values[0])
def recommend(data: pd.DataFrame, interest) -> object:
slack = Slack()
_interest = interest[0]
most_similar = extract_most_similar_paper(data)
most_similar_message = generate_recommend_message(
data=most_similar,
recommend_type='similar',
interest=_interest
)
slack.post_message(most_similar_message)
most_dissimilar = extract_most_dissimilar_paper(data)
most_dissimilar_message = generate_recommend_message(
data=most_dissimilar,
recommend_type='dissimilar',
interest=_interest
)
slack.post_message(most_dissimilar_message)
Slackへの投稿部分を作る
Slackに投稿するライブラリは下記のように作成します。
作成にあたっては、予めアカウントにアプリを登録6し、Incoming Webhookを有効にしてエンドポイントを取得しておいて下さい。
# -*- coding: utf-8 -*-
import json
import requests
import yaml
class Slack(object):
def __init__(self):
self._conf = self.load_conf()
def load_conf(self) -> dict:
with open('paper_recommend/.slack_conf.yaml', 'r') as f:
_conf = yaml.load(f)
return _conf
def post_message(self, message: str) -> object:
url = self._conf['webhook']['url']
requests.post(url=url, data=json.dumps({'text': message}))
WebhookのURLは.slack_conf.yamlに次のように保存します。
webhook:
url: your_endpoint
以上で実装完了です。
あとは適当なサーバーにデプロイしてcronで定期更新してください。
レコメンド結果
実際にレコメンドした結果を画像で紹介します。
今回の興味は
I want to predict mascots' popularity from its photo using machine learning methodologies.
です。
ゆるキャラグランプリの順位を画像のみで推定できないかを試していまして、それを簡単に説明した文です。
興味に最も近い論文は、なんとなく興味に近いものをレコメンドできています。
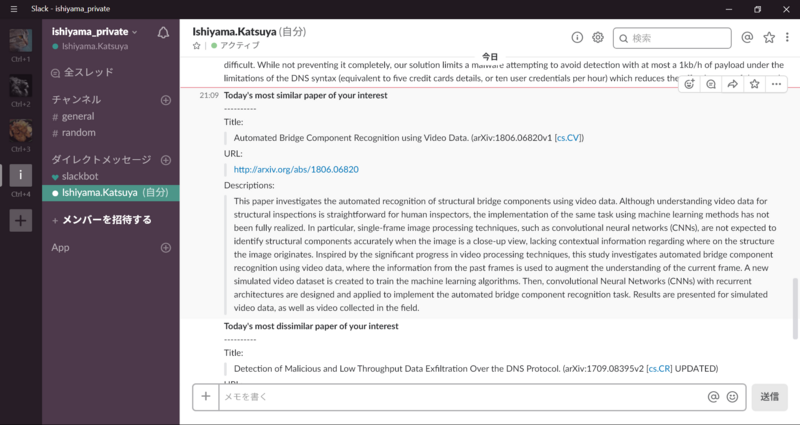
対して、興味から最も遠い論文は、、、まったく興味ない。
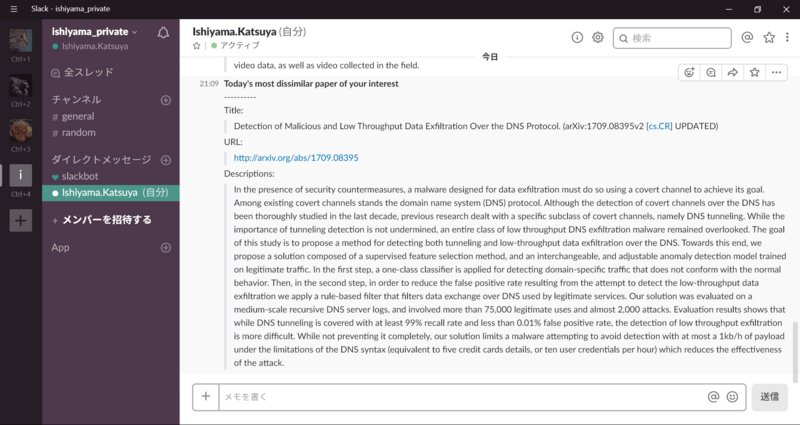
まとめ
今回はarXivのRSSで自分の興味に最も近い論文と最も遠い論文を1本ずつレコメンドするSlack Botを作りました。
最も近い論文は実際に自分の興味と重なっている部分がありますが、反対に、最も遠い論文は興味が持てませんでした。
レコメンド対象分野に統計 (stat) とコンピューター・サイエンス (cs) の2つを選びましたが、どちらの分野も幅が広いので、さらに範囲を狭める処理を追加した方が精度が上がりそうです。
また、この結果を受けて、「類似度を何らかの方法でクラスタ分けして、そのクラスタの代表的な論文を1本ずつレコメンドする」方が広くチェックできるので、当初の目的を果たせる確率も高くなりそうです。
今後の課題
- 自分の興味(
main.pyのinterest)をSlack Botにメッセージを投げれば登録できるようにする。 - 専門分野も上と同じように登録できるようにする。
- 今回は扱える興味が1つだったが、複数扱えるようにする。
- より洗練された推薦アルゴリズムを採用する。
- GAEなどのクラウド上のサーバーで運用する。
- 事後検証できるように、取得した論文の情報を保存できるようにする。
-
実際には http://export.arxiv.org/rss/stat に飛ばされます。 ↩
-
XPathがうまく使えるパーサーがあると楽なんですが。 ↩
-
こちらにもありますが、徐々に言語が同じ構文になって来ているように思います。
私の認識ではScalaのような形になっていると認識していますが、この理解であっているんでしょうか? ↩ -
方法は当日の発表資料 (SlideShare)のAppendixに記載してあります。 ↩